
7.2문제: 쿼드 트리 뒤집기(ID:QUADTREE)
문제
대량의 좌표 데이터를 메모리 안에 압축해 저장하기 위해 사용하는 여러 기법 중 쿼드 트리(quad tree)란 것이 있습니다. 주어진 공간을 항상 4개로 분할해 재귀적으로 표현하기 때문에 쿼드 트리라는 이름이 붙었는데, 이의 유명한 사용처 중 하나는 검은 색과 흰 색밖에 없는 흑백 그림을 압축해 표현하는 것입니다. 쿼드 트리는 크기의 흑백 그림을 다음과 같은 과정을 거쳐 문자열로 압축합니다.
- 이 그림의 모든 픽셀이 검은 색일 경우 이 그림의 쿼드 트리 압축 결과는 그림의 크기에 관계없이 b가 됩니다.
- 이 그림의 모든 픽셀이 흰 색일 경우 이 그림의 쿼드 트리 압축 결과는 그림의 크기에 관계없이 w가 됩니다.
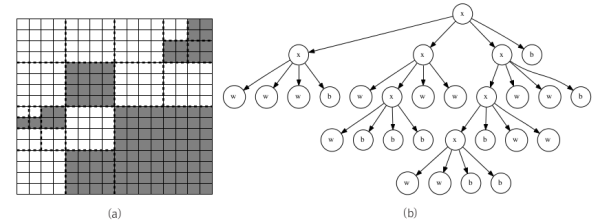
- 모든 픽셀이 같은 색이 아니라면, 쿼드 트리는 이 그림을 가로 세로로 각각 2등분해 4개의 조각으로 쪼갠 뒤 각각을 쿼드 트리 압축합니다. 이때 전체 그림의 압축 결과는 x(왼쪽 위 부분의 압축 결과)(오른쪽 위 부분의 압축 결과)(왼쪽 아래 부분의 압축 결과)(오른쪽 아래 부분의 압축 결과)가 됩니다. 예를 들어 그림 (a)의 왼쪽 위 4분면은 xwwwb로 압축됩니다.
그림 (a)와 그림 (b)는 16×16 크기의 예제 그림을 쿼드 트리가 어떻게 분할해 압축하는지를 보여줍니다. 이때 전체 그림의 압축 결과는 xxwww bxwxw bbbww xxxww bbbww wwbb가 됩니다.
쿼드 트리로 압축된 흑백 그림이 주어졌을 때, 이 그림을 상하로 뒤집은 그림 을 쿼드 트리 압축해서 출력하는 프로그램을 작성하세요.입력
첫 줄에 테스트 케이스의 개수 C (C≤50)가 주어집니다. 그 후 C줄에 하나씩 쿼드 트리로 압축한 그림이 주어집니다. 모든 문자열의 길이는 1,000 이하이며, 원본 그림의 크기는 을 넘지 않습니다.
출력
각 테스트 케이스당 한 줄에 주어진 그림을 상하로 뒤집은 결과를 쿼드 트리 압축해서 출력합니다.
예제 입력
4 w xbwwb xbwxwbbwb xxwwwbxwxwbbbwwxxxwwbbbwwwwbb예제 출력
w xwbbw xxbwwbbbw xxwbxwwxbbwwbwbxwbwwxwwwxbbwb
First Thoughts
문자열에 대한 표현방법
나는 처음 이 문제를 봤을 때 4개의 자식을 가진 연결리스트 트리 또는 배열 트리를 생성하면 될 것이라고 생각하였다. 근데 구현을 하려는 과정에서 뒤집는 방법을 어떻게 구현해야될지 생각이 나지 않았다. 입력받은 문자열을 배열을 사용하여 구현할려고해도 시간초과나 메모리 누수가 생길 거 같았다. 이런저런 걸림돌로 생각이 많아져서 구현은 못하였다.
My code
구현X
Answer code
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#define MAX_SIZE 20000
using namespace std;
string original;
//압축 문자열 분할하기
char decompressed[MAX_SIZE][MAX_SIZE];
void decompress(string::iterator& it, int y, int x, int size) {
char head = *(it++);
if (head == 'b' || head == 'w') {
for (int dy = 0; dy < size; dy++) {
for (int dx = 0; dx < size; dx++) {
decompressed[y + dy][x + dx] = head;
}
}
}
else {
int half = size / 2;
decompress(it, y, x, half);
decompress(it, y, x+half, half);
decompress(it, y+half, x, half);
decompress(it, y+half, x+half, half);
}
}
//압축 다 풀지 않고 뒤집기
string reverse(string::iterator& it) {
char head = *it;//첫번째 값 x일경우
++it;
if (head == 'b' || head == 'w')
return string(1, head);
string upperLeft = reverse(it);//왼쪽 위
string upperRight = reverse(it);//오른쪽 위
string lowerLeft = reverse(it);//왼쪽 아래
string lowerRight = reverse(it);//오른쪽 아래
return string("x") + lowerLeft + lowerRight + upperLeft + upperRight;
}
int main(void) {
int C;
cin >> C;
for (int i = 0; i < C; i++) {
cin >> original;
string::iterator itr = original.begin();
cout<<reverse(itr)<<endl;
}
}
Difference & Faults
두려움
나의 생각을 코드로 구현하기 위해 가장 시간이 오래걸린 거 같다. 이렇게하면 저게 걸리고 저렇게하면 이게 걸리고... 썼다 지웠다를 반복하며 결국에는 아예 작성하지 못하였다.
뒤집기 순서
책에서도 '압축 문자열 분할하기'와 '압축 다 풀지 않고 뒤집기'로 나눠져있는데 나 또한 뒤집는 것을 언제해야될지 고민되었다. 원래의 트리를 만들고 원래의 것을 뒤집어야하는지 아니면 입력받은 문자열을 어떤 방법을 사용하여 뒤집어야하는지 생각했다. 문자열 자체를 재귀적으로 보고 'x'의 의미에 대해 깊이 알았다면 구현이 크게 어려웠을 거 같진 않다.
Impressions
iterator의 사용
책의 정답 알고리즘을 보면 누가봐도 문자열 자체를 재귀적으로 잘 이해하고 작성한 코드 같다. 그 중에서 가장 눈에 띄었던 것은 iterator의 사용이다. reverse라는 함수에서 iterator매개변수를 참조형식으로 받아 처음 재귀호출을 하고 그 이후로는 계속 iterator의 위치가 변형되어 input되는 것이다. 매개변수를 정말 똑똑하게 사용하는 방법같다.
Summary
처음 내 방식대로 코드를 작성할려고 보니 여러가지 걸림돌이 눈에 밟혔다. 최대한 코드를 작성하면서도 '어차피 시간초과 뜰 거 같다', '이 자료구조로는 공간 차지가 심한거 같아'와 같은 이런저런 생각들로 결국은 작성했던 코드를 모두 지워버렸다. 이 문제뿐만이 아니라 나는 어떤 모르는 문제를 마주쳤을 때 항상 문제사항부터 떠오르는 거 같다. 그래서 시작을 하는데 오래걸린다. 앞으로는 실패해서 돌아와도 되니까 좀 더 대범하게 작성을 하고싶다.
