
DataBase란
- 여러 사람들이 공유하여 사용할 목적을 가지고 체계적으로 통합 및 관리하는 데이터들의 집합을 말합니다.
- DB의 설계가 중요한 이유
- DB를 잘 설계하면 DB를
효율적으로 관리할 수 있습니다. 효율적이라는 얘기는파급효과가 크며,데이터 품질과 관련되어 있으며,간결함(시스템 요구사항과 한계를 가장 명확하게 표현하는 도구)이 요구되는 DB설계입니다.
- DB를 잘 설계하면 DB를
데이터의 저장
- RAM은 휘발성 메모리로 RAM에 있는 데이터는 프로그램이 종료되면서 함께 사라집니다.
이처럼 휘발성을 지닌 데이터를 사라지지 않게 우리는 영속성을 부여합니다.
영속성은 아주 쉽게저장으로 이해할 수 있습니다. 데이터에 영속성을 부여하는 방식은파일로 보관하는 것과DB에 보관하는 것으로 나눌 수 있습니다.
파일저장
- 파일: 논리적인 데이터의 저장 단위를 파일이라고 부릅니다.
파일에 저장하는 방식은 다음의 문제점이 존재합니다.
- 파일을 실행하기 위한 별도의 독립적인 어플리케이션이 필요합니다.
- 데이터가 변경되면 응용 프로그램이 수정되어야 하는 종속성 문제가 발생합니다.
- 파일에서는 데이터의 검사가 불가능합니다.
- 이로인해 데이터의 중복이 발생할 수 있으며 무결성을 보장하기 힘들어 집니다.
- 데이터 무결성 = 데이터의 정확성 + 데이터의 일관성
- 이로인해 데이터의 중복이 발생할 수 있으며 무결성을 보장하기 힘들어 집니다.
DB의 특징
실시간 접근성 (Real Time Accessibility)
- 사용자가 질의를 요청하면 즉시 응답해 줍니다.
지속적인 변화 (Continuous Evolution)
- 삽입(Insert), 삭제(Delete), 갱신(Update)을 통해 데이터를 변화시킬 수 있으며, 이 과정에서 무결성이 회손되지 않습니다.
동시 공유 (Concurrent Sharing)
- 같은 내용의 데이터에 여러 사람이 동시에 접근할 수 있습니다.
내용에 대한 참조 (Content Reference)
- 데이터의 주소나 위치가 아니라 사용자가 요구하는 내용(데이터가 가지고 있는 값)에 따라 참조됩니다.
- 사용자가 데이터를 요청했을 때 주소가 아니라 값을 반환한다는 의미입니다.
데이터의 독립성
- 하위 단계의 데이터 구조가 변경되더라도 상위 단계에 영향을 미치지 않습니다.
DB모델
- DB모델이란 DB가 어떤 모양을 하고 있으며, 어떤 방식으로 데이터를 저장하고 있는지를 설명합니다.
계층형 모델 (Hierarchical model)
- hierarchy를 가지는 순서화된 트리 집합으로 DB를 구성했다는 의미입니다.
네트워크형 모델 (Network model)
- Graph구조를 기반으로 DB를 구성했다는 의미입니다.
관계형 모델 (Relational model)
관계라는 개념으로 DB를 구성했다는 의미입니다.- 2차원 테이블에 Attribute,Tuple,Schema와 같은 정보를 표현해 관계를 나타냅니다.
객체형 모델 (Object model)
- 데이터와 절차를 일체화 한 객체를 활용해 DB를 구성했다는 의미입니다.
객체-관계형 모델 (Object-relational model)
- 관계형 모델과 객체형 모델을 결합한 형태로 DB를 구성했다는 의미입니다.
오늘날 가장 많이 사용되는 DataBase는 Relational DataBase입니다.
앞의로의 설명에는 RDB를 전재로 하는 부분이 많음을 인지하고 읽어주시면 감사하겠습니다.
DBMS란
- DataBase Management System의 약자로 데이터베이스를 관리하는 시스템을 의미합니다.
RDBMS란
- RDMBS는 여러 DB 중 관계형 데이터베이스를 관리하기 위해 만들어진 시스템을 말합니다.
- 한번쯤 들어봤을 Oracle, MySQL, PostgreSQL등이 모두 RDBMS에 해당합니다.
SQL
- Structured Query Language의 약자로 RDBMS에서 자료를 관리 및 처리하기 위해 설계된 언어입니다.
NoSQL
- Not-Only SQL로 SQL기능 이외의 추가적인 기능도 제공해주겠다는 의미를 이름에서 확인할 수 있습니다.
- NoSQL DB는 기존의 관계형 데이터베이스보다 융통성 있는 데이터 모델을 사용하며, 데이터의 저장과 검색에 특화된 매커니즘을 제공합니다.
- NoSQL의 예시로는 MongoDB가 있습니다.
- 저장되는 데이터의 구조에 따라
Key Value DB,Document DB,Wide Column DB,Graph DB로 종류가 나뉩니다. - NoSQL은 Scale-out을 지원해 확장성 부분에서 RDB보다 뛰어나다는 강점이 있습니다.
- Scale-out: 서버의 수를 늘려 성능을 향상시키는 방법
인덱스
- 인덱스란 데이터베이스 테이블의 검색 속도를 높이기 위한 자료구조를 말합니다.
- 인덱스는 대용량 데이터에서 원하는 데이터를 빠르게 조회하기 위해 (select쿼리문의 성능을 향상시키기 위해) 사용됩니다.
