
들어가기 전에
- 이 글은 카카오if에서 진행한 JVM warm up영상을 보고 정리하는 글입니다.
- 모든 이미지의 출처 역시 JVM warm up에서 비롯된것임을 밝힙니다.
서론
해당 강연은 카카오모빌리티 계정 서비스를 담당하면서 겪었던 경험에 대한 얘기였습니다. 계정 서비스는 자사의 여러 MSA 서비스 중 TPS요청이 높은 서버에 속한다고 합니다. TPS란 초당 트랜잭션 수를 나타내는 지표입니다.
JVM warm up이란?
해당 API는 빠른 응답속도를 보장하는 게 중요한 서비스이며, 자바 11버전과 Spring Boot 2를 사용하고 있다고 합니다. 이를 최적화하기 위해서는 자바 개발언어의 특징을 잘 이해해야 합니다.
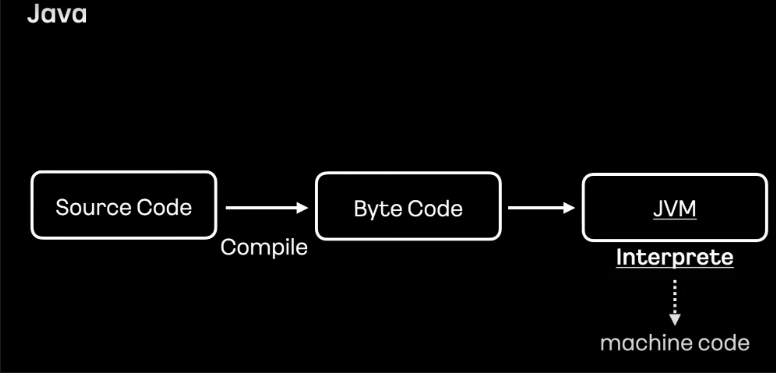
개발자가 작성한 자바 코드는 1차적으로 중간언어라 불리는 Byte Code로 컴파일해야 합니다. Byte Code는 JVM에 의해 번역되어 Jar 또는 War로 변환되어 활용하게 됩니다. 즉, 자바는 컴파일과 인터프리터 두 동작에 의해 실행되는 언어입니다.
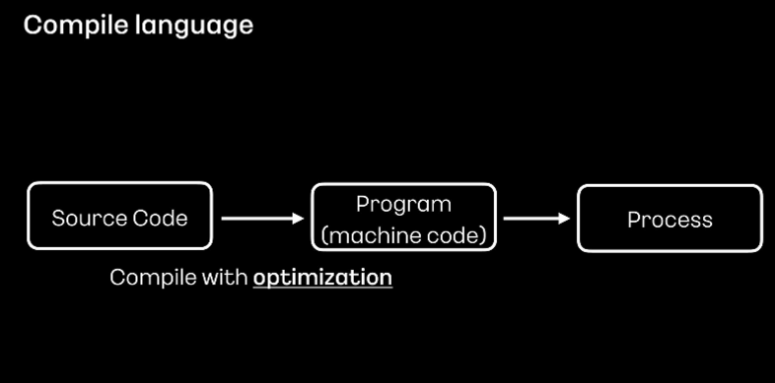
그러다 보니 Java는 컴파일 과정에서 바로 기계어로 번역하는 C, C++, Golang Lust와 같은 컴파일 개발 언어보다 성능이 뒤처집니다. 컴파일 언어들이 런타임 환경에서 준비된 기계어를 즉시 실행하기 때문이기도 하고, 컴파일로 기계를 만들 때 코드 최적화를 진행하기 때문이기도 합니다. 다만 컴파일을 통해 생성된 기계어는 빌드 환경의 cpu 아키텍처에 종속적이기 때문에 다른 아키텍처 환경에서 실행하려면 해당 빌드 환경에서 새로 빌드해야 한다는 단점이 있습니다.

이렇듯 컴파일 언어가 인터프리터 언어보다 성능적으로 더 유리합니다. 인터프리터 방식을 취하는 자바는 이러한 문제를 해결하기 위해 JVM에 JIT 컴파일러를 사용하고 있습니다.
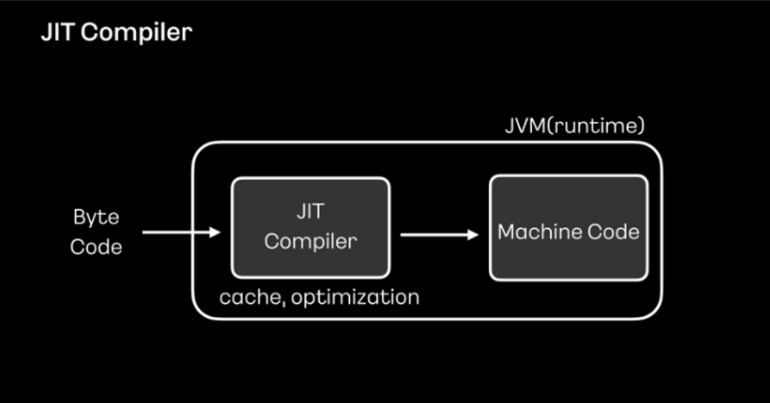
JIT 컴파일러는 바이드 코드를 머신 코드로 변환하는 과정에서 머신 코드를 캐시에 저장하고 활용합니다.
