Sharding
Sharding은 데이터베이스를 조각으로 나누는 것이다.
샤딩(Sharding)은 horizontal partitioning과 관련된 데이터베이스 설계 패턴이다.
한 테이블의 row들을 여러 개의 서로 다른 테이블(파티션)으로 분리하는 것을 말한다.
vertical partitioning은 열 전체가 완전히 새로운 테이블로 분리되기 때문에 테이블 내의 데이터들은 독립적이며 열과 행이 모두 달라진다.
샤딩(Sharding) 적용에 앞서서
- 샤딩을 적용한다는 것은 프로그래밍, 운영적인 복잡도는 더 높아지는 단점이 있다.
- 가능하면 Sharding을 피하거나 지연시킬 수 있는 방법을 찾는 것이 우선 되어야 한다.
Scale-up- Hardware Spec이 더 좋은 컴퓨터를 사용한다.
- Read 부하가 크다면
- Cache나 Database의 Replication을 적용하는 것도 하나의 방법이다.
- Table의 일부 컬럼만 자주 사용한다면
Vertically partition도 하나의 방법이다.- Data를 Hot, Warm, Cold Data로 분리하는 것이다.
Sharding에 필요한 원리
- 분산된 Database에서 Data를 어떻게 Read할 것인지
- 분산된 Database에 Data를 어떻게 잘 분산시켜서 저장할 것인지
- 분산이 잘 되지 않고, 한 쪽으로 Data가 몰리게 되면 자연스럽게 Hotspot이 되어 성능이 느려지게 된다.
- 이런 이유로 균일하게 분산하는 것이 중요한 목표이다.
구현
주로 application level에서 실행된다.
여기서 application은 어떤 shards에 읽기와 쓰기를 전송할지를 정의하는 코드를 포함하고 있는 것을 말한다.
어떤 데이터베이스 관리 시스템은 내장된 sharding 능력이 있어서 database level에서 바로 사용할 수도 있다.
Shard Key를 어떻게 정의하는냐에 따라 데이터를 효율적으로 분산시키는 것이 결정된다.
올바른 shard에 일관성 있는 방식으로 들어갈 수 있도록 entry를 위치시키기 위하여 hash함수에 들어가는 value들은 같은 column에서 나와야 한다.
이 column을 shard key라고 부른다.

방법에 대해서
Hash Sharding
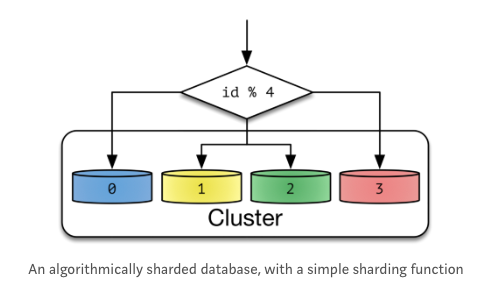
Shard Key: Database id를 hashing하여 결정한다.
Hash의 크기는 Cluster안에 있는 Node개수로 정하게 된다.
간단한 Sharding 기법이다.
Dynamic Sharding

Naming 그대로 Dynamic으로 바꿀 수 있다.
Locator Service를 통해 Shard Key를 얻는다.
Cluster가 포함하는 Node의 개수를 늘려도 Locator Service에 Shard Key를 추가만 하면된다.
기존의 Data의 Shard Key는 변경이 없으며, 확장에 유연한 구조이다.
- Example
HDFS: Name Node
MongoDB: ConfigServer
Entity Group
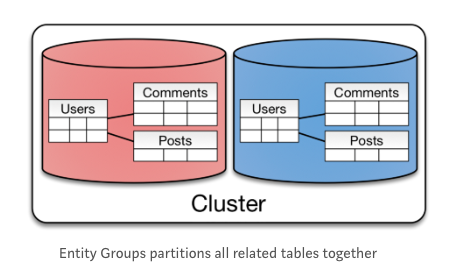
이전에 RDBMS의 join, index, transaction을 사용해 application의 복잡도를 줄일 수 있었다.
이와 유사한 방법으로 Sharding하는 것이 Entity Group이다.
- 하나의 물리적인 Shard에 쿼리를 진행한다면 효율적이다.
- 하나의 Shard에서 강한 응집도를 가질 수 있다.
- 데이터는 자연스럽게 사용자별로 분리되어 저장된다.
- 사용자가 늘어남에 따라 확장성이 좋은 partitioning이다.
다만, cross-partition 쿼리는 single partition 쿼리보다 consistency의 보장과 성능을 잃는다.
따라서 이런 쿼리들이 자주 실행하지 않도록 만들어야한다.
Pitfall

Dynamic Sharding을 진행하게 된다면 작업량을 효과적으로 줄일 수 있다.
HotSpot을 찾고 Sharding을 진행한다.
지속적으로 Sharding으로 진행하게 된다면 가장 오른쪽 Node만 Write를 진행하게 된다.
나머지 Node들은 Read Performance가 향상하는 효과를 얻을 수 있다.
언제 사용하는가
복잡성 때문에 Sharding은 대규모의 데이터를 다룰 때 사용된다.
주로 다음과 같은 상황에서 유용하다.
- 애플리케이션 데이터의 양이 단일 database node의 storage 한계를 초과했을 때
- 쓰기, 읽기의 양이 단일 노드나 read replica가 핸들링할 수 있는 수준을 넘어 반응이 느려졌을 때
- 하나의 database node 또는 read replica에 가능한 네트워크 대역폭을 초과해 반응속도가 느려졌을 때
Sharding을 피하는 방법을 우선 적용해보고 불가피하다면 그때 적용하는 것이 좋다.
Sharding에 반드시 Trade-Off가 있다.
- Locator와 Sync해야하는 비용이 필요하다.
- Cross-Partition Query가 발생할 경우 기존의 Query보다 느릴 수 있다.
참고자료
https://nesoy.github.io/articles/2018-05/Database-Shard
https://velog.io/@matisse/Database-sharding%EC%97%90-%EB%8C%80%ED%95%B4
