파일의 기초
파일의 기초
파이썬 프로그램에서 새로운 데이터를 만들었다고 하여도 프로그램이 종료되면 데이터는 메모리에서 지워지고 모두 사라진다. 따라서 만일 프로그램에서 나온 데이터를 반영구적으로 저장하고자 한다면 하드 디스크에 파일 형태로 저장하여야 한다.
- 메모리
- RAM(Random Access Memory): 휘발성 성질
- ROM(Read Only Memory): 비휘발성 성질
- 하드 디스크
- HDD(Hard Disk Drive): 플래터와 헤드로 작동하여 파일을 저장함
- SSD(Solid State Drive): HDD와 다르게 반도체 메모리에 파일을 저장하기 때문에 속도가 상대적으로 빠르다.
파일 처리는 예전부터 많은 분야에서 사용되었지만 빅데이터 시대인 요즘에도 많이 사용된다. 그 이유는 규모가 큰 데이터 세트는 파일에 저장되는 것이 일반적이기 때문이다. 공공 데이터 세트도 CSV(Comma-Separated Values) 파일 형태로 제공, 저장된다.
파일의 개념
파일(file)은 보조기억장치에서 문서, 소리, 그림, 동영상과 같은 자료들을 모아 놓은 것이다. 파일은 보조기억장치상에서 논리적인 정보 단위이다. 즉 보조 기억 장치의 물리직인 특성과는 상관없이, 프로그래머한테 동일한 논리적인 인터페이스를 제공한다. 운영체제는 파일 조작에 관련된 기능을 라이브러리로 제공한다.
컴퓨터에서 위의 자료를 저장할 때는 바이너리 형태(2진법)로 저장되는데 이를 인코딩이라 한다. 반대로 바이너리 형태를 다시 사람이 쉽게 인식할 수 있는 형태로 되돌리는 것을 디코딩이라 한다.
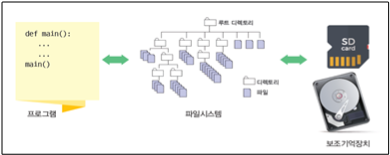
파일 안에는 순차적으로 바이트(8비트)들이 저장되어 있고 맨 끝에는 EOF(End-Of-File, -1과 동일)가 있다. 모든 파일은 입출력 동작이 발생하는 위치를 가리키는 파일 포인터를 가지고 있다. 처음 파일을 연다면 파일 포인터는 첫 번째 파이트를 가리키고, 파일의 내용을 읽거나 쓸때마다 파일 포인터는 자동으로 업데이트 된다.
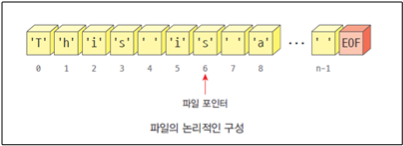
파일의 열고 닫기
파이썬에서 파일을 사용하기 위해서는 먼저 열어야한다. 파일을 여는 함수는 open()이다. open()은 파일 이름을 받아서 파일 객체를 생성한 후에 이를 반환한다. 이렇게 파일이 열리면 파일의 데이터를 읽거나 쓸 수 있다.
마지막으로 파일과 관련된 작업이 끝난다면 파일을 닫아야 한다. 파일 객체가 가지고 있는 close()를 호출하면 파일이 닫힌다. 파일과 같은 리소스(resource, 키보드, 마우스, 프린터기 등)들은 항상 열었으면 닫아야한다.
파일 모드
open()의 매개변수로 mode가 있다. 이는 파일을 어떻게 사용할 것인지를 기입하는 것이다.
| 파일 모드 | 모드 이름 | 설명 |
|---|---|---|
| 'r' | read mode | 파일로부터 데이터를 처음부터 읽어들이겠다. |
| 'w' | write mode | 파일의 처음부터 데이터를 입력하겠다. 파일이 없으면 생성된다. 만약 파일 내 데이터가 존재하면 기존의 내용은 지워진다. |
| 'a' | append mode | 파일의 끝에 데이터를 추가한다. 파일이 없으면 생성된다. |
| 'r+' | 읽기와 쓰기모드 | 파일에 읽고 쓸 수 있는 모드이다. 모드를 변경하려면 seak()가 호출되어야 한다. |
예를 들어서 d: 드라이브의 디렉토리의 input.txt 파일을 읽기 용도로 열려면 다음과 같은 문장을 사용한다.
infile = open(file = "d:\\phones.txt", mode = "r")
여기서 \\은 \(백슬래시) 기호 자체를 의미한다. \은 문자열에서 특별한 의미를 가지는 기호라서 그냥 \만 쓰면 특수 문자를 표시하게 된다. 예를 들어서 \n은 줄바꿈 기호이다. 따라서 이것을 막기 위하여 2개의 백슬래시를 붙어서 \\와 같이 표시하는 것이다.
