내장 함수
파이썬 인터프리터에는 항상 사용할 수 있는 많은 함수가 준비되어 있다. 이러한 함수를 내장 함수라고 한다.
예를 들어, print() 함수는 지정된 객체를 표준 출력 장치 (화면)에 출력한다. 이러한 내장 함수들은 이용하면 프로그램을 훨씬 쉽게 작성할 수 있다.
Python 3.8에는 69개의 내장 함수가 있다. 내장 함수들은 간단한 설명과 함께 알파벳 순서로 https://docs.python.org/3/library/functions.html에 나열되어 있다. 이들 함수들은 import 문장으로 포함시킬 필요가 없다. 언제든지 사용할 수 있는 것이다.

- abs() 함수
abs() 함수는 숫자의 절대값을 반환하는데 사용한다. 정수 및 부동 소수점 수를 포함하여 모든 수에 적용이 가능하다.number = -9 number_abs = abs(number) print(number_abs) 출력 결과: 9 - all() 함수
all() 함수는 시퀀스(리스트나 딕셔너리 등)을 받아서, 시퀀스의 모든 항목들이 참일 경우, True를, 하나라도 거짓이라면 False를 반환한다. 시퀀스가 비어있을 경우는 True를 반환한다.
0이 아닌 값은 참으로, 0은 거짓으로 간주한다.test_list = [1,2,3,4] print(all(test_list)) test_list_1 = [0,1,2,3,4] print(all(test_list_1)) 출력 결과: True False - any() 함수
any() 함수는 시퀀스 객체에 있는 단 하나의 항목이라도 참인 경우 True를, 그렇지 않다면 False를 반환한다.mylist = [0, 1, 2, 3] print(any(mylist)) 출력 결과: True - bin() 함수
bin() 함수는 입력 받은 정수의 이진수(0b로 시작) 로 표현하여 반환해준다.
test = 15
print(bin(test))
출력 결과:
0b1111-
eval() 함수
eval() 함수는 전달된 수식(문자열)을 구문 분석하고 프로그램 내에서 수식의 값을 계산한다.

test = "3*3*2" print(eval(test)) 출력 결과: 18 -
sum() 함수
sum() 함수는 리스트에 존재하는 항목들을 전부 더하여 합계를 반환한다.print(sum[1, 2, 3]) 출력 결과: 6 -
len() 함수
len() 함수는 객체의 길이를 계산하여 반환해준다. 물론 공백의 길이도 포함되어 계산된다.
문자열에서는 문자의 길이를, 리스트에서는 요소의 개수를, 딕셔너리, 튜플에서도 요소의 개수를 계산하여 반환해준다.test_list = [1,2,3,4,5,['test']] print(len(test_list)) 출력 결과: 6 -
list() 함수
리스트 인스턴스를 생성해준다.s = 'abcdefg’ print(list(s)) # 리스트 객체의 생성자이다. t = (1, 2, 3, 4, 5, 6) print(list(t)) 출력 결과: [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’] [1, 2, 3, 4, 5, 6] -
map() 함수
map() 함수는 반복가능한 객체(리스트, 튜플 등)의 각 항목에 주어진 함수를 적용하여 결과를 반환하여 준다. list(), tuple() 등을 이용해 시퀀스 객체로 만들 수 있다.

