
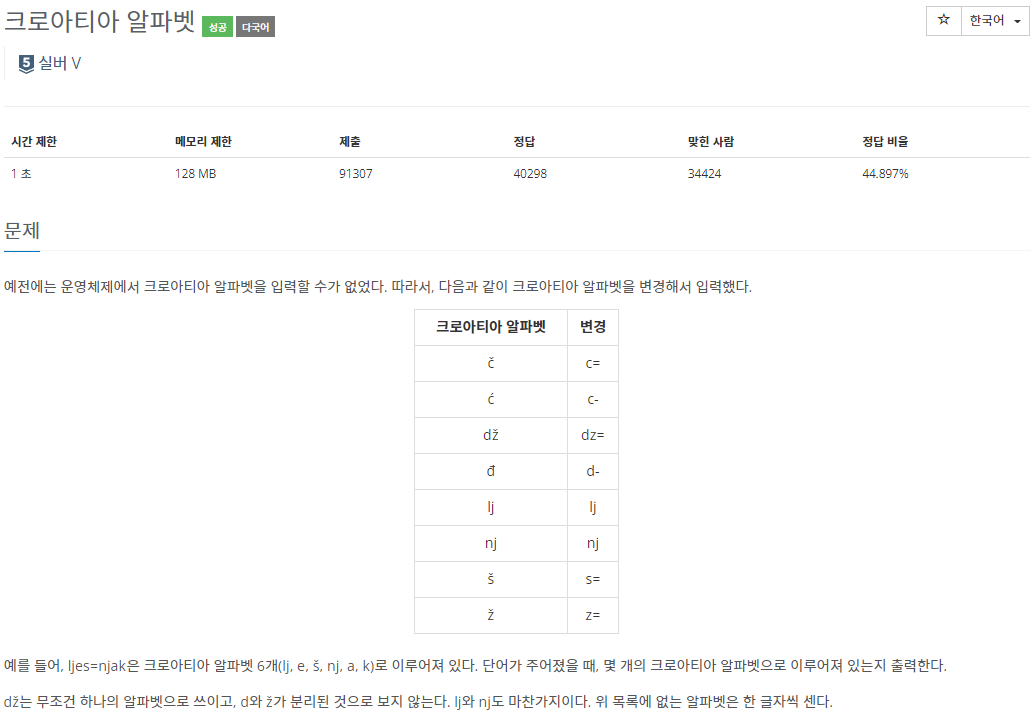
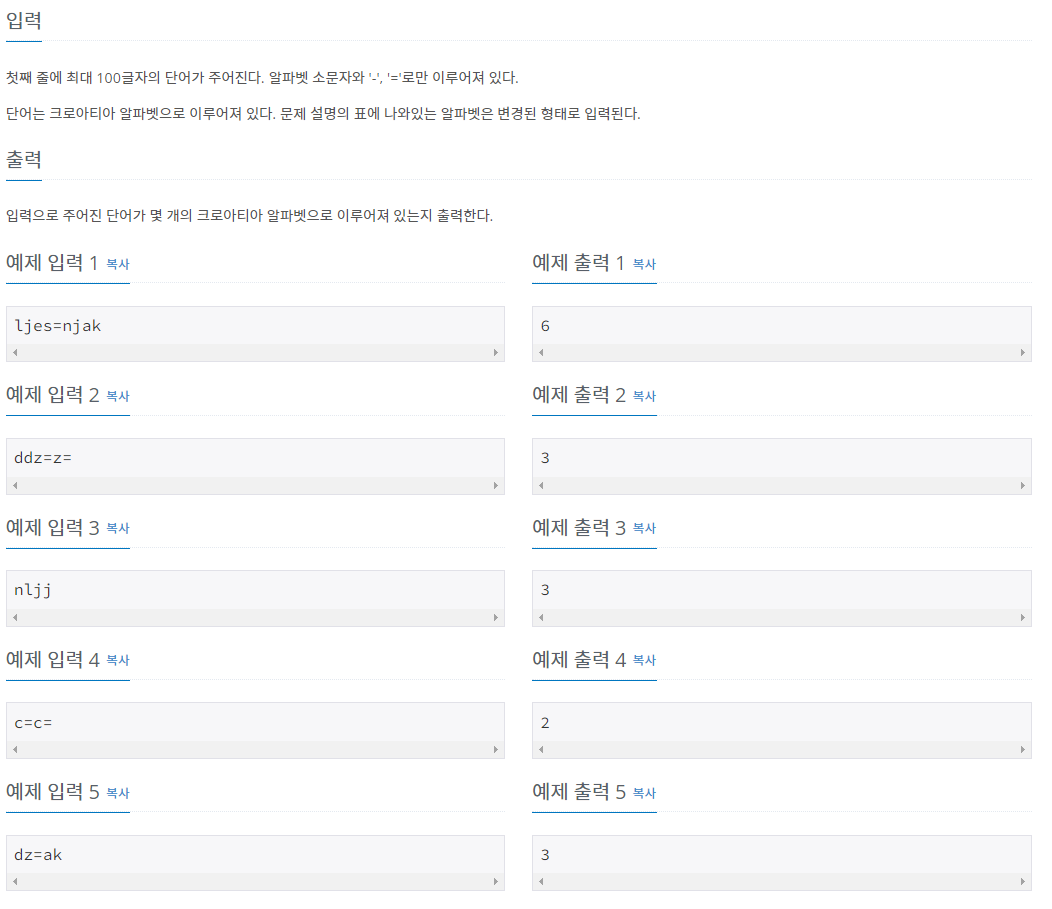
문제 설명
- 크로아티아 알파벳 + 이를 제외한 일반 알파벳의 개수를 구하는 문제입니다.
접근법
-
한번에 처리할 좋은 방법이 보이지 않습니다.
-
저는 크로아티아 알파벳을 제거하는 방향으로 문제를 풀었습니다.
- 하지만 문제가 생겨 크로아티아 알파벳의 개수를
-
크로아티아 알파벳을 다룰때 몇가지 유의사항이 있습니다.
-
dz=와 z=는 상당히 유사합니다. (예제 2번)
- dz=를 d와z=로 인식해도 안되며, dz=를 dz=와 z=로 두번 인식해도 안됩니다.
-
크로아티아 알파벳을 제거하면 가짜 크로아티아 알파벳이 생길 수 있습니다. (예제 3번)
- lj를 제거하고나면 문자열이 n과j만 남습니다. 하지만 이는 크로아티아 알파벳 nj가 아닙니다.
- 즉 크로아티아 문자열을 제거한다기보다 다른 방식으로 표현해야 합니다.
- 저는 띄어쓰기로 replace해 위와같은 문제를 방지했습니다.
n j로 표현해 크로아티아 알파벳으로 잘못 읽히는 걸 방지했습니다.
- 저는 띄어쓰기로 replace해 위와같은 문제를 방지했습니다.
-
정답
import java.io.*;
import java.util.*;
class Main {
// dz=와z=를 어떻게 처리할 것인가
public static void main(String[] args) throws IOException {
String[] Croatia = { "c=", "c-", "d-", "lj", "nj", "s=", "z=" }; // dz=는 제외