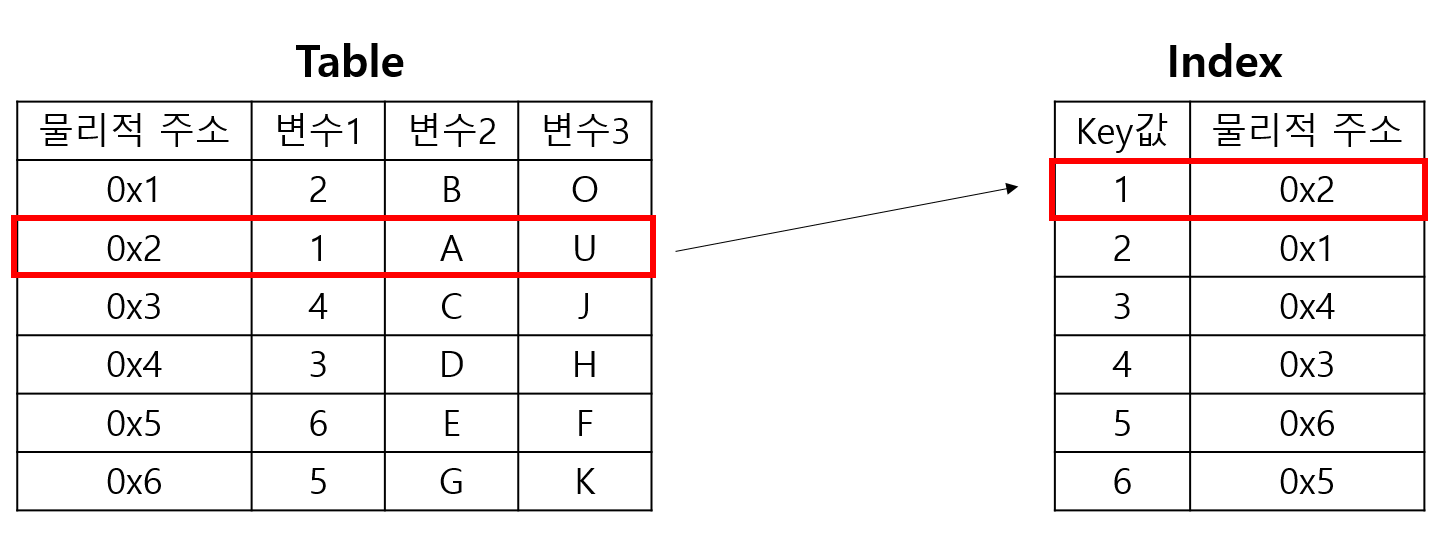
- 인덱스 생성을 명령하면 해당 컬럼의 데이터를
정렬한 후별도의 메모리 공간에 (해당 컬럼의 값, 물리적 주소)의 쌍을 저장합니다.
- 인덱스를 설정하는 방법(MySQL)
CREATE INDEX 인덱스명 ON 테이블명(컬럼명);
DROP INDEX 인덱스명 ON 테이블명;- 인덱스는 Where절에서 활용되어야 그 효과를 볼 수 있습니다.
Where절이 사용되지 않는 SELECT문이나, 인덱스 컬럼을 이용하지 않는 Where절은 인덱스의 효과를 얻기 힘듭니다.
인덱스의 장단점
장점
- 데이터 검색 속도와 테이블 성능이 향상됩니다.
- index scan은 일반적으로 full table scan보다 속도가 빠릅니다.
단점
- 인덱스도 하나의 데이터베이스 객체이기 때문에 저장하기 위한 공간이 필요합니다.
- 잘못 사용하면 오히려 검색 기능이 저하될 수 있습니다.
- delete,update가 빈번한 테이블에서는 index가 효율적이지 못합니다.
delete와 update에서는 기존 인덱스를 삭제하지 않고 '사용하지 않음'처리를 해두기 때문에 비효율이 발생하게 됩니다.
- delete,update가 빈번한 테이블에서는 index가 효율적이지 못합니다.
인덱스를 사용하면 좋은 경우
- 규모가 큰 테이블에 적합합니다.
- 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 작업이 자주 발생하지 않는 컬럼에 설정하면 좋습니다.
- WHERE나 ORDER BY, JOIN 등이 자주 사용되는 컬럼에 사용하면 좋습니다.
- 인덱스를 부여할 때 진행되는
정렬에 의해 해당 작업들의 성능이 개선될 수 있습니다.
- 인덱스를 부여할 때 진행되는
- 데이터의 중복도가 낮은 컬럼에 사용하면 좋습니다.
인덱스로 선택하기 적절한 Column
- 값들이 유니크하며(Cardinality), 집합을 잘 대표하는(Selectiviy) 컬럼을 index로 설정하는 게 좋습니다.
인덱스의 자료구조
해시 테이블
- 해시 테이블은 key와 value를 한 쌍으로 데이터를 저장하는 자료구조입니다.
- 해시 충돌이라는 변수가 존재하지만, 평균적으로 O(1)의 매우 빠른 시간만에 원하는 데이터를 탐색할 수 있는 자료구조입니다.
- 해시 테이블은 인덱스로 잘 사용되지 않습니다.
그 이유는 해시의 성능이 등호(=)연산에 최적화되어 있기 때문입니다.
하지만 DB에서는 부등호(<,>)연산이 자주 사용되기 때문에 정렬된 형태가 더 효율적입니다.
해시 테이블 내부의 데이터들은 정렬되어 있지 않기 때문에 부등호 연산을 빠르게 수행할 수 없습니다.
B-Tree
- B-Tree는 binary tree와 기본 구조는 유사합니다. B-Tree는 binary tree와 다르게 한 노드에 자식 노드가 2개 이상일 수 있습니다.
- B-Tree는
균형 트리로 루트에서 리프까지의 거리가 일정합니다. - B-Tree는 어떤 값에 접근할 때 걸리는 시간이 모두 동일한
균일성의 특성을 지니고 있습니다.- 하나의 값에 도달하는 데 걸리는 시간은 O(logN)입니다.
- B-Tree는 테이블의 갱신(INSERT/UPDATE/DELETE)이 반복되면 조금씩 균형이 깨지게 됩니다.
- 어느정도는 자동으로 균형을 회복하지만, 갱신이 빈번하다면 균형을 맞춰주는 작업이 추가로 필요합니다.
B+Tree
- 오직 Leaf노드에만 key와 data를 저장하고, 리프노드끼리 LinkedList의 형태로 연결되어 있습니다.
- Branch노드에는 key값만 담아둡니다.
- 리프노드 이외에는 data가 없기 때문에 더 많은 메모리를 확보하고 이를 통해 더 많은 key를 수용할 수 있습니다.
- 하나의 노드에 더 많은 key들을 담을 수 있기 때문에 트리의 높이가 낮아집니다.
- Full Scan을 해야할 때 리프노드만 선형탐색하면 됩니다.
Composite Index
- 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 걸 의미합니다.
- WHERE절에서 AND연산으로 검색이 많이 되는 경우 우수한 성능을 보입니다.
Clustered Index와 Non-Clustered Index
Clustered Index
-
데이터와 인덱스가 합쳐져 있는 인덱스 입니다.
-
새로운 값이 들어가기 위해서는 기존의 값들이 한 칸씩 자리를 비켜줘야 합니다.
-
pk가 생성되면 clustered index가 자동으로 생성됩니다.
clustered index가 pk는 아니지만, clustered index는 pk와 밀접한 관련이 있습니다. -
특징
- 테이블 당 1개만 존재합니다.