만약 d: 드라이브 아래의 tmp 디렉토리 안에 input.txt 파일이 있다면 다음과 같은 문장을 사용하여야 한다.
infile = open(file = "d:\\tmp\\input.txt", mode = "r")
만약 파일 이름 앞에 경로가 붙지 않으면 현재 작업 디렉토리에서 파일을 한다.
infile = open(file = "input.txt", mode = "r")
파일에서 읽기
일반적으로 파일의 읽기는 read(), readline(), readlines() 메서드가 사용된다.
- read()
파일의 모든 내용을 읽어들인다. 보통의 경우 파일의 용량이 크기때문에 한번에 내용을 읽어드리는read()는 쓰이지 않는다. 하지만 문자단위로 읽어드릴 경우 괄호안의 값으로 읽고 싶은 만큼의 값을 넣어주면 된다. 만일 한 글자를 읽고자한다면 1를 넣어주면 된다. - readline()
파일의 한 줄을 읽어드린다. 그리고 파일 포인터는 다음 줄로 이동한다. 한 줄만 읽기에 보통 반복문(while, for)과 함께 쓰인다.
한 줄씩 읽어드리다가 더이상 데이터가 없는 경우는 공백 문자열 ''이 반환된다.
한 줄씩 읽어드릴 때 마지막에는 줄바꿈 문자 '\n' 가 붙기때문에 rstrip() 메소드를 사용하는 경우도 있다.
만일 파일 안에 숫자 데이터가 있다면 int, float를 사용하여 문자열을 숫자로 바꿔 주어야한다. - readlines()
readlines은 모든 내용을 읽고 리스트를 반환한다. 리스트의 요소는 한 줄, 한 줄이 된다.
# 파이썬에서 파일을 읽는 방법
# read(), readline(), readlines() 를 사용하여 파일을 읽는다
# read(): 모든 파일의 내용을 읽어들인다
# readline(): 한 번에 한 라인씩 읽어들인다(반복문)
# readlines(): 여러 라인을 리스트에 저장한다. 기본적으로 빈칸(개항, \n)이 포함된다.
# read()로 text.txt 를 읽는 방법
print('1. read() 사용')
file = open(file ='text.txt', mode='r', encoding="UTF-8")
string = file.read()
print(string)
file.close()
# readline()로 text.txt 를 읽는 방법
print('2. readline() 사용')
file = open(file ='text.txt', mode='r', encoding="UTF-8")
string = file.readline()
print(string, end='')
# readline 으로 읽어드린 문자열 데이터의 끝에 \n가 붙어 있기 때문에 end=''를 붙여준다.
string =file.readline()
print(string)
file.close()
# readlines()로 text.txt 를 읽는 방법
print('3. readlines() 사용')
file = open(file ='text.txt', mode='r', encoding="UTF-8")
string = file.readlines()
print(type(string))
print(string)
result = ''.join(string)
print(result)
file.close()
출력 결과:
1. read() 사용
안녕. 놀고 싶은 기주야!
밖에 눈이 내리지 펑펑
나는 놀고싶지 펑펑
하지만 못하지 엉엉
해야하지 파이썬
shit~man
2. readline() 사용
안녕. 놀고 싶은 기주야!
밖에 눈이 내리지 펑펑
3. readlines() 사용
<class 'list'>
['안녕. 놀고 싶은 기주야!\n', '밖에 눈이 내리지 펑펑\n', '나는 놀고싶지 펑펑\n', '하지만 못하지 엉엉\n', '해야하지 파이썬\n', 'shit~man\n']
안녕. 놀고 싶은 기주야!
