
22.7 문제: 삽입 정렬 뒤집기(ID:INSERTION)
문제
유명한 정렬 알고리즘인 삽입 정렬은 정렬된 부분 배열을 유지하며 이 배열에 새 원소를 삽입해 나가는 식으로 동작합니다. 주어진 정수 배열 A를 정렬하는 삽입 정렬의 구현은 다음과 같습니다.
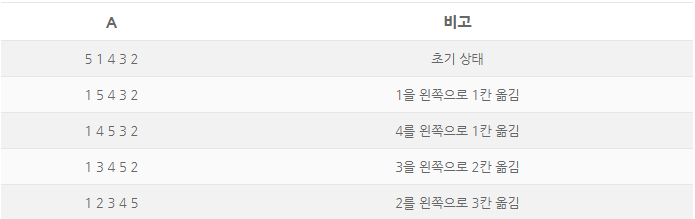
void insertionSort(vector<int>& A) { for(int i = 0; i < A.size(); ++i) { // A[0..i-1] 에 A[i] 를 끼워넣는다 int j = i; while(j > 0 && A[j-1] > A[j]) { // 불변식 a: A[j+1..i] 의 모든 원소는 A[j] 보다 크다. // 불변식 b: A[0..i] 구간은 A[j] 를 제외하면 정렬되어 있다. swap(A[j-1], A[j]); --j; } } }삽입 정렬은 A[0..i-1] 이 정렬된 배열일 때, A[i] 를 적절한 위치를 만날 때까지 왼쪽으로 한칸씩 움직입니다. 예를 들어 A={5,1,4,3,2} 의 삽입 정렬은 다음과 같이 이루어집니다.
1부터 N까지의 자연수가 한 번씩 포함된 길이 N 인 수열 A[] 를 삽입 정렬했습니다. 원래 수열은 알 수 없지만, 그 과정에서 각 원소가 왼쪽으로 몇 칸이나 이동했는지를 알고 있습니다. 예를 들어, 위 예제에서 각 위치에 있는 값들이 움직인 칸수를 표현하면 {0,1,1,2,3} 이 됩니다. 이 때 원래 수열을 찾아내는 프로그램을 작성하세요.입력
입력의 첫 줄에는 테스트 케이스의 수 C (1 <= C <= 50) 가 주어집니다. 각 테스트 케이스의 첫 줄에는 원 배열의 길이 N (1 <= N <= 50000) 이 주어집니다. 그 다음 줄에 N 개의 정수로 A의 각 위치에 있던 값들이 움직인 칸수가 주어집니다. A 는 1부터 N 까지의 정수를 한 번씩 포함합니다.
입력의 양이 많으므로 가능한 빠른 입력 함수를 사용하는 것이 좋습니다.출력
각 테스트 케이스마다 재구성한 A[] 를 한 줄에 출력합니다
예제 입력
2 5 0 1 1 2 3 4 0 1 2 3예제 출력
5 1 4 3 2 4 3 2 1
First Thoughts
삽입 정렬의 기본 원리
일단 문제를 읽고 두가지 구문이 눈에 띄었다. "삽입 정렬", "왼쪽으로 이동". 삽입 정렬의 특성이 자기자신을 기준으로 왼쪽 부분은 정렬이 되어있고 그 정렬된 부분의 원소들과 자기 자신을 비교함으로써 적절한 위치에 삽입하는 것이다. 그렇다면 각 정수가 움직이기 위해서는 기본적으로 자기 앞에 큰 원소들이 위치해있어야한다. 이를 베이스로 코드를 작성하였다.