이를 통해 반복되는 변환 과정을 줄여 성능을 향상시키고 런타임 환경에 맞춰 코드를 최적화함으로써 성능을 보완하고 있습니다.
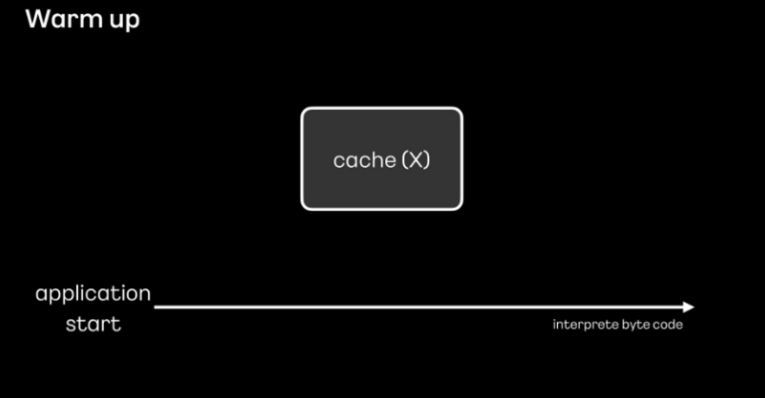
하지만 애플리케이션을 시작하는 단계에서는 캐시된 내역들이 없기 때문에 JIT 컴파일러의 성능이 좋을 수 없습니다.
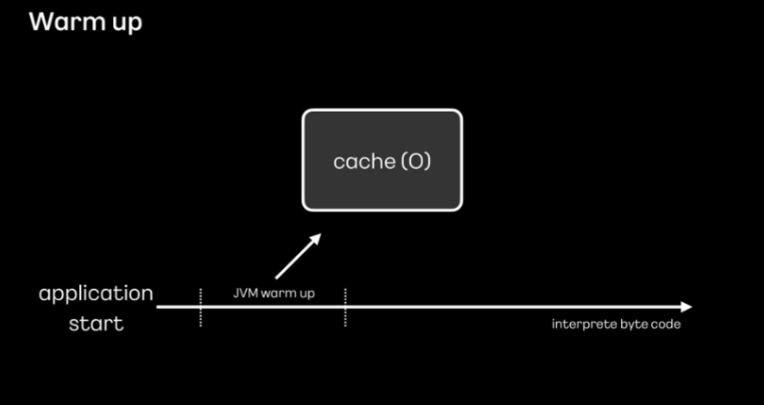
그래서 애플리케이션 시작 후 의도적으로 미리 로직을 실행하여 기계어가 캐시에 저장되고 최적화될 수 있도록 하는 warm up 절차가 필요합니다.
런타임에 액세스할 때 즉시 사용할 수 있도록 모든 클래스를 미리 캐시에 기록해 두는 작업을
JVM warm up이라고 합니다.
문제 상황
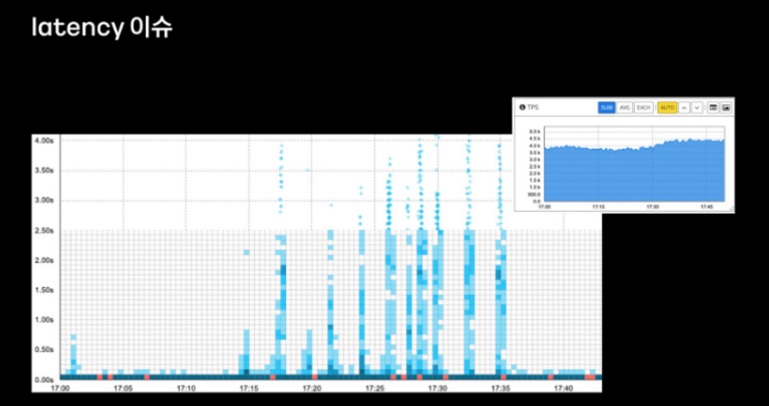
계정 서비스로 요청되는 트래픽은 과거 대비 매달 또는 분기별로 약 10~20%씩 증가하는 추세를 보이고 있었고, 2021년 5월쯤 개정 서버를 배포하는 과정에서 응답 지원 이슈가 발생했다고 합니다.
계정 서버는 쿠버네티스에서 운영되며 다수의 pod에 대해 롤링 업데이트 방식으로 배포가 진행되고, pod이 순차적으로 배포되기 때문에 그래프와 같이 지연 또한 순차적으로 나타나고 있었다고 합니다.
이러한 지연 현상이 계속 유지되는 게 아니라 어느 정도 시간이 지나면 해소된다는 점이 특징적이었다고 합니다.

지연의 원인을 파악하기 위해 리소스에 대한 분석을 먼저 진행했다고 합니다.
cpu는 평균 10% 이하로 운용되고 있었으며 메모리는 60% 이하 그리고 네트워크 밴드 리스는 워커노드당 10~20메가바이트 수준으로 대부분의 리소스들이 여유 있는 상태였다고 합니다.
