Redis는 Single Thread임에도 불구하고 어떻게 작업을 빨리 처리할까

Redis는 왜 빠를까?
Redis는 MySQL 및 Orcale과 같은 RDBMS, 그리고 MongoDB와 같은 NoSQL보다 읽기 및 쓰기 속도가 빠릅니다. 그리고 Redis가 왜 빠른지에 대해 아래와 같은 이유를 얘기합니다.
- 메모리 기반 저장소
- 간단한 데이터 구조 및 효율적인 알고리즘
- Multiplexing과 Event Loop System
1. 메모리 기반 저장소
CPU를 기준으로 디스크보다 RAM이 더 가까운 곳에 위치합니다. 덕분에 CPU는 가까운 RAM에 접근하는 속도가 멀리 있는 디스크에 접근하는 것보다 빠릅니다. 또한 CPU는 디스크에 직접 접근할 수 없기 때문에 디스크의 데이터를 사용하려면 데이터를 RAM에 올리는 I/O작업이 필요합니다.
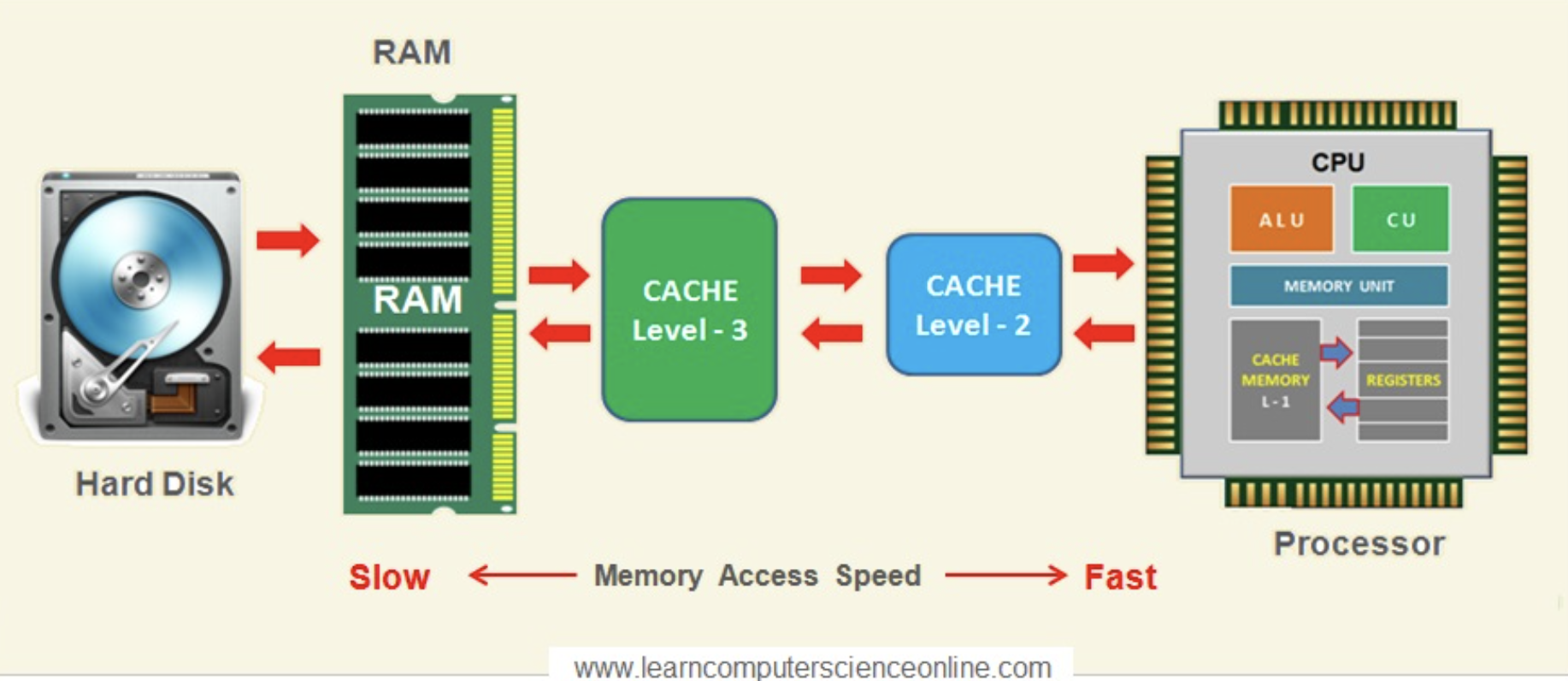
이런 이유로 메모리 기반 저장소인 레디스는 디스크 기반의 다른 저장소보다 빠른 데이터 읽기 및 쓰기가 가능합니다.
