Timeseries data analysis process
☑️ 시계열 분석이란?
과거의 관측값이 가지고 있는 여러 패턴 토대로, 미래의 관측값을 예측하는 것.
☑️ 고전적인 시계열 모델과 딥러닝 계열 시계열 모델의 차이
- 고전적인 시계열 모델 (ex. AR) : 예측 대상을 제외한 외생변수를 사용하지 않는다. 즉, univariate timeseries 모델임.
- 딥러닝 계열 시계열 모델 : 다른 외생변수의 사용에 제한이 없다. 즉, multivariate timeseries로 확장 가능하다. (딥러닝 계열 시계열 모델의 장점)
☑️ 시계열 데이터 분석 과정
-
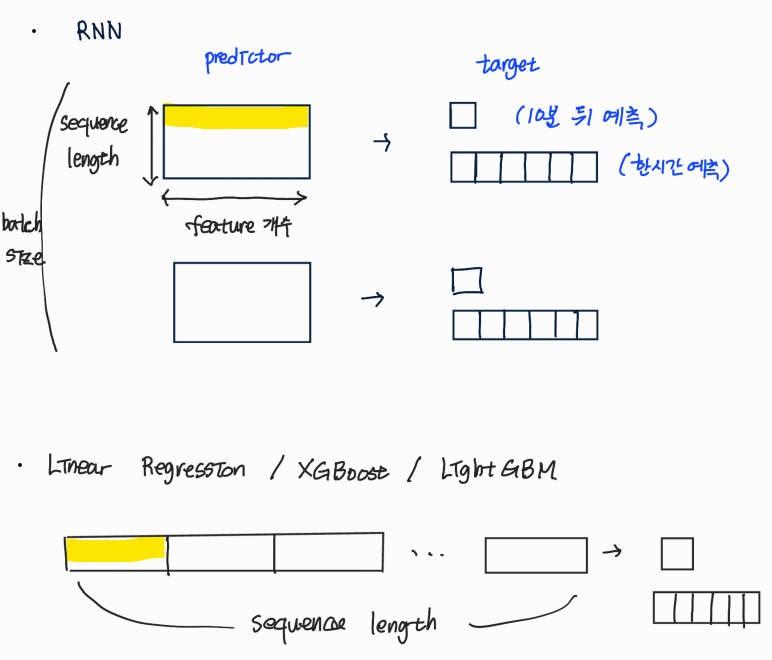
문제를 정의 : 과거 데이터 몇 개의 sequence(timestamp)로 미래 얼마만큼의 sequence를 예측할 건지를 결정한다.
ex) 7일 데이터(predictor)로 미래 1시간(target) 예측 -
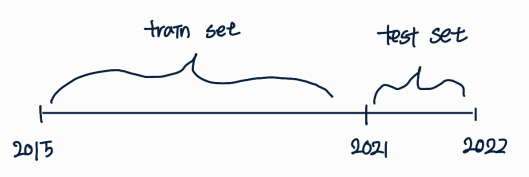
train/test split : 과거 데이터로 미래 시점을 예측하는 문제이므로 train/test split시 데이터가 섞이지 않도록 유의해야 한다.
특히, train data의 마지막 sequence length를 통해 test data의 첫 시점을 예측하므로 test data set을 나눌 때, train data의 마지막 sequence를 포함시켜야 한다.train_size : 전체 데이터의 80%로 임의 지정 train_set = df[0:train_size] test_set = df[train_size - sequence_length: ] -
scaling : 딥러닝 모델을 사용할 때는 데이터를 스케일링 해야함.
시계열 데이터를 scaling 할 때는 반드시 데이터를 train/test set으로 나눈 이후, scaling을 해야 함.
train/test set을 나누지 않은 채로 전체 데이터에 대해 scaling하면, 만약 test set에 max값이 있으면 미래 정보를 가지고 scaling하는 경우가 발생하기 때문이다.
→ 따라서, 먼저 train/test set을 나누고 train set 내에서 scalng을한 다음, 그 값을 test set을 scaling하는데도 적용해야 한다.
- sliding window : sequence data를 만드는 과정
def build_dataset(data, seq_length): dataX = [] dataY = [] for i in range(0, len(data)-seq_length): _x = data[i:i+seq_length, :] # 0: 0+48 _y = data[i+seq_length ,[-1] ] # 48:48+12 # print(_x, "-->",_y) dataX.append(_x) dataY.append(_y) return np.array(dataX), np.array(dataY)
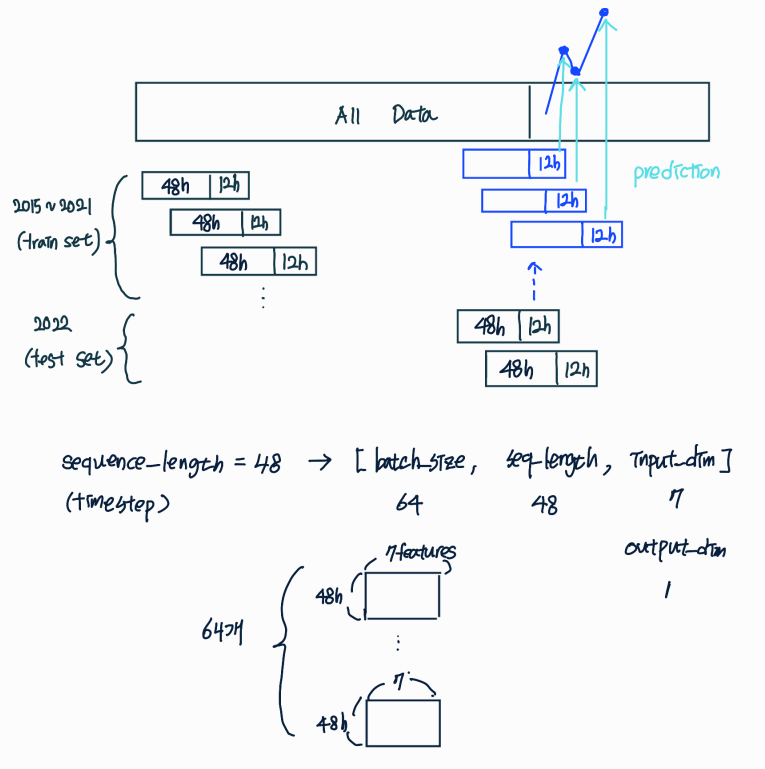
- 2015~2021 sequence dataset으로 모델 학습
- 2022 sequence dataset으로 예측 (48h으로 12h 예측하고, 48h으로 12h 예측하고, 계속해서 순차적으로 예측해나감)
- 모델 : 모델에 따라 데이터의 형태가 달라진다.