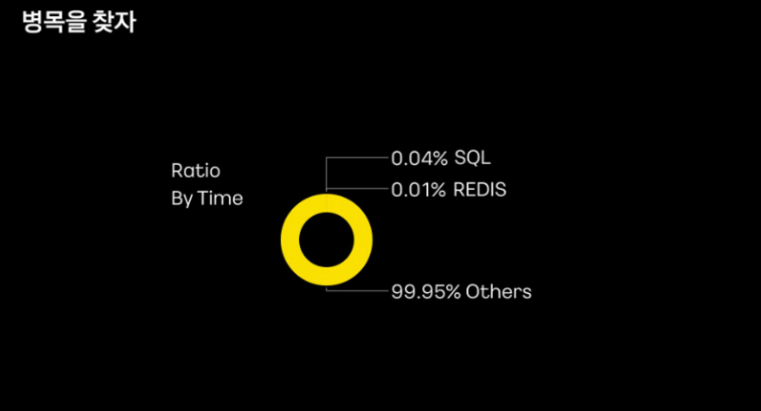
이후 애플리케이션 모니터링을 위한 apm에서 응답 지연 당시의 요청을 살펴봤다고 합니다.
외부 데이터베이스에서의 지연은 확인되지 않았고 대부분의 지연이 Others, 즉 어플리케이션 영역에 있는 요청에 의해 일어나고 있었다고 합니다. 다만 해당 요청이 도메인 로직에 의한 건지는 아직 확인되지 않은 상태였다고 합니다.
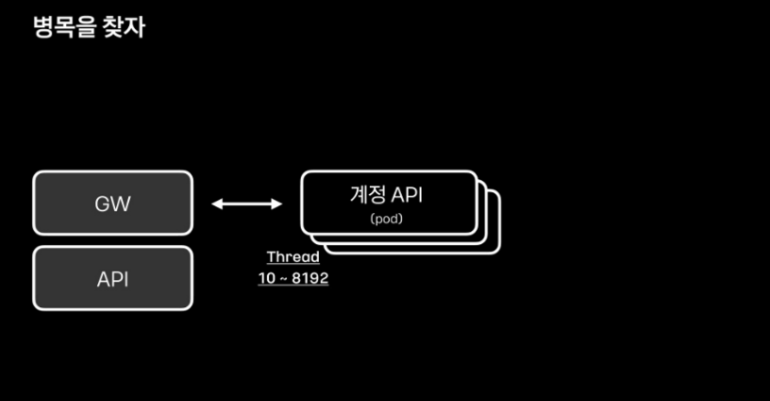
그래서 트래픽을 처리하는 톰켓 웹 애플리케이션 서버의 스레드 개수를 확인했다고 합니다.
10개의 스레드로 시작하여 최대 8천여 개까지 늘어나는 설정이 되어 있었고, 서비스 시작 후 스레드가 200여 개 어난 것을 확인하고 스레드 시작 개수를 조정할 필요성을 느꼈다고 합니다.
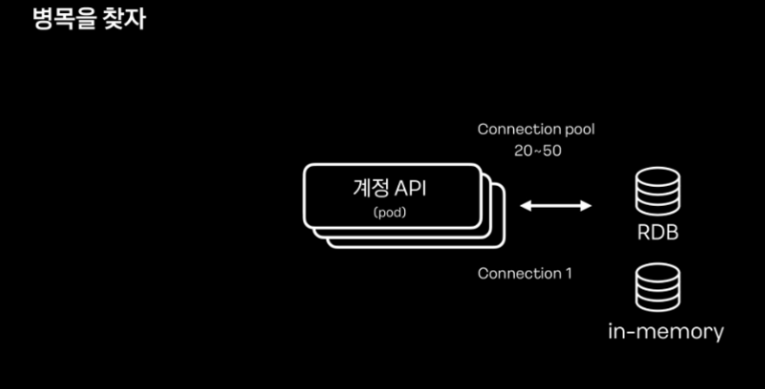
DB Connection은 RDB의 커넥션 풀이 20개로 시작되게끔 설정되어 있었고 서버 시작 이후로도 큰 변화가 없어문제가 없는 것으로 판단했다고 합니다.
Inmemory DB인 Redis는 single road로 운영되고 있어 문제라고 생각하지 않았다고 합니다.
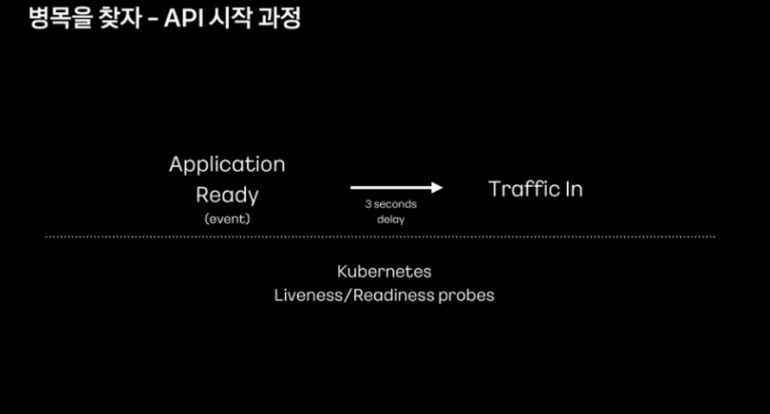
다음으로 Java로 구현한 계정 api에 JVM warm up이 잘 준비됐는지 확인했다고 합니다.