밖에 눈이 내리지 펑펑
나는 놀고싶지 펑펑
하지만 못하지 엉엉
해야하지 파이썬
shit~man예제) read() 를 활용한 텍스트 내 알파벳 세기
# 하나의 파일을 읽어서 그 안에 각 알파벳이 몇 개씩 있는지 확인하는 프로그램
counter = [0] *26
infile = open(file='files/mobydick.txt', mode='r')
ch = infile.read(1)
while ch != '':
ch = ch.upper() # 대문자로 바꾼다.
# 알파벳이라면
if (ch >= 'A') and (ch <= 'Z'):
i = ord(ch) - ord('A')
# ord() 는 유니코드를 반환해준다. A를 빼면 현재 알파벳의 문자번호를 알 수 있다.
counter[i] +=1
ch = infile.read(1)
print(counter)
파일에 쓰기
'w' 모드로 파일을 열었다면 파일에 텍스트를 쓸 수 있다. 이 때는 write() 메소드를 사용한다. 콘솔에 출력할 때는 print() 함수가 자동으로 줄바꿈 문자(\n)를 붙이지만 파일에 쓸 때는 줄바꿈 문자(필요하다면)를 써줘야 한다. write() 메서드의 중요한 점은 데이터가 있는 파일에 'w' 모드로 쓰면 기존의 데이터는 지워진다는 점이다. 데이터의 추가는 'a'이다.
print() 함수의 매개변수 file에 파일 객체를 전달함으로써 파일에 텍스트를 출력할 수 있지만 보통 쓰이지 않는다.
긴 텍스트에 대해 writes() 메소드를 쓸 수 있는데, 리스트, 튜플 등의 시퀀스 자료형을 입력할 수 있다. 이때 요소들은 입력이 될 때 요소 사이 마다 공백없이 붙여지기에 join을 활용한다.
# 파이썬에서 파일 쓰는 방법
# write() : 기본적을 파일에 쓰는 방법이다. 빈칸(\n)이 필요하면 직접 입력해야 한다.
# writelines() : 리스트 등으로 된 여러 문장을 입력하기 위해서 사용한다.
# 문자열을 빈칸(\n)으로 입력하기 위해 join()을 사용한다.
# write
with open(file='write.test.txt', mode='w', encoding='UTF-8') as file :
file.write('안녕하세요 반갑습니다.\n')
file.write('저는 놀고싶어요\n')
# writelines
with open(file='write.test.txt', mode='a', encoding='UTF-8') as file :
# list 형태로 바로 파일에 기록했다.
file.writelines(['one','two','셋','넷','놀고싶덩'])
file.write('\n')
# list 를 공백을 넣어 합쳤다.
file.writelines(' '.join(['1','2','3','4','놀고싶덩']))
file.write('\n')파일 닫기
파일을 열었으면 닫아야한다. 파일을 닫으면 파일과 연결된 자원이 해제된다. 파이썬에는 참조되지 않은 객체를 정리해주는 쓰레기 수집가가 있지만 파일을 닫을 때 이것을 너무 의존하면 안된다.
파일을 닫을 때는 close(), try...finally, with이 있다.
- close()
이 방법은 완전히 안전하지 않다. 만일 파일 작업을 수행하다가 오류가 발생하면 파일을 닫지 않고 코드가 종료될 수 있다. - try...finally()
try 안에 파일 관련 코드를 작성하고 finally에 close()를 넣는다. try가 실행되다가 프로그램을 중지시키는 예외가 발생하더라도 무조건 finally는 실행되기에 보다 안전하다. - with
파일을 닫는 가장 좋은 방법은 with 명령문이다. 이 방법에서는 with 명령문 내의 블록이 종료될 때 close() 메소드가 내부적으로 자동호출이 된다.