- pk를 생성하면 자동으로 clustered index가 생성됩니다.
- 데이터가 정렬된 상태로 존재합니다.
-
인덱스를 설정하는 방법(MySQL)
CREATE CLUSTERED INDEX 인덱스명 ON 테이블명(컬럼명);Non-Clustered Index
- 데이터랑 직접적으로 연결되어 있지 않고 간접적으로 참조하는 인덱스 입니다.
- 특징
- Secondary Index(보조 인덱스)라고도 합니다.
- 테이블 내에 여러 개가 존재할 수 있습니다.
- Unique 제약조건으로 컬럼을 생성하면 자동으로 생성됩니다.
- 데이터가 정렬되어 있지 않습니다.
- 추가적인 저장 공간이 필요합니다.
- Clustered Index보다 약간 느리지만, Clustered Index보다 Insert,Update,Delete의 부하가 적습니다.
- 인덱스를 설정하는 방법(MySQL)
CREATE NONCLUSTERED INDEX 인덱스명 ON 테이블명(컬럼명);식별 관계와 비식별 관계
식별 관계
- 부모 테이블의 PK가 외래키로 사용되면서 자식 테이블의 PK에 포함되는 경우입니다.
비식별 관계
- 부모 테이블의 PK가 외래키로 사용되지만 자식 테이블의 PK에 포함되지 않는 경우입니다.
Cardinality
- 어떤 컬럼에 인덱스를 설정했을 때 유리한지를 나타내는 척도입니다.
- 데이터의 중복이 낮을수록(데이터 원소의 종류가 많은수록) 인덱스 설정시 유리합니다.
DISTINCT(컬럼)을 통해 cardinality를 구할 수 있습니다.
트랜잭션
- 트랜잭션이란 데이터베이스의 상태를 변환시키기 위해 수행하는 작업의 단위를 의미합니다.
- SQL(SELECT,INSERT,DELETE,UPDATE)을 통해 DB에 접근하는 작업이 하나의 트랜잭션이 될 수 있습니다.
- 하나의 SQL문장이 반드시 하나의 트랜잭션을 의미하는 건 아닙니다. 개발자의 정의에 의해 작업의 단위, 즉 트랜잭션은 달라집니다.
- 하나의 트랜잭션은 Commit되거나 Rollback됩니다.
- Commit연산은 해당 트랜잭션의 작업이 성공적으로 완료되었음을 알려줍니다.
- Rollback연산은 해당 트랜잭션이 행한 모든 연산을 취소합니다.
트랜잭션의 특성(ACID)
원자성(Atomicity)
- 트랜잭션의 모든 연산들은 정상적으로 수행 완료되거나 아니면 전혀 어떠한 연산도 수행되지 않은 상태를 보장해야 합니다. All or nothing
일관성(Consistency)
- 트랜잭션 완료 후에도 데이터베이스가 일관된 상태로 유지되어야 합니다.
독립성(Isolation)
- 하나의 트랜잭션을 실행하면서 변경한 데이터는 이 트랜잭션이 완료될 때까지 다른 트랜잭션이 참조하지 못합니다.
지속성(Durability)
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 합니다.
트랜잭션의 상태

[이미지 출처: https://gmlwjd9405.github.io/2017/10/01/basic-concepts-of-development-db.html]
활동(Active)
- 트랜잭션의 연산들이 정상적으로 실행되고 있는 상태입니다.
부분 완료(Partially Committed)
- 트랜잭션이 마지막 연산까지 실행했지만 아직 Commit되지 않은 상태입니다.
실패(Failed)
- 오류가 발생해 트랜잭션이 중단된 상태입니다.
완료(Committed)
- 트랜잭션이 성공적으로 종료되고 Commit연산까지 완료한 상태입니다.
철회(Aborted)
- 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태입니다.
트랜잭션 격리수준(Transaction Isolation Level)
- 다른 트랜잭션에서 변경한 데이터를 어느 수준으로 볼 수 있는가를 나타냅니다.
격리수준이 필요한 이유
- DB의 ACID를 보장하는 작업은 효율성과 Trade-off관계에 있습니다. 이러한 Trade-off사이에서 본인의 상황에 맞는 최적의 상태를 보장하기 위해 격리수준은 여러 단계로 나눠져 있습니다.
격리수준 역시 동시성과 무결성 사이의 Trade-off가 발생합니다.
- 격리수준을 높이면 무결성이 높아지지만 동시성이 떨어지고,
격리수준을 낮추면 동시성이 높아지지만 무결성이 떨어집니다.
격리수준 단계
들어가기 전에) Lock에 대해
Lock은 트랜잭션 처리의 순차성을 보장하기 위해 동시성을 제어하는 행위입니다.
- Shared Lock(Read Lock, 공유락): 데이터를 읽을 때 사용하는 Lock입니다. 같은 Shared Lock끼리 동시에 접근을 허용합니다.
- Shared Lock이 걸려있어도 추가적인 읽기를 수행할 수 있습니다.
- Exclusive Lock(Write Lock, 베타락): 데이터를 변경할 때 사용하는 Lock입니다. Lock이 해제되기 전까지 다른 트랜잭션의 접근이 불가능합니다.
- Exclusive Lock이 걸려있으면 추가적인 읽기와 쓰기가 모두 불가능합니다.
Read Uncommitted (레벨 0)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리지 않습니다.
즉, 트랜잭션에서 처리중이거나 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽을 수 있습니다. - DB의 일관성을 유지할 수 없습니다.
- Dirty Read, Non-repeatable Read, Phantom Read가 발생할 수 있습니다.
