데이터베이스의 기본
데이터베이스의 개념
일상생활을 하다보면 뉴스, 인터넷, SNS 등에서 데이터베이스(Database)라는 단어를 종종 접한다. 데이터베이스는 모바일, 서버 컴퓨터, 인터넷환경에서 없어서는 안될 요소이다.
파이썬에서 작성한 프로그램의 데이터를 파일에 저장할 수도 있지만, 한계가 존재한다. 예를 들어 한 사람에게서는 접속한 사이트, 결제한 금액, ID와 Password 등의 데이터가 존재하는데, 수 천명의 데이터를 파일로 관리하기에는 한계가 있다. 이를 해결하기 위한 것이 데이터베이스이다.
앞에서 말한 다양한 형태이며 지속적이고 대량적인 데이터를 관리하기 위해서 나타난 것이 데이터베이스 관리 시스템(DBMS)이다. 데이터베이스는 대량의 데이터를 체계적으로 저장해 놓은 것 정도로 간단히 정의내릴 수 있으며, 데이터베이스는 여러 사용자나 시스템이 서로 공유할 수 있어야한다.
데이터베이스 관리 시스템은 이러한 데이터베이스를 관리 해주는 시스템이다.
파이썬 프로그래밍을 익히기위해 파이썬 소프트웨어를 설치하였드시, 데이터베이스를 익히기 위해서는 데이터베이스 소프트웨어를 설치해야한다. 데이터베이스 소프트웨어를 DBMS(DataBase Management System, Software)라고도 한다. 이러한 DBMS 제품은 다양한데, 현재 가장많이 쓰이고있는 오라클(Oracle) 부터 SQL 서버(SQL Server), MySQL, 액세스(Access), SQLite 등이 있다.
관계형 데이터베이스
DBMS은 크게 계층형(Hierarchical) DBMS, 망형(Network) DBMS, 관계형(Relational) DBMS, 객체지향형(Object-Oriented) DBMS, 객체관계형(Object-Relational) DBMS 등으로 나뉜다.
관계형 DBMS를 가장 많이 사용하며, 일부 멀티미디어 분야에서는 객체지향형이나, 객체관계형 DBMS를 활용하는 추세이다.
앞에서의 오라클, SQL 서버,액세스 ,MySQL 등은 모두 관계형 DBMS(RDBMS)라고 할 수 있다.
RDBMS의 가장 큰 단점은 시스템 자원을 많이 차지해서 속도가 전반적으로 느리다는 점이다. 허나 하드웨어의 발달로인해 예전에 비해 많이 나아졌다.
데이터베이스 관련 용어
건물을 지으려면 먼저 설계도를 작성하드시, 데이터베이스의 구축은 먼저 데이터베이스 모델링이라는 작업으로 시작된다. 데이터베이스 모델링은 현실 세계에서 사용되는 데이터를 DBMS에 어떻게 옮겨 넣을지를 결정하는 과정이다.
예를 들어 포털사이트에 회원가입을 한다고 하면, '회원'의 정보를 어떻게 DBMS에 넣을 것인지 생각해야한다. 회원 자체를 컴퓨터에 넣을 수없으므로 회원을 나타낼 수 있는 특성(속성)을 추출해서 그 특성을 DBMS에 넣어야 하는 것이다. 즉 이름, 생년월일, 이메일 주소, 연락처 등의 정보를 DBMS 에 저장해야한다.
이러한 정보들을 테이블(Table)이라는 표 형태의 틀에 맞춰서 넣어야한다.
