
⚙️백엔드 관점에서 생각해볼만한 서비스 고도화
우테크(우아한 기술 블로그)에서 입점요청 승인툴 고도화에 대해서 정리해놓은 글이 있어서 이를 분석해보며 이해해보도록 한다.
개요
우아한 형제들의 대표 서비스 배달의 민족에서는 입점자가 판매를 시작하기 전 준비해서 업로드해야하는 데이터들은 이렇다.
- 가게의 기본 정보
- 사업자정보, 영업신고증 등 각종 인허가 서류
- 영업시간, 휴무정보, 매장 사진
- 배달팁, 배달 시간, 배달지역 정보
- 메뉴 사진, 메뉴 정보
- 주문 대금을 위한 정산 정보
- 등등등...
이러한 정보들을 온라인 계약서 형태로 등록한다고 한다.
내부 승인팀이 이렇게 받아온 데이터를 확인하여 검수하고 배달의 민족 어플리케이션에 입점시키는 방식이다.
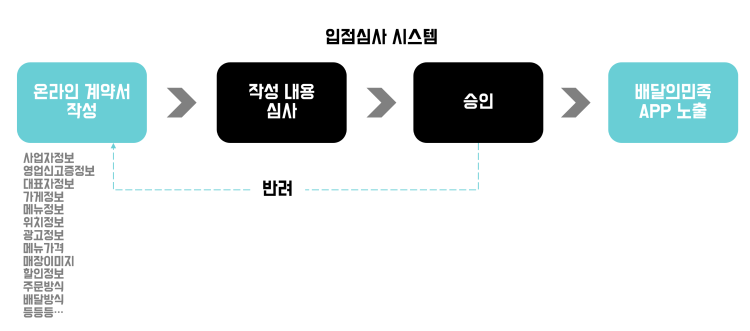
이 과정을 요청-심사 프로세스 라고 칭하며 이 프로세스가 운영되는 SUPER2 승인툴 어드민을 고도화 했다고 한다. 어떻게 고도화 하였는지 알아보자.
문제점 파악
일단 업로드된 데이터들은 각 담당자에 맞는 요청을 자동으로 분배해주는 자동분배 시스템 기반으로 운영되고 있다고 한다. 한 쪽으로 너무 몰리지 않는 한 카테고리를 기준으로 요청을 분배해주는 것 같다.
✅첫째, 승인 작업자들의 작업현황 파악의 어려움
한 팀에 배치된 데이터들은 업무자 각자가 자신의 업무를 피킹해가는 구조였다고 한다. 이 과정에서 누락하는 업무도 생기고 업무의 진행도를 한 번에 파악하기 위해서 매번 새로고침을 해야하는 문제점이 존재
✅둘째, 승인 업무 총괄자가 전체 현황을 알기가 힘듦
관리자가 병목구간을 해소하기 위해서 전체의 흐름을 알아야 하는데 이를 한 번에 확인할 수 있는 방법이 없어 매번 메신저로 진행정도를 확인했다고 한다.
이 문제들을 토대로 두 가지 해결방안을 제시함.
👉승인 작업자가 개인의 업무를 빨리 해결할 수 있게, 개인 업무 관리 고도화
👉관리자가 전체 현황을 효율적으로 트래킹 할 수 있게, 업무현황보드 개발
개인 업무 관리
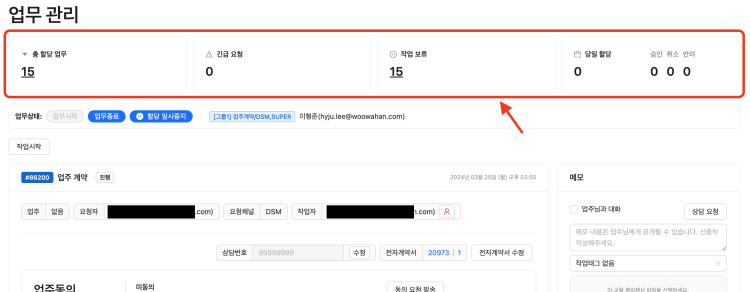
개인 업무 현황을 확인할 수 있도록 업무 관리 화면 상단에 상단 보드를 제공, 매번 필터를 설정해 조회해야하는 번거로움을 해결했다고 한다.
