리스트(list)란?
예를 들어서 학생 10명의 성적 평균을 구한다고 가정해보자. 그렇다면 성적을 담을 변수는 10개가 필요하다. 만일 100명이라면 프로그래머에게는 상당히 곤란할 것이다. 이와 같은 문제를 해결하기 위해 필요한 것이 list이다.
리스트(list)는 쉽게 대량의 데이터를 저장할 수 있는 공간을 만들 수 있고 손쉽게 데이터를 처리할 수 있다. 리스트는 [ ]를 이용해 데이터를 저장한다.
 '
'
예를 들어 10개의 정수를 저장하는 리스트는 다음과 같다.
scores = [1,2,3,4,5,6,41,50,60,10]만일 초기값이 있다면 위와 같이 생성하면 되지만 사용자로부터 입력받은 값을 리스트에 추가하려면 append() 메서드를 사용한다.
scores = [ ]
for i in range(10):
scores.append(int(input("성적을 입력하시오:")))
print(scores)리스트가 필요한 경우는 서로 관련된 데이터를 묶어서 처리할 경우이다. 하나의 이름 아래 데이터들에게 번호를 부여하고 관리한다. 이를 통해 쉽게 기억할 수 있으며 관리도 간편해진다.
동일한 자료형 뿐만 아니라 서로 다른 자료형의 요소를 하나의 리스트 안에 포함할 수 있다. 또 리스트 안에 다른 리스트를 포함시키는 것도 가능하다.
list1 = [12, "dog", 180.14] # 혼합 자료형
list2 = [["Seoul", 10], ["Paris", 12], ["London", 50]] # 내장 리스트: 리스트 안에 리스트가 있는 꼴.
list3 = ["aaa", ["bbb", ["ccc", ["ddd", "eee", 45]]]] # 내장 리스트파이썬의 리스트는 다른 언어의 배열(array)과 유사하다. 하지만 배열의 크기는 고정되어 있는 반면에 리스트의 크기는 가변적이다. 즉 요소의 개수에 따라서 커지거나 작아질 수 있다. 또 배열은 같은 데이터 타입만 저장할 수 있지만 리스트에는 다양한 종류의 데이터 타입형태를 섞어서 저장할 수 있다. 하여 파이썬의 리스트가 배열보다 훨씬 사용하기 편하다
# C언어에서의 배열
int arr[5] = {1,2,3,4,5};리스트 요소 접근하기
리스트에 저장된 데이터들을 리스트 요소(array element)라고 한다. 그리고 리스트의 요소에는 고유한 번호가 붙어 있는데 이를 인덱스(index, 첨자)라고 칭한다.
리스트의 이름을 쓰고 [ ]안에 번호를 표시하면 리스트 요소가 된다. 유효한 인덱스의 범위는 0에서 부터 (리스트의 크기-1) 까지이다.
각각의 리스트 요소들은 변수와 동일하다. 값을 넣을 수도 있으며 값을 꺼낼 수도 있다.
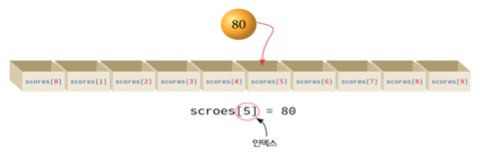
리스트의 요소에 인덱스 범위를 확인하고 값을 저장하는 코드는 다음과 같다.
if i >= o and i < len(scores) :
scores[i] = number리스트 순회하기
리스트의 요소들을 순서대로 방문하는 작업은 많이 나타난다.
인덱스를 사용하여 방문하는 작업이다.
예를 들어 10인 리스트가 있다고 하자. 변수 0에서 시작하여 하나씩 증가시키면서 거기에 해당되는 리스트 요소를 방문하는 방법이다.
# 리스트 요소 활용
for i in range(len(scores)):
print(i, score[i])
# 리스트의 요소 변경
for i in range (len(scores)):
score[i] = i*10여기서 len(scores)는 리스트의 요소들의 갯수, 즉 리스트의 크기인 10을 반환한다.
인덱스 대신 리스트를 활용하는 작업은 아래와 같다.
