ch.01
아카의 장점
프로그램 곳곳에 존재하는 순차적 부분, 블로킹 콜을 전부 없애거나 최소한으로 만들 수 있다.
여러 개의 스레드가 동시에 작업을 수행하더라도, Thread 나 Task 가 포함하지 않는 코드가 존재하기 때문에 순차적 작업이 존재하게 된다.
아카는 이러한 순차적 작업을 줄여준다.
스케일 아웃을 자동적으로 보장해준다.
아카 세계의 컴포넌트는 액터 이다.
하나의 액터만 집어내어 기존의 JVM 에서 독자적인 JVM으로 실행하는 것은 매우 쉽다.
별도의 JVM으로 독립시키지 않고 동일한 JVM 내에서 인스턴스 수만 늘리는 것도 가능하다.
-> location transparance 기능 덕분
유연한 스케일 덕분에 시스템 전체의 처리율을 적정한 수준으로 유지하는 작업이 수월해진다.
모듈화
아카를 사용하여 시스템을 설계하면 클래스/객체 중심으로 생각하던 사고방식이 '액터'를 중심으로 변화된다.
기존의 java, c# 같은 언어에서의 객체들은 서로 밀접하게 결합되어 있다.
그에 비해 액터는 서로 완벽하게 독립적이며, 오로지 메시지를 주고 받는 방식으로만 커뮤니케이션 하기 때문에 응집성 , 느슨한 결합 , 캡슐화 등의 프로그래밍 원리를 완벽히 구현한다.
이런 식의 코드를 설계하다보면, 코드 조각들이 특정 기능을 중심으로 자연스럽게 모여드는데
그 조각이 하나의 독립적인 액터, 또는 컴포넌트를 형성한다.
이러한 컴포넌트를 떼어내서 독립적 JVM 위에서 실행하기 위해서 클러스터를 구축할 수 도 있고,
독자적인 서비스를 만들기 위해 마이크로서비스 아키텍처를 구현 할 수도 있다.
차세대 동시성 모델
액터 모델에서는 Lock 등의 구조물이 없다.
오직 액터만 존재한다.
액터들은 서로 독립적인 구조물이며, 서로 메소드를 호출할 수도 없고,
new 를 통해서 새로운 인스턴스를 만들수도 없다.
반응형 선언 에서는 SW의 덕목을 4가지로 말한다.
- 반응성
-
모든 소프트웨어는 사용자가 필요로 할 때 빠르게 응답하는 것을 목적으로 삼아야 한다.
-
모든 상황에 구애받지 않고 일관성 있는 반응성을 유지하게 만들어야 한다.
- 탄력성
- 확장성 이라는 표현보다 스케일 업/다운 을 모두 포괄하는 용어
- 유연성
-
장애허용과 밀접한 관련
-
반응성 + 구체적 방법
-
중복, 격리, 대리 등의 방법 사용
- 메시지 중심
-
사건 -> 메시지
-
사건 : 목적지 없음 / 메시지 : 반드시 목적지 있음
-
비동기적 메시지 전달과 장소 투명성을 포괄함
ch.02
핑퐁 게임
[ 액터 시스템 만들기 ]
액터를 사용하기 위해서는 우선 ActorSystem 이라는 객체를 만들어야 한다.
모든 액터는 어떤 액터 시스템 내부에서 동작을 수행한다.
그러므로 액터시스템 = 액터를 담는 컨테이너 라고 생각할 수 있다.
동일한 액터 시스템 안의 액터들은
- 스레드 스케줄링
- 구성파일
- 로그 서비스
등을 공유한다.
액터 시스템은 ActorSystem 클래스에 정의된 정적 메서드 create 를 호출하여 생성한다.
이처럼 어떤 객체를 생성하기 위한 목적으로 사용되는 정적 메서드를
팩토리 메서드 라고 한다.
val actorSystem = ActorSystem.create("TestSystem")
create 메서드에 전달하는 문자열은 사용하려는 액터시스템의 이름이다.
하나의 애플리케이션에서 하나의 액터시스템을 사용하는 것이 일반적이지만
그 안에서 여러개의 액터시스템을 만들어 사용하는 것도 가능하다.
[ 액터 만들기 ]
// 메인 클래스
import akka.actor.{ActorSystem, Props}
import org.study.actor.PingActor
object Main {
def main(args: Array[String]) = {
val actorSystem = ActorSystem.create("TestSystem")
def ping = actorSystem.actorOf(Props.create(classOf[PingActor]))
ping ! "pong"
}
}
// PingActor 클래스
import akka.actor.{Actor, Props}
import akka.event.Logging
class PingActor extends Actor {
val log = Logging(context.system, this)
val pong = context.actorOf(Props.create(classOf[PongActor], self), "pongActor")
def receive = {
case msg@"pong" =>
log.info(s"Ping received $msg")
pong ! "ping"
}
}
// PongActor 클래스
import akka.actor.{Actor, ActorRef}
import akka.event.Logging
class PongActor(ping: ActorRef) extends Actor {
val log = Logging(context.system, this)
def receive = {
case msg@"ping" =>
log.info(s"Pong received $msg")
ping ! "pong"
Thread.sleep(1000) // 실전에서는 절대 금물!!!