# 파일을 받는 3가지 방법
# 1 번째 방법 : close() 호출
# 단점은 파일을 가지고 작업하다가 에러가 발생하면 파일이 제대로 닫히지 않는 경우가 발생한다.
file = open(file='c:/Temp/test.txt', mode='r', encoding='UTF-8')
line = file.readline().rstrip()
print(line)
# print(hi)
file.close()
print('------------------------------------')
# 2 번째 방법: try...finally
try:
file = open(file='c:/Temp/test.txt', mode='r', encoding='UTF-8')
line = file.readline().rstrip()
print(line)
# print(hi)
finally: # 무조건 실행되는 부분이기 때문에 1번째 방법보다 안전하다.
print('실행')
file.close()
print('------------------------------------')
# 3 번째 방법: with 명령문
# with 명령문 내의 블록이 종료될 때 자동으로 파일이 닫힌다.
# close() 가 내부적으로 호출이 된다.(권장)
with open(file='c:/Temp/test.txt', mode='r', encoding='UTF-8') as file:
line = file.readline().rstrip()
print(line)
# print(hi)다양한 텍스트 파일 입출력 방법
for문 구문을 이용한 방법
readline()와 같은 메소드를 사용하지 않고 파일의 데이터를 가져올 수 있다. 파일을 문자열들이 저장되어 있는 시퀀스(컨테이너) 객체로 볼 수 있다. 따라서 for 문을 이용하여 아래와 같이 작성할 수 있다.
file=open(file='text.txt', mode='r')
for line in file:
.............print(line)
위의 코드를 통해 파일의 모든 줄을 읽어서 콘솔에 출력할 수 있다. 각 반복에서 변수 line에 파일의 한 줄이 할당된다. for 문을 사용하여 파일을 읽은 후에, 다시 파일을 읽으려면 파일을 닫았다가 열어야한다.
줄바꿈 문자 제거
파일에서 텍스트를 읽을 때 기본적으로 줄바꿈 문자가 들어간다. 이것을 없애려면 strip() 함수를 호출한다.
텍스트 데이터에서 원치 않는 글자들을 제거하는 것은 데이터 과학에서도 중요한 작업인데, 파이썬에서는 strip()를 활용한다.
strip()은 양 끝을 관리하며 중간의 공백, 특정 문자를 제거하는 것은 불가하다.
rstrip(), lstrip()을 사용하여 좌우를 선택할 수 있다.
단어 분리하기
여러 문장이 들어있는 텍스트 파일에서 단어를 분리하고자 한다면 split() 메서드를 활용한다.
메서드를 호출할 때 분리자(separator)를 지정할 수 있다. 이를 활용해 공백 혹은 특정 문자를 기준으로 분리하는 것이 가능하다.
with open(file= 'test.txt', mode='r',encoding='UTF-8') as file:
for string in file:
# 좌우 공백을 제거함과 동시에 공백을 기준으로 분리 후 리스트형태로 반환
line = string.strip().split()
for word in line:
print(word)문자 인코딩
컴퓨터는 문자를 나타내고자 할 때 정수 형태의 문자 코드를 사용한다. 가장 유명한 것이 아스키 코드(ASCII)이다. 아스키 코드는 각 글자에 128개의 인코딩 값을 정의한다. 예를 들어 문자 A는 아스키 코드로 65이다. 요즘은 세계 모든 글자를 나타낼 수 있는 유니코드(UniCode)가 사용된다.
유니 코드 중에서 가장 많이 사용되는 인코딩은 UTF-8이다. UTF-8은 각 문자를 1개에서 4개의 바이트로 인코딩한다.
텍스트 파일의 문자 인코딩이 중요한 이유는 인코딩에 따라서 동일한 파일이라도 파일을 이루는 바이트가 달라지기 때문이다. UTF-8의 방식이 많이 사용되고 있다해도 ANSI 도 전혀 없지 않다. 그렇기에 메모장을 저장할 때 사용자가 어떠한 방식을 사용할 것인지 선택해야한다. 파이썬에서는 운영체제로 부터 문자 인코딩 설정을 가져온다. 그렇기에 사용자가 UTF-8 기반의 파일을 열 때는 직접 인코딩을 지정해줘야 한다.
file = open(file='...' , mode='...', encoding='UTF-8')
CSV(Comma-Seperated Values) 파일 처리
CSV는 테이블 형식의 데이터를 저장하고 이동하는데 사용되는 구조화된 텍스트 파일 형식이다. CSV는 Microsoft Excel과 같은 스프레드시트에 적합한 형식이다. 공공기관에서 제공하는 데이터는 CSV 형식의 데이터 세트가 많다.
파이썬의 csv 모듈은 CSV reader와 CSV writer를 제공한다.
