딕셔너리(dictionary)
딕셔너리의 개념
딕셔너리(dictionary)는 사전이라는 의미다. 사전에는 단어와 그 단어의 설명이 저장되어 있다. 여기서 단어는 키(key), 설명은 값(value)이다. 파이썬의 딕셔너리는 키와 값의 쌍을 저장할 수 있는 객체이다. 그리고 키를 이용하여 값을 검색할 수 있다.
딕셔너리에서 키는 해시가능 객체이어야 하고 중복되는 값을 허용하지 않는다.
딕셔너리의 생성
딕셔너리는 중괄호 안에 항목을 쉼표로 분리시켜서 나열하면 된다. 항목은 키(key)와 값(value)으로 구성된다.

딕셔너리에서 값은 어떤 객체이든지 가능하지만 키는 변경 불가능한 객체이어야 한다. 즉 문자열이나 숫자여야 한다. 만약 키가 변경이 가능하면 많은 문제가 발생하기 때문이다.
예를 들어 네이버든, 넥슨 게임이든 아이디(키)는 중복검사를 하여 중복을 살펴본다. 또 대학교에서 이름은 같아도 학번은 다른 점이 있다.
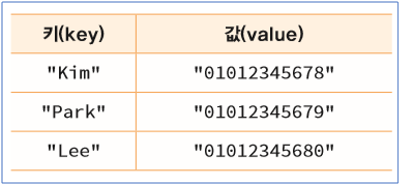
다음은 사람의 이름과 전화번호를 딕셔너리로 저장한다.
contacts = {‘Kim’: "01012345678', 'Park' : 01012345679’, 'Lee':'01012345680'}
print(contacts)
출력결과
{ ‘Kim’ : ‘101012345678’ , ‘Lee’ : 101012345680’, Park : '01012345679'}위의 문장은 3개의 항목을 가진 딕셔너리를 생성한다. 각 항목은 '키:값'의 형식으로 구성된다. 첫 번째 항목의 키 값은 'kim'이며 값은 '101012345678' 이다. 키의 자료형은 혼합되어도 된다.
공백 딕셔너리는 빈 중괄호 { }로 생성한다. 혼동할 수 있는 점이 세트또한 중괄호 {} 를 이용하여 생성한다. 허나 세트의 빈괄호는 set() 메서드를 통해,공백 딕셔너리는 단순한 {}로 생성된다.
항목 출력하기
딕셔너리에서 키와 값을 전부 출력이 가능하며, 키와 값을 key()메서드, values()메서드를 사용해 따로 출력하는 것도 가능하다.
country_code = {'America':1, 'Korea':82, 'China':86, 'Japan':81}
print(country_code) # 항목 출력
# 아래의 경우 항목 각각이 튜플 형태로 출력된다.
for country in country_code.items():
print(country, end= " ")
print(country_code.keys()) # 딕셔너리의 키만 출력
country_code["German"] = 49 # 딕셔너리 추가
print(country_code)
print(country_code.values()) # 딕셔너리의 값만 출력
출력결과 :
{'America': 1, 'Korea': 82, 'China': 86, 'Japan': 81}
('America', 1) ('Korea', 82) ('China', 86) ('Japan', 81)
dict_keys(['America', 'Korea', 'China', 'Japan'])
{'America': 1, 'Korea': 82, 'China': 86, 'Japan': 81, 'German': 49}
dict_values([1, 82, 86, 81, 49])
항목 접근하기
딕셔너리에서 항목을 꺼낼 때 항목의 키를 사용한다. 키를 [] 안에 지정하거나 get()메소드를 사용한다. 예를 들어 위의 예시에서 이름이 'kim'인 사람의 번호를 꺼내고자 한다면 다음과 같이 문장을 쓴다. 만일 키가 딕셔너리에 존재하지 않다면 KeyError가 발생한다.
contacts = {"Kim’ : ‘01012345678', 'Park’ : '01012345679’, 'Lee': '01012345680'}
print(contacts['Kim’])
contacts.get('Kim’)
출력결과
‘01012345678'
'01012345678’만일 get()을 사용했을 때, 키가 없다면 None이 반환된다.