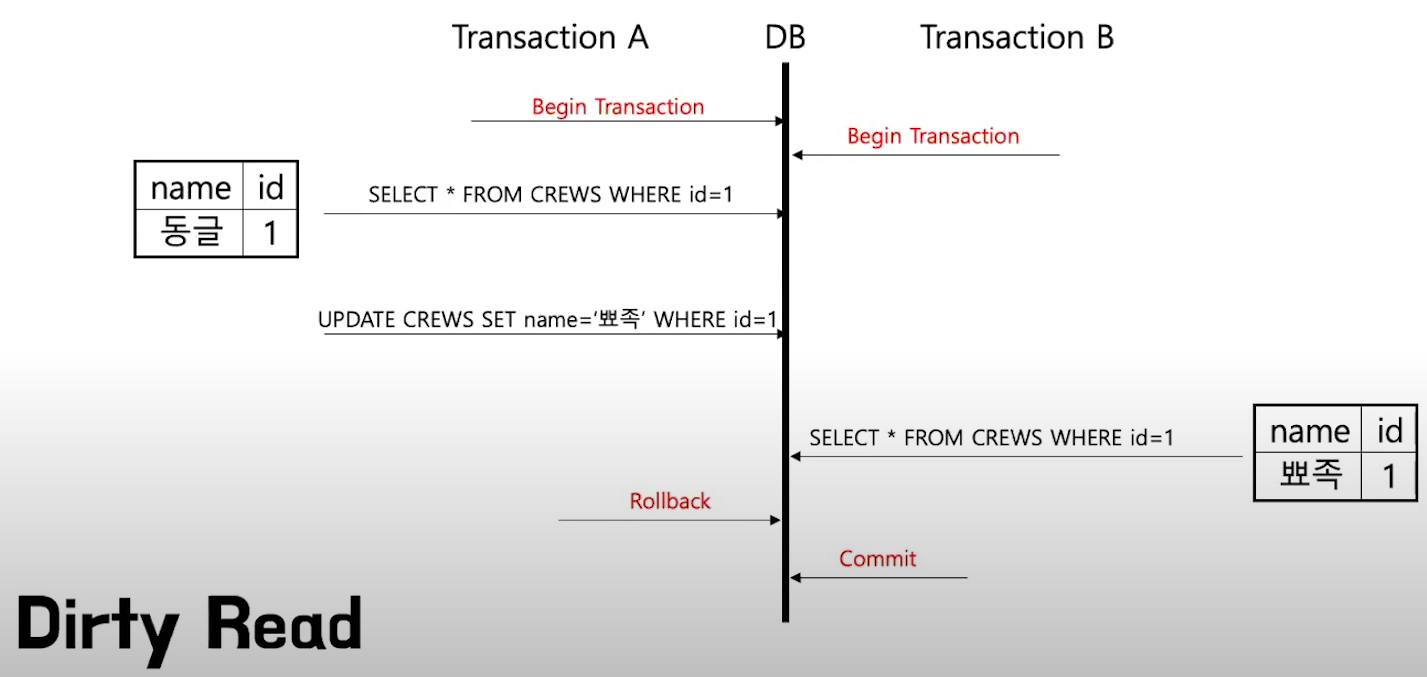
[Dirty Read]
A트랜잭션에서 데이터를 수정한 뒤 커밋을 하지 않았어도, B트랜잭션은 수정된 내용으로 데이터를 볼 수 있습니다. (dirty read)
A트랜잭션이 Commit이 아닌 Rollback을 하게되면 B트랜잭션은 잘못된 데이터를 가지고 있게 됩니다.
[이미지 출처: [10분 테코톡] 🌼 예지니어스의 트랜잭션]
Read Committed (레벨 1)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock을 겁니다.
여러 트랜잭션이 동시에 데이터를 수정하는 건 불가능 하지만, 여러 트랜잭션이 동시에 데이터를 읽는 건 가능합니다. - 해당 트랜잭션에서 Rollback 혹은 Commit이 완료되었다면 다른 트랜잭션이 변경된 데이터를 볼 수 있습니다.
하지만 해당 트랜잭션에서 Rollback 혹은 Commit을 완료하지 않았다면 다른 트랜잭션에서는 Undo영역에 있는 데이터를 보게 됩니다. - Commit이 이루어진 트랜잭션에만 조회할 수 있다는 의미입니다.
- Non-repeatable Read, Phantom Read가 발생할 수 있습니다.
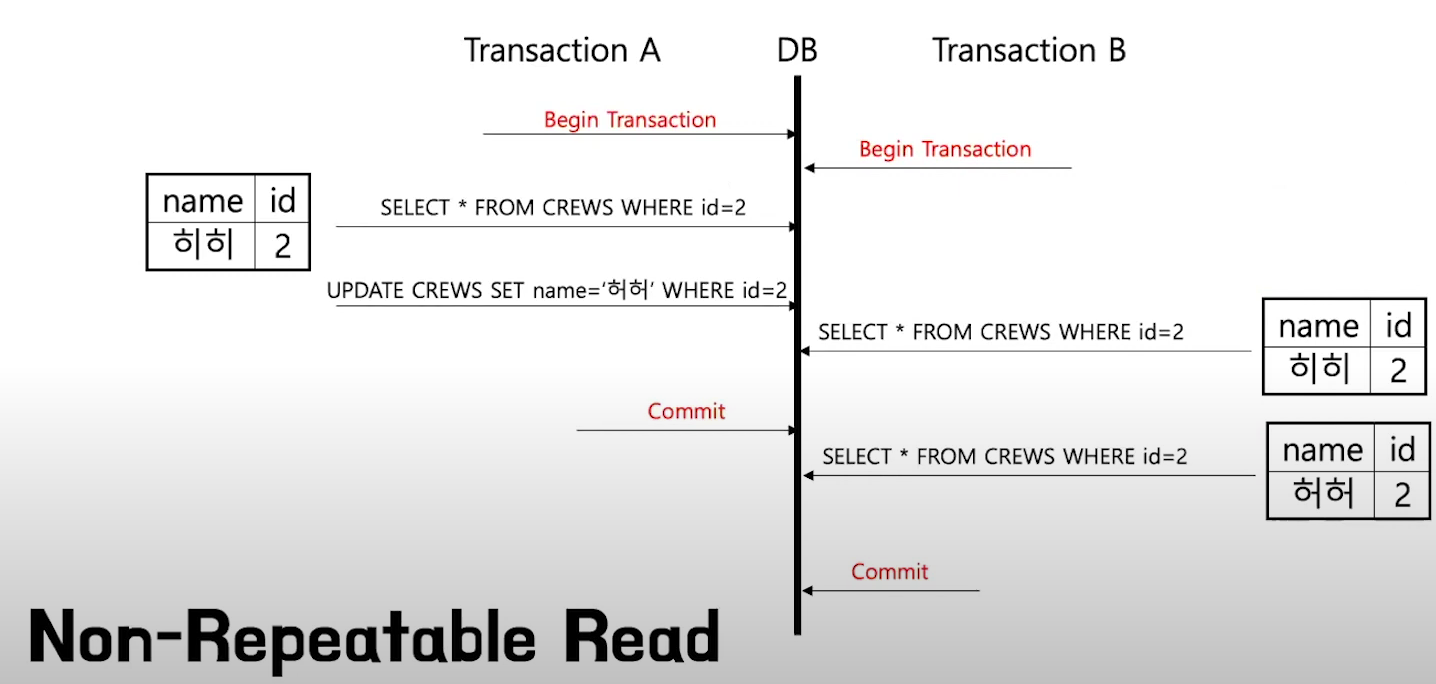
[Non-repeatable Read]
A트랜잭션에서 데이터를 수정한 뒤 커밋을 하지 않으면, B트랜잭션은 수정된 데이터가 아닌 수정 이전의 데이터가 보이게 됩니다.