}
}액터를 만드는 부분의 코드는
val pong = context.actorOf(Props.create(classOf[PongActor], self), "pongActor")이다.
액터시스템이 액터를 만들기 위해서는 Props, 액터의 이름 이 두가지가 필요하다.
여기서 Props 란
- 액터를 만드는 데 필요한 구성 요소를 담는 구성파일 같은 클래스
- 불변객체이기 때문에 필요한 곳에서 자유롭게 공유 가능
액터 클래스가 인수 없이 기본 생성자를 사용하는 경우에는
Props.create(PingActor.class)처럼 액터의 타입(클래스) 만 전달하면 된다.
만약 액터 클래스가 인수를 받아들이는 생성자를 사용하면
Props.create(PingActor.class, "arg1", "arg2") 와 같이 작성하여 인수를 전달할 수도 있다.
액터의 이름 은 액터시스템 내에서 반드시 고유해야 한다.
액터들은 tree 와 비슷한 계층구조를 형성하기 때문에 경로(path) 라는 개념이 존재하는데,
액터의 이름은 경로에서 사용된다.
액터의 이름이 무의미할 때는 UUID.randomUUID() 를 사용하기도 한다.
actorOf 라는 것은 액터를 만들기 위한 팩토리 메서드이다.
props 와 액터의 이름을 인수로 받아들인다.
ActorSystem 또는 ActorContext 객체로부터 호출할 수 있다.
[ ActorRef ]
위의 코드에서 ActorSystem 의 actorOf 메서드가 생성하는 객체의 타입이
PingActor 가 아닌 ActorRef 라는 점이다.
액터시스템 내의 액터는 모두 ActorRef 이며
ActorRef 는 액터를 가리키는 참조이다.
모든 액터는 오직 ActorRef 라는 타입에 의해서만 접근 가능하다.
ActorRef 를 액터 객체를 둘러싸고 있는 껍질이라고 볼 수도 있다.
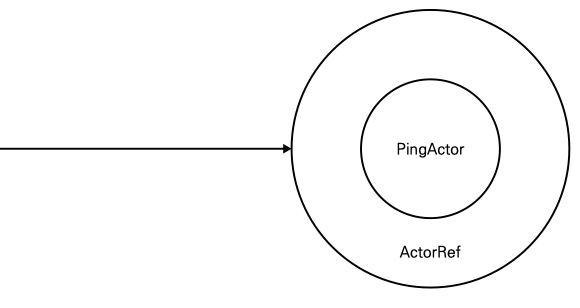
액터시스템은 props 에 따라 액터를 만들고,
그것을 ActorRef로 둘러싼 뒤 되돌려 준다.
[ 장소 투명성 ]
장소 투명성 : 액터가 물리적으로 어디에 존재하는지 알 필요가 없음
-> 오로지 ActorRef 를 가지고 작업을 수행하기 때문
모든 액터를 하나의 JVM 위에서 실행할 때는 별 의미 없지만
여러 개의 JVM 이 클러스터를 형성하는 클러스터링의 경우 위력을 보인다.
모든 코드가 ActorRef 를 대상으로 작성되었기 때문에 실제 액터의 물리적 장소를
클라이언트 코드에 아무 영향을 주지 않고 자유롭게 옮길 수 있다.
[ 메시지 전송 ]
일반적인 객체지향 프로그래밍에서는
'객체를 만든 다음 그 객체가 가지고 있는 메서드를 호출' 한다.
그러나 액터 세계에서는
액터를 만든 다음 그 액터에 메시지를 전송한다
ActorRef 는 tell 과 ask 라는 두 개의 API 를 제공한다.
우선 tell 메서드는 메시지 와 발신자 두 가지를 인수로 받아들인다.
첫 번째 인수인 메시지는 임의의 자바 객체(Object) 가 될 수 있다.
클래스를 정의할 때 특정 타입을 상속하지 않았다면
ActorRef 객체가 있을 때 tell 메서드를 사용해 어떤 타입의 객체라도 보낼 수 있다.
두 번째의 발신자 의 주소는 반드시 ActorRef 타입을 가져야 한다.
즉, 발신자는 어떠한 액터이다.
발신자 주소를 위해서는 보통 다음과 같은 네 가지 형태의 값이 사용된다.
-
getSelf() : 이 메서드 액터 자신의 ActorRef 객체를 리턴한다.
따라서 메시지를 보내는 액터 자신을 발신자로 정할 때 사용한다.
