
상황 설명
쇼핑몰 사이트에서 상품 리스트를 보여줄 때, 평균 평점이라는 데이터를 어떻게 처리하면 좋을까요?
(이미지 출처 : 롯데ON)
평균 평점을 계산하려면 해당 상품의 모든 리뷰 정보를 알고 있어야 합니다. 데이터베이스의 관점에서 만약 Product 테이블과 Review 테이블이 나눠져 있다면 Review 테이블을 Join해야 합니다.

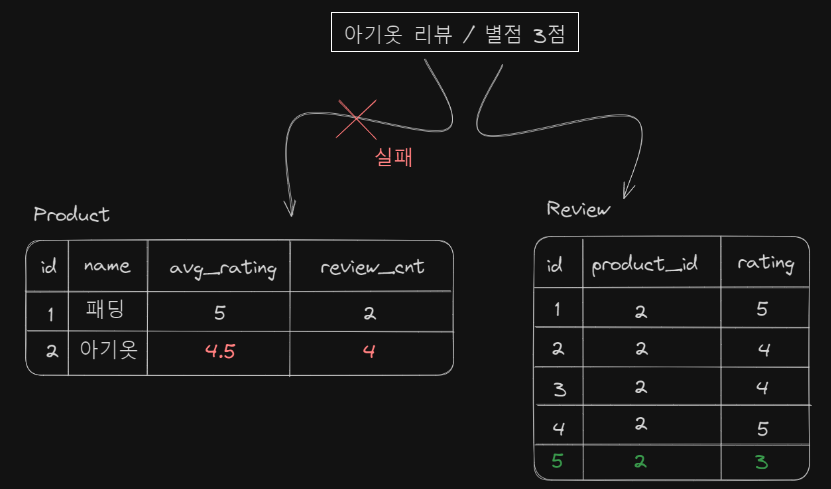
아기옷 정보를 화면에 출력하기 위해 Product의 정보 외에 Review테이블에서 SELECT AVG(rating) FROM review WHERE product_id = 2를 한 결과가 필요하다는 얘기입니다.
이러한 작업은 MSA환경에서 Product와 Review가 각각의 Microservice로 분리되어 존재하면 더 큰 부담으로 다가올 수 있습니다.
이러한 문제를 해결하기 위해 반정규화를 선택할 수 있습니다. 반정규화란 데이터의 중복을 허용하는 방법입니다. 우리는 Review테이블을 통해 평균 평점이라는 정보를 알아낼 수 있지만, 중복을 허용해 평균 평점이라는 값을 Column으로 가지고 있을 수 있습니다.