My Code
#include <iostream>
#include <algorithm>
#include <string.h>
using namespace std;
int movement[50000];
typedef int KeyType;
struct Node {
//노드에 저장된 원소
KeyType key;
//노드의 우선순위,노드를 루트로 하는 서브트리의 크기
int priority, size;
//두 자식 노드의 포인터
Node* left, * right;
//생성자에서 난수 우선순위를 생성하고 size와 left/right를 초기화
Node(const KeyType& _key) :key(_key), priority(rand()), size(1), left(NULL), right(NULL) {}
void setLeft(Node* newLeft) { left = newLeft; calcSize(); }
void setRight(Node* newRight) { right = newRight; calcSize(); }
//size멤버 갱신
void calcSize() {
size = 1;
if (left)
size += left->size;
if (right)
size += right->size;
}
};
typedef pair<Node*, Node*> NodePair;
NodePair split(Node* root, KeyType key) {
//공백의 트리인경우
if (root == NULL)
//트리가 없음
return NodePair(NULL, NULL);
//root의 key가 node의 key보다 작은 경우
if (root->key < key) {
//root의 오른쪽 부트리에서 node의 key보다 작은 경우나 큰 경우 나누기
NodePair rs = split(root->right, key);
//나눈 트리 중 node의 key값보다 작은 트리(root의 key값보다는 큰 트리=>오른쪽 트리)를 현재 root의 오른쪽 트리로 설정
root->setRight(rs.first);
//현재 부트리는 root가 루트노드인 경우와 쪼개진 트리의 node의 key보다 큰 원소의 트리로 이루어진 두개의 부트리 반환
return NodePair(root, rs.second);
}
//root의 key가 node의 key보다 큰 경우
//root의 key보다 원소값이 작은 왼쪽 부트리를 key값과 비교하여 트리 생성
NodePair ls = split(root->left, key);
//나눈 트리 중 node의 key값보다 큰 트리(root의 key값보다는 작은 트리=>왼쪽 트리)를 현재 root의 왼쪽 트리로 설정
root->setLeft(ls.second);
//현재 부트리는 root가 루트노드인 오른쪽 트리와 쪼개진 트리의 node의 key보다 작은 원소의 트리인 왼쪽 부트리로 이루어진 두개의 부트리 반환
return NodePair(ls.first, root);
}
Node* insert(Node* root, Node* node) {
//공백의 트리라면 새로운 노드만 반환
if (root == NULL)
return node;
//root의 우선순위보다 node의 우선순위가 높은 경우
if (root->priority < node->priority) {
//왼쪽,오른쪽 트리 생성
NodePair splitted = split(root, node->key);
//node를 루트로 하고 node보다 작은 원소들이 모인 왼쪽 부트리와
node->setLeft(splitted.first);
//node보다 큰 원소들이 모인 오른쪽 부트리를 node에 잇는다
node->setRight(splitted.second);
//이어진 node를 루트로 반환
return node;
}
//root의 우선순위보다 node의 우선순위가 작은 경우
//root의 왼쪽,오른쪽 부트리의 루트노드와 비교하며 진행
//node의 key가 root의 key보다 작은 경우
else if (node->key < root->key) {
//왼쪽 부트리로 이동
root->setLeft(insert(root->left, node));
}
//node의 key가 root의 key보다 큰 경우
else {
//오른쪽 부트리로 이동
root->setRight(insert(root->right, node));
}
//현재 root반환
return root;
}
Node* kth(Node* root, int k) {
//왼쪽 서브트리의 크기 계산
int leftSize = 0;
if (root->left != NULL)
leftSize = root->left->size;
//k가 왼쪽 서브트리 내부에 있을 경우
if (k <= leftSize)
//왼쪽 서브트리로 들어가 순회
return kth(root->left, k);
//왼쪽 트리의 사이즈와 현재 루트까지 합쳐서 k개
if (k == leftSize + 1)
//현재 root값 반환
return root;
//k가 오른쪽 서브트리에 있을 때
return kth(root->right, k - leftSize - 1);
}
Node* merge(Node* a, Node* b) {
if (a == NULL)