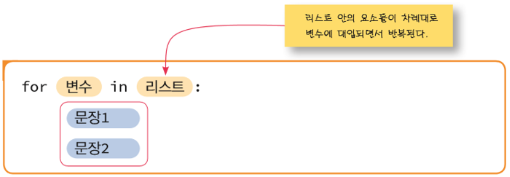
만일 리스트의 모든 요소를 출력하고자 한다면 다음과 같다.
for element in scores:
print(element)scores 리스트의 첫 번째 요소부터 변수 element에 할당되고 반복 루프 안의 문장들이 실행된다. 한번의 반복이 끝나민 두 번째 요소가 변수 element에 할당된다. 이 경우에는 우리가 리스트의 크기에 대하여 신경 쓰지 않아도 된다.
list 클래스
리스트는 위에서와 같이 [ ] 사용하여 생성할 수 있다. 또한 list 클래스를 사용해 생성할 수 있다.
list1 = list() # 공백 리스트 생성
list2 = list("Hello") # 문자 H, e, l, l, o를 요소로 가지는 리스트 생성
list3 = list(range(0, 5)) # 0, 1, 2, 3, 4를 요소가 가지는 리스트 생성
# 위는 아래와 같은 문장이다.
list1 = [ ] # 공백 리스트 생성
list2 = [ "H", "e", "l", "l", "o" ] # 문자 H, e, l, l, o를 요소로 가지는 리스트
list3 = [ 0, 1, 2, 3, 4 ] # 0, 1, 2, 3, 4를 요소가 가지는 리스트 생성내장 리스트
list1 = [12, "dog", 180.14] # 혼합 자료형
list2 = [["Seoul", 10], ["Paris", 12], ["London", 50]] # 내장 리스트:
list3 = ["aaa", ["bbb", ["ccc", ["ddd", "eee", 45]]]] # 내장 리스트위와 같이 리스트 안에 리스트가 들어있는 골을 내장 리스트라 칭한다.
내장 리스트가 포함된 리스트의 출력은 2차월 배열과 유사하다. 즉 위의 list2의 'Paris'의 인덱스는 list2[1][0] 이다.
list = [["Seoul", 10], ["Paris", 12], ["London", 50]]
print("list[2][1]: ",list[2][1])
출력 결과:
50내장 리스트를 더플 루프로 출력하는 것이 가능하다. C언어의 2차원 배열과 유사하다.
위의 list[0], list[1], list[2] 각각의 행의 첫 번째에 대한 주소값이 있다. 그리고 list는 그 주소들의 주소를 가진다.
for i in range(len(li2)):
for j in range(len(li2[i])):
print(li2[i][j])
출력 결과:
서울
10
뉴욕
20
파리
30
시퀀스(sequence) 자료형
파이썬에서 리스트는 넓게 보면 시퀀스(sequence) 자료형에 속한다. 시퀀스에 속하는 자료형들은 순서를 가진 요소들의 집합이라는 공통적인 특성이 있으며 시퀀스의 자료형에는 다음 6가지가 있다.
1. 문자열 2. 바이트 시퀀스 3. 바이트 배열
4. 리스트 5. 튜플 6.ragne 객체
이들의 공통적인 특성은
- 요소들이 순서를 가진다.
- 요소들은 인덱스를 통해 참조할 수 있다.
위의 특성의 예는 다음과 같다.
text = "Will is power."
print(text[0], text[3], text[-1])
flist = ["apple", "banana", "tomato", "peach", "pear" ]
print(flist[0], flist[3], flist[-1])
출력 결과:
W l .
apple peach pear다른 언어들과 다르게 파이썬은 시퀀스에 해당되는 자료형에는 모두 동일한 연산자를 사용할 수 있다. 예를 들어 len()을 통해 문자열의 길이, 리스트의 길이를 구할 수 있다.
text = "Will is power.”
print(len(text))
flist = ["apple", "banana“,"tomato", "peach", "pear"]
print(len(flist))
출력 결과:
14
5시퀀스에서 사용가능한 연산자는 다음과 같다.
