
이 게시글은 윤기원(AWS 파트너 솔루션즈 아키텍트), 김윤섭(AWS 데이터베이스 아키텍트)님의 일체형 데이터베이스, 목적에 맞게 MSA 구조로 전환하기 강연을 듣고 정리한 내용입니다.
모던 애플리케이션에서 요구하는
높은 성능,확장성,가용성,개발 편의성을 확보하기 위해 많은 회사들이 모놀리틱 구조에서 MSA 구조로 전환하고 있습니다. 하나의 큰 모놀리틱 DB를 MSA 구조로 전환하는 방법을 알아보고 이를 통해 얻을 수 있는 장점들에 대해서 알아보겠습니다.
먼저 모던 애플리케이션의 특징과 이러한 특징들이 마이크로 서비스 아키텍처와 어떠한 관계가 있는지 살펴보겠습니다.
과거의 레거시 애플리케이션과는 다른 모던 애플리케이션의 특징은 어떤 것이 있을까요 ?
모던 애플리케이션의 특징
전 세계의 수많은 사용자들이 서비스를 이용할 수 있으며, 사용자들은 PC뿐 아니라 모바일, IoT 등 다양한 방식으로 서비스를 이용하게 됩니다. 또한 이용하는 사용자의 숫자는 적게는 수천에서 많게는 수백만 이상이 될 수 있으며, 이러한 사용자의 증가는 필연적으로 서비스 요청의 증가와 데이터양의 증가로 이어지게 됩니다. 하지만 이러한 복잡해진 환경에서도 전 세계의 고객들은 여전히 빠른 응답시간을 보장받길 원합니다. 따라서 모던 애플리케이션은 좀 더 빠르게 동작하면서도, 동시에 안정적이어야 합니다. 또한 데이터의 정합성은 유지하면서, 동시에 개발자들은 빠른 개발과 배포가 가능해야 합니다.

그러면 이러한 모던 어플리케이션의 요구사항을 만족하기 위해서는 어떻게 해야 할까요 ?
모던 애플리케이션을 위한 마이크로 서비스 아키텍처를 말하기에 앞서서 그 반대편에 있는 모놀리스 아키텍처를 먼저 살펴보겠습니다.
모놀리스 아키텍처
기존 모놀리틱 시스템은 여러 서비스들이 오라클로 대표되는 하나의 큰 RDBMS를 메인 DB로 사용하고 또 각 서비스들은 서로 강한 의존성을 가집니다. 이런 모놀리틱 구조에서는 관리 포인트가 줄어들고 시스템을 표준화하기 쉽다는 장점이 있었습니다. 하지만 이러한 모놀리틱 구조에서 개발자들은 새로운 서비스를 추가한다거나 기존의 서비스를 변경하는 것에 큰 어려움을 겪었습니다. 또한 이러한 모놀리틱 시스템 구조에서는 사용자나 요청이 폭증할 경우 이를 처리하기 위한 확장성을 가지는 것이 어려웠습니다.
그리고 이러한 문제들을 해결하기 위해서 국내에서도 마이크로 서비스 아키텍처를 도입하는 사례들이 많아지고 있습니다. 마이크로 서비스를 도입하게 되면 서로 독립적인 서비스를 구성할 수 있으며 이를 통해서 개발이나 배포가 용이해지고 시스템의 확장도 용이해집니다. 그러면 마이크로 서비스가 어떻게 이런 것을 가능하게 하는지 알아보겠습니다.
기존의 모놀리틱 시스템 구조에서는 애플리케이션이나 DB에서 변경이 있을 경우 그에 따른 영향이 매우 컸습니다. 따라서 새로운 개발을 하거나 변경을 할 경우에는 수많은 서비스 담당자들이 모두 함께 작업을 해야 했습니다. 그러다 보니 새로운 기술을 도입하는 것은 커녕, 작은 변경이나 배포조차 정해진 유지 보수 시간에만 반영이 가능했습니다. 결국 개발자와 운영자들 모두 효율성이 떨어지게 되고 전체 시스템 관점에서도 지속적으로 기술 부채가 쌓이는 문제가 발생되었습니다. 이러한 문제를 해결하기 위해 모놀리틱 시스템을 서비스 단위로 분리하는 마이크로 서비스 아키텍처가 등장했습니다. 마이크로 서비스 아키텍처의 도입은 서비스 단위로 개발팀을 좀 더 작게 나누고 개발과 운영에 대한 권한과 책임을 위임함으로써 더 빠른 개발과 배포를 하면서도 서비스 간의 영향을 줄일 수 있게 만들었습니다. 그리고 이러한 마이크로 서비스를 위한 DB 전환은 적절한 데이터베이스를 선택하는 것부터 시작됩니다.

그러면 어떻게 적합한 목적별 DB를 선택해서 마이크로 서비스로의 전환을 용이하게 할까요 ?
모던 애플리케이션은 수백만의 트래픽 수용과 밀리 세컨드 단위의 빠른 응답속도를 제공해야 하고 유연한 확장이 가능해야 하며 어떤 장애 상황이 오더라도 안전하게 시스템과 데이터를 보호할 수 있어야 합니다. 또 다양한 고객의 요구사항에 빠르게 대응하고 신속하게 서비스를 배포할 수 있어야 합니다.