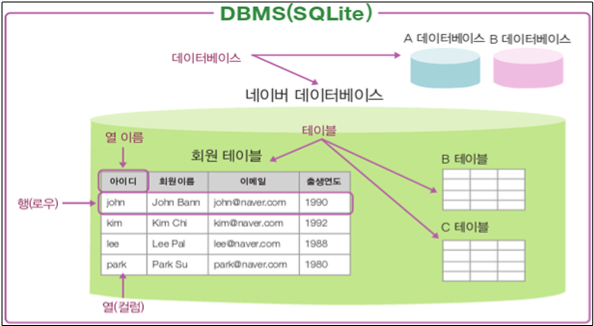
아래는 그림을 통한 간단한 데이버베이스 관련 용어이다.
| 용어 | 설명 |
|---|---|
| 데이터 | john, john Bann, john@naver.com, 1990 등 하나하나의 단편적인 정보를 말한다. |
| 테이블 | 회원 데이터가 표 형태로 표현된 것이다. 지금은 네이버 데이터베이스를 구현하기 위해 회원정보를 보관할 회원테이블을 생성하였다. |
| 데이터베이스(DB) | 테이블이 저장되는 저장소로, 주로 원통 모양으로 표현한다. 위의 그림에서는 네이버, A, B 데이터베이스가 있으며, 각 데이터베이스에는 고유한 이름을 가져야한다. |
| DBMS | 데이터베이스를 관리하는 시스템 또는 소프트웨어를 의미한다. SQLite 소프트웨어가 이에 해당한다. |
| 열(컬럼 또는 필드) | 각 테이블은 1개 이상의 열로 구성된다. 회원 테이블은 아이디, 회원이름, 이메일, 출생연도 4개로 구성되어있다. |
| 열 이름 | 각 열을 구분하는 이름이다. 열 이름은 각 테이블안에서 중복되지 않아야한다. |
| 데이터 형식 | 열의 데이터형식으로 테이블을 생성할 때 열 이름과 함께 들어갈 데이터형식을 지정해야한다. 예를 들어 출생연도는 자료형이 int여야한다. '빠른94'와 같은 값이 들어가면 안되기 때문이다. |
| 행(로우) | 실질적인 데이터로, john/John Bann/john @naver.com/1990 은 하나의 행 데이터이다. |
| SQL(Structured Query Language) | DBMS(SQLite)에서 어떤 작업을 하고 싶다면 DBMS에 맞춰서 지시해야한다. SQL은 DBMS의 언어이다. |
데이터 베이스의 구축
1-SQLite의 실행.
데이터베이스를 구축하려면 먼저 SQLite에 접속해야한다. 그림과 같이 파일 탐색기에서 sqlite3.exe 를 실행시키면 명령 프롬프트창이 열리면서 splite> 로 표시된다.
2-SQL 작성
1. 데이터 베이스의 생성
데이터 베이스를 생성하거나 열기위해서는 다음과 같다.
open 데이터베이스 이름
이 명령어는 데이터베이스가 존재한다면 열어주고, 존재하지 않다면 새로 생성해준다. 아래와 같이 명령어를 작성하면 네이버 데이터베이스(이름: naverDB)가 생성된다.

2. 테이블 생성
naverDB에 테이블을 생성해야한다. 이를 위한 SQL 문의 형식은 다음과 같다.
CREATE TABLE 테이블이름(열이름1 데이터형식, 열이름2 데이터형식, ...);
3. 데이터 입력
생성한 회원 테이블(userTable)에 행 데이터를 입력해야한다. 형태는 다음과 같다.
INSERT INTO 테이블이름 VALUES(값1, 값2, ...);

행데이터의 삭제와 수정은 다음과 같다.
행 데이터의 삭제 : "DELETE FROM 테이블 이름 WHERE 열이름=값;"
형 데이터의 수정: "UPDATE 테이블 이름 SET 수정할 데이터의 열 이름 = 새값, WHERE 조건 열 이름= 값"
4. 데이터 조회 및 활용
데이터를 조회 및 활용하는 SQL 문은 SELECT 이다.
SELECT 열 이름 FROM 테이블이름;
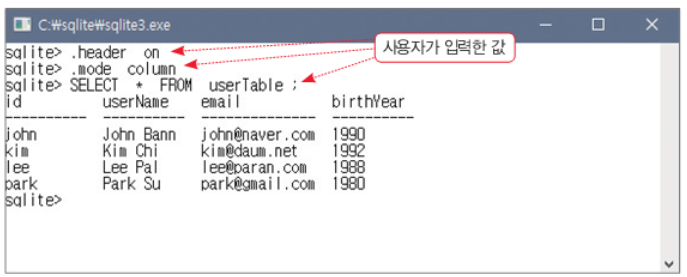
만일 데이터를 불러올 때 조건을 달고자 한다면 WHERE을 뒤에 붙여줘야한다.
