미래연구소 딥러닝 스터디 17기
1.[미래연구소] 딥러닝 스터디 17기 - week 2

https://futurelab.creatorlink.net/ 컴퓨터가 딥러닝 연산을 하기 위해서는 비정형 데이터를 컴퓨터가 연산할 수 있도록 '수치화'하는 과정이 필요함. 이렇게 수치화된 데이터들을 matrix 형태로 보관/처리하는 것을 vectori
2.[미래연구소] 딥러닝 스터디 17기 week 3
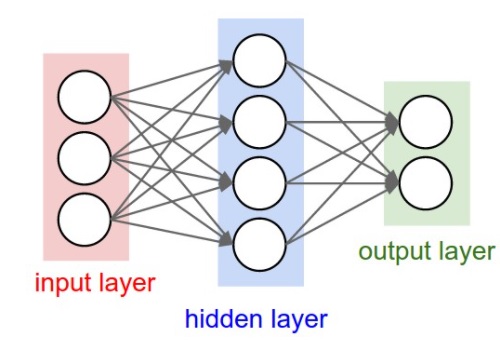
http://futurelab.creatorlink.net/ 2주차에서는 hidden layer의 node가 하나인 경우만을 다뤘다. 3주차에서는 hidden layer의 node가 여러개인 경우로 확장해 공부하기로 한다. hidden layer의 node가
3.[미래연구소] 딥러닝 17기 week 4
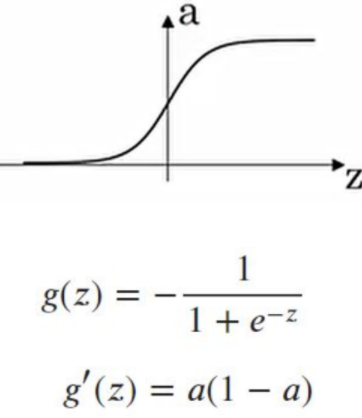
http://futurelab.creatorlink.net/sigmoid의 단점 : 0 < s(z) < 1saturation : weight의 update가 잘 일어나지 않는 현상 vanishing gradient : activation의 미분계수가
4.[미래연구소] 딥러닝 17기 week5
Underfitting vs. Overfitting Fit 이란? 특정 data를 학습하는 과정 overfitting : 너무 학습을 많이해서 정답을 외워버리는 현상 underfitting : 모델이 train data조차도 잘 못 맞추는 상황 그렇다면 right
