라우터
아카 라이브러리에서 병렬 처리를 해야할 때 사용하는 메커니즘은 라우터이다.
// Main 클래스
import akka.actor.{ActorSystem, Props}
import org.study.actor.PingActor
object Main {
def main(args: Array[String]) = {
val actorSystem = ActorSystem.create("TestSystem")
val ping = actorSystem.actorOf(Props.create(classOf[PingActor]))
ping ! "start"
}
}
// PingActor 클래스
import akka.actor.{Actor, Props}
import akka.event.Logging
import akka.routing.RoundRobinPool
/**
* 아카 라우터를 이용해서 자식 액터를 만들고 1부터 10까지의 정수를 보내는 액터
*/
class PingActor extends Actor {
val log = Logging(context.system, this)
val childRouter = context.actorOf(RoundRobinPool(5).props(Props[Ping1Actor]), "ping1Actor")
def receive = {
case msg : String =>
for (i <- 1 to 10) childRouter ! i
log.info("PingActor sent 10 messages to the router.")
}
}
// Ping1Actor 클래스
import akka.actor.{Actor, ActorRef}
import akka.event.Logging
/**
* 정수를 받으면 자신의 해시코드 값과 함께 화면에 출력하는 간단한 액터
*/
class Ping1Actor extends Actor {
val log = Logging(context.system, this)
override def receive = {
case msg: Int =>
log.info(s"Ping1Actor($this.hashcode) received $msg")
work(msg)
}
private def work(n: Integer) {
log.info(s"Ping1Actor($hashCode()) is working on $n")
Thread.sleep(1000) // 실전에서는 절대 금물!!!
log.info(s"Ping1Actor($this.hashCode()) completed")
}
}
PingActor가 자식 액터를 만들 때 보통과 다르게 아카의 라우터를 만들고 있다.
class PingActor extends Actor {
val log = Logging(context.system, this)
val childRouter = context.actorOf(RoundRobinPool(5).props(Props[Ping1Actor]), "ping1Actor")보통의 경우라면
context.actorOf(Props.create(classOf[Ping1Actor]), "ping1Actor") 처럼 작성될텐데
라우터를 사용하면 액터 조립법을 RoundRobinPool 이라는 객체의 props 메서드에 인수로 전달하게 된다.
이것은 아카에서 라우터를 만들기 위해 사용하는 특정한 API 다.
라우터는 동일한 클래스를 이용해서 만들어진 여러 개의 인스턴스 앞에 존재하는 가상의 액터라고 생각하면 된다.
RoundRobinPool(5)라고 하면 Ping1Actor 를 이용하는 액터를 5개까지 포함하는 pool을 만들어서 사용하겠다는 뜻이다.
이때 풀에 존재하는 구체적인 액터 인스턴스에 직접 접근하지 않고
라우터를 가리키는 ActorRef를 사용한다.
PingActor 코드에서 childRouter 라는 이름을 가진 객체의 타입이 ActorRef인데 이것이 라우터다.
액터 / 라우터 모두 ActorRef 타입으로 표현된다는 점에서는 차이가 없다.
그러나 일반적인 액터는 ActorRef가 액터의 인스턴스 자체를 가리키고,
라우터의 경우에는 ActorRef가 액터의 인스턴스로 이루어진 풀 앞에 놓여있는 임시적인 액터를 가리킨다는 점에서 차이가 있다.
예제 코드가 구현하고 있는 액터와 라우터를 그림으로 표현하면 다음과 같다.
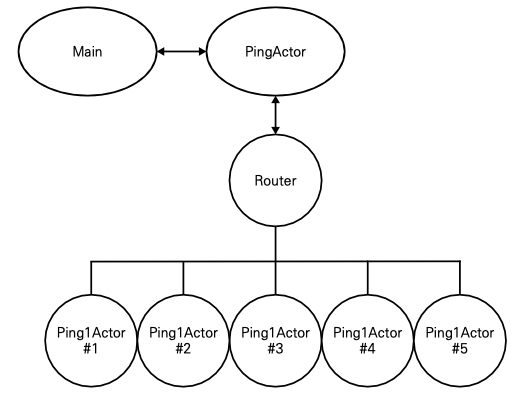
PingActor가 보기에 Ping1Actor는 평소처럼 하나의 액터로 인식된다.
Router 아래의 Ping1Actor #1 에서 #5 까지의 인스턴스는 액터 풀에 존재하는 객체들로서
라우터 바깥에서는 보이지 않는다.
그들에게 접근하기 위해서는 라우터에게 메시지를 전달해야 한다.
이렇게 라우터 뒤에 숨어서 동작하는 액터들을 "라우티 routee" 라고 부르기도 한다.
라우티에게 전달된 메시지는 백그라운드 풀에 존재하는 5개의 Ping1Actor 인스턴스에게 하나씩 번갈아가면서 전달된다.(round robin 방식)
이러한 Ping1Actor 액터들은 컴퓨터의 CPU 코어가 충분하다면 최대한 병렬적인 방식으로 동작을 수행한다.
Ping1Actor는 메시지가 전달되면 어떤 액터 인스턴스가 어떤 값을 처리하는지 확인하기 위해서 자신의 해시코드 값과 함께 자기가 처리하고 있는 메시지의 값을 화면에 출력한다.