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String S = br.readLine();
int cnt = 0;
// dz=만 길이가 3이고, z=보다 먼저 처리해야 하기 때문에 따로 처리합니다.
// z=보다 빨라야 하는 이유는 z=는 dz=를 d와z=로 인식해 버리기 때문입니다.
for (int i = 0; i < S.length() - 2; i++) {
if (S.substring(i, i + 3).equals("dz=")) cnt++; // 여기서 dz=를 제거하지 않고 개수만 셌다가
}
S = S.replaceAll("dz=", " "); // 여기서 한번에 문자열 제거를 진행합니다.
for (int j = 0; j < Croatia.length; j++) {
for (int i = 0; i < S.length() - 1; i++) {
if (S.substring(i, i + 2).equals(Croatia[j])) cnt++;
}
// 처음에 S.replaceAll(Croatia[j], " ")를 했는데 예제3에서 오류가 발생했습니다. lj가 없어진 후 nj를 크로아티아 문자로 인식해 버렸습니다.
S = S.replaceAll(Croatia[j], " "); // 중간이 없어지면서 생긴 문자를 크로아티아 문자로 인식하는걸 방지합니다.
}
S = S.replaceAll(" ", ""); // 임시로 띄어쓰기한 걸 다시 붙여줍니다.(띄어쓰기도 length에 포함되기 대문에 없애야 합니다)
System.out.println(cnt + S.trim().length());
}
}
기록하고 정리하는 걸 좋아하는 백엔드 개발자입니다.