키가 없을 때의 디폴트를 지정하려면 get()의 두 번째 인수로 디폴트 값을 지정한다.
number = contacts.get("Choi", "010114")
print(number)
출력결과
‘1010114’키가 딕셔너리에 존재하는지를 확인할려면 in연산자를 사용한다.
print(“Kim” in contacts)
출력결과 : True항목 추가 및 변경하기
딕셔너리도 변경이 가능한 컨테이너이다. 따라서 딕셔너리에 항목을 추가, 제거가 가능하다. 추가 및 제거를 하여도 동일한 주소를 가진다.
예를 들어 연락처를 추가하고자 한다면 다음과 같이 작성한다.
contacts['Choi'] = '01056781234'
print(contacts)
출력결과
{‘Kim’ : ‘01012345678’ , ‘Choi’ : '01056781234’, 'Lee’ : ‘01012345680', 'Park': '01012345679'}항목 삭제하기
딕셔너리에서 특정한 항목의 삭제는 pop()메서드, del 키워드, clear()메서드가 있다.
- pop()은 주어진 키에 해당 하는 항목을 제거하고 반환한다.
contacts {‘Kim’ : ‘01012345678', 'Park’ : '01012345679’, 'Lee': '01012345680’ }
print(contacts.pop(‘Kim’))
print(contacts)
출력결과
‘01012345678'
{'Lee': '01012345680', 'Park'; '010123456791}- del는 키에 해당 하는 항목을 제거만 한다.
contacts {‘Kim’ : ‘01012345678', 'Park’ : '01012345679’, 'Lee': '01012345680’ }
del contacts[‘Kim’]
print(contacts)
출력결과
{'Lee': '01012345680', 'Park'; '010123456791}- clear() 는 모든 항목을 삭제한다.
항목 순회하기.
딕셔너리에 저장된 항목을 순회하기 위해선 for문을 이용한다.
scores = { 'Korean': 80, 'Math': 90, 'English': 80 }
for item in scores.items(): # 키와 값을 함께 출력하기 위하여 items()를 사용함
print(item, end= ‘ ‘)
출력결과
('Math', 90) ('English', 80) ('Korean', 80)위의 문장에서 scores 딕셔너리의 키와 값을 모두 출력하기 위해 items()메서드를 사용했다. 만일 저 메서드가 없다면 키 값만 출력된다.
항목이 존재 유무 검사
어떤 키가 딕셔너리에 존재하는지의 검사는 in 연산자를 사용한다.
squares = {1 : 1, 3 : 9, 5 : 25, 7 : 49, 9 : 81}
print(squares)
print(1 in squares)
print(2 not in squares)
출력결과
{1 : 1, 3 : 9, 5 : 25, 7 : 49, 9 : 81}
True
True딕셔너리의 함축
딕셔너리 함축(Dictionary Comprehension)은 새로운 딕셔너리를 생성하는 간결한 방법이다. 리스트 함축과 매우 유사하다. 딕셔너리 함축은 {}안의 (key: value)와 for 문장으로 이루어진다.
아래는 0에서 5까지의 정수로부터 3-제곱값을 생성하는 코드이다.
triples = {x:x**3 for x in range(0,6)}
print(triples)
출력 결과:
{0:0, 1:1, 2:8, 3:27, 4:64, 5:125}정렬
파이썬 딕셔너리의 근본적인 요소들은 특정 순서대로 저장하지 않는다.
예를 들어 다음과 같이 저장된 딕셔너리를 출력하더라도 매번 다르게 출력된다.
dic = { "bags": 1, "books": 5, "bottles": 4, "coins": 7, "cups": 2, "pens": 3 }
print(dic)
출력결과
{‘coins’: 7, ‘pens’ : 3, ‘bottles’ : 4, ‘books’ : 5, ‘cups’ : 2, 'bags': 1}위의 딕셔너리를 리스트로 변환하여 출력하여도 입력한 순서와 다름을 확인 할 수 있다.
print(list(dic))
출력결과
['coins', 'pens', 'bottles', 'books', 'cups', 'bags']딕셔너리의 키를 정렬할 때 가장 간단한 방법은 파이썬의 내장 함수 sorted()메서드를 이용하는 것이다. sorted()함수는 딕셔너리에서 객체를 받아서 정렬된 키들의 리스트를 반환한다.