2. 간단한 데이터 구조 및 효율적인 알고리즘
Redis는 List, (Sorted) Set, Hash와 같은 자료구조를 제공하며 각 자료구조에 맞는 효율적인 알고리즘을 사용합니다.
예시로 Redis의 Sorted Set은 Skip List 알고리즘을 사용해 B-Tree기반의 Sorted Set보다 더 빠른 범위 조회 기능을 제공합니다.
3. Multiplexing과 Event Loop System
개인적으로 Multiplexing과 Event Loop System은 '단순히 Redis가 왜 빠른지에 대한 이유'와는 거리가 조금 있다고 생각하는데, 이에 대해 얘기해 보겠습니다.
Redis와 Single Thread
Redis는 Single Thread로 명령어를 처리합니다.
Redis 6.0버전부터 Multi Thread가 도입됐지만 이는 클라이언트의 요청을 읽고 쓰는 작업에 대한 부분이고, 명령어를 처리하는 부분은 여전히 Single Thread로 구성되어 있습니다.
어떤 작업을 처리하냐에 따라 다르지만, 일반적으로 병렬처리가 가능한 Multi Thread가 Single Thread보다 빠른 경우가 많습니다. 따라서 레디스가 정말 빠른 처리속도만을 보장하려 했다면 명령어 처리 역시 Single Thread가 아닌 Multi Thread로 처리하도록 설계했을 수도 있다고 생각합니다.
하지만 Redis는 Single Thread로 명령어를 처리합니다. Single Thread인 덕분에 동시성 문제를 처리하기 위해 락과 같은 복잡한 개념을 사용할 필요 없이 간단히 시스템을 설계 및 구현할 수 있었습니다. 대신 Single Thread이기 때문에 I/O와 같이 시간이 오래 걸리는 작업이 많아지면 이를 처리하는 동안 CPU가 대기하게 되는 문제가 발생할 수도 있습니다.
Redis는 '이러한 문제'를 해결하기 위해 Multiplexing과 Event Loop System을 활용했습니다.
즉, Multiplexing과 Event Loop System은 'Redis가 왜 빠른지'에 대한 대답보다 'Redis가 Single Thread임에도 불구하고 어떻게 빠를 수 있는지' 에 대한 대답에 가깝다고 생각했습니다.
Multiplexing
Multiplexing은 다양한 분야에서 사용되는 용어지만, 그 의미의 본질은 여러 개의 신호를 하나의 채널에서 동시에 전송하는 기술입니다.
일반적으로 user space에 존재하는 process는 I/O작업을 직접 처리하지 못해 kernel에게 I/O작업을 요청합니다. 그리고 이 process는 kernel의 I/O작업의 결과를 반환받을 때까지 대기합니다.
