
문제 설명
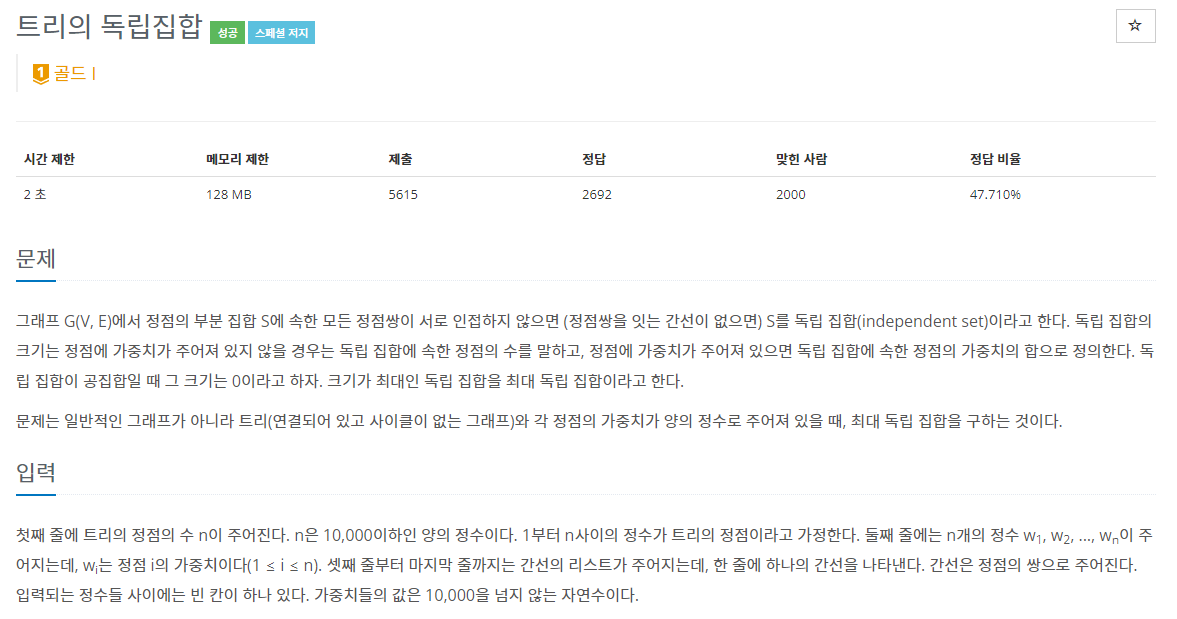
- https://www.acmicpc.net/problem/2213
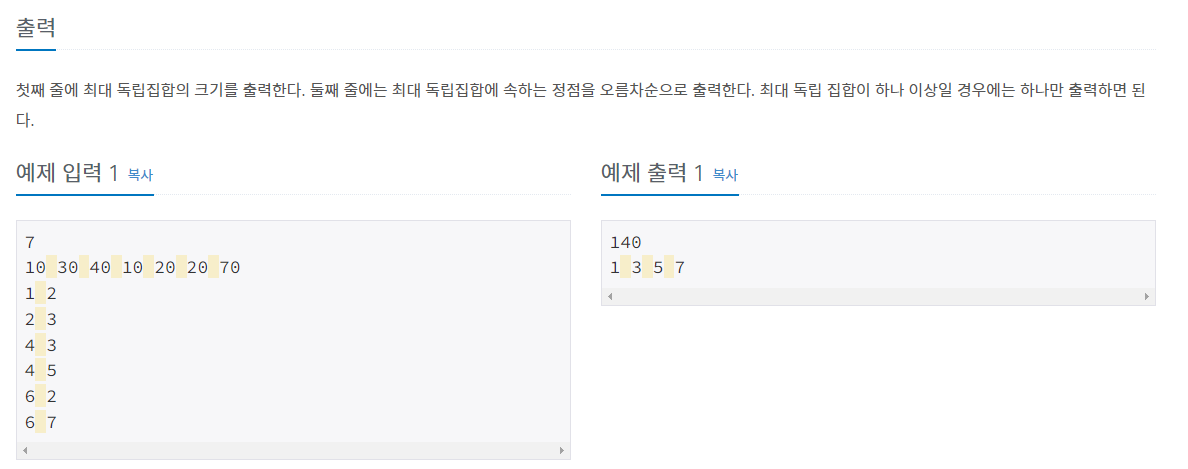
- 크기가 최대인 독립집합의 크기, 그리고 속한 정점의 번호를 구하는 문제입니다.
독립집합이란 선택된 노드들이 인접하지 않는 집합을 말합니다.
접근법
- 문제에서 트리가 주어진다고 명시되었기 때문에 트리를 구현합니다.