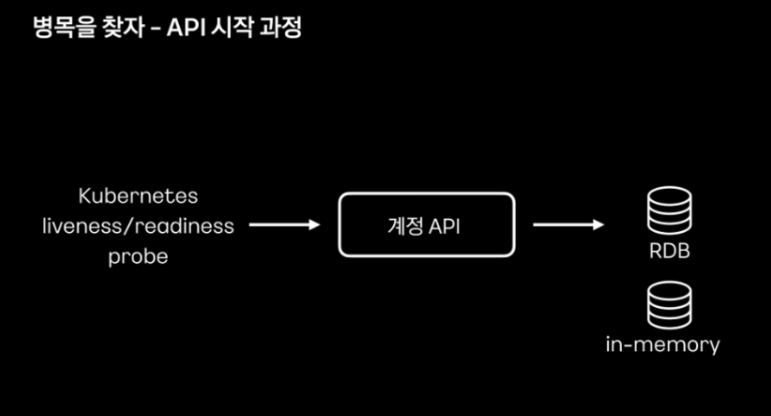
Warm up 동작을 살펴보면 liveneww/readiness probe 요청이 있을 시 데이터베이스에 정해진 정보를 기재하도록 되어 있다고 합니다.

Pseudo Code를 살펴보면 liveness, readiness probe 요청을 처리하는 컨트롤러에서 warmer 메서드를 호출하게 되고, warmer 메서드에서는 데이터베이스에 정해진 데이터를 질의하게 됩니다.
해당 warmer는 실제 서비스에서 사용되는 api가 아니면서 api 내용도 특정 데이터 조회 로직에 한정되어 충분한 warm up이 이뤄지지 않고 있다고 판단했다고 합니다.

지금까지의 분석으로 아래 두 가지 결론을 내렸다고 합니다.
1. pod의 tomcat thread들이 200여 개로 시작할 수 있도록 개선하는 작업이 필요하다.
2. JVM warm up 과정은 실제 사용하는 api를 localhost로 호출하되, real traffic과 같은 유사한 요청이 되도록 개선하는 게 필요하다.
문제 해결
warm up은 warm up 이전에 트래픽이 유입되지 못하게 함으로써 문제를 해결했다고 합니다. 예전에는 정해진 시간만큼만 지연시키고 트래픽을 유입시켰다면 이제는 웜업이 완료되어야 트래픽이 유입될 수 있도록 개선했다고 합니다.
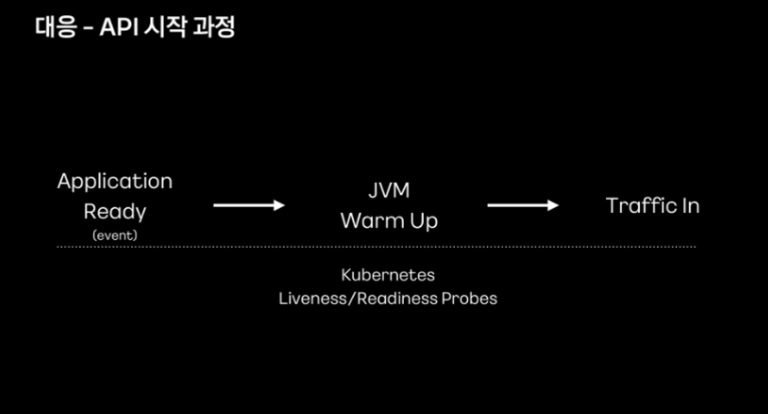
warm up은 기존과 동일한 Liveness/Readiness Probe 과정에서 처리했다고 합니다.
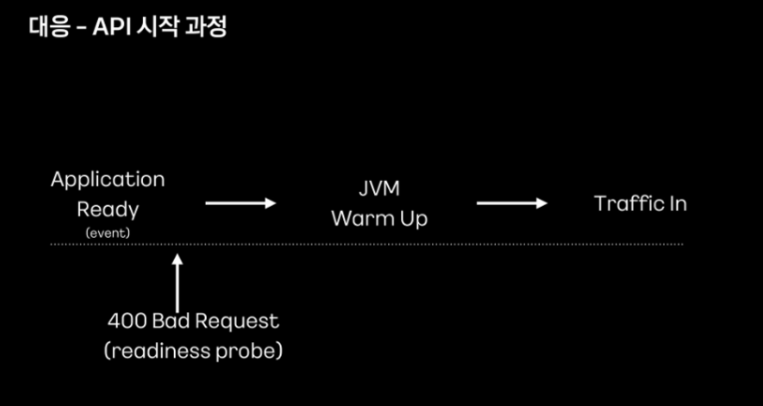
warm up 이전의 요청에는 400 응답을 줘 외부 트래픽이 유입되지 않도록 변경했다고 합니다.
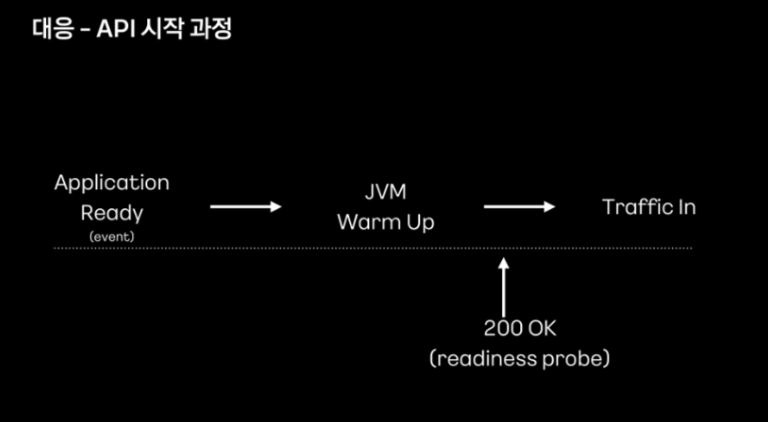
warm up이 완료되면 트래픽이 유입될 수 있도록 readiness probe 요청의 응답을 200으로 변경했다고 합니다.