SELECT 열이름1, 열이름2, ... FROM 테이블이름 WHERE 조건;
데이터를 정렬시키고자 한다면 ORDER BY를 사용한다.
SELECT 열이름1, 열이름2, ... FROM 테이블이름 ORDER BY 열 이름;
sqlite> SELECT id, birthYear FROM userTable WHERE birthYear<=1990;
john 1990
lee 1988
park 1980
sqlite) SELECT * FROM userTable WHERE id = ‘lee’;
lee Lee Pal lee@paran.com 1998
sqlite> SELECT * FROM userTable ORDER BY birthyear;
park Park Su park@gmail.com 1980
lee Lee Pal lee@paran.com 1988
john John Bannijohn@naver.com 1990
kim Kim Chi kim@daum.net 1992
sqlite>.quit SQLite 간단한 명령어 정리
| 명령어 | 설명 |
|---|---|
| .table | 현재 데이터베이스의 테이블 목록을 보여준다. |
| .schema 테이블이름 | 테이블의 열 및 데이터 형식 등 정보를 보여준다. |
| .header on | SELECT 문으로 출력할 때 헤더를 보여준다. |
| .mode column | SELECT 문으로 출력할 때 컬럼 모드로 출력한다. |
| .quit | SQLite를 종료한다. |
| DROP TABLE 테이블이름 | 생성된 테이블을 삭제한다. |
파이썬과 sqlite3모듈
파이썬에서 데이터를 입력하는 코딩 순서
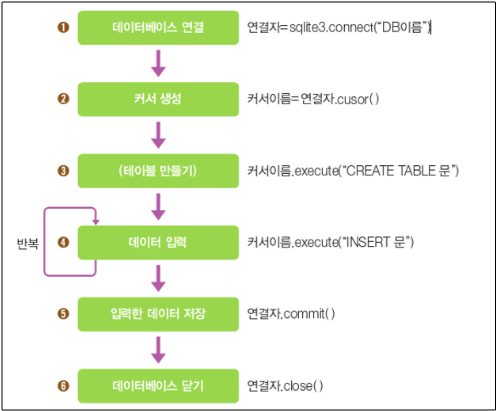
- 데이터베이스 연결
파이썬에서 SQLite 를 사용하고자한다면 sqlite3모듈을 활성화를 시켜야한다. 그리고 sqlite3.connet("DB이름")으로 데이터베이스에 연결해야한다.만일 데이터베이스가 존재한다면 연결되고 존재하지 않다면 생성된다.
import sqlite3
con = sqlite3.connect("C:/PythonDB/naverDB") # 소스 코드가 저장된 폴더에 생성
출력 결과:
아무것도 나오지 않음위의 코드에서 naverDB는 앞에서의 SQLite를 이용해 생성한 naverDB와는 별개의 것이다.
- 커서 생성
커서(Cursor)는 데이터베이스에 SQL 문을 실행하거나 실행된 결과를 돌려받는 통로와 같은 것이다.
앞에서 생성한 연결자 con에 커서를 만들어야한다.
cur = con.cursor()
출력 결과:
아무것도 나오지 않음- 테이블 만들기
테이블을 만들기 위한 SQL문을 커서이름.execute() 함수의 매개변수로 넘겨주면 SQL문이 데이터베이스에 실행된다.
cur.execute("CREATE TABLE userTable (id char(4), userName char(15), email char(15), birthYear int)")
출력 결과:
<sqlite3.Cursor object at 개체번호)- 데이터 입력
데이터의 입력또한 execute() 함수를 이용하여 데이터입력 SQL문을 매개변수로 넘겨주면된다.
