
💾 메모리 계층구조의 필요성
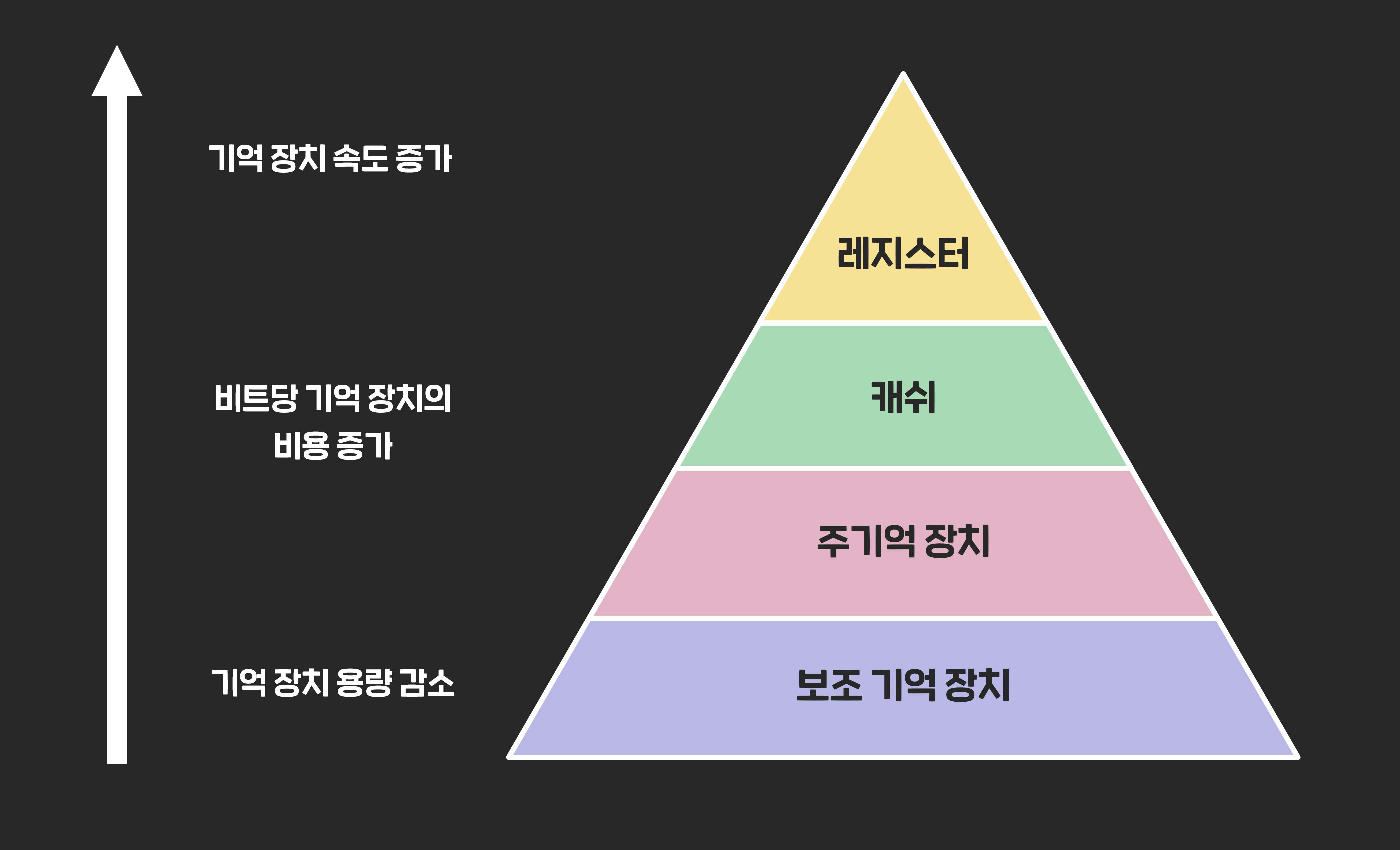
메모리의 크기가 크면 속도가 느려지고
크기가 작아지면 속도는 빠르지만 비용이 상승한다.
프로세서의 활용도를 높이기 위해서는 메모리의 속도가 처리기에 비해 뒤지지 않아야한다.
하지만 용량이 클 필요또한 있다.
이런 딜레마를 해결하기 위해서 등장한것이 메모리 계층구조이다.💾 캐시
메모리는 레지스터에 비해 용량은 크지만 프로세서가 접근하는 시간이 오래걸린다.