가장 일반적인 형태이다. -
getSender() : 이것은 현재 처리 중이 메시지를 보내 온 발신인의 주소를 다음 액터에게 그대로 포워드(forward) 할 때 사용한다.
액터 사이의 질의-응답 관계를 형성하려 할 때 주로 사용된다. -
어떤 특정 액터를 가리키는 ActorRef 객체가 있다면 그것을 발신자로 정할 수도 있다.
실제 발신인의 주소를 다른 액터의 주소로 변경한다는 점에서 getSender() 와 개념적으로 비슷하다. -
ActorRef.noSender() : 이 메서드는 개념적으로 null 에 해당하는 액터 주소를 리턴한다.
발신인 주소가 아무 의미가 없는 경우에 사용한다.
[ 메일 박스 ]
액터에 어떤 메시지를 전송하면 액터마다 가지고 있는 메일 박스에 저장된다.
여러 개의 액터가 하나의 메일 박스를 공유하는 경우도 있다.
액터의 메일박스를 염두에 두는 것은 메모리 사용량, 역류(back-pressure) 등을 고민할 때 뿐이고, 보통 메일박스는 애플리케이션 코드에서는 보이지 않는 투명한 존재이다.
이는 이벤트 큐, 디스패치 큐 드의 원리와 비슷하다.
전달되는 메시지가 메일박스에 차곡차곡 쌓이고, 액터는 그 메시지를 한 번에 하나씩 처리하는 것이다.
[ onReceive ]
액터시스템은 내부에 스레드풀을 보유하고 있다.
디스패처 라고 부르기도 한다.
액터시스템은 일정한 규칙에 따라 스레드를 액터에게 할당한다.
스레드가 할당된 액터는 메시지를 처리하고 스레드를 풀로 반납한다.
액터에 스레드가 할당되고 -> 메시지를 처리하고 -> 스레드를 풀에 반납하고 -> 스레드가 다른 액터에 할당된다.
액터는 디스패처에 의해서 스레드가 할당되어야만 동작을 수행할 수 있다.
그래서 아카의 디스패처는 수많은 액터를 대상으로 풀 내부에 존재하는 스레드를
최대한 공정한 방식으로 할당하기 위해 애쓴다.
어느 액터에 스레드가 할당되면 발생하는 일이다.
-
메일박스에서 메시지를 하나 꺼낸다.
-
액터의 onReceive 메서드를 호출하면서 메시지를 인수로 전달한다.
-
onReceive 의 동작이 완료된다.
-
스레드를 반납할 시간이 되었는지 확인한다.
-
시간이 되었으면 스레드를 반납하고 다음 순서를 기다린다.
-
아직 시간이 안 되었으면 메일박스에서 다음 메시지를 꺼내고 위 과정을 반복한다.
이러한 메시지 처리 방식 자체는 이해하는 것이 어렵지 않다.
하지만 여기에서 반드시 짚어야 하는 두 가지 사항이 있다.
어느 특정한 시점에서 보았을 때 액터의 onReceive 메서드를 호출하는 스레드는 반드시 1개로 국한된다.
디스패처가 하나의 액터에 2개 이상의 스레드를 동시에 할당하지 않기 때문이다.
이 덕분에 아카에서 멀티스레드 환경 문제를 고민하지 않아도 된다.
액터의 onReceive 메서드를 호출하는 스레드가 영원히 똑같은 것은 아니다.
하나의 시점에서 onReceive 를 호출하는 스레드는 반드시 1개로 국한되지만,
시점이 달라지면 똑같은 액터의 onReceive 를 실행하는 스레드가 얼마든 다른 스레드로 달라질 수 있다.
액터의 철학은 모든 것이 비동기적이고, 어느 것도 중단(blocking) 되지 않는다는 데 있다.
[ 액터 라이프 사이클 ]
모든 액터는 ActorSystem( 액터 시스템의 환경이나 문맥) 에 접근할 수 있는 context() 메서드를 포함하고있다.
ActorContext 는 해당 액터의 관점에서 보이는 ActorSystem 의 모습을 나타내는 객체라고 생각하면 된다.
모든 액터는 생성 - 재시작 - 멈춤 의 라이프사이클을 갖고있다.
액터의 재시작은 액터시스템에서 에러가 발생하여 ActorRef 가 내부에 저장된 액터 객체를 버리고
동일한 객체를 클래스의 생성자를 호출함으로써 액터를 새로 만드는 경우다.
액터의 라이프사이클 관련 메서드는 아래와 같다.
-
preStart : 생성자가 완료된 직후에 실행된다.
-
proStop : 액터의 라이프사이클이 완전히 종료하기 직전에 실행된다.
-
preRestart : 재시작이 이루어지기 직전에 실행된다.
-
postRestart : 재시작이 이루어진 직후에 실행된다.