라우터를 이용하면 일반 액터를 사용할때 보다 훨씬 실행시간이 단축된다.
아카의 라우터가 제공하는 기능은 강력하고 편리하기 때문에 병렬성이나 확장성을 고려할 때 라우터는 언제나 좋은 선택이 된다.
예제 소스를 실행시키면 출력값에 해시값이 같이 출력되는데 사실 이 해시값은 불필요하다.
출력된 내용을 자세히 보면 액터가 고유한 경로를 가지고 있음을 알 수 있다.
아카에서 모든 액터는 트리구조에 포함된 노드이기 때문에 루트에서 시작해서 자신에게 이르는 '경로'라는 개념을 갖는다.
우리가 다루고 있는 액터의 경우에는 "pingActor" 라는 이름의 액터에서 출발해서 "ping1Actor" 라는 이름의 라우터 액터를 지나 "$b" 라는 이름의 액터에 이르는 경로를 가지고 있다.
다시 말해서 이 액터의 이름은 "$b" 이다. 이 액터는 아카의 라우터 기능에 의해서 풀 내부에서 동적으로 생성되기 때문에 사람이 붙여주는 이름이 없다.
라우터와 감시전략
풀 내부에 존재하는 액터인스턴스들의 부모 액터가 누구인가 하는 점이 헷갈릴 수 있다.
예제 코드에서 “ping1Actor”라는 이름의 라우터를 만 든 부모 액터는 “pingActor”였다.
하지만 “ping1Actor”로 지칭되는 액터는 실 제 Ping1Actor 클래스의 인스턴스가 아니라 ‘라우터’를 가리키는 액터다.
그렇다면 풀 내부에 존재하는 다섯 개의 Ping1Actor 인스턴스들의 부모는 “pingActor”인가 아니면 “ping1Actor”인가.
앞에서 본 경로에서도 쉽게 확인할 수 있듯 Ping1Actor 인스턴스들의 부모는 당연히 “ping1Actor”, 즉 라우터 자신이다.
그것은 곧 Ping1Actor의 인스턴스 들($a, $b, $c, $d, $d라는 이름을 갖는 액터 인스턴스들)의 감시자도 “ping1Actor”라는 이름을 가진 라우터라는 사실을 뜻하기도 한다.
풀과 그룹
아카 라우터에서 풀 pool 은 라우터에게 내부의 액터 인스턴스를 생성할 권리를 부여하는 것을 말한다.
그래서 라우터가 액터 인스턴스들의 감시자 역할도 하고, 부모로서의 라이프 사이클을 관리한다.
하지만 경우에 따라서는 우리가 직접 생성한 액터를 그룹으로 묶은 다음,
어떤 라우터에게 그 그룹에 존재하는 액터들을 라우티로 사용하라고 말하고 싶을때도 있다.
이런 경우에는 라우터가 액터 인스턴스를 생성할 권리를 갖지 않고,
따라서 감시자나 부모의 역할도 수행하지 않는다.
단순히 자기에게 전달된 메시지를 정해진 알고리즘에 따라서 그룹에 존재하는 다른 액터에게 전달하는 역할만 담당한다.
라우팅 알고리즘
아카 라이브러리는 단순한 라운드로빈 외에도 다음과 같이 다양한 라우팅 알고리즘을 지원한다.
RandomRouter
이름 그대로 라우터 배후에서 동작하고 있는 액터 인스턴스 중에서 하나를 무작위 로 골라서 메시지를 전송하는 알고리즘이다.
SmallestMailboxRouter
액터 인스턴스 중에서 메일박스에 처리되지 않고 저장되어 있는 메시지의 수가 가 장 적은 것을 골라서 보내는 알고리즘이다. 인스턴스 사이에서 업무량의 균형을 맞춰주고 싶을 때 사용하면 된다.
BroadcastRouter
라우터에 전달된 메시지를 액터 인스턴스 모두에게 전송하고자 할 때 사용한다.
ScatterGatherFirstCompletedRouter
scatter라는 영어단어는 흩뿌린다는 뜻을 가지고 있다. gather first completed 라는 표현은 첫 번째로 완료된 결과를 수집한다는 뜻이다.
두 표현을 연결해서 생 각해보면 라우터에 전달된 메시지를 모든 액터 인스턴스에 전달한 다음, 가장 먼저 계산된 결과를 리턴 하는 것을 취하고 나머지는 무시하는 알고리즘이다.
ConsistentHashingRouter
해시에서 키가 매핑 되는 슬롯의 위치에 액터가 있다고 생각하면 이해하기 쉽다. 라우터는 전달된 메시지가 가진 키의 해시 값을 계산한 다음, 그 해시 값에 매핑 되어 있는 액터 인스턴스에게 메시지를 전송한다.
따라서 해시 값이 변하지 않는 한 동일한 키를 가진 메시지는 언제나 동일한 액터 인스턴스에게 전달된다.
아카 에서 지원하는 ConsistentHashingRouter는 단순히 해시 알고리즘만 사용하 는 것이 아니라 분산 시스템에서 널리 사용되는 알고리즘인 일관적 해시consistent hashing를 사용해서 가변성을 최소화 시킨 것이다.