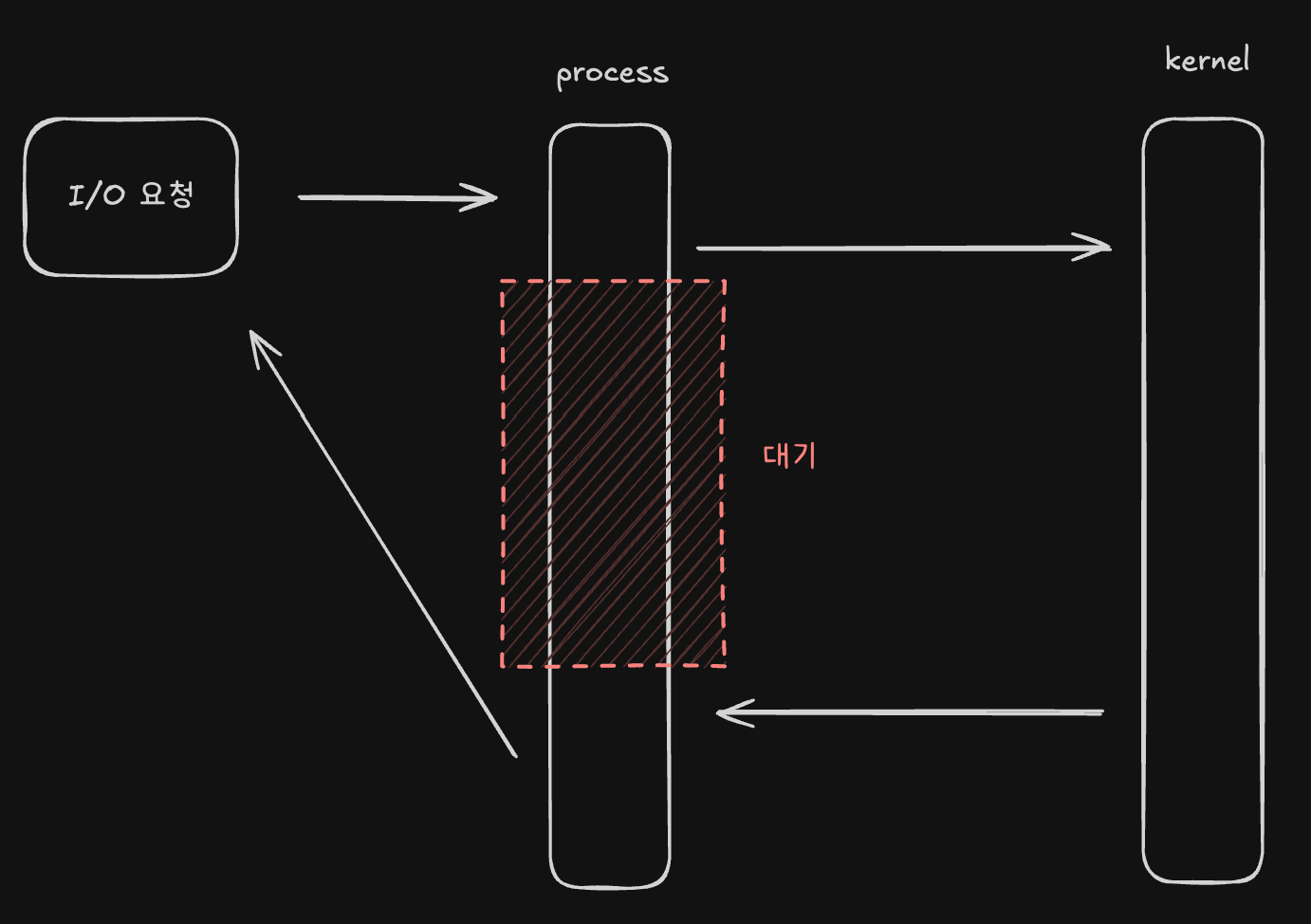
하나의 process에 여러 I/O요청이 동시에 들어오는 경우에도 순차적으로 처리되기 때문에 나머지 요청은 대기하게 됩니다.