B트랜잭션 입장에서는 동일한 행동을 했지만 다른 결과를 얻게 될 수 있습니다.
A가 수정커밋을 하기 전에 SELECT를 했다면 수정 전의 데이터를 얻게 되지만,
A가 수정커밋을 한 후 SELECT를 했다면 수정 후의 데이터를 얻게 됩니다.
[이미지 출처: [10분 테코톡] 🌼 예지니어스의 트랜잭션]
Repeatable Read (레벨 2)
- 모든 데이터에 Shared lock을 겁니다.
- 트랜잭션이 시작되기 전에 커밋된 내용만 조회할 수 있습니다.
- 트랜잭션이 시작되는 시점에 DB를 사진을 찍고, 그 사진을 보면서 작업을 한다고 생각하면 됩니다.
- MVCC(Multi-Version Concurrency Control)을 통해 구현할 수 있습니다.
최초에 5번 트랜잭션이 데이터 조회했을 때 그 값으로 A를 얻습니다.
10번 트랜잭션이 해당 데이터를 A에서 B로 변경했습니다.
5번 트랜잭션이 다시 해당 데이터를 조회하면 10번이 업데이트한 B가 아닌 undo영역에 있는 A를 얻습니다.
- Phantom Read가 발생할 수 있습니다.
- Phantom Read는 한 트랜잭션이 같은 쿼리를 두 번 실행했는데, 첫 번째 쿼리에서 없던 값이 두 번째 쿼리에서 나타나는 현상을 말합니다.
- INSERT를 수행할 때 발생하는 현상입니다.
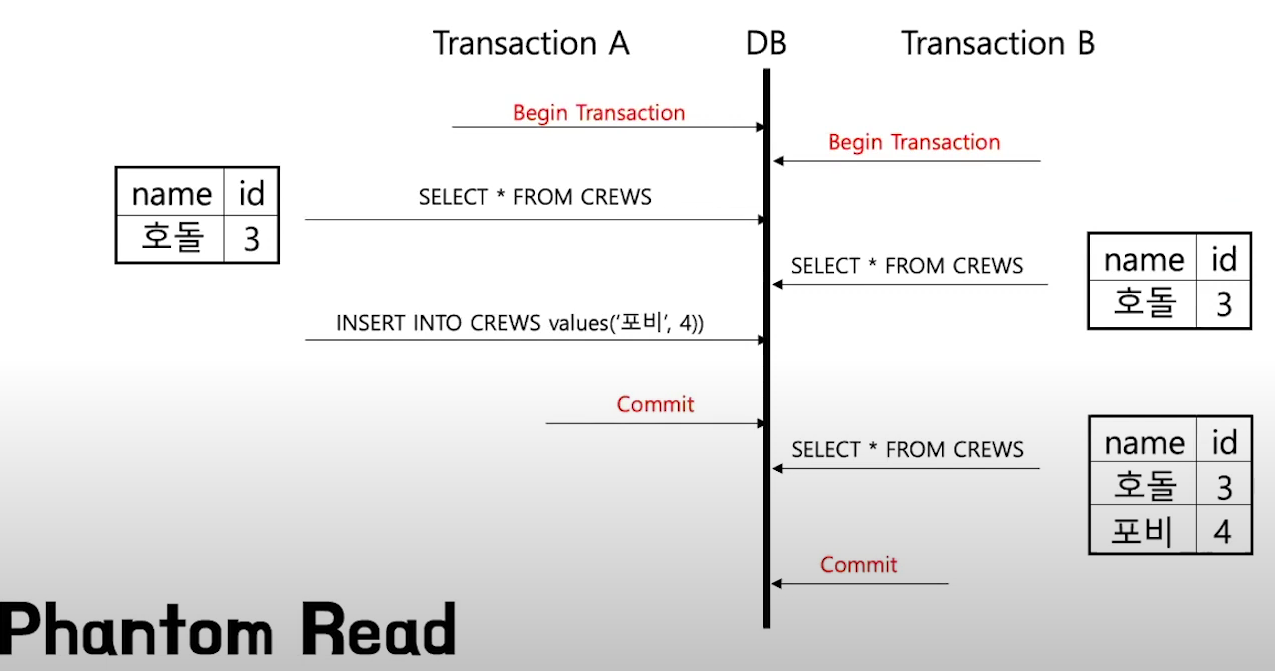
[Phantom Read]
DB에 아무런 데이터가 없습니다.
1번 트랜잭션에서 SELECT를 실행하면 0개의 데이터가 출력됩니다.
2번 트랜잭션에서 값을 추가한 뒤 Commit까지 실행합니다.
1번 트랜잭션에서 SELECT를 실행하면 1개의 데이터가 출력됩니다. (자신이 만든 적 없는 데이터가 보이게 됩니다)
[이미지 출처: [10분 테코톡] 🌼 예지니어스의 트랜잭션]
Serializable (레벨 3)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock을 겁니다.
- 다른 사용자는 해당 영역의 데이터를 수정하거나 읽을 수 없습니다.
- 가장 안전하지만 가장 많은 비용이 발생하는 격리수준입니다.
- Serializable하지 않을 때 발생할 수 있는 문제점들
- Dirty Read(Lv0) - 아직 커밋되지 않은 수정 중인 데이터를 다른 트랜잭션이 읽을 수 있다.
- Non-Repeatable Read(Lv0,Lv1) - 한 트랜잭션에서 같은 쿼리를 두번 실행하는 데 그 결과가 다르다.
- Phantom Read(Lv0,Lv1,Lv2) - 데이터를 읽을 때 첫번째 쿼리에 없던 값이 두번째 쿼리에서 발견된다.
한 트랜잭션 내에서 같은 쿼리문이 실행되었음에도 불구하고 조회 결과가 다른 경우를 뜻합니다.
[요약]
Read Uncommitted : 아무런 Lock을 걸지 않은 상태
Read Committed : Commit 완료된 데이터만 조회 가능
Repeatable Read : 트랜잭션 시작 전에 Commit된 내용만 조회 가능
Serializable : 다른 트랜잭션과 완전히 분리
정규화
- 테이블간의 중복을 최소화하기 위한 작업이 바로 정규화입니다.