(총 할당 업무, 보류 작업, 중요 정보 제공)
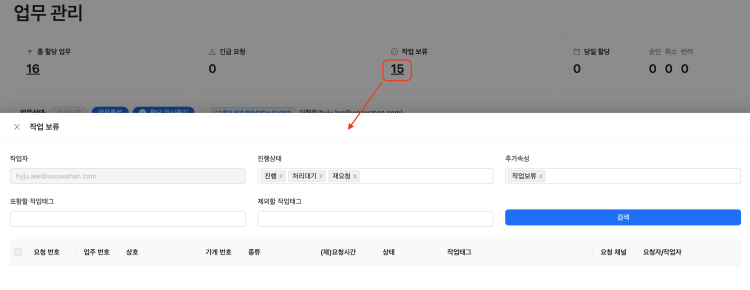
기존 요청 관리 화면의 일부를 레이어로 제공하며 기본 필터를 제공했다고 한다.
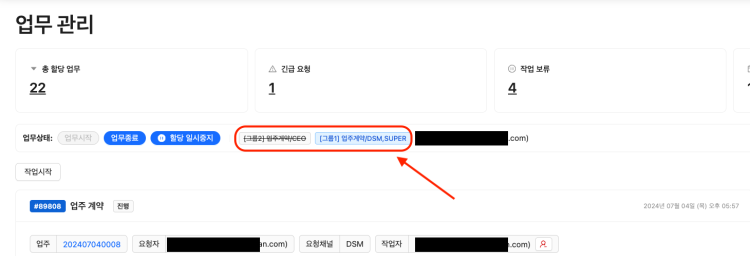
수동으로 그룹 설정하던 것을 수정하여 자동으로 그룹 설정이 가능하게 만들었다고 함.
다음은 사용자 경험의 쾌적함을 더욱 향상시키기 위한 핵심 개선 방안 4가지이다.
-
색상 대비와 사용성 향상

웹 콘텐츠 접근성 가이드라인 (WCAG) 에서는 색상 대비에 관한 명확한 기준을 제시하고 있다. 기준 확인하기
AA 등급을 기준으로 설정해주면 클릭이나 터치의 상호작용 유도를 더욱 직관적이고 쉽게 만들어줄 수 있다. (상호작용에 따른 동적 변화도 고려해야함)
2. 특정 상태를 컬러로만 표현하지 않기

색상은 시작적으로 중요한 요소이지만 색약자들을 위한 추가적인 정보를 더해 누구나 쉽게 상태에 대한 이해를 할 수 있도록 해야한다.
3. 사용자의 특정 액션에 대한 취소를 가능하게 하고 수행을 어렵게 만들어 리스크 줄이기
한 번의 클릭으로 중요한 데이터를 삭제하거나, 잘못된 데이터를 생성할 수 있으니 이를 되돌릴수 있도록 만들고 신중하게 처리해야하는 행위는 수행을 어렵게 만들어야 함
-
페이지네이션 사용하기

인피니티 스크롤은 피드처럼 지속적으로 탐색한 콘텐츠에 대해서는 적합하지만 업무 목적으로는 페이지네이션이 적합할 수 있다. (DB에 부담이 갈 수 있지만 사용자 경험 측면에서는 더 좋다는 이야기)
업무 현황 보드
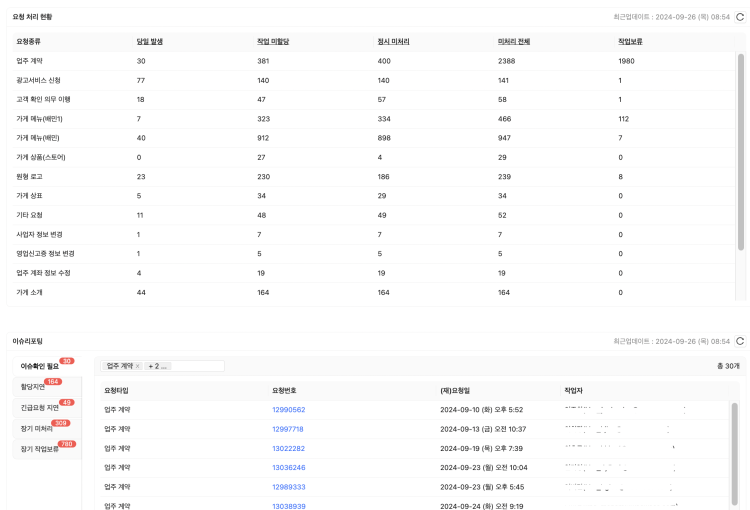
업무 현황 보드는 관리자가 승인 작업자들의 업무 상태와 요청 처리 현황등을 실시간에 근접하게 확인할 수 있음.