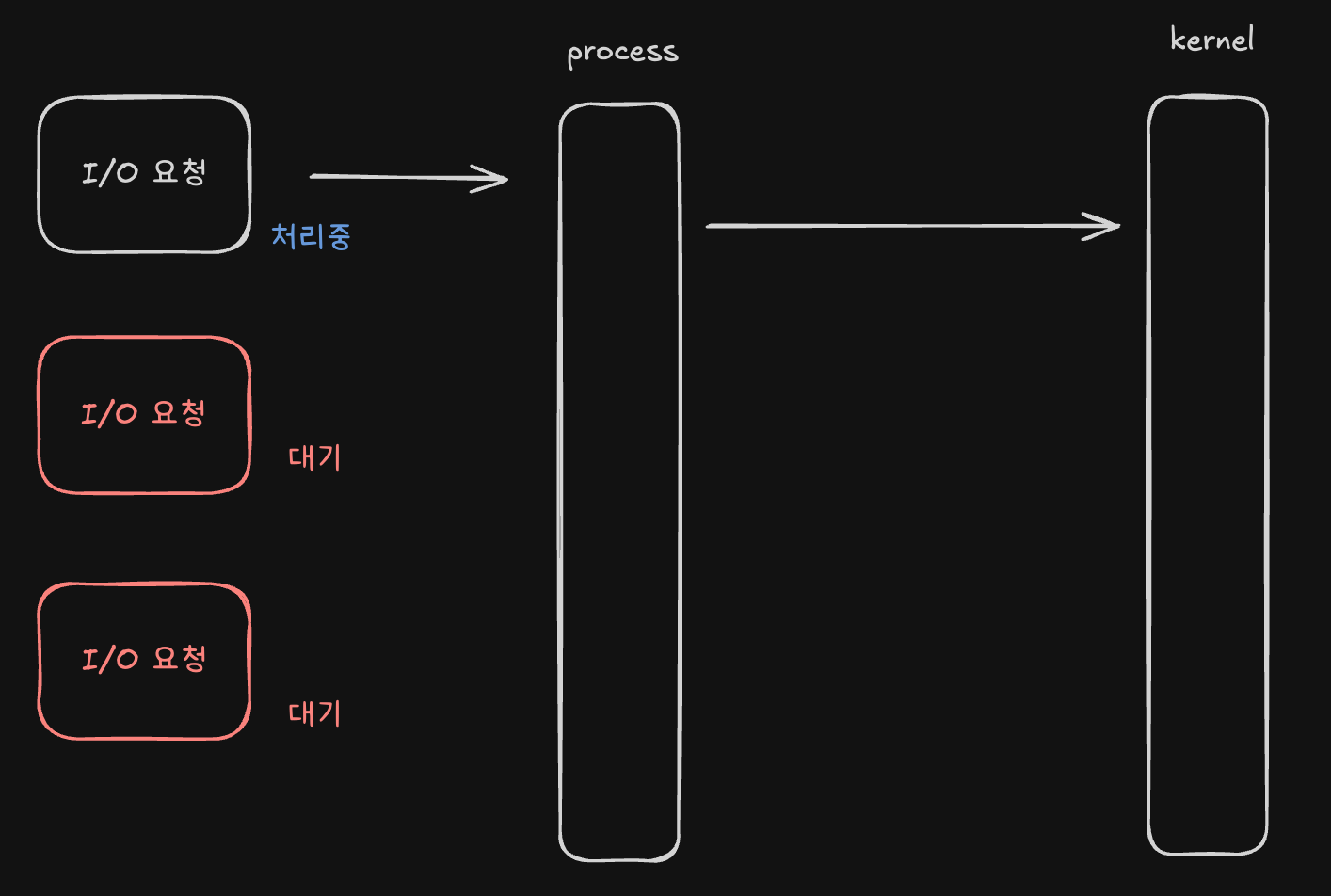
이러한 문제를 해결하기 위해 process 또는 thread를 늘려 각자 I/O요청을 처리하도록 할 수 있습니다.