- 데이터의 중복을 없애면 무결성을 유지할 수 있고 DB자원의 소모값도 줄어듭니다.
- 또한 데이터가 중복되어 존재하면 여러 이상(anomalies)이 발생합니다.
- 데이터를 insert,delete,update하려할 때 중복된 값 모두에게 적용해야 하는지, 중복된 값 중 몇번째에 적용해야 하는지를 알 수 없습니다.
제1 정규화
- 테이블의 Column이 하나의 값(Atomic Value)만 가지도록 만듭니다.
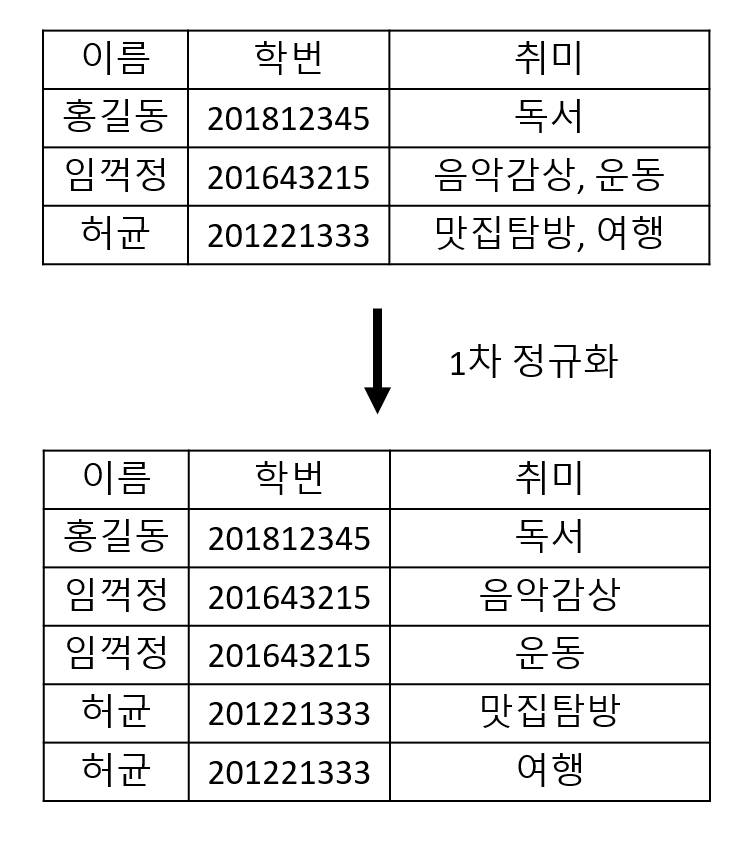
제2 정규화
- 제1 정규화를 진행한 상태에서
완전 함수 종속적이도록 테이블을 분해합니다.
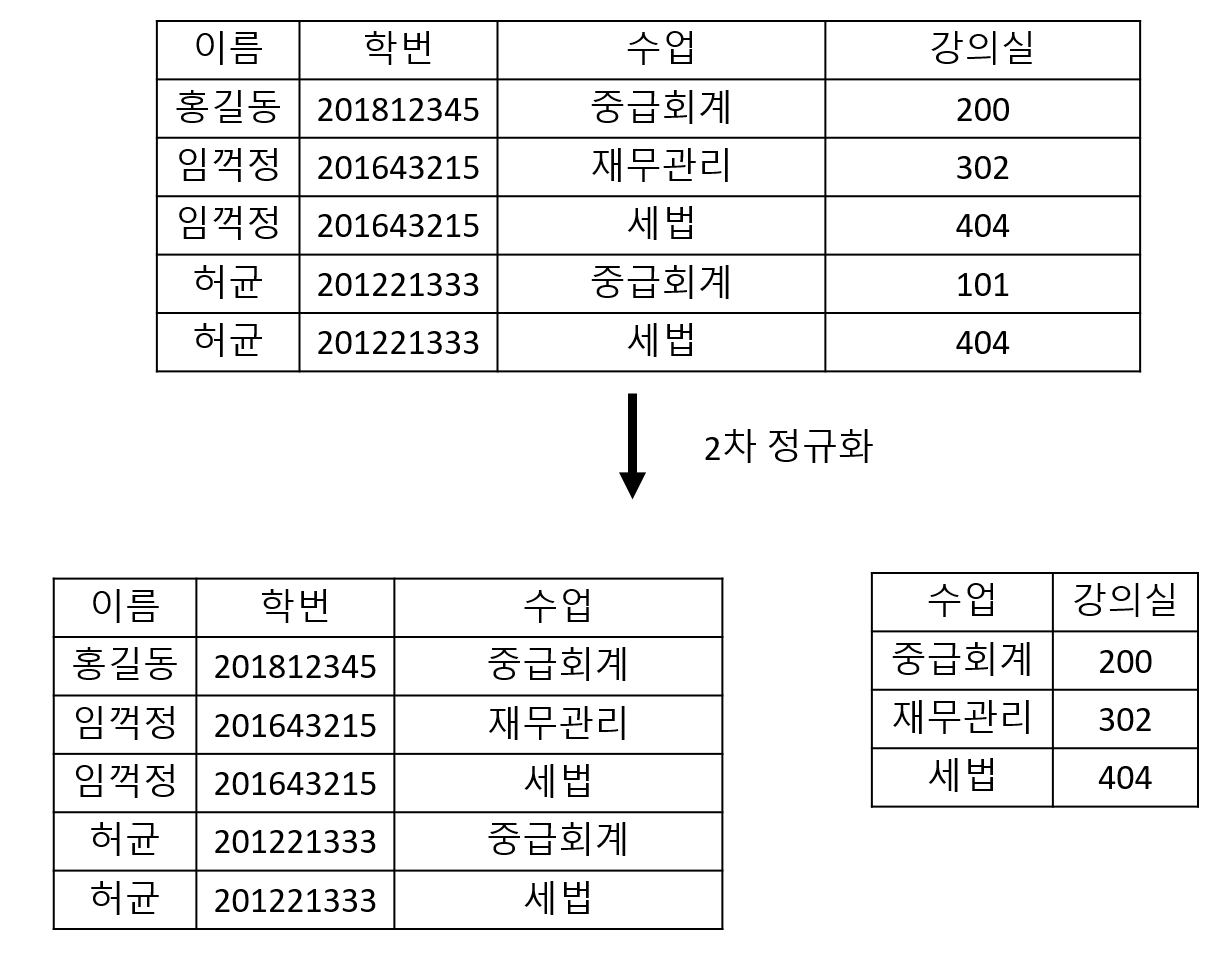
제3 정규화
- 제2 정규화를 진행한 상태에서
이행적 종속적이지 않도록 테이블을 분해합니다.- A->B, B->C이면서 A->C이면 이행적 종속적이라고 말합니다.