cur.execute("INSERT INTO userTable VALUES('john', 'John Bann', 'john@naver.com', 1990)")
cur.execute("INSERT INTO userTable VALUES('kim', 'Kim Chi', 'kim@daum.net', 1992)")
cur.execute("INSERT INTO userTable VALUES('lee', 'Lee Pal', 'lee@paran.com', 1988)")
cur.execute("INSERT INTO userTable VALUES('park', 'Park Su', 'park@gmail.com', 1980)")
출력 결과:
sqlite3.Cursor object at 개체번호)가 각각 4회 출력됨- 입력한 데이터의 저장
4번에서의 데이터 입력은 아직 완전히 데이터베이스에 완전히 저장된 것이 아닌 임시로 저장된 것이다. 이를 확실하게 넘겨주는 것을 커밋(commit)이라고 한다.
con.commit()
출력 결과:
아무것도 나오지 않음- 데이터베이스 닫기
데이터 베이스또한 리소스이므로 사용을 끝마쳤으면 닫아줘야한다.
con.close()
출력 결과:
아무것도 나오지 않음아래의 코드는 데이터를 입력받아서 데이터베이스에 저장하는 코드이다.
# 사용자로부터 데이터를 입력받아서 DB에 저장하는 실습
import sqlite3
# 전역 변수 선언
con, cur = None, None # 연결자, 커서를 저장하는 변수 초기화
id, userName, email, birthYear = "","","",""
# 메인 코드 부분
if __name__ == '__main__':
con = sqlite3.connect("C:/PythonDB/naverDB")
cur = con.cursor()
# 무한 루프를 돌면서 사용자로부터 데이터를 입력받는 코드
while True:
id = input("사용자 ID 기입: ")
# 무한 루프의 탈출
# 사용자가 입력을 하지않고 엔터키를 입력한 경우 루프를 빠져나온다.
if id == "":
break
userName = input("사용자 이름 기입: ")
email = input("사용자 이메일 기입: ")
birthYear = (input("사용자 출생년도 기입: "))
# 사용자가 입력한 데이터를 이용하여 쿼리문 작성하는 코드
# 1번 statement 식의 insert into 방식
# sql = "insert into userTable values('"+id+"','"+userName+"','"+email+"',"+ birthYear+")"
# 2번 preparedStatement 식의 insert into 방식(와일드 카드 사용 방식)
# print(sql)
# statement 식을 이용하는 것보다 가독성이 좋다. 그리고 혼란을 야기하지 않는다.
# 와일드 카드의 개수를 헤아려서 그에 맞는 저장할 데이터를 제공시켜주면된다.
cur.execute("insert into userTable (id, userName, email, birthYear) values(?,?,?,?)",(id,userName,email,birthYear))
con.commit()
# 데이터 조회
# cur.execute("select * from userTable")
# while True:
# row = cur.fetchone()
# if row == None:
# break
# id = row[0]
# userName = row[1]
# email = row[2]
# birthYear = row[3]
# print("%5s %5s %5s %5d" %(id, userName, email, birthYear))
con.close()파이썬에서 데이터를 조회하는 코딩 순서
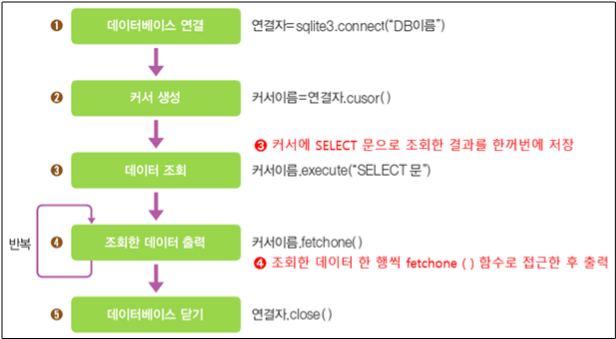
위의 그림에서 3번과정에서 execute의 SQL문에 SELECT 문을 통해 데이터를 조회한다. 이 때 커서를 통해 조회된 내용은 전부 커서에 저장(메모리 저장)된다.
