[필수 포함 사항]
- READ.ME 작성
- 프로젝트 빌드, 자세한 실행 방법 명시
- 구현 방법과 이유에 대한 간략한 설명
- 완료된 시스템이 배포된 서버의 주소
- 해당 과제를 진행하면서 회고 내용 블로그 포스팅
- Swagger나 Postman을 이용하여 API 테스트 가능하도록 구현
확인 사항
- ORM 사용 필수
- 데이터베이스는 SQLite로 구현
- secret key, api key 등을 레포지토리에 올리지 않도록 유의
- README.md 에 관련 설명 명시 필요
도전 과제: 스스로에게도 도움이 되는 내용 + 추가 가산점
- 배포하여 웹에서 사용 할 수 있도록 제공
- 임상정보 검색 API 제공
과제 안내
다음 사항들을 충족하는 서비스를 구현해주세요.
- 임상정보를 수집하는 batch task
- 수집한 임상정보에 대한 API
- 특정 임상정보 읽기(키 값은 자유)
- 수집한 임상정보 리스트 API
- 최근 일주일내에 업데이트(변경사항이 있는) 된 임상정보 리스트
- pagination 기능
- 최근 일주일내에 업데이트(변경사항이 있는) 된 임상정보 리스트
- Test 구현시 가산점이 있습니다.
실행 예제
- Read
curl localhost:3000/trials/{trial_id} => { "count": 30, "data" : [ { "post" : "test...", "author" : "somebody", "created_at" : 212312312312312, ... }, ... ] } - List
curl localhost:3000/list => { "count": 300, "data" : [ { "post" : "test...", "author" : "somebody", "created_at" : 212312312312312, ... }, ... ] }
프로젝트 자세히
회고
- 처음으로 OpenAPI를 사용하는 과제가 나왔다. 공공데이터포털에서 제공하는 API를 사용하는 것이였는데 API에 대한 자세한 사용방법이 나와있어 편리하게 사용할 수 있다. 임상정보를 수집하는 batch task를 위해 cron을 사용했다.
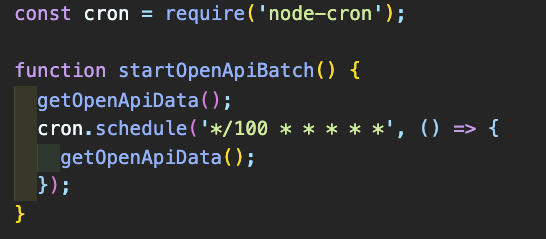 getOpenApiData함수를 먼저 실행 후 100초 뒤에 다시 실행을 반복하는 함수이다.
getOpenApiData함수를 먼저 실행 후 100초 뒤에 다시 실행을 반복하는 함수이다.
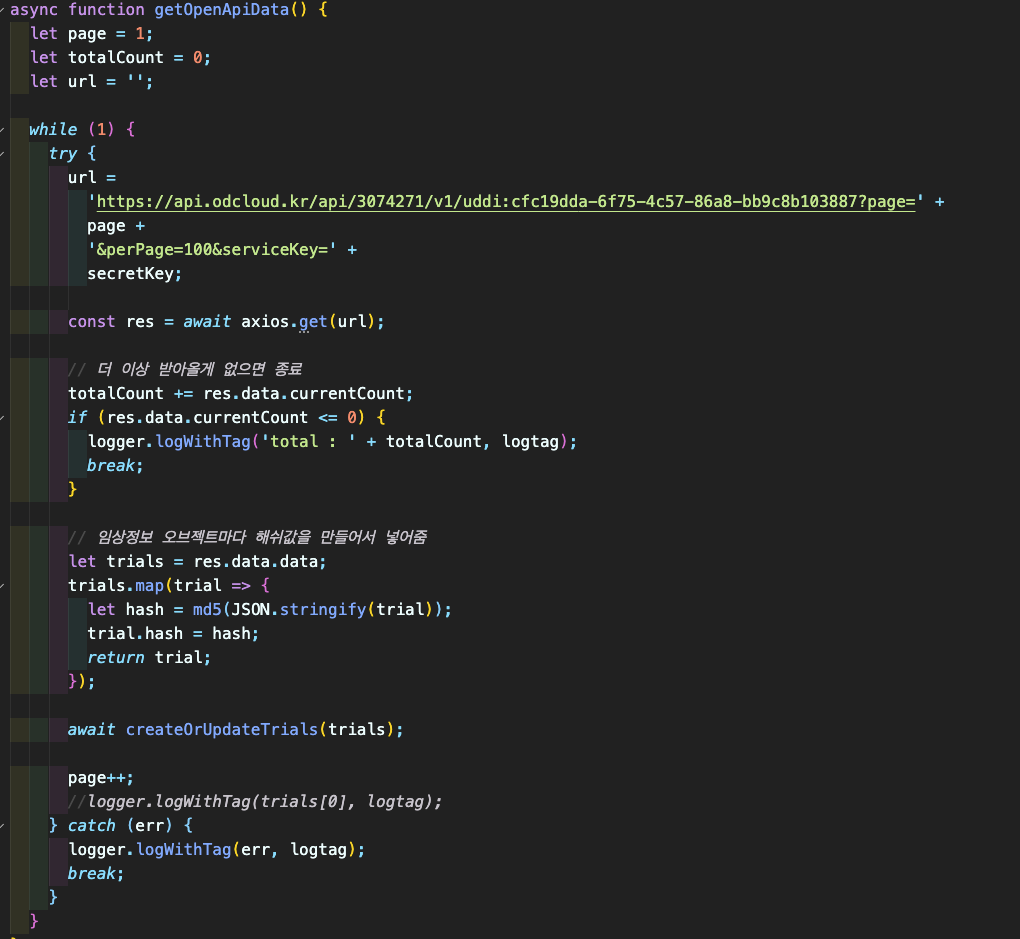 axios로 OpenAPI 데이터를 받아온다. 반복문을 통해 모든 page의 데이터를 읽는다. 데이터에는 수정사항에 대한 표시로 해시값을 포함하였다.(* md5는 객체를 해시하지 못해 JSON.stringify(trial)로 문자열로 만듦) 읽어온 데이터는 데이터베이스 로직에 보내 존재하지 않는 데이터는 생성하고 기존 데이터는 해시값이 변했을 경우 업데이트 한다. 이와 같은 작업을 100초 마다 작업을 한다. 검색API를 구현하는 부분에서 팀원에게 새로운 방식을 배웠다.