레지스터는 메모리에 비해 접근 시간이 짧지만 용량이 작다.
이를 해결하기 위해 캐시를 사용한다.
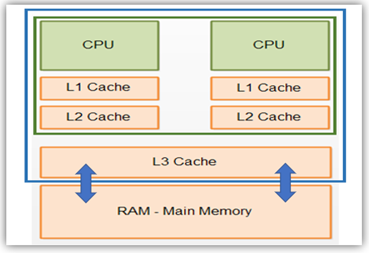
우리가 사용하는 컴퓨터에는 여러개의 캐시메모리가 존재한다.
프로세서와 제일 가까운 순으로 L1,L2,L3 캐시라고 부른다.
프로세서와 가까울수록 속도가 빠르고 멀어질수록 용량이 커진다.
보통 멀티 프로세서 시스템에서 L1과 L2는 프로세서에 L3는 따로 빠져 메모리와 연결되어 있다.참조지역성
참조 지역성의 원리
시간지역성
- 어떤 메모리의 참조를 위해 한 블록을 캐시로 가져온다면
다음에 사용할 코드는 그 블록 내부의 명령어일 가능성이 높다.
공간지역성
- 얼마전 a코드를 사용했다면 그 부근을 재사용할 가능성이 높다.
이를 이용하여 캐시는 프로세서가 다음에 사용할 데이터를 예측한다.
예측이 잘 맞으면 캐시히트 실패해서 메모리에서 가져온다면 캐시 미스 라 한다.
캐시 적중률 = 캐시히트/(캐시히트+캐시미스)
우리가 사용하는 캐시 적중률은 85~95%이다.
💻 다양한 입출력
I/O 연산을 위해 사용가능한 기법은 크게 3가지가 있다.
1. 프로그램 입출력(programmed I/O)
2. 인터럽트 기반 입출력(Interrupt-driven I/O)
3. 직접 메모리 접근(DMA, Direct Memory Access)
DMA에 집중하고 남은 부분은 컴퓨터 구조 공부시에 자세히 살펴보자📖 프로그램 입출력
프로그램 속 명령어로 입출력장치를 제어하는 방법이다.
레지스터 내의 관련 비트를 설정할뿐
프로세서가 I/O 연산이 언제 완료 되는지 알기위해서는 지속적인 검사가 필요하다.
I/O 연산 종료시 까지 주기적 검사
또한 데이터 송수신 준비 까지 프로세서가 오랫동안 기다려야함
-> 프로세서 낭비📖 인터럽트 기반 입출력
모듈에거 I/O 명령을 보낸후 완료되면 인터럽트를 보내게 한다.
프로세서는 인터럽트 요청이 오기전까지 다른 작업을 할수 있게된다.
디민 프로그램 입출력보다 효율적일 뿐 여전히 프로세서의 적극적인 간섭을 요구하며
어떤 데이터 전송도 프로세서를 거쳐야한다.
즉, 이또한 프로세서의 낭비가 발생한다.위 두방법은 두가지 문제가 발생한다.
1.I/O 전송률이 프로세서가 장치를 점검하고 서비스 하는 속도에 영향을 받는다.
2.프로세서가 I/O 전송수행시 많은 명령어가 수행된다.
그렇기에 대용량의 데이터가 전송될시에는 보다 효율적인 기술을 필요로한다.
이를 위한 기술이 바로 DMA이다,📖 DMA
DMA는 프로세서를 거치지 않고 메모리와 I/O 장치의 직접 데이터 송수신을 위한 기술이다.
특징
1. 대용량 메모리 전송, 즉 파일 입출력에 효율적이다.
2. 프로세서는 데이터 전송의 시작과 끝에만 관여한다.
프로세서는 데이터를 읽거나 쓸때 다음과 같은 정보를 보내 DMA 모듈에 I/O 작업을 명령한다.
- 읽기,쓰기 요청여부 확인
- 관련 I/O 장치 주소
- 읽거나 쓸 메모리 내의 시작위치
- 읽거나 쓸 워드의 개수
3. DMA 기능은 시스템 버스상에 있는 별도의 모듈 혹은 I/O 모듈에 포함될수 있다.
4. 전송이 완료되면 DMA 모듈은 인터럽트 신호를 프로세서에 보낸다.
5. 시스템 버스를 사용하므로 프로세서가 버스를 사용해야 하는 상황에 대용량 전송이 발생하면
프로세서의 수행이 조금 느려지게 된다.
학생