# csv 파일 읽기
import csv
with open(file='files/weather.csv',mode='r') as f:
# csv 파일은 reader() 함수를 사용해야한다.
data = csv.reader(f)
# 헤더 제거
header = next(data)
for row in data:
print(row)
출력 결과:
['1980-04-01', '108', '6.5', '3.2', '11.7']
['1980-04-02', '108', '6.5', '1.4', '12.9']
['1980-04-03', '108', '11.1', '4.1', '18.4']
['1980-84-84', '108', '15.5', '8.6', '21’]
...위의 코드에서 csv.reader() 메서드는 csv 파일을 읽어드린다. next() 메서드는 데이터의 한 줄을 읽고 반환한다.
아래의 코드는 위의 weather.csv 파일에서 특정한 정보를 추출하여 활용하는 것이다.
# 최저 기온을 구하기
import csv
most_row_tem = 10.0
with open(file='files/weather.csv', mode='r') as f:
data = csv.reader(f)
header = next(data) # 헤더 제거하기
for weather_list in data:
if most_row_tem > float(weather_list[3]):
most_row_tem =float(weather_list[3])
print(most_row_tem)
출력 결과:
-19.2디렉토리 작업
파이썬 프로그램에서 파일을 처리하다보면 어떤 디렉토리에 있는 전체 파일을 찾아서 처리해야하는 경우가 종종 있다.
현재 파이썬 프로그램이 실행되는 디렉토리를 작업 디렉토리(Current Working Directory) 라고 한다. 예를 들어 'file'이라는 명의 디렉토리의 'a.py'의 파이썬 파일을 쓰고 있다고 한다면 'file'이 작업 디렉토리가 된다.
만일 작업 디렉토리를 얻고자 한다면 os.getcwd() 메서드를 사용한다. 이는 작업 디렉토리의 위치를 반환해준다.
만일 사용자가 처리하는 데이터 파일이 'data' 명의 서브 디렉토리에 저장되어 있다면 아래와 같은 문장으로 작업 디렉토리를 변경할 수 있다.
subdir = 'data'
os.chdir(subdir)
작업 디렉토리 안의 파일들의 리스트를 얻고자 한다면 listdir() 메서드를 사용한다.
for filename in os.listdir()
.....print(filename)
이때 파일들 뿐만 아니라 디렉토리의 이름도 같이 반환하는데, 파일만을 얻고자 한다면 isfile() 메서드를 활용한다.
if os.path.isfile(filename)
.....print(filename)
파일을 반환할 때, 특정 확장자명을 가진 파일들만 다루는 것이 가능한데, endswidth() 메서드를 사용한다.
if filename.endswidth(".확장자명")
.....print(filename)
import os
# 현재 작업 디렉토리를 얻는 방법
directory = os.getcwd()
print(directory)
print('-----------------------------------')
# 작업 디렉토리 안에 파일들의 리스트를 얻고자 할 때 ..디렉토리 반환
for finename in os.listdir():
print(finename)
print('-----------------------------------')
# 파일만 추출하고자 할 때
for filename in os.listdir():
if os.path.isfile(filename):
print(filename)
print('-----------------------------------')
# 파일의 특정한 확장자만 걸러내고자 할 때 endswith() 사용
file = os.listdir()
for name in file:
if os.path.isfile(name):
if name.endswith('.jpg'):
print(name)이진 파일과 임의 접근 파일
텍스트 파일에서는 모든 정보가 문자열로 변환되어서 파일에 기록되었다. 즉 정수값도 print()를 통하여 문자열로 변환된 후에 파일에 쓰였다. 즉 123456와 같은 정수값을 화면에 출력하려면 6개의 문자 '1', '2', '3', ‘4’, ‘5’, ‘6’ 으로 변환하여 출력하였다. 이 변환은 print() 함수가 담당하였다.
반면 이진 파일(binary file)은 데이터가 2진수의 형태로 직접 저장되어 있는 파일이다. 일반적으로 텍스트 파일을 제외한 이미지, 동영상 등 모든 파일이 바이너리 파일이다. 즉 정수 123456는 문자열로 변환되지 않고 0 1 226 64 와 같은 이진수 형태로 그대로 파일에 기록되는 것이다.