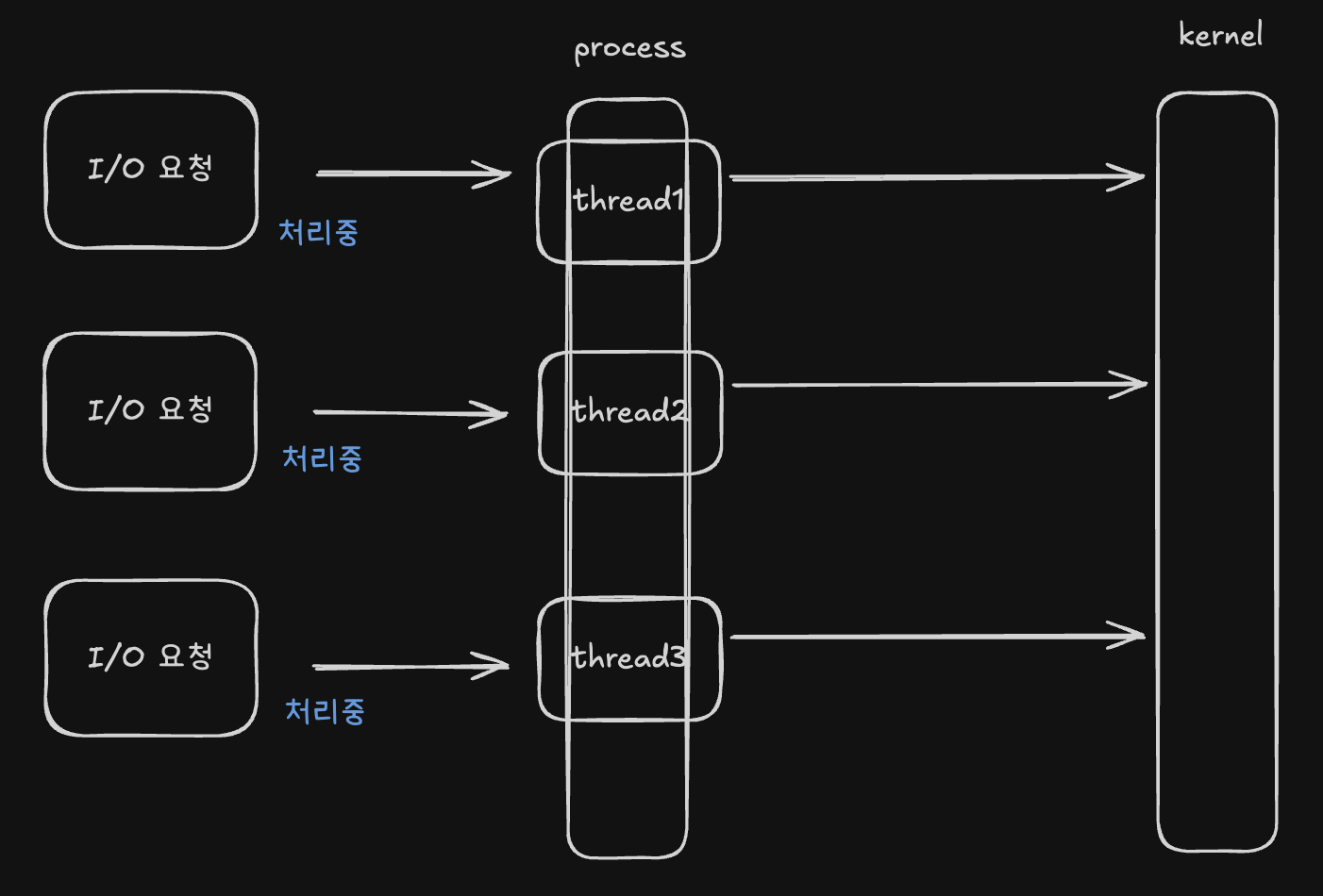
하지만 multi thread(process)의 경우 thread의 개수가 많아질수록 context switching 비용도 증가한다는 문제가 있어 대량의 네트워크 소켓 작업과 같은 일에는 적절하지 않을 수 있는데요. 이러한 문제를 해결하기 위해 사용하는 기술 중 하나가 I/O Multiplexing입니다. I/O Multiplexing은 적은 수의 thread로도 다수의 I/O 요청을 비동기적으로 처리할 수 있게 해줍니다.
네트워크에서 클라이언트와 서버는 소켓을 통해 데이터를 주고받습니다. 클라이언트가 서버에 데이터를 보내거나 받을 때, 서버는 각 클라이언트마다 개별적인 소켓을 생성하여 관리합니다. 소켓에서 recv 시스템 콜을 통해 데이터를 읽으면 해당 스레드는 Block되어 응답이 올때까지 대기하게 됩니다. 이 대기상태 동안 다른 소켓의 요청은 처리할 수 없기 때문에 일반적으로 하나의 스레드가 하나의 소켓을 감시하는 구조를 사용합니다.