5.[미래연구소] 딥러닝 17기 week6
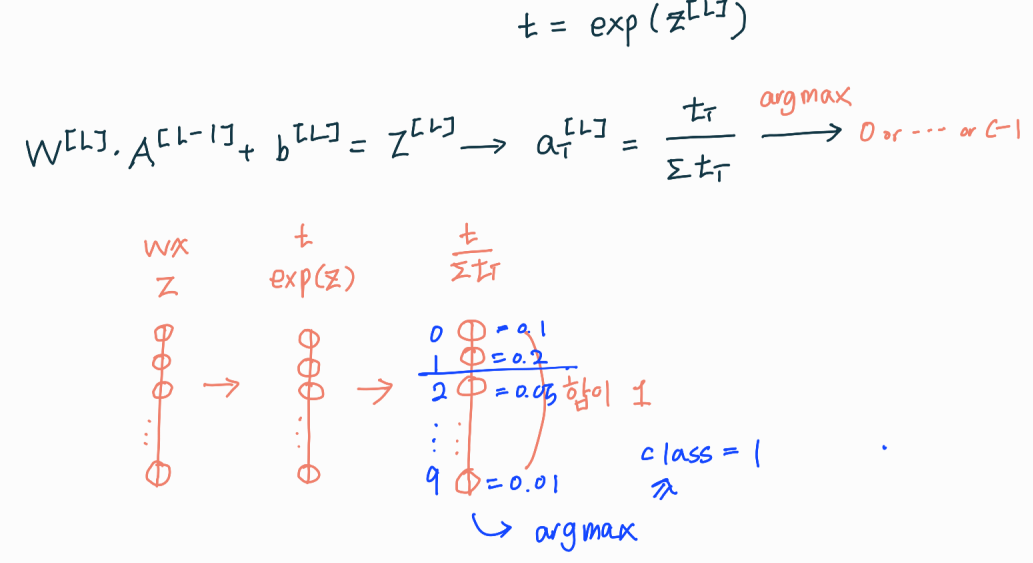
http://futurelab.creatorlink.net/1) output layer와 class의 연관성 \-> output layer node는 각각 class가 될 확률이다.즉, output layer node개수 = class 개수2) softmax의
6.[미래연구소] 딥러닝 17기 week7

http://futurelab.creatorlink.net/input data의 범위를 조정\-> input 간에 (x1, x2) 범위가 달라지게 되면 cost 함수가 찌그러진 형태로 그려질 수 밖에 없고, 그렇게 되면 일정한 learning rate에 대해서
7.[미래연구소] 딥러닝 17기 week8
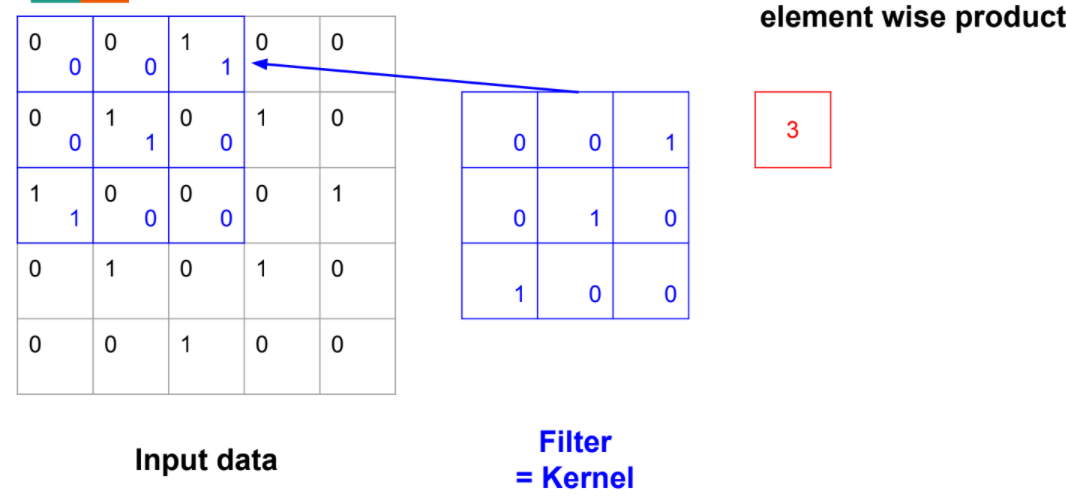
\- 사람/동물의 시각자극 처리 방법1) 뇌는 인접 정보를 읽는다. (간단한 점, 선들부터 뉴런이 반응)\-> 특정 feature를 detect하는 뉴런이 필요2) 뇌는 인접 정보를 읽는다.\-> 인접 feature를 detect하는 뉴런이 필요3) 뇌는 공간 정보를
8.[미래연구소] 딥러닝 17기 week9
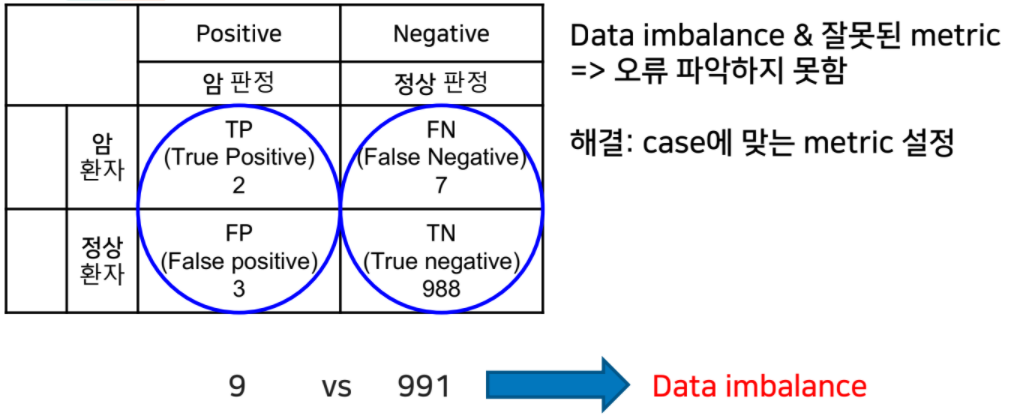
http://futurelab.creatorlink.net/Regression MAE(mean absolute error) : 특이값(outlier)에 robust, 절댓값을 취하기 때문에 차이를 직관적으로 느낄 수 있음RMSE(root mean square