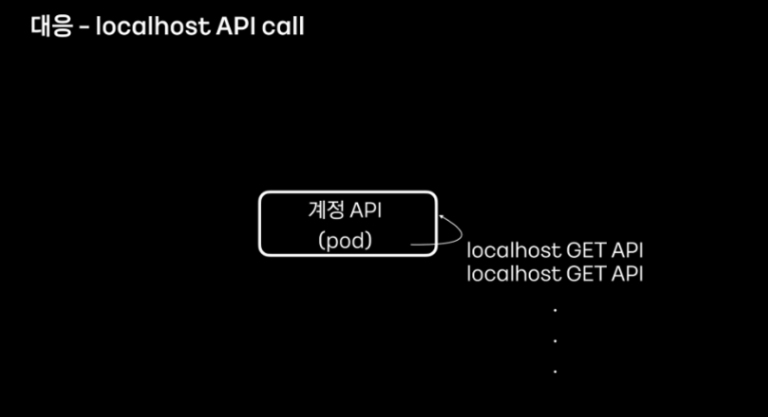
또한 warm up은 각 pod마다 localhost api 요청을 하도록 변경했다고 합니다. 서비스에 자주 사용되는 get api와 배포 과정에서 확인된 지원 대상들을 warm up 과정에 포함시켰다고 합니다.
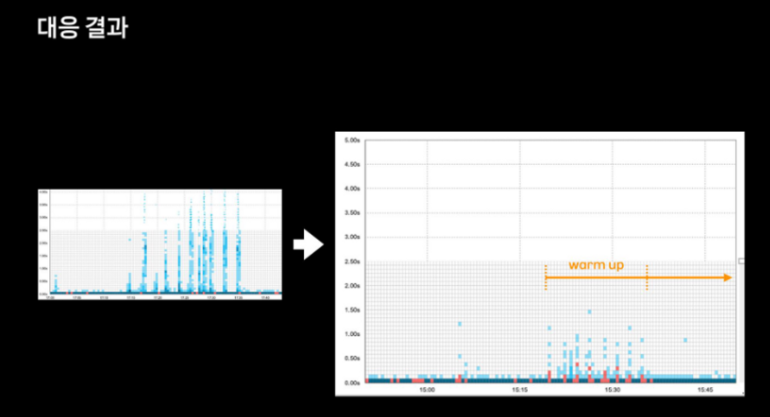
이를 통해 아래와 같은 성능 향상을 얻을 수 있었다고 합니다. 일부의 지연들은 warm up 과정에서 localhost를 호출하게 된 api들이라고 합니다.
하지만 두달 후 비슷한 문제가 또 발생했다고 합니다.
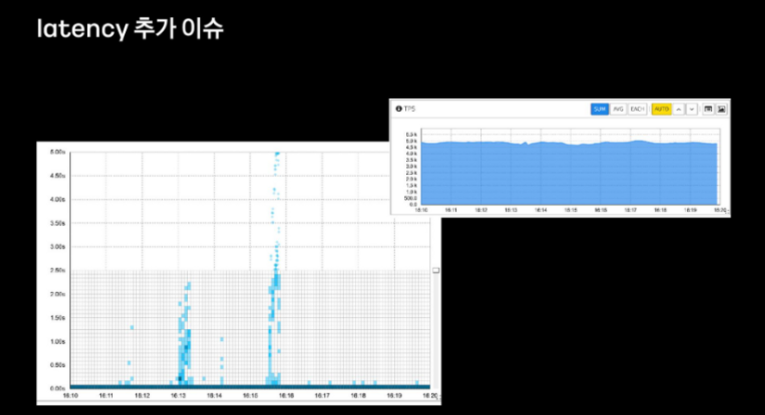
이전 트래픽 대비 20%정도 향상된 트래픽(약 tps 5000가량) 상황에서 또 다시 응답 지연 현상이 발생했다고 합니다.
이미 warm up에 대한 조치는 완료된 상태였기에 다른 방법들을 고민하며 테스트를 진행했다고 합니다.

테스트 또는 고려사항
- JIT을 Gral로 변경
- 별다른 성능 향상이 없었다고 합니다.
- AOT 컴파일 활용
- Gral vm을 활용해 네이티브 바이너리를 만들 수 있다는 장점이 있습니다.
- 스프링 노트에서는 아직 실험적 도입 단계라 적용했을 때 기존 코드들이 모두 잘 동작한다는 보장을 하기 어려워 보류했다고 합니다.
- 실제 트래픽과 같이 많은 수의 warm up 시도
실제로 3번 방식으로 문제를 해결했다고 합니다.

문제 해결을 이해하기 전에 JIT의 내부 동작에 대한 이해가 필요합니다.
JIT은 메서드 전체 단위로 Compile을 합니다.
예를 들어 다음과 같은 과정을 거친다호 갛빈다.