| 함수나 연산자 | 설명 | 예 | 결과 |
|---|---|---|---|
| len() | 길이 계산 | len([1, 2, 3]) | 3 |
| + | 2개의 시퀀스 연결 | [1, 2]+[3, 4, 5] | [1, 2, 3, 4, 5] |
| * | 반복 | ['hello']*3 | ['hello','hello','hello'] |
| in | 소속 | 3 in [1, 2, 3] | True |
| not in | 소속하지 않음 | 5 not in [1, 2, 3] | True |
| [] | 인덱스 | mylist[1] | mylist의 1번째 요소 |
| min() | 시퀀스에서 가장 작은 요소 | min([1, 2, 3]) | 1 |
| max() | 시퀀스에서 가장 큰 요소 | max([1, 2, 3]) | 3 |
| for 루프 | 반복 | for x in [1, 2, 3]: print (x) | 1 2 3 |
인덱싱과 슬라이싱
인덱싱(indexing)
인덱싱(indexing)이란 리스트에서 하나의 요소를 인덱스 연산자를 통하여 참조(접근)하는 것을 의미한다.
인덱스는 정수이며, 항상 0에서부터 시작하며 (리스트 크기-1)까지의 범위를 가진다. 각 인덱스 요소는 변수와 똑같이 사용이 가능하다. 예를 들어 list[1]에 해당하는 값을 변수 item에 할당이 가능하다.
파이썬에서는 음수 인덱싱이 가능하다. 양수의 인덱스와 다르게 음수 인덱스는 리스트의 맨 뒤의 요소부터 접근한다. 음수 인덱스의 범위는 -1부터 -(리스트 크기)까지다.
만일 리스트의 크기를 넘어서는 인덱스를 사용하면 indexError가 발생한다.
슬라이싱(slicing)
슬라이싱(slicing)은 리스트 안에서 범위를 지정하여서 원하는 요소들을 선택하는 연산이다.
mylist[start:end]와 같은 문법을 취한다. start인덱스 요소부터 end-1요소까지 선택된다.
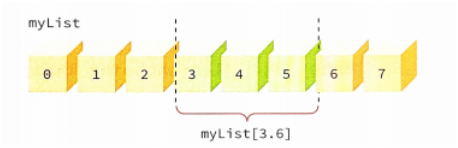
슬라이싱 연산은 요구된 요소를 포함하는 부분 리스트를 반환한다. 즉 슬라이싱 연산을 하면 리스트의 새로운 복사본을 얻을 수 있다는 이야기이다.
슬라이싱 연산에서 시작 인덱스와 종료 인덱스는 생략될 수 있다. 인덱스가 생략되면 시작 인덱스는 0이 되고 종료 인덱스는 (리스트길이-1)이 된다.
print(squares = [0, 1, 4, 9, 16, 25, 36, 49])
print(squares [:3])
print(squares[4:])
print(squares[:])
출력 결과:
[0, 1, 4]
[16, 25, 36, 49]
[0, 1, 4, 9, 16, 25, 36, 49]리스트의 경우 문자열과 다르게 요소들의 변경이 가능하다. 이 때도 슬라이싱에 값을 대입하는 것이 가능하다. 또한 요소들에 공백을 넣음으로써 리스트의 크기를 변경하는 것이 가능하다.
letters = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’]
letters
letters[2:5] = [‘C’, ‘D’, ‘E’] # 리스트의 일부를 변경
letters
letters[2:5] = [] # 리스트의 일부를 삭제
letters
출력 결과:
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’]
[‘a’, ‘b’, ‘C’, ‘D’, ‘E’, ‘f’, ‘g’]
[‘a’, ‘b’, ‘f’, ‘g’]리스트의 기초 연산들
리스트의 합병과 반복
두 개의 리스트를 합칠 때는 +, +=, extend(list타입의 매개변수) 를 사용하면된다.