만일 딕셔너리의 값을 정렬하고자 한다면 value() 메서드를 추가한다.
print(sorted(dic))
print(sorted(dic.values())
출력 결과 :
['bags', 'books', 'bottles', 'coins', 'cups', 'pens']
[1, 2, 3, 4, 5, 7]만일 딕셔너리의 값에 따라 키를 정렬하고자 한다면 sorted()함수에 요소들을 비교할 때 사용하는 키를 지정하여야 한다.
print(sorted(dic, key=dic.__getitem__))
# [1, 2, 3, 4, 5, 7] 순서로 정렬된다.
출력결과
['bags', 'cups', 'pens', 'bottles', 'books', 'coins']문자열
문자열(string)
문자열은 프로그래밍에서 가장 자주쓰이는 데이터 형식이다. 문자열은 문자들의 시퀀스로 정의된다. 글자들이 실(string)로 묶여 있는 것이 문자열이라고 생각하면 된다.
파이썬에서는 str 클래스가 문자열을 나타낸다. str 클래스는 파이썬의 내장 클래스이다. 파이썬에서 문자열 리터럴은 작은 따옴표나 큰 따옴표로 감싸서 표현한다. 문자열은 str 클래스의 생성자를 호출하여서 생성할 수도 있고 아니면 문자열 리터럴을 이용하여 생성하여도 된다.
s1 = str("Hello") # 생성자 이용
s2 = "Hello“ # 리터럴 생성문자열은 변경 불가능한 객체이다. 문자열 객체가 생성되면 더 이상 변경될 수 없다. 문자열은 변경될 수 없기에, 변경된 문자열이 필요하면 새로운 객체를 생성하게 된다.
word = ‘abcdef’
word[0] = 'A'
TypeError: 'str' object does not support item assignment문자열도 크게 보면 시퀀스(sequence)라는 자료구조에 속한다. 따라서 앞에서 학습하였던
인덱싱이나 슬라이싱과 같은 연산들과 len()와 같은 내장 함수들이 모두 적용된다.
인덱싱 : 개별 문자 접근하기
문자열은 문자들로 이루어져 있다. 문자열 중에서 하나의 문자를 추출하고자 한다면 인덱싱(indexing)을 사용한다.
word = 'abcdef’
print(word[0])
print(word[5])
출력결과
‘a’
‘f’인덱스는 0에서 부터 문자열의 크기-1 까지 이며 음수또한 가능하다. 음수의 경우 -1이 문자열의 맨 뒤 글자를 의미하며 차례로 뒤로 내려간다.
슬라이싱
파이썬에서 문자열의 슬라이싱(slicing)도 지원한다. 슬라이싱이란 문자열의 일부를 잘라 새로운 문자열을 만든다. 슬라이싱을 이용하면 원하는 부분을 쉽게 잘라 낼 수 있다.
s="Hello World“
print(s[0:5])
출력결과
'Hello'위의 문장에서 s[0:5]은 문자열 s의 특정 구간을 나타내는 수식으로 “0부터 4까지”의 구간을 의미한다. 0이 시작 위치이고 5가 종료 위치이다. 종료 위치 5는 구간에 포함되지 않는다는 것에 주의해야 한다. 이렇게 콜론(:)을 이용하여서 특정한 구간을 지정하는 것이 슬라이싱이다.
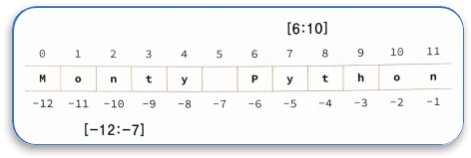
슬라이싱을 이용해 주민등록번호의 앞자리를 분리하는 예를 만들 수 있다.
reg= "980326"
print(reg [0:2], "년")
print(reg[2:4], "월")
print(reg [4:6], "일")
출력결과
98 년
03 월
26 일음수가 아닌 인덱스를 사용하는 경우, 슬라이스의 길이는 인덱스의 차이이다. 예를 들어서 word [1:3]의 길이는 2이다. 슬라이싱에서 시작 인덱스나 종료 인덱스로 적절치 못한 값을 사용하더라도 파이썬은 자동으로 적절한 값으로 변경하여 실행한다.