이진 파일의 장점은 효율성이다. 만일 텍스트 파일의 숫자 데이터를 읽고 활용하려면 int() 와 같은 함수를 사용하여 숫자로 변환해야 하기 때문이다. 이는 시간이 많이 걸리며 비효율적이다. 그렇기에 이진 파일을 사용하면 이러한 변환없이 바로 숫자 데이터를 읽을 수 있기에 텍스트 파일에 비하여 저장공간도 더 적게 차지하며 속도도 빠르다.

이진 파일의 단점은 인간이 파일의 내용을 확인하는 것이 힘들다는 것이다. 문자 데이터가 아니므로 모니터나 프린터로 출력하는 것이 불가하다.
또 다른 단점으로 정수나 실수 데이터를 표현하는 방식이 컴퓨터 시스템마다 다를 수 있기에 이식성이 떨어진다. 반면 텍스트 파일은 아스키 코드, 유니코드 등으로 되어 있기에 다른 컴퓨터에서도 읽을 수 있다. 때문에 이식성이 중요하다면 상대적으로 비효율적이라도 텍스트 형태의 파일을 사용하는 것 좋다. 만일 데이터가 상당히 크고 실행 속도가 중요하다면 이진 파일로 하는 편이 좋다.
이진 파일에서 데이터를 읽기 위해서는 먼저 열어야 한다.
infile = open(file = 'filename' , mode = 'rb')
여기서 'rb'는 read binary 라는 의미로 바이너리 데이터를 가져오겠다는 의미이다. 반대로 데이터를 기입할 때는 'wb', write binary를 쓴다.
이 후 입력 파일에서 8 바이트(64비트)를 읽으려면 다음과 같이 쓴다.
bytesArray = infile.read(8)
위의 bytesArray 는 바이트형의 시퀀스로서 0부터 255까지의 값들의 모임이다. 첫 번째 바이트를 꺼내고자 한다면 다음과 같다.
byte1= bytesArray[0]
반대로 이진 파일에 바이트를 저장하고자 한다면 다음과 같다.
outfile = open(filename, "wb")
# 아래 숫자는 모르겠다. 이 처럼 이진 데이터는 사람이 인식하기 힘들다.
bytesArray = bytes([255, 128, 0, 1])
outfile.write(bytesArray)
아래는 이미지 파일을 복사하는 코드이다.
# 이미지 복사하기
# 모드가 rb. wb 라는 것은 이진 파일임을 뜻한다.
infile = open(file='test.jpg', mode='rb')
outfile = open(file='copy_test.jpg', mode='wb')
while True:
# 1024바이트(=1kb)를 읽겠다.
copy_buffer = infile.read(1024)
if not copy_buffer: # 파일의 끝에 도달한다면 EOP(-1) 반환
break
outfile.write(copy_buffer) # 복사될 이미지에 읽은 내용 추가
infile.close()
outfile.close()
print('복사끝')순차 접근과 임의 접근
파일의 입출력 방법에는 '순차 접근' 과 '임의 접근'이 있다.
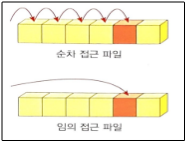
'순차 접근(sequential access)' 모든 데이터를 처음부터 순차적으로 읽거나 기록하는 것을 말한다. 이러한 방법은 한번 읽은 데이터를 다시 읽으려면 현재의 파일을 닫고 파일을 다시 열어야한다. 또한 앞부분을 읽지 않고 중간이나 마지막을 건너뛸 수도 없다.
'임의 접근(random access)'는 파일의 어느 위치에서든지 읽기와 쓰기가 가능하다.
모든 파일에는 '파일 포인터(file pointer)'라는 것이 존재한다. 파일 포인터는 읽기와 쓰기 동작이 현재 어떤 위치에서 이루어지는지를 나타낸다. 새 파일이 만들어지게되면 파일 포인터의 값은 0이 되며 이것은 파일의 시작부분을 가리킨다. 만일 추가모드('a')로 열릴 경우 파일의 끝이되며, 다른 모드에서는 파일의 시작부분을 가리킨다.

파일에서의 읽기, 쓰기가 수행될 때마다 파일포인터의 값이 시사각각 바뀐다.
만일 읽기 모드로 파일을 열고, 100바이트를 읽었다면 파일 포인터의 위치는 100이된다.