반복을 할때는 * 연산자를 사용하면 된다.
japan_food = ['스시','타코야끼','오야코동']
korea_food = ['비빔밥','김치','불고기']
korea_japan_food.extend(japan_food)
print(korea_japan_food)
china_food = ['짜장면','짬뽕']
print(china_food*3)
korea_japan_food = korea_food + japan_food
출력 결과:
['비빔밥', '김치', '불고기', '스시', '타코야끼', '오야코동']
['짜장면', '짬뽕', '짜장면', '짬뽕', '짜장면', '짬뽕']
리스트 길이
len()함수를 통해 리스트의 길이를 출력할 수 있다.
japan_food = ['스시','타코야끼','오야코동']
korea_food = ['비빔밥','김치','불고기']
korea_japan_food = korea_food + japan_food
print(len(korea_japan_food))
print(len(korea_food))
출력 결과:
6
3요소 추가하기
.append() 함수를 통해 리스트의 끝에 해당하는 자리에 요소를 추가할 수 있다.
korea_food = ['비빔밥','김치','불고기']
korea_food.append('수육')
print(korea_food)
출력 결과:
['비빔밥', '김치', '불고기', '수육']요소 삽입하기
.append() 메소드는 리스트의 끝에 요소를 추가한다. 하지만 .insert()메소드는 우리가 원하는 특정한 위치에 새로운 요소를 추가할 수 있다.
korea_food = ['비빔밥','김치','불고기']
korea_food.insert(1,'수육')
print(korea_food.index('수육'))
print(korea_food.index('김치'))
print(korea_food)
출력 결과:
1
2
['비빔밥', '수육', '김치', '불고기']위에 '수육'이라는 요소가 인덱스 1번 자리에 들어감으로써 '김치','불고기'요소들은 인덱스가 한 칸씩 뒤로 밀린 것을 확인할 수 있다.
요소 찾기
in연산자를 통해 리스트에 어떠한 요소가 포함되어 있는지를 확인할 수 있다.
korea_food = ['비빔밥','김치','불고기']
if '비빔밥' in korea_food:
print("확인되었습니다")
출력 결과:
확인되었습니다또한 .index() 메소드를 통해 리스트의 요소의 인덱스 번호를 확인할 수 있다.
하지만 그 요소가 리스트안에 없을 시 오류를 발생하므로 조건문과 함께 사용하는 것이 안전하다.
x = '김치'
korea_food = ['비빔밥','김치','불고기']
if x in korea_food:
print(x,"의 인덱스 번호: ",korea_food.index(x) )요소 삭제하기
pop()메서드는 특정한 위치의 요소를 삭제함과 동시에 그 요소를 반환한다.
remove()메서드는 항목을 삭제한다. pop()과의 다른점은 항목 값을 입력받는다는 점과 요소를 반환하지 않는다는 점이다.
remove()메서드를 사용하여 중복된 요소값을 제거할 때는 인덱스 번호가 앞에 있는 것을 먼저 삭제한다.
'del'이 존재한다. del의 사용은 del list[(인덱스 번호)] 이다. remove와 다르고 pop과 같게 인덱스 번호를 받고 그 인덱스 번호에 해당하는 요소를 삭제한다. 또한 삭제된 요소를 반환하지 않는다.
리스트의 모든 요소를 삭제하고자 한다면 슬라이스의 범위를 전부로 하거나([:])혹은 clear를 사용할 수 있다.
요소들이 삭제되면 뒤에 있는 요소와 번호들이 한 칸씩 당겨진다.
# pop()메서드
korea_food = ['비빔밥','김치','불고기']
delete = korea_food.pop(1)
print(korea_food)
print(delete)
출력 결과:
['비빔밥', '불고기']
김치
# remove()메서드
korea_food = ['비빔밥','김치','불고기']
if '비빔밥' in korea_food:
korea_food.remove('비빔밥')
print(korea_food)
출력 결과:
['김치', '불고기']
# del
korea_food = ['비빔밥','김치','불고기']
del korea_food[1]
print(korea_food)
출력 결과:
['비빔밥', '불고기']
# clear을 이용해 모든 요소 삭제
korea_food = ['비빔밥','김치','불고기']
korea_food.clear()
print(korea_food)
출력 결과:
[]리스트 일치 검사
리스트 일치 검사 ==, !=, >, < 를 사용하여 2개의 리스트를 비교할 수 있다. 리스트를 비교하려면 먼저 2개의 리스트가 동일한 자료형의 요소들을 가지고 있어야 한다.