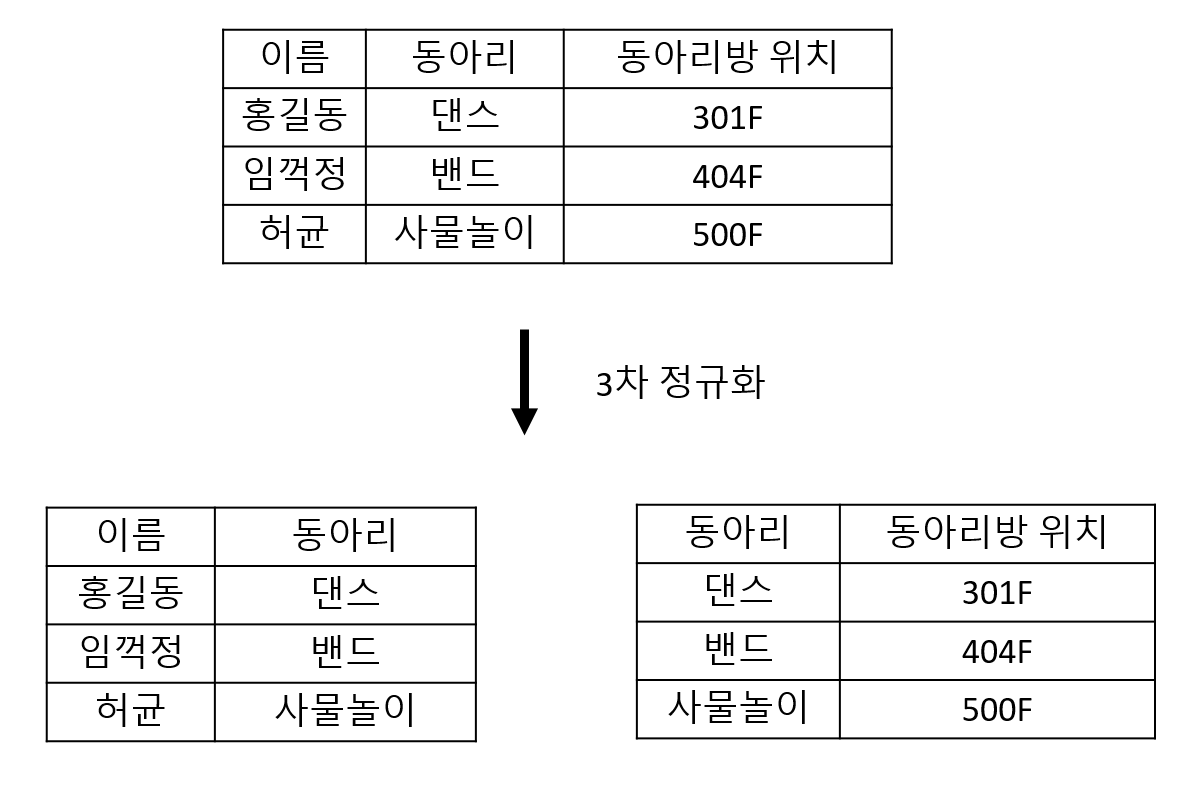
학생이름으로 동아리를 알 수 있고, 동아리를 통해 동아리방의 위치를 알 수 있습니다. 또한 학생이름을 통해 자신의 동아리 위치도 알 수 있습니다.
만약 3차 정규화를 실행하지 않았을 때 길동이가 사물놀이 동아리에 들어간다면 동아리방 위치도 같이 변경해 줘야 합니다.
하지만 3차 정규화를 실행한 상태에서는 길동이의 동아리 값만 바꾸면 동아리방 위치는 자동으로 바뀐 값을 얻어올 수 있습니다.
BCNF 정규화
- 제3 정규화를 진행한 상태에서
모든 결정자가 후보키가 되도록테이블을 분해합니다.
* 후보키가 여러개인 경우 후보키마다의 테이블을 생성하는 걸 의미합니다.
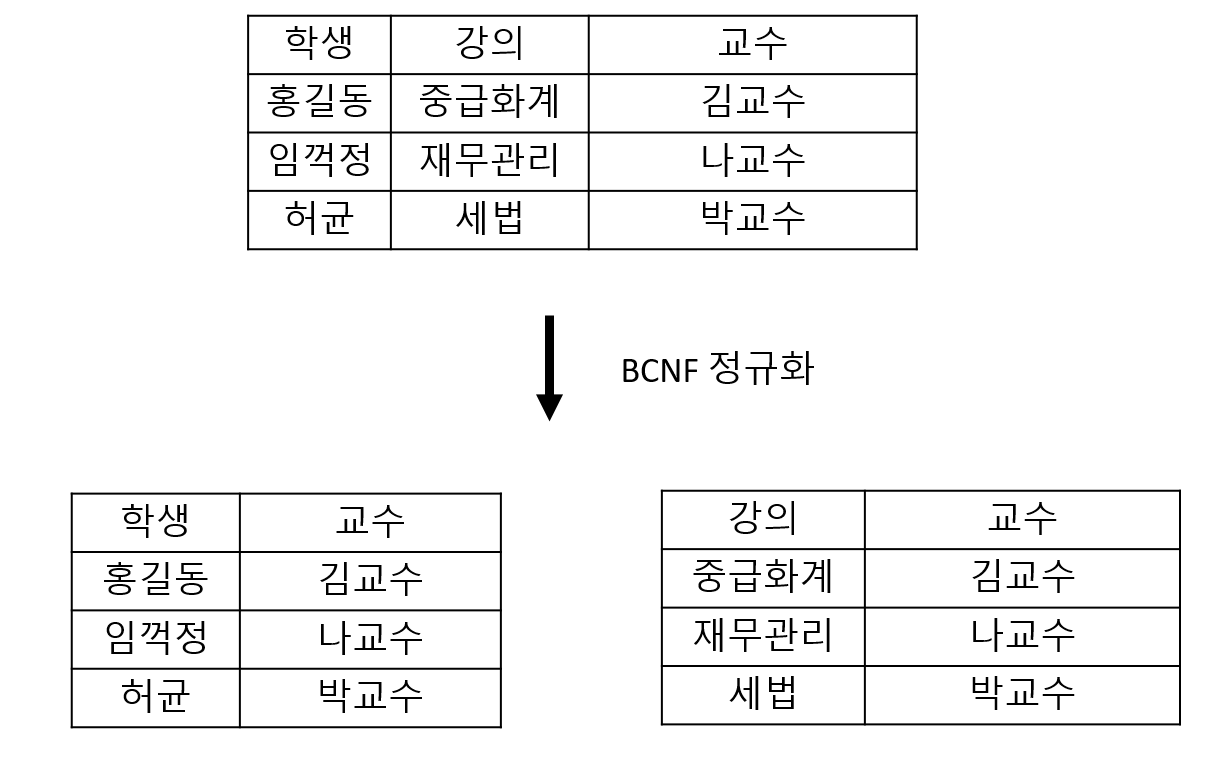
학생과 강의에 의해 교수가 결정되고 있으면서 교수를 통해 강의가 결정되고 있다.