word = 'Python'
print(word[0:42])
print(word[2:42])
출력 결과
‘Python'
‘thon'이썬 문자열은 변경될 수 없다. 이것을 불변(immutable)하다고 한다. 따라서 문자열의 인덱스 위치에 문자를 저장하는 것은 오류이다. 만약 다른 문자열이 필요하다면 개발자가 새로운 문자열을 생성하면 된다.
word = 'Python’
'J' + word [1:]
word[:2] + 'py'
출력 결과
‘Jython’
‘Pypy’문자열 비교하기
컴퓨터는 사람의 언어를 숫자로 해석한다. 이에 영어는 아스키 코드, 한국어의 경우 유니코드를 통해 숫자로 받아들인다. 따라서 문자열과 문자열의 비교또한 가능하다. 맨 앞글자 부터 비교해나가는데 같으면 다음 문자를 비교해나간다.
참고로 간단하게 사전으로 예를 들 수 있는데 사전는 알파벳 순으로 배열되므로 사전에 앞에 있을 수록 작은 값이다.
예를 들어 다음은 apple과 banana를 < 연산자로 비교를 한다.
print("apple" < "banana“)
출력결과
True마찬 가지로 ==, !=, >=, <=, >, < ! 연산자 또한 적용할 수 있다.
다음은 사용자로 받아들인 문자열들의 순서를 정할 때 사용할 수 잇다.
a = input("문자열을 입력하시오: ")
b = input("문자열을 입력하시오: ")
if a <b:
print(a, "이 앞에 있음")
else:
print(b, "이 앞에 있음")
출력결과
문자열을 입력하시오: apple
문자열을 입력하시오: orange
apple이 앞에 있음반복하여 문자 접근하기
for 문을 이용하여 문자열의 문자들에게 접근이 가능하다.
예를 들어 다음은 사용자로 부터 입력 받은 문자열의 문자를 하나씩 출력하는 프로그램이다.
string = input("문자열을 입력하시오 : ")
for c in string :
print(c)또한 특정한 순서로 문자에게 접근하는 것도 가능하다. 예를 들어 인덱스가 홀수인 문자열에 접근이 가능하다.
string = input("문자열을 입력하시오 : ")
for i in range(1, len(string), 2 :
print(string[i])split()함수와 partition()함수
문자열에서 split() 함수를 통해 특정 문자를 기준으로 나누는 것이 가능하다. split() 함수는 문자열 안의 단어를 나누어 단어들의 리스트로 반환한다. 인자값(분리자,separator)으로 아무것도 주지 않으면 공백, 엔터키를 기준으로 나눈다.
위의 split()함수와 비슷한 역할을 하는 것이 partition()함수이다. partition의 구분자를 통해 문자열을 분리하고 튜플로 반환한다. 이는 전화번호나, 이메일 저장 등에 유용하다.
test1 = 'Never put off till tomorrow what you can do today.'
test2 = 'Mississippi '
test3 = '12345asdf@google.com'
print(test1.split())
print(test2.split('i'))
tuple = test3.partition('@')
print(type(tuple))
print(tuple)
출력 결과:
['Never', 'put', 'off', 'till', 'tomorrow', 'what', 'you', 'can', 'do', 'today.']
['M', 'ss', 'ss', 'pp', ' ']
<class 'tuple'>
('12345asdf', '@', 'google.com')
문자열의 검사 : is...
문자열이 알파벳인가? 숫자인가? 공백인가? 등에 따라 True와 False를 반환하는 함수가 있다. is...()함수를 통해 문자열의 검사가 가능해진다.