- 메서드 내 모든 바이트 코드들은 한꺼번에 네이티브 코드로 Compile 됩니다.
- 네이티브 코드로 전환 후 후속 최적화 작업을 위해 프로파일링 정보를 수집합니다.
- 그리고 tiered compilation이란 단계별 컴파일을 통해 코드 최적화를 진행하게 됩니다.
tiered compilation은 C1과C2 2단계 컴파일로 이뤄져 있다고 합니다.
C1 단계에서는 간략한 최적화만 진행하게 되고 C2 단계에서는 최대 최적화를 하여 코드 캐시에 저장하고 활용함으로써 코드의 신속도를 높인다고 합니다.
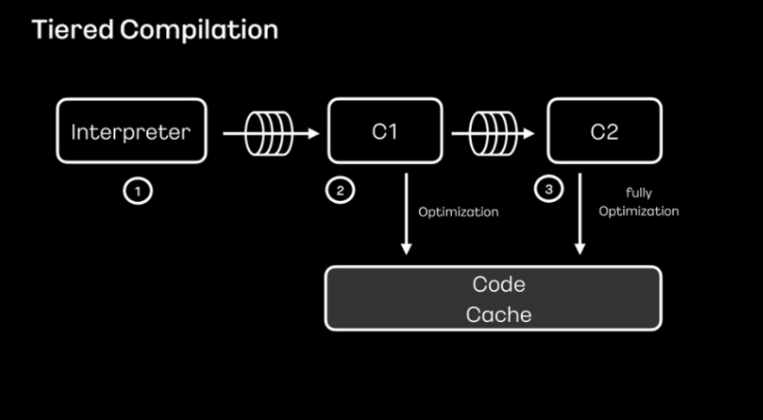
- 인터프리터를 통해 바이트 코드가 기계어로 번역됩니다.
- 해당 메서드가 정해진 임계치 설정만큼 호출되면 C1 컴파일러를 통해 최적화 됩니다.
- 이후 C2 컴파일러의 임계치 설정만큼 해당 메서드가 더 호출되면 C2 컴파일러를 통한 최대 최적화가 진행됩니다.

tiered Compilation은 0~4단계 레벨로 나눌 수 있다고 합니다.
- level0: 바이트코드를 최적화 없이 기계어로 변경하는 해석 단계입니다.
- level1: 더 이상 최적화가 불필요하다고 느끼는 간략한 코드들을 컴파일 하는 단계입니다.
추가적인 최적화를 진행하지 않기 때문에 프로파일링 정보를 수집하지 않습니다. - level2: 제한된 최적화를 진행합니다.
- level3: 프로파일링 모드로 정보로 수집하고 최적화를 진행합니다.
- level4: C2컴파일을 실행합니다.
다시 얘기하면 level0은 최적화를 실행하지 않는 단계, level1~3은 C1최적화를 실행한 상태, level4는 C2최적화를 실행한 상태라고 할 수 있습니다.
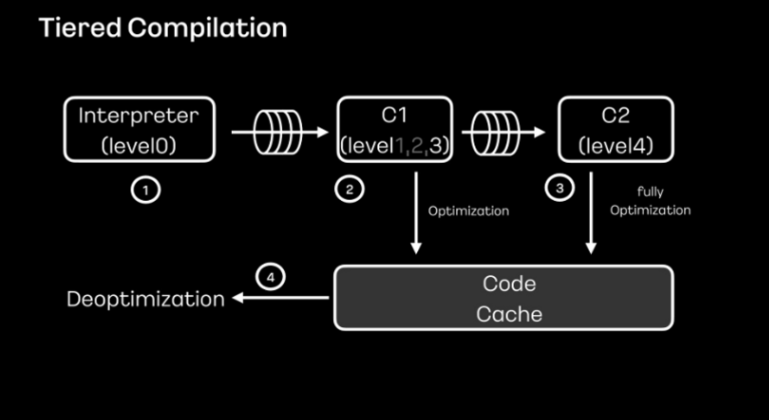
일반적인 흐름을 다시 살펴보면 바이트코드가 level0를 통해 기계화로 번역 후 C1 임계치보다 많이 실행되면 C1 컴파일러를 위한 큐에 전달 됩니다. C1에서는 level3까지 최적화해 진행하여 이를 코드 캐시에 저장합니다.
이후 해당 메서드가 C2의 임계치보다 더 많이 실행되면 level4를 통해 최대 최적화를 진행한 후 코드 캐시에 다시 저장하게 됩니다.
이 과정에서 C1과 C2는 각각 쓰레드를 가지고 별도로 동작한다고 합니다.
C2 컴파일러 큐가 가득 차면 큐에 담겨져 있는 메서드를 꺼내 C1 레벨2로 컴파일 하게 됩니다. 이후 큐 버퍼에 여유가 생기게 되면 다시 level3, level4까지 컴파일이 되는 절차를 갖습니다. 만약 level2가 자주 컴파일 되고 있다면 C2 컴파일 큐가 가득 차 있다고 판단할 수 있어 C2 컴파일러 쓰레드 수를 조정할 필요가 있습니다.