def square(n): return n*n mylist = [1, 2, 3, 4, 5] result = list(map(square, mylist)) print(result)) 출력 결과: [1, 4, 9, 16, 25] -
dir() 함수
dir 함수는 객체가 가지고 있는 변수나 함수를 보여준다. 객체에 dir() 메소드가 정의되어 있는 경우, 이 메소드가 호출되며 dir() 메소드는 리스트로 변수와 함수를 반환한다.
아래에서 파이썬이 내부적으로 사용하는 함수는 __가 붙어 있다.
dir 함수는 어떤 객체에서 사용할 수 있는 함수들이 무엇인지 알고싶을 때 유용하다.
test1 = '안뇽!'
print(dir(test1))
출력 결과:
['__add__', '__class__', '__contains__', '__delattr__',
'__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getnewargs__', '__gt__',
'__hash__', '__init__', '__init_subclass__', '__iter__']-
max(), min() 함수
max()는 리스트나 튜플, 문자열의 객체 안에서 가장 큰 항목을 반환해준다. 예를 들어서 정수의 리스트에서 가장 큰 정수를 찾을 때 사용할 수 있다. 반대로 min() 가장 작은 항목을 반환해준다.values = [ 1, 2, 3, 4, 5] print(max(values)) print(min(values)) 출력 결과: 5 1 -
enumerate() 함수
이 함수는 시퀀스, 즉 순서가 있는 자료형(list, set, tuple, dictionary, string)을 받아 인덱스를 포함한 열거형(enumerate) 객체를 반환한다.
열거형 객체는 첫 번째 요소로 번호, 두 번째 요소로 번호에 해당하는 값을 가진다.
보통 'for문' 과 자주 사용된다.
enumerate()의 두 번째 인자로 start와 함께 값을 넣어 시작 값을 지정할 수 있다.
열거형(enumeration)은 고유한 상숫값에 연결된 기호 이름(멤버)의 집합이다.
대표적인 예로 불(Bool)자료형이 있다. False, True는 상수값 0, 1 으로 연결되어 있다.
열거형을 사용하는 이유는 특정 상태를 하나의 집합으로 만들어 관리함으로써 코드를 정리하는데 수월하기 때문이다. 즉, 가독성이 높아지고 문서화를 하는데 도움이 된다.
test = ['안녕','테스트','집']
print(enumerate(test))
print(list(test))
for i, value in enumerate(test):
print(i,value)
for i, value in enumerate(test, start=100):
print(i,value)
출력 결과:
<enumerate object at 0x000001D6466E5980>
['안녕', '테스트', '집']
0 안녕
1 테스트
2 집
100 안녕
101 테스트
102 집- filter() 함수
filter() 함수는 특정 조건을 만족하는 요소만을 뽑는다. 이 함수는 두 개의 인자값을 가지는데, 첫번 째 조건을 나타내는 함수이고 두 번째로 반복 가능 객체이다. 첫 번째 인자값인 함수가 True값을 반환하는 요소들만 리스트의 형태로 반환된다.
def myfilter(x):
return x > 3
result = filter(myfilter, (1, 2, 3, 4, 5, 6))
print(list(result))
출력 결과:
[4, 5, 6]- zip() 함수
zip() 함수는 2개의 리스트를 하나로 묶어주는 함수이다.아울러 zip() 함수가 가장 많이 사용되는 부분은 for 반복문이다.
names = [ "KIM", "LEE", "PARK" ]
scores = [ 100, 99, 80 ]
print(list(zip(names,scores)))
for n, s in zip(names, scores):
print(n, s)
출력 결과:
[('KIM', 100), ('LEE', 99), ('PARK', 80)]
KIM 100
LEE 99
PARK 80정렬과 탐색
sort()와 sorted() 는 정렬시켜준다.
둘의 차이점은 sort()는 자료 그 자체를 정렬하고 바꾸고, sorted()는 자료를 정렬하고 새로이 반환한다는 점이다.
sort() 는 리스트 객체의 메소드이다. 그렇기에 그 리스트의 값 자체를 변경시키며 None을 반환한다. 허나 sorted는 내장함수로 리스트에 한정되지 않고 튜플, 문자열, 딕셔너리 등 반복가능객체에 전부 사용될 수 있다. 이렇게 객체를 받고 정렬시킨 후 리스트를 반환해준다. sort()의 경우 새로운 리스트를 생성하지 않기에 sorted()에 비해 속도가 빠르지만 원본값을 바꿔버린다는 점을 주의해야한다.
이 둘의 매개 변수로는 reverse와 key가 있다.
- reverse 는 부울 값(True, False)를 가지는데 True의 경우 내림차순, False는 오름차순이다.
디폴트 값으로는 False를 가진다. - key 는 어떻게 정렬 할 것인가에 대한 기준을 제시해준다. 보통 lambda 함수와 자주 쓰인다.
test = [('옥동자','개그맨',49),('문재인','대통령',90),('김옥분','무직',10)]
# 3번째 요소를 기준으로 오름차순 정렬
print(sorted(test, key = lambda test : test[2]))
print(sorted(test, key = lambda test : test[2], reverse = False))
# 3번쨰 요소를 기준으로 내림차순 정렬
print(sorted(test, key = lambda test : test[2], reverse = True))
출력 결과:
[('김옥분', '무직', 10), ('옥동자', '개그맨', 49), ('문재인', '대통령', 90)]
[('김옥분', '무직', 10), ('옥동자', '개그맨', 49), ('문재인', '대통령', 90)]
[('문재인', '대통령', 90), ('옥동자', '개그맨', 49), ('김옥분', '무직', 10)]정렬의 안정성
파이썬에서의 정렬은 안정성이 보장된다. 안정성이란 동일한 키를 가지고 있는 레코드(예: '김옥분', '무직', 10) 가 여러개 있을 때 정렬 후에도 레코드의 원래 순서가 유지되는 것을 의미한다.
data = [(1, 100), (1, 200), (2, 300), (2, 400)]
print(sorted(data, key=lambda data: data[0]))
출력 결과:
[(1, 100), (1, 200), (2, 300), (2, 400)]위의 코드에서 (1, 100) 레코드와 (1, 200) 레코드가 정렬 후에도 위치가 변경되지 않았다. 이것은 사소한 것 같지만 중요할 수도 있다. 예를 들어서 대학교에서 신입생을 선발할 때, 성적이 같으면 선착순으로 선발한다고 하면 반드시 정렬의 안정성이 보장되어야 한다.
람다식
람다식 또는 람다 함수는 무명 함수, 즉 이름이 없는 함수를 만드는 것이다. 람다식은 이름은 없고 몸체만 있는 함수이다. 람다식은 함수이지만 def 키워드가 아닌 lambda 키워드로 생성된다. 보통 람다식은 딱 한번 사용되는 함수를 만들 때 사용된다.
람다식은 여러 개의 매개 변수를 가질 수 있으나 반환값은 무조건 하나여야한다. 또 자신만의 이름공간을 가지고 있다.