- 트리를 만들면서 메모이제이션을 통해
독립집합의 크기를 먼저 구합니다.
dp[0][i] = i를 root로 하는 트리에서 i번째 노드를 선택했을 때 최대 독립집합의 크기
dp[1][i] = i를 root로 하는 트리에서 i번째 노드를 선택하지 않았을 때 최대 독립집합의 크기 - i를 선택하면(dp[0][i]) i와 인접한 모든 노드는 선택하지 않아야 합니다.(dp[1][next])
- i를 선택하지 않으면(dp[1][i]) i와 인접한 노드는
선택할 수도 있고 선택하지 않을 수도 있습니다.여기서 i가 선택되지 않았다고 i-1번째가 반드시 선택되어야 하는 건 아니라는 게 중요합니다. - 독립집합의 크기를 모두 구한 뒤 해당 독립집합에 포함된 값을 구합니다.
기본적으로dp[0][i] > dp[1][i]면 i노드를 선택하는 게 선택하지 않는 것보다 더 유리하다는 의미이므로 i가 최대 독립집합에 포함되는 걸로 생각할 수 있습니다.- 하지만 이렇게만 설정하면 반례가 발생할 수 있습니다. 이러한 반례가 발생하는 이유는 모든 리프노드들은 dp[1][i]가 0이기 때문에
dp[0][i] > dp[1][i]를 만족하게 됩니다. 하지만 위 링크에 있는 경우처럼 리프노드를 사용하지 않는 경우도 발생하기 때문에 조금 더 조건을 추가해줘야 합니다. - 이 문제의 핵심은
i를 선택하면 i와 인접한 노드를 선택할 수 없다이기 때문에 해당 조건을 역추적에도 동일하게 적용해 줍니다.parentContainedInSet변수로 해당 노드를 선택했다면 다음 노드는 선택할 수 없도록 만들어 줬습니다.
- 하지만 이렇게만 설정하면 반례가 발생할 수 있습니다. 이러한 반례가 발생하는 이유는 모든 리프노드들은 dp[1][i]가 0이기 때문에
정답
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int[] arr = new int[N+1];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 1; i <= N; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
Map<Integer,List<Integer>> graph = new HashMap<Integer,List<Integer>>();
for (int i = 0; i < N-1; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
makeGraph(graph,a,b);
makeGraph(graph,b,a);
}
int[][] dp = new int[2][N+1];
boolean[] v = new boolean[N+1];
DFS(1,0,graph,v,arr,dp);
StringBuilder sb = new StringBuilder();
sb.append(Math.max(dp[0][1], dp[1][1]));
sb.append("\n");
boolean[] v2 = new boolean[N+1];
List<Integer> independentSet = new ArrayList<Integer>();
BackT(graph,dp,1,v2,false,independentSet);
Collections.sort(independentSet); // 트리에서 DFS로 선택한 노드는 오름차순으로 정렬되어 있지 않기 때문에 직접 정렬을 해 줍니다.
for (Integer val : independentSet) {
sb.append(val);
sb.append(" ");
}
System.out.println(sb.toString());
// for (int i = 0; i < 2; i++) {
// System.out.println(Arrays.toString(dp[i]));
// }
}
public static void BackT(Map<Integer,List<Integer>> graph, int[][] dp, int now, boolean[] v, boolean parentContainedInSet, List<Integer> independentSet) {
v[now] = true;
//부모노드의 포함여부(parentContainedInSet)가 없으면 리프노드는 항상 dp[0][now] > dp[1][now]이기 때문에 반드시 선택되는 오류가 발생합니다.
if(!parentContainedInSet && dp[0][now] > dp[1][now]) {
independentSet.add(now);
parentContainedInSet = true;
}else {
parentContainedInSet = false;
}
if(!graph.containsKey(now)) return;
for(int next: graph.get(now)) {
if(v[next]) continue;
v[next] = true;
BackT(graph,dp,next,v,parentContainedInSet,independentSet);
}
}
public static void DFS(int now, int prev, Map<Integer,List<Integer>> graph, boolean[] v, int[] arr, int[][] dp) {
v[now] = true;
dp[0][now] = arr[now];
if(graph.containsKey(now)) {
for (int next : graph.get(now)) {
if(v[next])continue;
DFS(next,now,graph,v,arr,dp);
// now를 선택하면 인접한 next들을 선택하지 않았을 때의 누적값을 모두 더한다.
dp[0][now] += dp[1][next];
// now를 선택하지 않으면 인접한 next에 대해 선택하거나 선택하지 않거나 상관없다.
dp[1][now] += Math.max(dp[0][next], dp[1][next]);
}
}
}
public static void makeGraph(Map<Integer,List<Integer>> graph, int from, int to) {
if(graph.containsKey(from)) {
graph.get(from).add(to);
}else {
List<Integer> temp = new ArrayList<Integer>();
temp.add(to);
graph.put(from, temp);
}
}
}
기록하고 정리하는 걸 좋아하는 백엔드 개발자입니다.