| 함수 | 설명 | 사용법 |
|---|---|---|
| isdigit() | 숫자로만 구성이 되어있다면 True를, 아니면 False를 반환한다. | st.isdigit() st[범위:범위].isdigit() |
| isalpha() | 글자로만 구성이 되어있다면 True를, 아니면 False를 반환한다. | st.isalpha() st[범위:범위].isalpha() |
| isalnum() | 글자 또는 숫자로 구성이 되어있다면 True를, 아니면 False를 반환한다. | st.isalnum() st[범위:범위].isalnum() |
| isspace() | 공백으로 구성되어 있다면 True를, 아니면 False를 반환한다. | st.isspace() st[범위:범위].isspace() |
| islower() | 소문자로 구성되어 있다면 True를, 아니면 False를 반환한다. | st.islower() st[범위:범위].islower() |
| isupper() | 대문자로 구성되어 있다면 True를, 아니면 False를 반환한다. | st.isupper() st[범위:범위].isupper() |
| isdecimal() | 해당 문자열이 10진수 정수로 구성되어 있다면 True를, 아니면 False를 반환한다. | st.isdecimal() st[범위:범위].isdecimal() |
| isnumeric() | 해당 문자열을 수로 볼 수 있다면 True를 아니면 False로 반환한다. | st.isnumeric() st[범위:범위].isnumeric() |
아래의 예시는 문자열을 입력받아 영어, 숫자, 공백의 수를 출력하는 프로그램이다.
statement = input("문자열을 입력하세요(영,숫,공)")
alpha_cnt = 0
digit_cnt = 0
spaces = 0
for ch in statement:
if ch.isalpha(): #알파벳이라면...
alpha_cnt += 1
elif ch.isdigit(): # 숫자라면...
digit_cnt += 1
elif ch.isspace(): # 공백이라면...
spaces += 1
else:
print("잘못된 입력")isdigit, isdecimal, isnumeric은 숫자를 다룬다는 점에서 유사하지만 엄밀하게 다른 점이 있다.
isdigit은 문자열이 '숫자'로 구성되어 있는지를 검사하며, isdecimal은 10진수로 표현되었는지, 즉 int형으로 변환이 가능한지를, isnumeric은 폭넓게 '수로 볼수 있는가?'를 따진다.
파이썬에서 str 클래스에서 음수, 실수 판별하는 메서드는 없다.
test = '½'
print("isdigit: ",test.isdigit())
print("isdecimal: ",test.isdecimal())
print("isnumeric: ",test.isnumeric())
부분 문자열 검색
문자열 안의 부분 문자열을 찾기 위하여 다음과 같은 메소드를 사용할 수 있다.
| 함수 | 설명 |
|---|---|
| find(문자,(시작위치)) | 문자열에서 시작위치에서 부터 해당 문자가 위치한 인덱스 번호를 반환해준다. 없을 경우 -1를 반환한다. (왼쪽에서 오른쪽으로 검사한다.) find()는 index()와 다른 점은 문자가 없어도 오류, 예외를 발생시키지 않는 점이다 처음 찾은 값만 리턴한다. |
| rfind(문자,(시작위치)) | 문자열에서 시작위치에서 부터해당 문자가 위치한 인덱스 번호를 반환해준다. 없을 경우 -1를 반환한다. (오른쪽에서 왼쪽으로 검사한다.) |
| startswith(문자,(시작지점),(끝나는 지점)) | 문자열이 해당 문자로 시작되는지 확인하여 True, False를 반환한다. (범위: 시작지점~끝나는 지점) |
| endswith(문자,(시작지점),(끝나는 지점)) | 문자열이 해당 문자로 끝나는지 확인하여 True, False를 반환한다. (범위: 시작지점~끝나는 지점) |
| count(문자, (시작지점), (끝나는 지점)) | 문자를 기입하여 문자열의 범위 내에서 문자의 개수를 반환한다. 없을 경우는 0을 반환한다. |
test = 'hello my name is hong gil dong'
# find()
print("문자 'l'의 인덱스 번호(왼쪽에서 오른쪽으로): ",test.find('l'))
# rfind()
print("문자 'l'의 인덱스 번호(오른쪽에서 왼쪽으로)",test.rfind('l'))
# startswith()
print("시작 인덱스를 5로하여 첫 문자가 'my'인지를 검사:", test.startswith('m',test.find('my')))
# endswith()
print("끝의 문자가 'dong'로 끝나는지 검사: ",test.endswith('dong'))
# count()
print("문자열 내의 문자 'i'의 개수를 출력: ",test.count('i'))
출력 결과:
문자 'l'의 인덱스 번호(왼쪽에서 오른쪽으로): 2
문자 'l'의 인덱스 번호(오른쪽에서 왼쪽으로) 24
시작 인덱스를 5로하여 첫 문자가 'my'인지를 검사: True
끝의 문자가 'dong'로 끝나는지 검사: True
문자열 내의 문자 'i'의 개수를 출력: 2
format함수
format함수란?
format함수는 문자열 포매팅을 위한 함수이다. 여기서 문자열 포매팅이란 문자열을 이쁘게 만드는 방법을 말한다.
format함수는 중괄호 {}안에 포매팅을 지정하고 format함수의 인자값을 안에 넣는다.