당일 처리 업무나 누락 업무를 확인하기가 더욱 쉬워지고 처리량을 확인함에 따라 인원이나 업무 배분 즉, 의사 결정이 빨라지므로 생산성 향상에 직결적으로 도움을 줌.
하지만 실시간 데이터 조회는 DB에 큰 부담을 주기 때문에 안정적으로 데이터를 전달하기 위한 방법을 모색했다고 함.
여기서는 세 가지 방법을 제시했는데 1) 캐싱, 2) 배치, 3) 스케쥴러 의 방법들이 후보였음.
Cache
캐시방식은 데이터 조회 시 반복적으로 발생하는 동일한 요청에 대해 빠르게 응답하기 위해 사용됩니다. 데이터를 조회한 뒤 인메모리 DB 에 저장하고 이후에는 인메모리 DB에 저장된 데이터를 활용하여 DB 조회 부담을 줄일 수 있다고 함.
하지만 캐싱에는 단점이 존재하는데
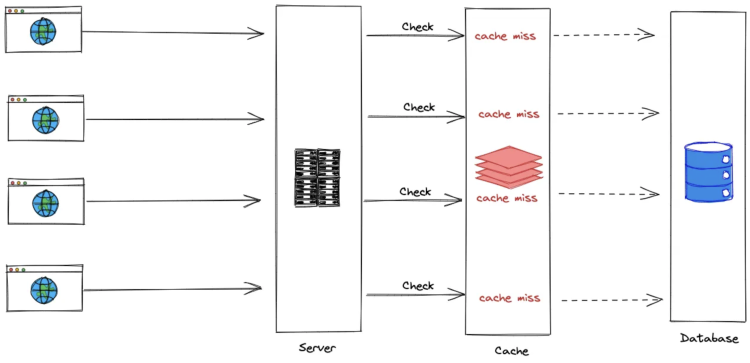
- 초기 조회 성능의 문제
결국 처음에는 실제 DB 조회가 필요하므로 큰 사이즈의 데이터를 여러 군데에서 요청한다면 (Cache Stampede) 성능 저하가 일어나게 됩니다. 이를 해결하기 위해 분산 락 (Distribute Lock) 매커니즘을 활용할 수 있지만 이는 구현 복잡성 증가, 운영 및 유지 보수 부담 등의 새로운 문제를 불러일으킬 수 있습니다. - 저장 데이터 크기의 문제
캐시로 저장해야할 업무 데이터가 10MB 를 넘어 메모리 사용량이 급격히 증가한다는 단점이 존재합니다. RDB 의 인덱스를 활용할 수도 없어 크게 비효율적이라고 판단 Batch
주기적으로 데이터를 조회 및 처리하여 별도의 통계 테이블에 저장 후 업무 현황 조회 시 통계 테이블에서 데이터를 가져오는 방식입니다. DB에 실시간 부하를 최소화하고 RDB 의 인덱싱 기법을 활용할 수 있는 점에서 대용량 데이터의 효율적인 조회가 가능합니다. 하지만 추가적인 오버헤드가 발생하기 때문에 초기화 작업이 수 분 단위로 소요되어 처리 속도가 느려지게 되어 실시간성이 떨어집니다.Scheduler
배치 방식과 비슷하게 일정한 주기로 데이터를 처리하고 저장하는 방법이지만 더 자주 실행되어 실시간에 가까운 데이터를 제공할 수 있습니다. 캐시의 속도와 배치의 대규모 데이터 처리의 이점을 모두 결합한 방식이라고 생각해도 될 것 같습니다.
