재귀
원래의 자리로 되돌아가거나 되돌아옴.
프로그래밍에서는 재귀함수로 사용한다.
특정 문제가 해결될때까지 자기 자신을 참조하는 함수를 의미한다.반복 vs 재귀
자기 자신을 참조(반복)한다 라는 말은 반복문과 동일하게 들린다.
실제로 재귀함수로 만들어진 코드는 반복문으로 대체가능하며 그 반대도 가능하다.
반복문의 경우 거의 언제나 재귀보다 빠르다.
또한 오버플로우의 위험또한 적다.
재귀의 경우 다시금 함수를 호출하여 스택에 쌓아나가는데
반복문의 경우에는 추가적인 메모리 사용이 없다.
그러면 반복문이 재귀보다 대다수의 경우에 빠르고 안전함에도 불구하고 재귀를 사용하는 이유가 뭘까?
1. 코드가 간결하다.
2. 특정 문제의 경우 재귀로 푸는것이 자연스럽고 이해하기 쉽다.
등이 있다.재귀사용법
재귀 함수를 사용할때는 고려해야할 부분이 있다.
1. 재귀 케이스
- 재귀호출은 반드시 원래 문제보다 작아진 부문제들을 처리해야한다.
2. 베이스 케이스
- 일정 수준 이하로 작아진 부문제는 직접해결해야한다.
위 두가지가 고려되지 않았을때
- 비효율적인 계산
- 무한반복
등의 문제가 발생할수있다.
재귀 예시
가장 흔히들 드는 예시인 팩토리얼을 재귀로 구현해보자.
팩토리얼은 n!=1*2*3*4~*n 이다.
n!=n*(n-1)!과 같고
같은식으로 (n-1)!=(n-1)*(n-2)! 과 같다.
이를 재귀로 구현해보자면
int Factorial(int n){
if(n == 1)
return 1;//베이스 케이스
else
return n*Factorial(n-1);//부문제가 더 작아짐
로 구현이 가능하다.
단 위식에서 n==1일때 조건이 없다면 무한반복이 되므로 종료 조건을 잘 적어주는 것이 좋다.스택
위 팩토리얼 문제의 스택을 한번 살펴보자.
Factorial(5)를 구하는 문제에서
코드는 Factorial(5)->Factorial(4)->Factorial(3)->Factorial(2)->Factorial(1)
순으로 호출될것이다.
또한 종료될때는 역순으로 Factorial(1)부터 해제되고 값이 리턴될것이다.
이를 그림으로 표현해보면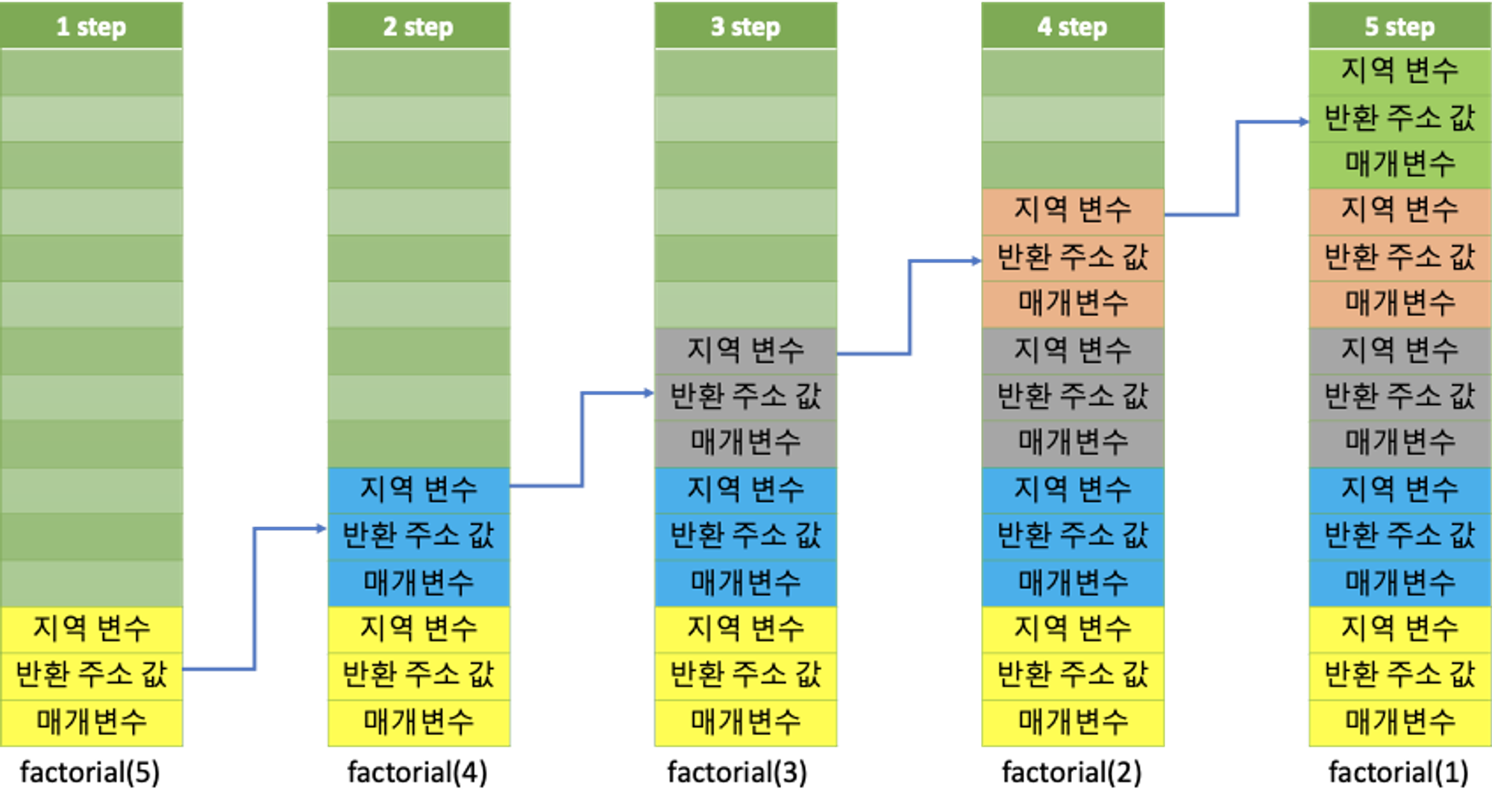
위 그림과 같다.
이때 문제는 n이 일정수준 이상으로 커지거나 n==1같은 종료 조건이 적혀있지 않다면
쉽게 스택 오버플로우 문제를 발생시킬 가능성이 있다.
학생