보통 파일의 데이터를 순차적으로 읽게된다면 파일포인터도 순차적을 값이 변경된다. 그러나 만일 데이터의 부분적으로 골라 읽고싶다면 파일 포인터를 이동시켜서 임의 파일 엑세스가 가능하다.
임의(random)이라는 말은 임의의 위치에서 데이터를 읽을 수 있다는 의미다. 사용자는 파일 포인터의 위치를 알아내고, 조정하고 원하는 위치에서 데이터를 읽을 수 있다.
이 때 위치를 나타내는 표시자의 위치를 반환하는 함수는 tell()이며, 이러한 표시자를 조작하는 함수가 seek() 이다.
infile = open("test.txt", “r")
str = infile.read(10)
print("읽은 문자열 : “, str)
position = infile.tell()
print("현재 위치: ", position)
position = infile.seek(0);
str = infile.read(10)
print("읽은 문자열 : ", str)
infile.close()딕셔너리 데이터 관리
딕셔너리와 같은 데이터의 파일 관리는 pickle 모듈을 통해 가능하다. 딕셔너리와 같은 객체를 파일에 저장하기 위해 파이썬에서는 다양한 방법을 제공한다. 특히 pickle 모듈이 많이 사용되는데 pickle의 dump(), load() 메소드를 사용하면 객체를 쓰고 읽을 수 있다.
dump() 메소드는 객체를 압축시켜 파일로 저장한다. 이 때 파일을 open()를 통해 열 때 확장자는 원하는대로 넣으면 된다. 여기서는 '.p' 로한다. 또한 바이너리 데이터이기에 mode 의 값으로 'wb','rb' 을 사용한다.
# 딕셔너리와 파일쓰기와 파일
import pickle
# 딕셔너리
gameOption = {
'Sound' : 8,
'VideoQuality' : 'high',
'Money' : 100000,
"WeaponList" : ['gun', ',ossle','knife']
}
# 확장자명은 원하는 대로 넣으면 된다
file = open('save.p', 'wb') # 이진 파일의 모드 b
pickle.dump(gameOption, file) # 딕셔너리를 피클 모듈을 이용하여 파일로 저장
file.close()
# 딕셔너리로 출력된 파일 읽기
file = open('save.p','rb') # 이진 파일의 모드 b
obj = pickle.load(file)
print(obj)예외 처리
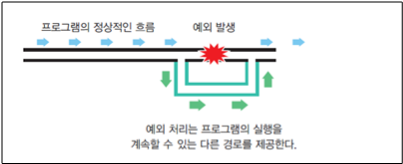
파이썬에서 실행 도중에 발생하는 오류를 예외(exception)라고 부른다. 만약 프로그래머가 만든 프로그램을 사용자가 사용하던 도중 오류가 발생하면 대개의 경우 프로그램이 종료된다. 만일 오류가 발생하여서 사용자가 작업중이던 데이터를 모두 잃어버린다면 큰 피해가 생길 것이다. 그렇기에 프로그래머들은 오류를 사용자에게 알려주고 모든 데이터를 저장한 후 안전히 프로그램을 종료할 수 있게하는 것이 바람직하다. 이러한 작업을 '예외처리' 라고 하며 파이썬은 이에 관한 기능을 제공해준다.
(x, y)=(2, 0)
z = x / y
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
z=x/y
ZeroDivisionError: division by zero 위의 코드의 경우 0를 나눈다는 점에서 예외가 발생한다. 파이썬에서는 소스 파일의 몇번째 문장에서 오류가 발생하였는지를 알려주며 어떠한 오류인지를 자세히 알려준다. 이러한 오류 메세지를 역추적 메세지(traceback message) 라고한다.
오류의 종류로는
- 사용자 입력 오류 : 사용자가 정수를 입력하는데 정수가 아닌 값을 입력할 수 있다.
- 장치 오류 : 네트워크가 안된다거나 하드 디스크 작동이 실패할 수 있다.
- 코드 오류 : 잘못된 인덱스를 사용하여서 배열에 접근하는 경우가 있다.
- IOError : 파일을 열 수 없을 때 발생한다.
- importError : 파이썬이 모듈을 찾을 수 없을 때 발생한다.
- ValueError : 연산이나 내장 함수에서 인수가 적절치 않은 값을 가지고 있을 경우 발생한다.