람다식은 sorted의 매개변수 key에 사용이 되며, GUI 프로그램에서 이벤트를 처리하는 콜백함수(callback handler)에서도 사용된다. 이벤트를 생성할 때 command의 값으로 람다식을 주는 것이다.
from tkinter import *
window = Tk()
btn1 = Button(window, text="1 출력", command=lambda: print(1, "버튼이 클릭"))
btn1.pack(side=LEFT)
btn2 = Button(window, text="2 출력", command=lambda: print(2, "버튼이 클릭"))
btn2. pack(side=LEFT)
quitBtn = Button(window, text="QUIT", fg="red", command=quit)
quitBtn.pack(side=LEFT)
window.mainloop()map()함수와 람다식
람다식은 내장 함수와도 함께 사용된다.
만일 리스트의 값에 2를 곱하려고 한다면 내장함수 map()를 사용하여 다음과 같이 작성할 수 있다.
list_a = [ 1, 2, 3, 4, 5 ]
f = lambda x: 2*x
result = map(f, list_a)
print(list(result))
출력 결과:
[2, 4, 6, 8, 10]map()은 람다식에 리스트의 요소를 하나씩 적용시킨다.
filter()함수와 람다식
내장 함수 filter()은 어떠한 조건을 가지는 함수를 주어서 리스트 요소들을 필터링해준다.
list_a = [1, 2, 3, 4, 5, 6]
result = filter(lambda x : x % 2 == 0, list_a)
print(list(result))
출력 결과:
[2, 4, 6]reduce()함수와 람다식
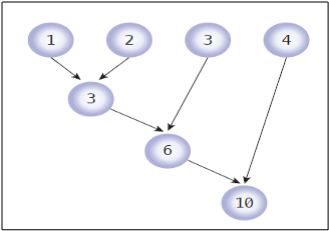
reduce(func, seq) 함수는 func() 함수의 시퀀스 seq에 연속적으로 적용하여 단일 값을 반환한다.

1. 리스트의 처음 2개의 요소에 func() 이 적용된다.
2. 앞의 결과의 값과 3번째 요소를 다시 func()에 적용한다.
3. 이 과정이 반복되어 하나의 값이 도출된다.
import functools
result = functools.reduce(lambda x,y: x+y, [1, 2, 3, 4])
print(result)
출력 결과:
10