먼저 리스트의 첫 번째 요소끼리 검사한다. 그 요소가 연산자의 답에 해당하면 True가 나오고 다음 요소로 넘어간다. 만일 도중에 False가 나오면 그 뒤로 넘어가지 않고 결과값으로 False를 반환한다. 하지만 끝의 요소까지 True가 나온다면 True를 출력하게 된다.
korea_food = ['비빔밥','김치','불고기']
popular_food = ['비빔밥','김치','불고기']
spy_food = ['비빔밥','기무치!','불고기']
print(korea_food==popular_food)
print(korea_food==spy_food)
출력 결과:
True
False
# 정수를 비교하기
# 아래의 경우 각 인덱스 요소 끼리 비교하다가 li2[2]가 더 크기에 True가 출력된다.
li1 = [1,2,3]
li2 = [1,2,4]
print(li1<li2)
출력 결과:
Ture
# 문자 비교하기
# 아래의 경우는 아스키코드 값을 가지고 비교한다 c와 d는 아스키코드값이 99, 100 이기에 True가 출력된다.
li1 = ['a','b','c']
li2 = ['a','b','d']
print(li1<li2)
출력 결과:
Tureor
리스트 정렬하기
리스트의 요소들을 정렬하는 것은 자주 사용된다 두가지 방법이 있는데
- 리스트 객체의 sort()메서드를 사용하는 방법
- sorted() 내장 함수를 사용하는 방법
sort() 메서드는 리스트를 그 자체 내에서 정렬시킨다. 즉 sort()메서드를 호출하면 원본 리스트가 변경된다. 원본을 유지하고 새로이 정렬된 리스트를 만들고자 한다면 내장 함수 sorted()를 사용하는 것이 바람직하다. sorted()는 정렬된 새로운 리스트를 반환한다.
두 개의 메서드는 reverse 매개 변수를 가지는 데 이는 정렬 방향을 지정하는데 사용된다.
reverse에서 True는 내림차, False는 오름차 순이다.
list1 = [1,4,3,2,5,0]
list2 = [4,5,2,3,10,1]
list = sorted(list1)
print(list)
list = sorted(list1, reverse=True)
print(list)
# reverse에서 True는 내림차, False는 오름차 순이다.
list2.sort(reverse=False)
print(list2)
출력 결과:
[0, 1, 2, 3, 4, 5]
[5, 4, 3, 2, 1, 0]
[1, 2, 3, 4, 5, 10]문자열의 정렬도 가능하다. sorted()의 매개변수로 key=str.lower을 준다면 글자들의 첫 글자를 기준으로 정렬이 가능하다.
# 문자열 정렬하기(한글의 경우 유니코드를 기준으로 정렬을 한다.)
li = ["하와이","폭포","가나","나국"]
li1= sorted(li, key=str.lower)
print(li1)
출력 결과:
['가나', '나국', '폭포', '하와이']
# 문장을 공백을 기준으로 구분으로 나눠 첫 글자의 아스키코드 기준으로 정렬한다.
li = sorted("A picture is worth a thousand words.".split(), key=str. lower))
print(li)
출력 결과:
['A', 'a', 'is', 'picture', 'thousand', 'words.', 'worth']문자열에서 리스트 만들기
문자열의 .split() 메서드는 문자열을 분리하고 이것을 리스트로 만들어서 반환한다.
str = "Hello my name is Hong, and you?"
print(str.split())
출력 결과:
['Hello', 'my', 'name', 'is', 'Hong,', 'and', 'you?']이 때 문자열을 분리하는 분리자(separator)를 지정할 수 있다. 만약, 분리자가 지정되지 않으면 스페이스를 이용하여 문자열을 분리한다.
아래는 콤마(,)를 통해 분리한 것이다.
str = "Hello my name is Hong, and you?"
print(str.split(','))
출력 결과:
['Hello my name is Hong', ' and you?']