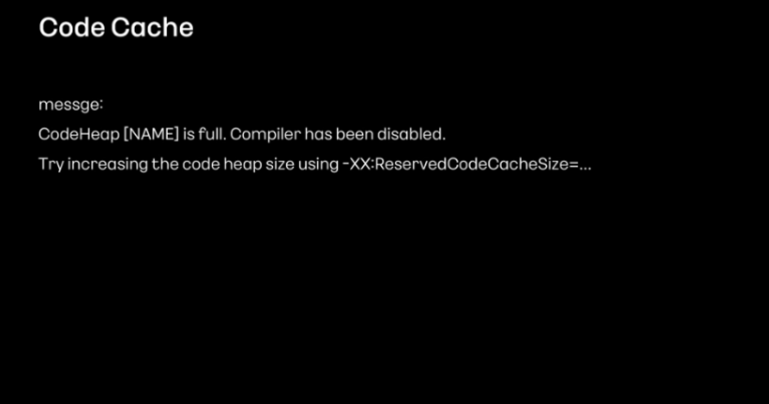
애플리케이션 실행 단계에서 jvm 옵션으로 초기 코드 캐시와 최대 사이즈를 조절할 수 있다고 합니다.
XX:InitialCodeCacheSize=NXX:ReservedCodeCacheSize=N
만약 코드 캐시가 가득 차게 되면 더 이상 성능상의 이득을 기대할 수 없습니다.CodeHeap [NAME] is full. Compiler has been disabled. Try increasing the code heap size using ...과 같은 에러 메시지를 만나면 크기를 늘려줘야 한다고 합니다.
카카오모빌리티의 계정 서비스에서는 이러한 문제가 발생하지 않아 크기를 변경하지 않고 jvm 기본값을 사용했다고 합니다.

C1, C2의 임계치는 java -XX:+PrintFlagsFinal -version | grep Threshold | grep Tier명령어로 확인할 수 있습니다.
- Tier3: C1의 Level3을 의미합니다.
- Tier4: C2의 Level4를 의미합니다.
- InvocationThreshold: 메서드의 호출 수를 의미합니다.
- BackEdgeThreshold: 하나의 메서드 내 반복문의 횟수를 의미합니다.
- CompileThreshold: 메서드의 호출 수와 메서드 내 반복문의 횟수를 더한 값을 기준으로 설정된 값입니다.

실제 메서드 호출 수와 메서드의 반복문 횟수가 설정된 기준을 넘어서면 각 레벨에 맞는 최적화를 진행합니다.
위 디폴트 설정을 기준으로 살펴보면 하나의 메서드가 약 200회 이상 호출되면 Tier3 InvocationThreshold 조건에 해당해 Tier3 최적화가 진행됩니다.
샘플 코드
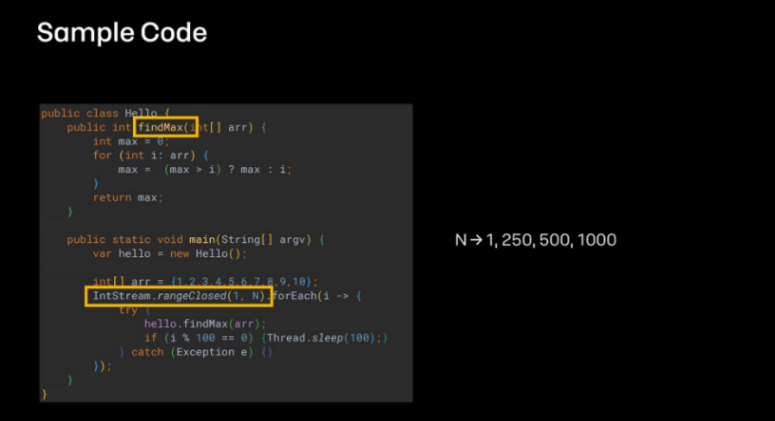
findMax 메서드는 전달받은 거래의 값 중 가장 큰 값을 찾는 메서드입니다.
호출 횟수를 1, 250, 500, 1000까지 늘려 동작시킨 후 C1,C2 컴파일러가 어떻게 쌓이는지를 확인할려고 합니다.
반복 횟수를 늘려도 처리 속도가 너무 빠르면 C2 Compiler가 동작하지 않을 수 있어 반복문 중간에 슬립을 주었습니다.

실행 시 진단 모드를 활성화하는 UnlockDiagnosticVmOptions와 LogCompilation 옵션을 주면 JIT 로그를 확인할 수 있다고 합니다.
위과 같은 모양의 로그가 쌓인다고 합니다.
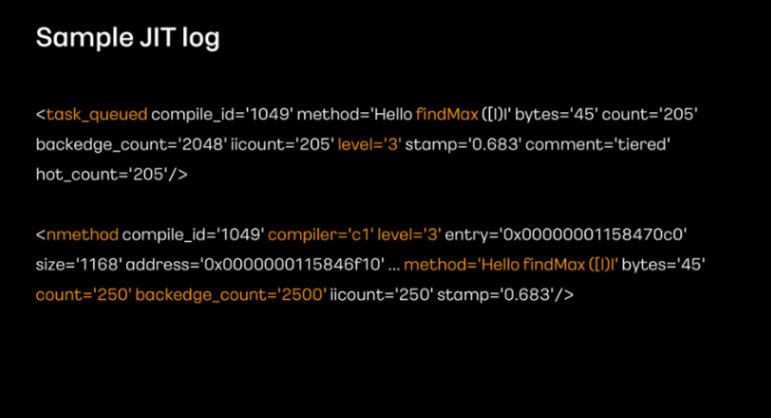
샘플 코드의 JIT 로그를 살펴보겠습니다.