하지만 I/O Multiplexing은 select, poll, epoll과 같은 시스템 콜을 이용해 하나의 스레드가 여러 개의 소켓을 감시할 수 있도록 합니다.
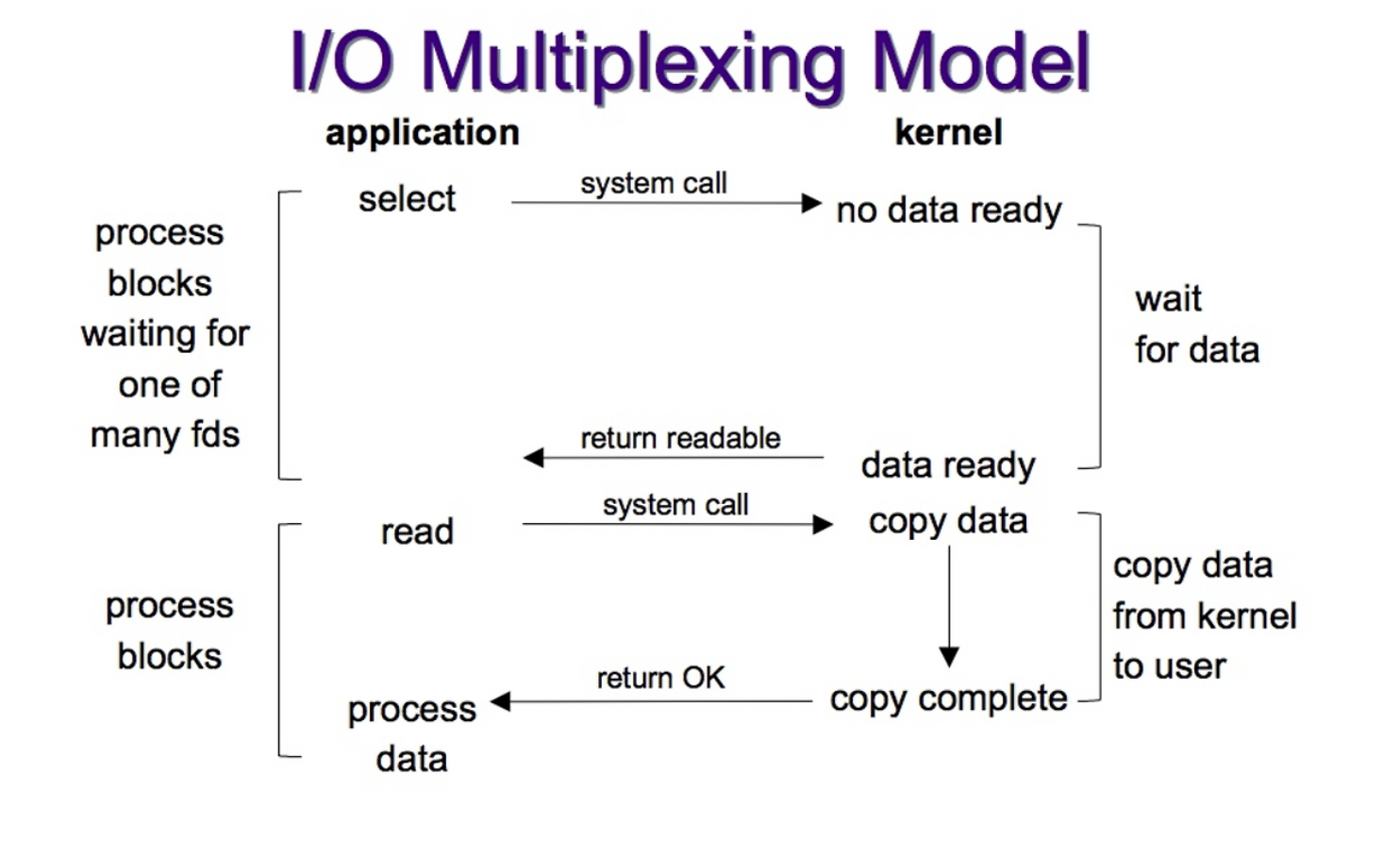
I/O Multiplexing을 통해 하나의 스레드가 여러 개의 소켓을 감시할 수 있게 됐지만, 데이터를 가져오기 위해 recv 시스템 콜을 실행하는 순간 스레드가 Block되는 건 여전합니다.