예를 들면 다음과 같다.
a = 3
b = 2
print("{0}*{1}={2}".format(a,b,a*b))
결과:
3*2=6중괄호 {}안에 인덱싱이 자동으로 되기에 굳이 숫자를 넣지 않아도 되지만 가독성을 위해 넣는 편이 좋다.
format 함수는 중괄호 안에 이름을 지정하여 인자값에 그 이름을 넣어 가독성을 높일 수 있다.
format함수의 인자로 그 값 자체가 들어가도 되며, 변수가 들어가도 된다.
# 이름으로 대입하기
s1 = 'number : {num}, gender : {gen}'.format(num=1234, gen='남')
print(s1)
# 직접 대입하기
s2 = 'name : {0}'.format('BlockDMask')
print(s2)
# 변수로 대입 하기
age = 55
s3 = 'age : {0}'.format(age)
print(s3)
결과:
number : 1234, gender : 남
name : BlockDmask
age : 55문자열 정렬하기
format함수를 이용하면 문자열을 왼쪽, 오른쪽, 중앙으로 정렬하는 것이 가능하다.
# 왼쪽으로 정렬하기
print("왼쪽으로 정렬하기 :'{0:<10}'|'{1:<5}'".format('left', 'a'))
# 오른쪽으로 정렬하기
print("오른쪽으로 정렬하기: '{0:>10}'|'{1:>5}'".format('right','b'))
# 중앙으로 정렬하기
print("중앙으로 정렬하기: '{0:^10}'|'{1:^5}'".format('center', 'c'))
결과:
왼쪽으로 정렬하기:'left '|'a '
오른쪽으로 정렬하기:' right'|' b'
중앙으로 정렬하기:' center '|' c '<, >, ^을 이용해 정렬할 방향을 선택할 수 있으며 왼쪽의 숫자는 인덱스를, 오른쪽의 숫자로 공백을 말한다. 예를 들어 첫 번째의 예시에서는 '10칸의 공백을 만들고 그 안에 0번째 인덱스 값을 넣고 그 값을 왼쪽으로 정렬하라' 라는 말이 된다.
문자열에 공백이 아닌 값 넣기
위의 예제에서 공백대신에 다른 특수를 넣는 것이 가능하다.
# 특수문자 '-'넣기
print("특수문자'-'넣기:'{0:-<10}'|'{1:-<5}'".format('test','a'))
# 숫자 0 넣기
print("숫자 0넣기:'{0:0>10}'|'{1:0>5}'".format('test','b'))
# 영어 a 넣기
print("영어 a넣기: '{0:a^10}'|'1:a^5'".format('test','c'))
결과:
특수문자 '-'넣기:'test------'|'a----'
숫자 0넣기:'000000test'|'0000b'
영어 a넣기:'aaatestaaa'|'aacaa'<, >, ^기호 앞에 특정 문자를 입력하면 공백 대신 그 문자가 삽입된다.
정수 및 소수 정리하기
정수와 소수에 쉼표 넣기
정수와 소수를 세자리 수 마다 쉼표(,)를 넣어 표기 쉽게 표현한다. 대표적으로 은행의 금액을 나타날 때 그러하다. format 함수를 통해 이러한 표현이 가능해진다.
아래의 코드에서 자료형을 지정한다면 그 지정한 자료형만 사용이 가능하다.
소수의 경우 아래와 같이 자료형을 지정해준다면 자동으로 5번째 자리까지 표현해준다.
- 방법 1 : {}.format(값)
# 정수
test_int = 1000000
print('{0:,}'.format(test_int))
print('{0:,d}'.format(test_int))
# 실수
test_float = 1000.10000001
print('{0:,}'.format(test_float))
print('{0:,f}'.format(test_float))
출력 결과:
1,000,000
1,000,000
1,000.10000001
1,000.100000- 방법 2 : format(값,"")
# 정수
test_int = 1000000
print(format(test_int,','))
print(format(test_int,',d'))
# 실수
test_float = 1000.10000001
print(format(test_float,','))
print(format(test_float,',f'))
출력 결과:
1,000,000
1,000,000
1,000.10000001
1,000.100000자리수와 소수점 표현하기
기호: 뒤에 특정한 수를 적음으로서 정수의 자리수와 소수의 소수점을 표현할 수 있다.