그런다음 커서이름.fetchone() 을이용하여 하나의 데이터를 가져온다.(fetchall()은 모든 데이터를 가져온다.) 이를 반복하여 모든 데이터를 출력한다. 이 때는 데이터를 입력, 변경을 하는 것이 아니기에 commit() 을 사용하지 않아도 된다.
import sqlite3
# 전역변수 선언
con, cur = None, None
id, userName, email, birthYear = "","","",""
row = None # 한 행을 가져와서 저장할 전역변수
rows = None # 전체 행을 가져와서 저장할 전역변수
if __name__ == '__main__':
# DB 연결
con = sqlite3.connect("c:/PythonDB/naverDB")
# 커서 생성
cur = con.cursor()
cur.execute("select * from userTable") # 조회된 데이터 전부 저장됨
# cur.execute("select * from userTable where birthYear>=1990")
# 아래 쿼리는 출생연도 컬럼을 기준으로 오름차순 정렬을 하는 쿼리이다.
# 단, 기본값이 asc 이기 때문에 asc는 생략이 가능하다.
# cur.execute("select * from userTable order by birthYear")
# 아래 쿼리는 출생연도 컬럼을 기준으로 내림차순 정렬을 하는 쿼리이다.
# 단, 기본값이 asc 이기 때문에 asc는 생략이 가능하다. 하지만 내림차순을 하는
# desc 생략은 불가하다
# cur.execute("select * from userTable order by birthYear desc")
# 아래는 한 조건에 의해 출력하는 쿼리문이다.
# cur.execute("select * from userTable where id = 'park'")
print("사용자ID 사용자이름 이메일 출생년도")
print('--------------------------------------------')
# row = cur.fetchone() # 튜플형태로 행의 값을 리턴해준다
# print(row) # 튜플형태로 행의 값을 리턴해준다.
# 무한루프를 돌면서 1행씩 가져와서 출력을 한다.
while True:
row = cur.fetchone() # 행을 하나씩 가져온다.
if row == None: # 더이상 가져올 데이터가 없다면 탈출
break
# 한 행에 있는 데이터를 각각 전역변수에 저장후 출력
id = row[0]
userName = row[1]
email = row[2]
birthYear = row[3]
print("%5s %15s %15s %5d" %(id, userName, email, birthYear))
# print('전체 행을 한번에 가져오는 fetchall() 함수 사용')
# fetchall() 함수를 사용하면 튜플리스트 혀여태로 전체 행을 반환해준디.
# rows = cur.fetchall()
# for data in rows:
# print(data)
# DB연결 해제
con.close()
출력 결과:
사용자ID 사용자이름 이메일 출생년도
--------------------------------------------
xi xi jinping china@naver.com 1990
chirs chris pan chirs@google.com 1949
moon moon jaein moon@daum.com 1911
park kinhae park@korea.com 1998
aaa aaaa aaa@naver.com 1999
예제. GUI와 데이터의 입력 및 조회
# GUI(tkinter 모듈 이용) 환경을 만들어서 데이터를 입력, 출력해주는 프로그램 실습
import sqlite3
from tkinter import *
from tkinter import messagebox
# 전역 변수 선언 및 초기화
con, cur = None, None
id, userName, email, birthYear = "", "", "", ""
# "저장"버튼을 클릭했을 때, 처리하는 이벤트 핸들러 함수 insertData() 선언 및 구현
def insertData():
con = sqlite3.connect("c:/PythonDB/naverDB")
cur = con.cursor()
id = edit1.get()
userName = edit2.get()
email = edit3.get()
birthYear = edit4.get()
try:
cur.execute("insert into userTable(id, userName, email, birthYear) values(?, ?, ?, ?)",
(id, userName, email, birthYear))
except:
messagebox.showerror("오류발생","데이터 입력 오류 발생")
else:
messagebox.showinfo("저장 완료","데이터 저장 완료")
con.commit()
con.close()
def selectData():
strData1 = []; strData2 = []; strData3 = []; strData4 = []
con = sqlite3.connect("c:/PythonDB/naverDB")
cur = con.cursor()
cur.execute("select * from userTable")
# 위의 strData1 ~ 4까지의 초기화되어진 리스트에 데이터를 추가함
strData1.append("사용자 ID"); strData2.append("사용자 이름")
strData3.append("이메일"); strData4.append("출생연도")
strData1.append("----------"); strData2.append("----------")
strData3.append("----------"); strData4.append("----------")
while True:
row = cur.fetchone()
if row == None:
break
strData1.append(row[0]); strData2.append(row[1])
strData3.append(row[2]); strData4.append(row[3])