그래서 Redis의 I/O Multiplexing을 담당하는 스레드는 여러 소켓을 감시하기만 할 뿐 직접 recv 시스템 콜을 실행하지 않고 이 작업을 위임합니다. 바로 Event Loop System에게요.
Event Loop System
Event Loop System은 일반적으로 이벤트를 적재하는 Queue가 존재하고, 시스템이 이를 무한히 감시하다가 Queue에 이벤트가 들어오면 그 이벤트를 꺼내 처리하는 구조를 말합니다. 이때 큐에서 꺼내온 이벤트를 직접 처리할 수도 있고, 백그라운드 스레드 풀을 이용해 병렬로 처리하는 경우도 있습니다.
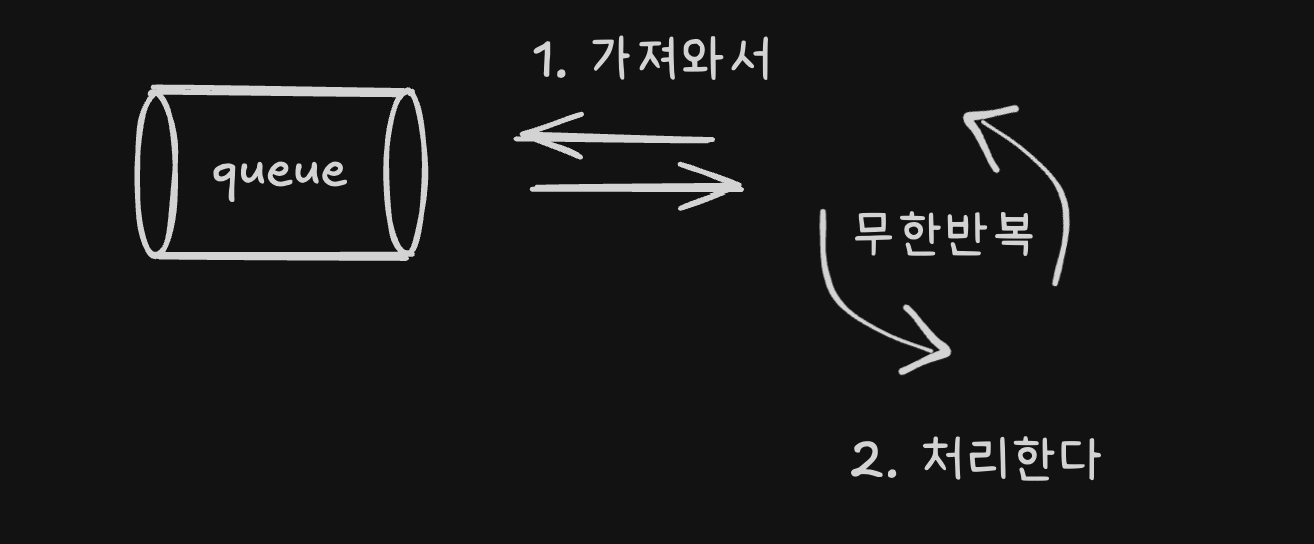
Redis의 Event Loop System은 I/O Multiplexing을 통해 감지된 소켓의 이벤트를 처리하고 해당 요청을 실행합니다. 초기의 Redis는 백그라운드 스레드 풀을 사용하지 않고 모든 작업을 단일 스레드에서 처리했습니다. 덕분에 Redis는 우리가 알고 있는 것처럼 원자적인 연산이 가능하고, 연산의 순서가 보장됩니다. 하지만 Redis6.0에서 일부 작업을 백그라운드 스레드에서 실행하는 ThreadedIO와 같은 기술이 추가되기도 했습니다.