정리해보자면 캐시 방식은 빠른 응답 속도와 효율적인 메모리 활용이 장점이지만 첫 조회시 발생하는 성능 저하와 대용량 데이터 처리에서 한계가 존재했습니다. 배치 방식은 대규모 데이터 처리에서 효과적이지만 실시간성을 보장하지 못합니다.
마지막으로 스케줄러 방식은 준 실시간성과 시스템 부하간의 균형을 유지하며 유연한 처리가 가능했습니다.
따라서 업무 현황 보드와 같은 준실시간 데이터 조회가 필요하고 데이터 크기가 큰 시스템에서는 스케쥴러 방식이 가장 적합하다고 합니다.
마지막으로, 업무 현황 보드에서 중요하게 사용되는 항목인 정시 미처리 요청 집계 를 구현하며 고민했던 점을 작성해주셨습니다.
승인 작업자에게 특정 시간까지 반드시 처리하도록 가이드하는 기준인 정시 미처리 요청 은 정해진 기준 시간 내에 처리되지 않은 요청이 몇 건인지 집계하여 보여주는 요소로 관리자가 확인하고 늦어지는 요청을 처리할 수 있도록 도와주는 항목.
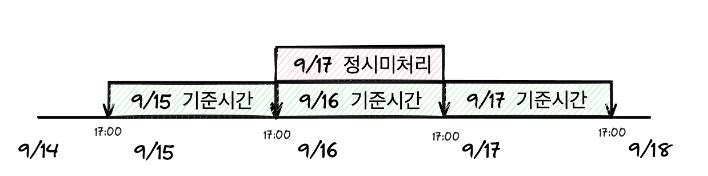
예시로 A 타입의 정시 미처리를 조회하려면 아래와 같은 쿼리가 발생하는데
SELECT count(*)
FROM request # 요청 테이블
WHERE request.created '2024-09-13 17:00:00' # 어제 기준시간(2일전 17시) 이후에 생성된 요청
AND request.status != 'ACCEPTED' # 완료(ACCEPTED) 상태가 아닌 요청
AND request.type = 'A'; # 요청 종류 A15 가지 타입별로 서로 다른 기준의 createdAt 을 적용해 카운트 해야하는 점을 해결하기 위해 가장 넓은 범위의 createdAt 을 사용하여 Application 레벨에서 필터링하여 카운팅 하는 방식으로 문제를 해결했다고 합니다.
fun findNotAcceptedOnTimeRequestCounts(today: LocalDate): Map<RequestType, Int> {
return requestQueryService.findNotAcceptedOnTime(today)
.filter { isAcceptedOnTime(it.type, it.createdAt, today) }
.groupingBy { it.type }
.eachCount()
}
private fun isAcceptedOnTime(requestType: RequestType, createdAt: LocalDateTime, today: LocalDate): Boolean {
return when (requestType) {
// 전일 0시~오늘 0시
RequestType.C, RequestType.D, RequestType.E ->
createdAt.isAfter(today.minusDays(1).atStartOfDay()) && createdAt.isBefore(today.atStartOfDay())
// 전일 12시~오늘 12시
RequestType.B, RequestType.F ->
createdAt.isAfter(today.minusDays(1).atTime(12, 0)) && createdAt.isBefore(today.atTime(12, 0))
// 전일 17시~오늘 17시
else ->
createdAt.isAfter(today.minusDays(1).atTime(17, 0)) && createdAt.isBefore(today.atTime(17, 0))
}
}그런데 여기서 비즈니스 요구 사항이 하나 더 늘어나 해당 요청들의 상세 목록을 페이지네이션 형태로 보여줘야 하게 되었다고 합니다. 이때 기존 방식으로 필터링 하는데에 어려움을 겪었다고 합니다.