오류를 처리하는 전통적인 방법은 메소드가 오류를 반환하는 것이나, 항상 가능한 것이 아니며 코드가 상당히 지저분해 진다.
파이썬에서는 try-except을 사용하여 오류를 처리할 수 있다.
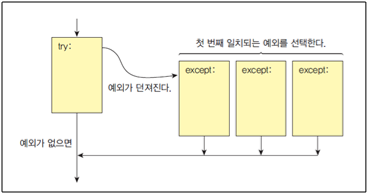
예외 처리기의 기본 형식은 아래와 같다.
try:
.....예외가 발생할 수 있는 문장
except(오류):
.....예외를 처리하는 문장
먼저 try 블럭에 예외가 발생할 수 있는 문장이 들어간다. except 블럭에는 자신이 처리할 수 있는 예외의 종류를 지정하고 그 예외를 처리하기 위한 문장이 들어간다.
예를 들어 앞의 0을 나누는 예외의 경우 아래와 같이 처리할 수 있다.
(x,y) = (2,0)
try:
z = x / y
except ZeroDivisionError:
print ("0으로 나누는 예외)만일 시스템이 내보내는 예외 메세지를 출력하고자 한다면 다음과 같이 한다.
(x,y) = (2,0)
try:
z = x / y
except ZeroDivisionError as e:
print(e)
출력 결과:
division by zero또한 while, break을 통한 반복문과 같이 쓸 수있다.
# 정수를 입력받는다.
while True:
try:
n = input("정수를 입력하시오 : ")
n = int(n)
break
except ValueError:
print("정수가 아닙니다. 다시 입력하시오.")
출력결과
정수를 입력하시오 : 23.5
정수가 아닙니다. 다시 입력하시오.
정수를 입력하시오 : 10try-except 블록에서의 흐름은 아래와 같다.
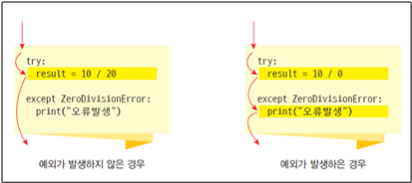
예외가 발생하지 않는다면 except의 블록을 건너뛴다. 반면에 예외가 발생한다면 오른쪽과 같이 except 블럭을 읽고 넘어간다.
except 를 여러개 활용하여 다중 예외 처리 구조를 작성할 수 있는데, 하나의 문장에서 여러 개의 예외가 발생하는 경우에 유용하다. except 뒤에 예외를 나타내는 클래스 이름을 적어두면 특정 예외를 처리하는 except 블럭이 된다.
except 블럭 뒤에 else 절을 붙일 수 있는데, 이는 try 블럭이 아무런 예외를 발생시키지 않을때, 즉 except 블럭이 실행되지 않을 때 esle절의 내용이 실행된다.
예를 들어 아래는 파일을 열고 문자열을 기록할 때, IOError 예외를 처리하고 예외가 발생하지 않으면 성공적으로 저장하였다고 출력하는 소스코드이다.
try:
fh = open("testfile", "w")
fh.write("테스트 데이터를 파일에 씁니다!!")
except IOError:
print("Error: 파일을 찾을 수 없거나 데이터를 쓸 수 없습니다. ")
else:
print("파일에 성공적으로 기록하였습니다. ")
출력 결과:
파일에 성공적으로 기록하였습니다.만일 except 블록을 만들 때 아무런 자세한 예외의 내용을 적지 않으면 어떠한 예외라도 처리할 수 있는 except 블럭이 된다.
try: # 예외가 발생할 수 있는 문장
...
except: # 어떠한 예외라도 발생하면 여기서 치이다.
...
else: # 예외가 없다면 이 블록이 실행된다.try-finally 블록도 존재하는데, finally는 예외가 발생하는 안하든 항상 실행되어야하는 문장을 두는 블록이다. finally 블록은 항상 실행된다.
만일 파일을 열고 활용한다고 한다면 예외의 여부와 관계없이 항상 파일을 닫아야하기에 finally 블록이 사용될 수 있다.
try:
open("test.txt", “w” )
f.write(“테스트 데이터를 파일에 씁니다!!”)
... # 파일 연산을 수행한다.
except IOError:
print(“Error: 파일을 찾을 수 없거나 데이터를 쓸 수 없습니다. ")
finally:
f.close()