ThreadedIO
Redis6.0부터는 I/O 처리를 멀티스레드로 수행할 수 있습니다. I/O 소켓에서 데이터를 읽고 쓰는 작업을 별도의 스레드에 위임함으로써 연산을 수행하는 스레드는 더 많은 CPU자원을 명령어 처리에 할당할 수 있습니다.

사용자가 Redis에 get key 명령어를 보내면
- 클라이언트가 Redis 서버의 IP와 포트로 TCP연결을 요청함
- Redis 서버는 Listening socket을 열어 accep()t를 통해 새로운 클라이언트 연결을 받음
- 운영체제 커널이 TCP 3-way handshake를 수행함
- 연결이 성공하면 Redis서버는 새 클라이언트 소켓을 Multiplexing I/O에 등록하고 해당 소켓을 감시함
- 클라이언트가 get key 명령어를 전송하면 Multiplexing은 소켓에 데이터가 도착했다는 이벤트를 감지하고 이벤트를 큐에 추가함('소켓에 읽을 데이터가 있음'이라는 신호를 넣음, 실제 데이터가 담겨있지는 않음)
- I/O 스레드는 이벤트가 발생한 소켓에서 데이터를 읽고 이를 단일 실행 스레드의 작업 큐(Execution Queue)에 전달함
- Redis의 단일 실행 스레드가 실행 큐에서 요청을 하나씩 꺼내 순차적으로 처리하고 네트워크 스레드에게 응답을 전달함
- 네트워크 스레드는 클라이언트의 소켓에 응답을 씀(write)
- 클라이언트가 Redis로부터 응답을 받음
References
- https://junuuu.tistory.com/746
- https://loosie.tistory.com/872
- https://brunch.co.kr/@growthminder/154
- https://haon.blog/redis/single-thread-fast/
- https://velog.io/@ohjinseo/Redis%EA%B0%80-%EC%8B%B1%EA%B8%80-%EC%8A%A4%EB%A0%88%EB%93%9C-%EB%AA%A8%EB%8D%B8%EC%9E%84%EC%97%90%EB%8F%84-%EB%86%92%EC%9D%80-%EC%84%B1%EB%8A%A5%EC%9D%84-%EB%B3%B4%EC%9E%A5%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0-IO-Multiplexing
- https://www.pauladamsmith.com/articles/redis-under-the-hood.html
- https://blog.bytebytego.com/p/why-is-redis-so-fast
- https://velog.io/@redjen/%EB%A0%88%EB%94%94%EC%8A%A4%EB%8A%94-%EC%99%9C-%EB%B9%A0%EB%A5%BC%EA%B9%8C
- https://plummmm.tistory.com/68
- https://velog.io/@kafkaaaa/IO-Multiplexing-%EC%9E%85%EC%B6%9C%EB%A0%A5-%EB%8B%A4%EC%A4%91%ED%99%94
- https://blog.naver.com/n_cloudplatform/222189669084
- https://kwj1270.tistory.com/entry/Reactive-%EC%97%AC%EC%A0%95%EA%B8%B01%EB%B6%80-IO-Multiplexing-%EA%B3%BC-Asynchronous-IO-%EA%B7%B8%EB%A6%AC%EA%B3%A0-Event-Loop
- https://d2.naver.com/helloworld/0853669
- https://redis.com/blog/multiplexing-explained/
- https://inpa.tistory.com/entry/%F0%9F%94%84-%EC%9E%90%EB%B0%94%EC%8A%A4%ED%81%AC%EB%A6%BD%ED%8A%B8-%EC%9D%B4%EB%B2%A4%ED%8A%B8-%EB%A3%A8%ED%94%84-%EA%B5%AC%EC%A1%B0-%EB%8F%99%EC%9E%91-%EC%9B%90%EB%A6%AC
- https://gutte.tistory.com/153
- https://www.korecmblog.com/blog/node-js-event-loop
- https://redis.io/docs/latest/operate/oss_and_stack/reference/internals/internals-rediseventlib/
- https://redis.io/blog/diving-into-redis-6/