역정규화
- 정규화는 데이터의 원자성을 보장하지만 테이블을 분리하기 때문에 많은 JOIN연산을 발생시킵니다.
JOIN연산에 대한 비용을 줄이기 위해 데이터의 중복을 허용하고 다시 테이블을 합치는 과정을 역정규화라고 합니다. - 즉 역정규화란 데이터베이스의 성능 향상을 위해 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법입니다.
대용량 데이터
- 데이터는 디스크보다 메모리에서 처리하는 게 더 효율적입니다. 하지만 데이터의 용량이 커져서 메모리에 올리지 못하게 되면 우리는 디스크로의 접근을 시도할 것이며 그로 인해 성능이 저하될 겁니다.
대용량 데이터 처리 방법
DB 확장시키기
- Scale Up: 고성능의 부품이나 서버로 교체합니다.
- Scale Out: 분산처리가 가능한 상태에서 여러 대의 서버를 추가합니다.
RDB대신 NoSQL사용하기
- RDB는 ScaleOut을 통한 확장이 쉽지 않습니다.
- RDB는 데이터 사이의 Relation이 핵심인데 잘못 분산하면 Relation이 소실될 수 있기 때문입니다.
- NoSQL은 비정형 데이터를 처리하기 위해 만들어졌습니다.
분산처리를 전제로 한 DB이기 때문에 RDB보다 대용량 데이터 처리에 유리합니다.
대용량 트래픽
- 여러 사람이 DB에 데이터를 요청하는 경우 어떻게 대응할 수 있을까요?
분산처리
Clustering
- DB서버가 다운되는 것을 대비하기 위해 나온 개념입니다.
- Clustering은 여러개의 DB서버를 둡니다.
- 하나의 DB서버가 중단되어도 나머지 서버에 의해 서비스를 지속적으로 제공할 수 있습니다.
- Active - Active 방식은 모든 DB서버를 실제 작동하는 상태로 둡니다.
- 하나의 DB storage를 공유하기 때문에 병목이 발생할 수 있습니다.
- Active - Standby 방식은 실제로 동작하지 않는 여분의 서버를 둡니다.
- 비용적인 이점이 있지만 Active상태의 서버DB에 문제가 생겼을 때 Standby서버를 구동하기 까지의 시간이 소요됩니다.
Replication
- 두 개의 이상의 DBMS를 Source와 Replica로 나눠서 동일한 데이터를 저장하는 방식입니다.
- Source에서는 쓰기만 진행하고 Replica에서 읽기를 진행해 효율성을 높이는 방법입니다.
- Scale Out 이외에도 데이터 백업, 데이터 분석, 데이터의 지리적 분산(미국본사 넷플릭스의 한국서버 같은 느낌)을 위해 Replication을 진행합니다.
- MySQL의 Replication은 Binary log를 기반으로 구현되어 있습니다.
- 바이너리 로그란 서버에서 발생하는 모든 변경사항을 별도의 로그 파일에 순서대로 저장한 것입니다.
- Clustering은 DB Server의 다운을 대비했다면 Replication은 DB Storage의 다운을 대비하기 위한 기술이라고 할 수 있습니다.
파티셔닝(Partitioning)
- 커다란 table을 작은 partition단위로 나누어 관리하는 방법입니다.
- 필요한 부분만 Scan해 성능이 좋아지지만, table에 대한 JOIN 비용이 증가하는 단점이 있습니다.
샤딩(Sharding)
- DB에 데이터가 너무 많아져서 검색이 느려지는 걸 해결하기 위해 나온 개념입니다.
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법입니다.
- 수평 파티셔닝이 곧 샤딩입니다.
기타
In-memory DB vs Disk-base DB
- In-memory: 메모리에 데이터를 저장하는 방식입니다. 모든 데이터가 디스크에 올라온 상태이기 때문에 Disk-base방식보다 더 빠릅니다. 하지만 영속성이 보장되지 않으며 저장 공간이 한정적이라는 단점이 존재합니다.
- Disk-base: 디스크에 데이터를 저장하는 방식입니다. 디스크의 데이터를 페이지 단위로 메모리에 가져오는데 페이지에 원하는 데이터가 없다면 계속해서 페이지를 불러와야 합니다.
참고해서 더 추가할 내용
출처
- https://edu.goorm.io/learn/lecture/15413/%ED%95%9C-%EB%88%88%EC%97%90-%EB%81%9D%EB%82%B4%EB%8A%94-sql/lesson/767683/sql%EC%9D%B4%EB%9E%80
- https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4_%EB%AA%A8%EB%8D%B8
- https://www.oracle.com/kr/database/what-is-database/
- https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4
- https://ko.wikipedia.org/wiki/%EA%B4%80%EA%B3%84%ED%98%95_%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4
- https://gmlwjd9405.github.io/2017/10/01/basic-concepts-of-development-db.html
- https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=skout123&logNo=50147360337
- https://rebro.kr/167
- https://zorba91.tistory.com/293
- https://mangkyu.tistory.com/96
- https://jwprogramming.tistory.com/47
- https://coding-factory.tistory.com/216
- https://ilerlemek.tistory.com/78
- https://jhkang-tech.tistory.com/210
- https://mommoo.tistory.com/62
- https://joont92.github.io/db/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98-%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80-isolation-level/
- https://nesoy.github.io/articles/2018-02/Database-Replication
- https://2kindsofcs.tistory.com/40
- https://www.youtube.com/watch?v=95bnLnIxyWI
- https://www.youtube.com/watch?v=y42TXZKFfqQ
- https://hleee.medium.com/%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80-3287d4bcc64d
- https://www.youtube.com/watch?v=e9PC0sroCzc