이 문제는 QueryDSL 을 이용해 쿼리내 모든 조건을 OR 절로 추가해 각 요청 타입별 기준 시간에 따라 데이터를 추출하도록 변경했다고 합니다.
일반적으로 or 절을 많이 사용하면 성능 저하가 발생하지만 이 작업은 스케쥴러를 활용해 유동적으로 주기를 변경할 수 있었기 때문에 성능에 미치는 영향을 최소화 했다고 합니다.
fun findOnGoingNotAcceptedWithPagination(
requestTypes: List<RequestType>,
page: Long,
size: Long,
today: LocalDate,
): PaginationRequestResult<SimpleRequest> {
val results = jpaQueryFactory
.selectFrom(request)
.where(onGoingNotAcceptedCondition(requestTypes, today))
.offset(((page - 1) * size))
.limit(size)
.orderBy(request.createdAt.asc())
.fetchResults()
return PaginationRequestResult(results.results, page, size, results.total)
}
private fun onGoingNotAcceptedCondition(
requestTypes: List<RequestType>,
today: LocalDate
): BooleanBuilder {
val booleanBuilder = BooleanBuilder()
val createdAtCondition = BooleanBuilder()
requestTypes.forEach {
val condition = when (it) {
// 전일 0시~오늘 0시
RequestType.C, RequestType.D, RequestType.E ->
request.createdAt.between(today.minusDays(1).atStartOfDay(), today.atStartOfDay())
// 전일 12시~오늘 12시
RequestType.B, RequestType.F ->
request.createdAt.between(today.minusDays(1).atStartOfDay(), today.atTime(12, 0))
// 전일 17시~오늘 17시
else ->
request.createdAt.between(today.minusDays(1).atTime(17, 0), today.atTime(17, 0))
}
createdAtCondition.or(request.type.eq(it).and(condition))
}
booleanBuilder.and(request.status.ne(RequestStatus.ACCEPTED))
booleanBuilder.and(createdAtCondition)
return booleanBuilder
}SELECT
request.id,
request.type,
request.sort_time
FROM
request
WHERE
request.status != 'ACCEPTED'
AND (
(request.type = 'C' OR request.type = 'D' OR request.type = 'E')
AND request.created_at BETWEEN '2024-09-14 00:00:00' AND '2024-09-15 00:00:00'
OR
(request.type = 'B' OR request.type = 'F')
AND request.created_at BETWEEN '2024-09-14 00:00:00' AND '2024-09-15 12:00:00'
OR
(request.type NOT IN ('B', 'C', 'D', 'E', 'F'))
AND request.created_at BETWEEN '2024-09-14 17:00:00' AND '2024-09-15 17:00:00'
)
ORDER BY request.created_at ASC
LIMIT 20;이러한 접근법으로 요청별 기준 시간에 따라 데이터를 조회하고 페이지네이션 형태로 상세 목록 제공이 가능해졌다고 합니다.
결론
이러한 관리가 시스템 내에서 자동으로 이루어짐에 따라
관리자 기준 일 190분, 작업자 기준 일 900분의 불필요한 업무시간이 감소된 것으로 측정되었습니다.
또한 관리자와 작업자 모두 업무 현황을 효과적으로 트래킹할 수 있게 되면서 요청의 처리율도 크게 개선되었는데요. 광고 신청 요청을 기준으로, 개선 전에는 66.6%였던 요청의 당일 처리율이 개선 후 꾸준히 상승하며 최고 82.0%까지 올라가게 되었어요.
이러한 결과를 도출했다고 합니다.
이번 글은 사용자 경험과 데이터 관리가 얼마나 중요한 것인지 깨닫는 글이였다.
출처