# 조회를 재차 클릭을 했을 때 리스트 박스의 내용을 전체 삭제 후 내용 출력하게끔 함.
listData1.delete(0, listData1.size()-1); listData2.delete(0, listData2.size()-1)
listData3.delete(0, listData3.size()-1); listData4.delete(0, listData4.size() - 1)
# zip() 함수는 여러 개의 순회 가능한(iterable) 객체를 인자로 받고, 각 해당 객체가 담고 있는
# 요소를 차례로 접근할 수 있게끔 반복자(iterator)를 반환한다.
# 루프를 돌면서 각각의 해당하는 요소들의 값들을 ListBox 에 추가하고 있다.
for id, userName, email, birthYear in zip(strData1, strData2, strData3, strData4):
listData1.insert(END, id); listData2.insert(END, userName)
listData3.insert(END, email); listData4.insert(END, birthYear)
con.close()
if __name__ == "__main__":
window = Tk() # 윈도우 생성
window.geometry("600x300") # 화면크기 설정
window.title("GUI 데이터 입출력") # 윈도우의 제목 설정
editFrame = Frame(window) # Frame 컨네이너를 윈도우에 생성함
# pack()는 기본 값으로 side 매개변수에 TOP 값을 가진다.하여 위로 정렬시키면서
# Frame 컨테이너 속의 위젯들을 중앙 배치를 해준다.
editFrame.pack()
# 조회결과를 출력할 Frame 컨테이너를 윈도우에 생성함.
listFrame = Frame(window)
listFrame.pack(side=BOTTOM, fill=BOTH, expand=1)
# 위젯들 배치(editFrame 배치)
# Entry 위젯에서 width 속성은 픽셀값이 아니고, 텍스트 단위임을 상기하자.
edit1 = Entry(editFrame, width=10); edit1.pack(side=LEFT, padx=10, pady=10)
edit2 = Entry(editFrame, width=10); edit2.pack(side=LEFT, padx=10, pady=10)
edit3 = Entry(editFrame, width=10); edit3.pack(side=LEFT, padx=10, pady=10)
edit4 = Entry(editFrame, width=10); edit4.pack(side=LEFT, padx=10, pady=10)
# 데이터를 저장하는 버튼이며 insertData()를 이벤트 핸들러로 등록함.
btnInsert = Button(editFrame, text="저장", command=insertData)
btnInsert.pack(side=LEFT, padx=10, pady=10)
# 데이터를 조회하는 버튼이며 selectData()를 이벤트 핸들러로 등록함.
btnSelect = Button(editFrame, text="조회", command=selectData)
btnSelect.pack(side=LEFT, padx=10, pady=10)
# listFrame 컨테이너에 ListBox 위젯을 만들어서 레이아웃 배치를 한다.
# 리스트 박스는 여러 문자열을 위에서 아래로 나열할 때 사용하는 위젯이다.
listData1 = Listbox(listFrame, bg="yellow")
# pack()는 기본 값으로 side 매개변수에 LEFT 값을 주어 왼쪽 기준 정렬이 되며,
# 할당된 공간 양쪽을 다 채우고, 할당되지 않은 미사용 공간을 현재 위젯의 할당된
# 공간으로 변경한다.
listData1.pack(side=LEFT, fill=BOTH, expand=1)
listData2 = Listbox(listFrame, bg="yellow")
listData2.pack(side=LEFT, fill=BOTH, expand=1)
listData3 = Listbox(listFrame, bg="yellow")
listData3.pack(side=LEFT, fill=BOTH, expand=1)
listData4 = Listbox(listFrame, bg="yellow")
listData4.pack(side=LEFT, fill=BOTH, expand=1)
window.mainloop()