지금 보여주는 로그는 250회 동작시켰을 때 나타난 C1 컴파일 로그라고 합니다. (N=1일때는 C1 컴파일 임계치에 다다르지 않아 로그가 없었다고 합니다.
task_queued의 로그는 level3 컴파일을 위해 findMax메서드가 C1큐에 적재됐다는 내용이라고 합니다.
nmethod(네이티브 메서드)의 로그는 C1 컴파일 level3로 코드 최적화가 진행됐음을 나타냅니다.
함께 수집된 count와 backedge_count를 통해 임계치를 넘었는지 확인할 수 있습니다.
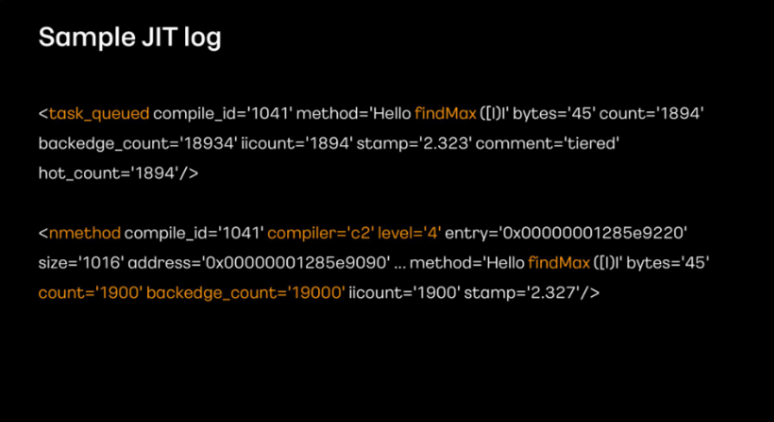
findMax 메서드를 1000회 실행하면 C2 컴파일 로그를 확인할 수 있습니다. nmethod를 보면 C2 컴파일 level4로 최적화가 됐음을 확인할 수 있습니다.
실제 테스트 결과
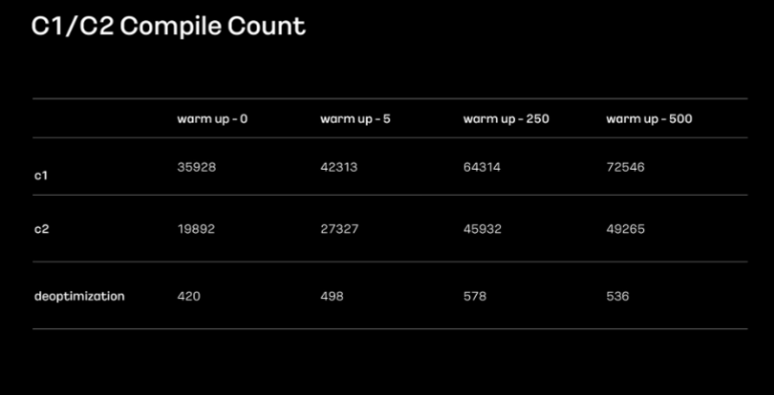
위 이미지는 카카오모빌리티 계정 서비스의 추가 조치를 위한 테스트 내용이라고 합니다.
서비스 실행 단계에서 warm up couint를 변경하면서 테스트를 진행했다고 합니다.
0 5 250 500개를 시도하였고 각각 C1,C2 컴파일러가 얼마큼 진행됐는지 확인했고, 증가하는 횟수에 따라 c1 c2 최적화가 더 많이 진행된다는 사실을 알았지만 그만큼 warmup 시간도 오래 걸리기 때문에 적절한 값을 선택하는 게 중요했다고 합니다.
250회를 시간 대비 효율적인 횟수라고 판단해 이를 개발 환경에서 테스트해봤고, 지연 문제가 발생하지 않았다고 합니다.
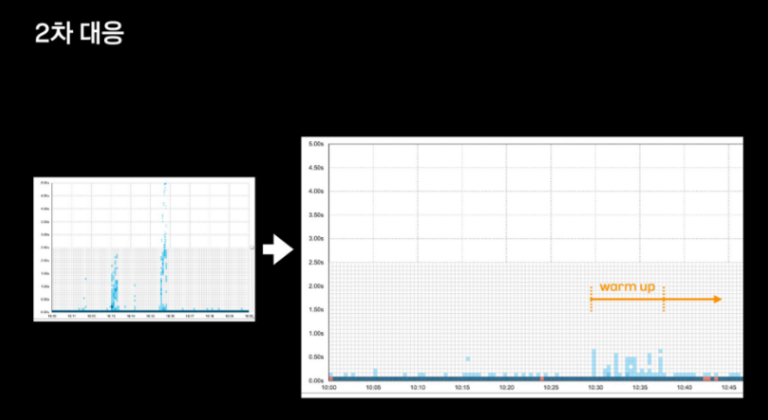
최종적으로 production 환경에서 warm up 카운트를 늘려 배포를 진행해봤고 배포 과정에서 발생했던 응답 지연 현상이 해소된 걸 확인할 수 있었다고 합니다.
이후 현재까지도 동일한 문제가 발생하고 있지 않으며 안정적인 서비스 배포를 진행하고 있다고 합니다.