이로써 Review테이블을 탐색하지 않고 곧바로 화면에 필요한 정보를 반환해줄 수 있게 되었습니다.
이렇게 되면 Review가 추가될 때마다 Product의 avg_rating도 새롭게 갱신해 줘야 합니다. Product의 avg_rating 계산을 쉽게 하기 위해 리뷰 개수까지 반정규화를 진행했습니다.
이제 Review가 추가되면 Review테이블 뿐만 아니라 Product테이블 까지 함께 갱신해줘야 합니다.
하지만 이는 언제까지나 시스템이 정상적인 상황만을 가정한 것입니다. 실제로는 시스템이 정상적으로 실행되지 않거나 예기치 못한 문제로 인해 한쪽의 동작이 원활히 실행되지 않을 가능성이 충분히 존재합니다. 이 경우 두 데이터 사이의 정합성이 일치하지 않게 됩니다.
앞으로도 시스템은 이따금씩 실패할 여지가 있고, avg_rating값은 점점 더 실제 평균 평점과 멀어지게 되어 결과적으로 반정규화한 데이터를 믿지 못해 이전처럼 Review테이블을 직접 탐색하게 될지도 모릅니다.
그래서 저는 개인적으로 처음부터 반정규화를 고려하는 걸 선호하지 않고, 서비스를 운영하다가 성능적으로 너무 큰 손해를 본다고 생각할 때 반정규화를 사용하는 게 좋다는 입장입니다.
또한 지금 예시처럼
약간의 정합성 불일치 정도는 무시되어도 괜찮은 경우에만 반정규화 사용이 가능하다고 생각합니다. 통잔잔고와 같이 중요한 데이터라면 반정규화의 사용을 최대한 고려하지 않을 것이며 사용하더라도 정말 많은 고민을 할 거 같습니다.반면 지금과 같은 예시에서는 100개의 리뷰가 존재한다고 했을 때 실제 평균 평점이 4.75인데 그게 화면상 4.74로 표시된다고 해서 서비스에는 전혀 치명적이지 않으며, 오히려 쇼핑몰 화면이 빠르게 보여지는게 유저 관점에서 더 유의미하다고 생각합니다.
데이터의 정합성을 맞추기 위해 주기적으로 데이터의 정합성을 맞추는 방법을 선택할 수 있습니다. 가령, 매일 00시마다 Review테이블에서 계산을 실행해 Product테이블의 avg_rating과 값이 일치하지 않는다면 최신의 값으로 업데이트 해줄 수 있을 겁니다.
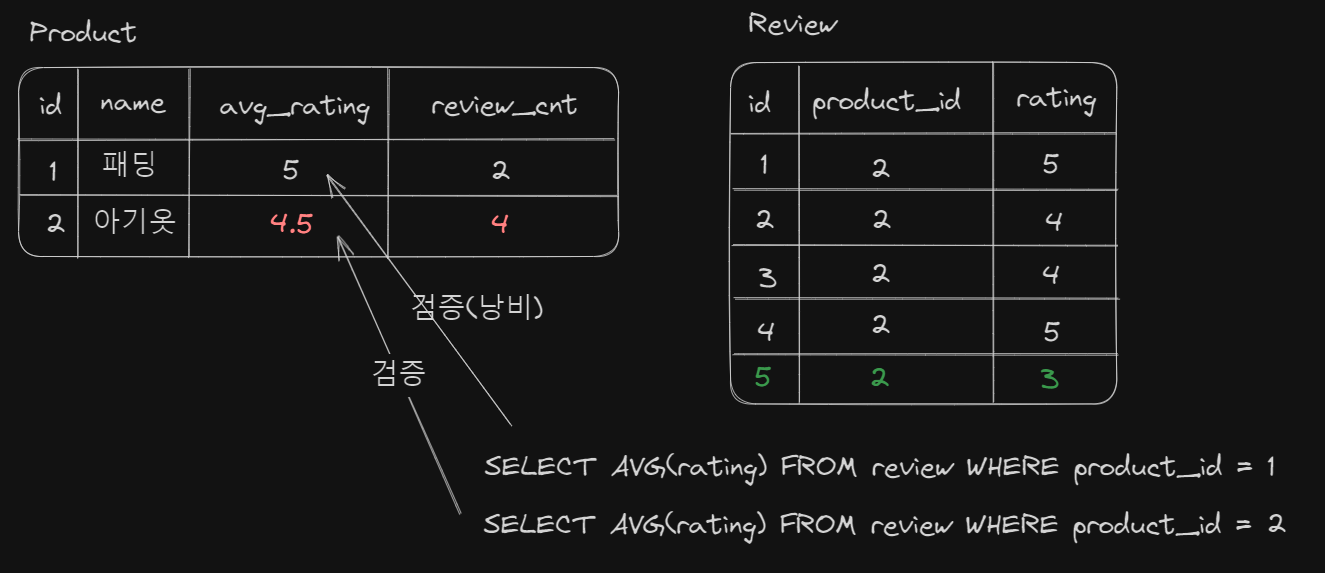
하지만 여기서도 낭비가 발생할 수 있습니다. Product테이블에 있는 모든 상품에 대해 매번 정합성 검증을 실행해야 할까요? 예시 테이블의 경우 '패딩' 상품은 새롭게 리뷰가 추가되지 않았으므로 굳이 00시에 정합성을 검증할 필요가 없습니다.
개선 방법

위 사진처럼 리뷰가 작성된 상품의 id를 따로 저장해두고, 해당 상품들만 정합성을 확인하는 방식으로 이전에 언급한 문제를 해결할 수 있습니다.
또한 Review와 changed_product는 동일한 데이터베이스로 하나의 트랜잭션으로 관리해 changed_product만 기록되지 않는 경우도 발생하지 않습니다.
같이 공부해보면 좋은 내용
- jpa envers