axios로 OpenAPI 데이터를 받아온다. 반복문을 통해 모든 page의 데이터를 읽는다. 데이터에는 수정사항에 대한 표시로 해시값을 포함하였다.(* md5는 객체를 해시하지 못해 JSON.stringify(trial)로 문자열로 만듦) 읽어온 데이터는 데이터베이스 로직에 보내 존재하지 않는 데이터는 생성하고 기존 데이터는 해시값이 변했을 경우 업데이트 한다. 이와 같은 작업을 100초 마다 작업을 한다. 검색API를 구현하는 부분에서 팀원에게 새로운 방식을 배웠다. 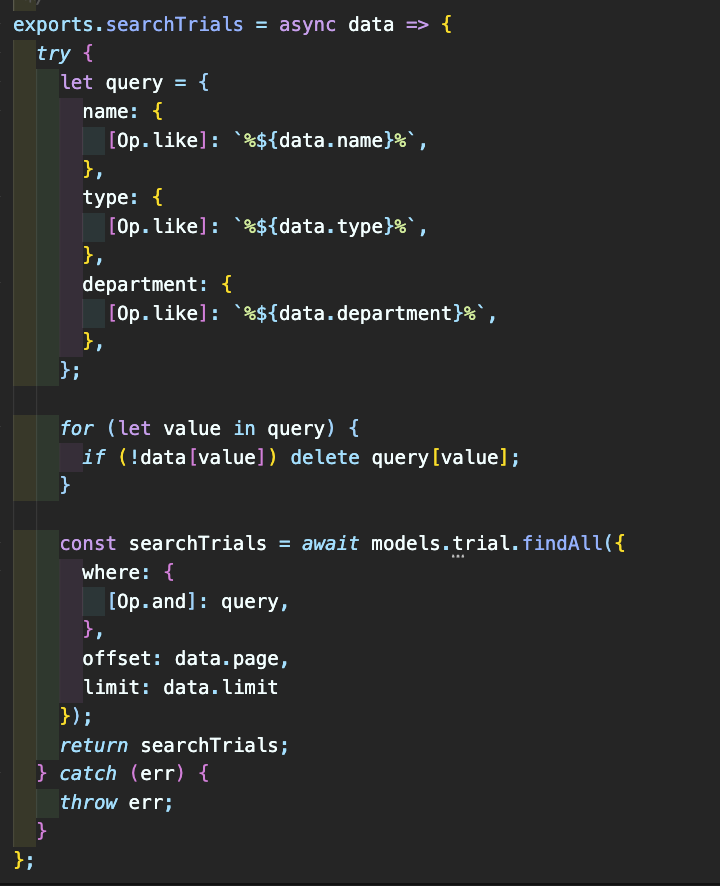 쿼리로 받은 name, type, department의 존재를 먼저 확인한다. 존재하는 것만 데이터베이스 쿼리에 적용하여 조건을 찾는다. 데이터베이스 쿼리에서만 해결하려고 했었는데 분리하여 해결하는 방법이 있다는 것을 익혔다.
쿼리로 받은 name, type, department의 존재를 먼저 확인한다. 존재하는 것만 데이터베이스 쿼리에 적용하여 조건을 찾는다. 데이터베이스 쿼리에서만 해결하려고 했었는데 분리하여 해결하는 방법이 있다는 것을 익혔다.
기록
- sequelize bulkCreate
- 여러 instance를 한번에 생성하고 같은 방식으로 편하게 다루기 위해 사용
- create과 달리 리턴값이 없다
- { returning: true } 옵션을 추가하면 리턴값이 생성

정리노트