return b;
if (b == NULL)
return a;
if (a->priority < b->priority) {
b->setLeft(merge(a, b->left));
return b;
}
a->setRight(merge(a->right, b));
return a;
}
Node* erase(Node* root, KeyType key) {
if (root == NULL)
return root;
if (root->key == key) {
Node* ret = merge(root->left, root->right);
delete root;
return ret;
}
if (key < root->key) {
root->setLeft(erase(root->left, key));
}
else {
root->setRight(erase(root->right, key));
}
return root;
}
void reverse_insert(int N) {
int original[50000];
Node* root=NULL;
for (int i = 1; i <= N; i++) {
root = insert(root, new Node(i));
}
for (int i = N - 1; i >= 0; i--) {
int l = movement[i];
original[i] = kth(root, i + 1 - l)->key;
root = erase(root, original[i]);
}
for (int i = 0; i < N; i++) {
cout << original[i] << ' ';
}
}
int main(void) {
int C;
int N;
cin >> C;
for (int i = 0; i < C; i++) {
cin >> N;
for (int j = 0; j < N; j++) {
cin >> movement[j];
}
reverse_insert(N);
memset(movement, 0, sizeof(int)*N);
}
}Answer Code
//my_code
#include <iostream>
#include <algorithm>
#include <string.h>
using namespace std;
typedef int KeyType;
struct Node {
//노드에 저장된 원소
KeyType key;
//노드의 우선순위,노드를 루트로 하는 서브트리의 크기
int priority, size;
//두 자식 노드의 포인터
Node* left, * right;
//생성자에서 난수 우선순위를 생성하고 size와 left/right를 초기화
Node(const KeyType& _key) :key(_key), priority(rand()), size(1), left(NULL), right(NULL) {}
void setLeft(Node* newLeft) { left = newLeft; calcSize(); }
void setRight(Node* newRight) { right = newRight; calcSize(); }
//size멤버 갱신
void calcSize() {
size = 1;
if (left)
size += left->size;
if (right)
size += right->size;
}
};
typedef pair<Node*, Node*> NodePair;
NodePair split(Node* root, KeyType key) {
//공백의 트리인경우
if (root == NULL)
//트리가 없음
return NodePair(NULL, NULL);
//root의 key가 node의 key보다 작은 경우
if (root->key < key) {
//root의 오른쪽 부트리에서 node의 key보다 작은 경우나 큰 경우 나누기
NodePair rs = split(root->right, key);
//나눈 트리 중 node의 key값보다 작은 트리(root의 key값보다는 큰 트리=>오른쪽 트리)를 현재 root의 오른쪽 트리로 설정
root->setRight(rs.first);
//현재 부트리는 root가 루트노드인 경우와 쪼개진 트리의 node의 key보다 큰 원소의 트리로 이루어진 두개의 부트리 반환
return NodePair(root, rs.second);
}
//root의 key가 node의 key보다 큰 경우
//root의 key보다 원소값이 작은 왼쪽 부트리를 key값과 비교하여 트리 생성
NodePair ls = split(root->left, key);
//나눈 트리 중 node의 key값보다 큰 트리(root의 key값보다는 작은 트리=>왼쪽 트리)를 현재 root의 왼쪽 트리로 설정
root->setLeft(ls.second);
//현재 부트리는 root가 루트노드인 오른쪽 트리와 쪼개진 트리의 node의 key보다 작은 원소의 트리인 왼쪽 부트리로 이루어진 두개의 부트리 반환
return NodePair(ls.first, root);
}
Node* insert(Node* root, Node* node) {
//공백의 트리라면 새로운 노드만 반환
if (root == NULL)
return node;
//root의 우선순위보다 node의 우선순위가 높은 경우