# 정수 N자리
print("정수 3자리 표현하기: '{0:03d}','{1:03d}'".format(12345,12))
# 소수점 N자리
print("소수점 2자리 표현하기: '{0:0.2f}','{0:0.4f}'".format(12.345))
결과:
정수 3자리 표현하기: '12345','012'
소수점 2자리 표현하기: '12.34', '12.3450'문자열의 대,소문자 변환
| 함수 | 설명 | 사용법 |
|---|---|---|
| upper() | 문자열 내용을 전부 대문자로 변환시킨다. | st.upper() |
| lower() | 문자열 내용을 전부 소문자로 변환시킨다. | st.lower() |
| capitalize() | 주어진 문자열의 첫 글자를 대문자로 변환시킨다. | st.capitalize() |
| title() | 주어진 문자열에서 알파벳 외의 문자(특수문자, 숫자, 띄어쓰기 등)로 나누어져 있는 문자열의 첫 글자를 모두 대문자로 변환시킨다. | st.title() |
| swapcase() | 문자열의 대문자는 소문자로, 소문자는 대문자로 변환시킨다. | st.swapcase() |
love = 'I Love You'
test = 'oh my god, what the... i\'m sorry'
print(love.upper())
print(love.lower())
print(test.capitalize())
print(test.title())
print(love.swapcase())
출력 결과
I LOVE YOU
i love you
Oh my god, what the... i'm sorry
Oh My God, What The... I'M Sorry
i lOVE yOUreplace : 문자열을 다른 문자열로 변환
replace는 문자열을 변경한 값을 반환하는 함수이다. 기본적인 형태는 '변수. replace(old, new, [count])' 형식으로 사용한다.
- old : 현재 문자열에서 변경하고 싶은 문자
- new: 새로 바꿀 문자
- count: 변경할 횟수. 횟수는 입력하지 않으면 old의 문자열 전체를 변경한다. 기본값은 전체를 의미하는 count=-1로 지정되어있다.
공백을 제거할 때 자주 쓰인다. 예를 들어
string = string.replace(" ","")
이에 공백을 제거할 수 있다.
test = 'hello world hello'
print(id(test))
hi = test.replace('hello','hi')
print(id(hi))
print(hi)
test1= 'nananana'
t = test1.replace('na','*',2)
print(t)
출력 결과:
1919412630752
1919412703728
hi world hi
**nanajoin : 리스트 요소들의 연결
join은 리스트의 요소들을 합쳐서 문자열로 출력하는 함수이다. 물론 for문과 +연산자를 통해 구현을 하는 것이 가능하다.
test = ['a','b','c','d']
str = ''
# 반복문을 통한 리스트 요소들의 연결
for i in test:
str += i
print(str)
# join함수를 통한 리스트 요소들의 연결
print(''.join(test))
출력 결과:
abcd
abcdstrip함수 : 문자열의 양쪽의 특정 문자, 공백 제거
strip함수를 이용하면 왼쪽, 오른쪽에 붙어 있는 특정한 문자를 제거할 수 있다.
중간의 공백을 제거하고자 한다면 직접 코드를 작성해야한다.
함수|설명
:-:|:-:
strip([chars]) | 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다.
lstrip([chars]) | 인자로 전달된 문자를 String의 왼쪽에서 제거합니다.
rstrip([chars]) | 인자로 전달된 문자를 String의 오른쪽에서 제거합니다.
test = '0000 abc ... hello 000 abc ..'
print(test.strip('0 abc .'))
print(test.lstrip('0 abc .'))
print(test.rstrip('0 abc .'))
결과:
hello
hello 000 abc ..
0000 abc ... hello인자 값으로 아무것도 넣지 않는다면 공백(' ')를 제거한다.
test = ' hello '
print(test.strip())
print(test.lstrip())
print(test.rstrip())
결과:
hello
hello
hello