if (root->priority < node->priority) {
//왼쪽,오른쪽 트리 생성
NodePair splitted = split(root, node->key);
//node를 루트로 하고 node보다 작은 원소들이 모인 왼쪽 부트리와
node->setLeft(splitted.first);
//node보다 큰 원소들이 모인 오른쪽 부트리를 node에 잇는다
node->setRight(splitted.second);
//이어진 node를 루트로 반환
return node;
}
//root의 우선순위보다 node의 우선순위가 작은 경우
//root의 왼쪽,오른쪽 부트리의 루트노드와 비교하며 진행
//node의 key가 root의 key보다 작은 경우
else if (node->key < root->key) {
//왼쪽 부트리로 이동
root->setLeft(insert(root->left, node));
}
//node의 key가 root의 key보다 큰 경우
else {
//오른쪽 부트리로 이동
root->setRight(insert(root->right, node));
}
//현재 root반환
return root;
}
Node* kth(Node* root, int k) {
//왼쪽 서브트리의 크기 계산
int leftSize = 0;
if (root->left != NULL)
leftSize = root->left->size;
//k가 왼쪽 서브트리 내부에 있을 경우
if (k <= leftSize)
//왼쪽 서브트리로 들어가 순회
return kth(root->left, k);
//왼쪽 트리의 사이즈와 현재 루트까지 합쳐서 k개
if (k == leftSize + 1)
//현재 root값 반환
return root;
//k가 오른쪽 서브트리에 있을 때
return kth(root->right, k - leftSize - 1);
}
Node* merge(Node* a, Node* b) {
if (a == NULL)
return b;
if (b == NULL)
return a;
if (a->priority < b->priority) {
b->setLeft(merge(a, b->left));
return b;
}
a->setRight(merge(a->right, b));
return a;
}
Node* erase(Node* root, KeyType key) {
if (root == NULL)
return root;
if (root->key == key) {
Node* ret = merge(root->left, root->right);
delete root;
return ret;
}
if (key < root->key) {
root->setLeft(erase(root->left, key));
}
else {
root->setRight(erase(root->right, key));
}
return root;
}
int n, shifted[50000];
int A[50000];
void solve() {
Node* candidates = NULL;
for (int i = 0; i < n; i++) {
candidates = insert(candidates, new Node(i + 1));
}
for (int i = n - 1; i >= 0; i--) {
int larger = shifted[i];
Node* k = kth(candidates, i + 1 - larger);
A[i] = k->key;
candidates = erase(candidates, k->key);
}
}
int main() {
int C;
cin >> C;
for (int i = 0; i < C; i++) {
cin >> n;
for (int j = 0; j < n; j++) {
cin >> shifted[j];
}
solve();
for(int i=0;i<n;i++){
cout << A[i] << ' ';
}
cout << endl;
memset(shifted, 0, sizeof(int) * n);
memset(A, 0, sizeof(int) * n);
}
}Difference & Faults
이번 코드는 difference & faults보다는 similarity 가 더 보이므로 이 부분은 따로 작성하지 않겠다.
Impressions
트립
이 문제의 가장 핵심부는 트립의 구현이라고 말하고 싶다. 물론 삽입의 원리를 충분히 이해하고 있어야 코드를 응용할 수 있었을 것이다. 하지만 무엇보다 트립을 코드로 구현하고 삭제나 삽입의 구현이 가장 핵심부인 거 같다. 트립 부분을 공부하면서 처음에는 이해가 안가서 삽입 부분만 3번을 읽었다. 그래서 일단 코드를 따라 작성해보고 각 코드별로 주석을 달면서 공부하니까 훨씬 수월하게 이해할 수 있었다. 무작정 따라하는 것을 선호하진 않지만 배움에 있어서는 무작정 따라해보는 것도 좋은 방법인 거 같다.
Summary
시험공부를 할 때마다 드는 생각이 있다. "이게 나올까?", "이거 공부해야되나?". 이번에 트립을 공부할 때나 알고리즘 이론 정리를 할 때 역시 "이걸 알아야할까?","이게 의미가 있을까?"이다. 근데 이 문제를 보고 내가 공부하는 것에 다시 확신을 얻었다. 앞으로 얼마 남지 않은 진도를 충실히 완주했으면 좋겠다.