그런데 과연 전통적인 모놀리틱 관계형 데이터베이스가 이와 같은 모던 애플리케이션의 요구사항을 효율적으로 처리할 수 있을까요 ?
이미 많은 기업들이 모놀리틱 시스템의 한계점을 인지하고 MSA로의 대대적인 전환을 시작하였거나 준비 하고 있습니다.
그렇다면 통합된 모놀리틱 데이터베이스는 어떤 한계점을 가지고 있을까요 ?
통합된 데이터베이스 한계
전통적인 모놀리틱 관계형 데이터베이스는 데이터의 변경 시 정규화된 테이블들 간에 ACID 트랜잭션을 유지해야 하고 필요로 하는 데이터를 조회하기 위해 여러 테이블들을 조인해야 합니다. 이런 이유로 트래픽이 증가함에 따라 지속적으로 낮은 응답속도를 보장하기가 쉽지 않습니다. 또 폭증하는 데이터를 저장하고 관리하기 위해서 데이터베이스의 용량을 확장해야 하지만 관계형 데이터베이스의 확장 방식인 수직 확장은 디스크 용량이나 CPU 또는 Memory 같은 자원을 추가하는데 많은 시간이 소요되고 확장 가능한 최대 용량의 한계를 가지고 있습니다. 다양하고 빠르게 변화하는 고객의 요구사항을 만족시키기 위해 개발자들은 유연한 개발 환경에서 적절한 도구를 선택하고 애플리케이션을 빠르게 개발하여 대응해야 합니다. 하지만 하나의 통합된 데이터베이스는 문제 해결을 위한 적절한 도구 선택의 폭을 제한하게 되고 이것은 개발자의 생산성을 떨어뜨려 서비스의 품질을 저해하는 원인이 됩니다.
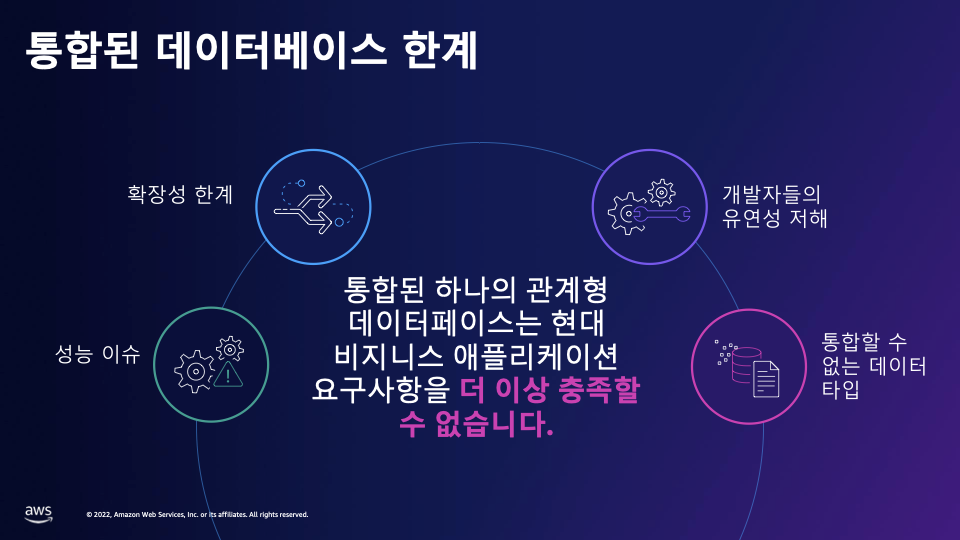
워크로드마다 데이터는 다양한 특성을 가지고 있습니다. 하나의 통합된 데이터베이스가 다양한 특성의 데이터를 저장하고 그 데이터를 효율적으로 처리할 수 있을까요 ?
예를 들어 문서 데이터를 관계형 데이터베이스에 저장하는 것과 DocumentDB와 같은 문서 전용 데이터베이스에 저장하는 것 둘 중 어떤 것이 더 효율적일까요 ?
목적별 데이터베이스
목적별 데이터베이스는 이런 한계점에 현실적이고 효율적인 해결책이 될 수 있습니다. 포크레인과 트럭이 다른 목적으로 사용되는 것처럼 각각의 데이터베이스 서비스들도 효율적으로 처리할 수 있는 데이터가 있고 그렇게 하지 못하는 데이터가 있습니다. 서비스 별로 목적에 맞는 데이터베이스를 잘 선택함으로써 우리는탄력적인 확장성,빠른 성능,신뢰할 수 있는 가용성을 확보할 수 있습니다. 또 목적에 맞는 데이터베이스를 사용하여 마이크로서비스 아키텍처 애플리케이션을 개발한다면 개발의 유연성 확보와 함께 빠른 배포가 가능해집니다. 이를 통해 트래픽과 데이터 증가에 대응하고 비즈니스에서 요구되는 혁신을 더 많이 수행하며 혁신을 통해 나온 새로운 기능들을 더 빠르게 시장에 출시하여 기업의 비즈니스 경쟁력을 확보하고 성장시킬 수 있습니다.최근 데이터베이스 산업 군에서는 데이터를 특성에 따라
관계형,키-밸류,다큐먼트,인메모리,그래프,타임시리즈,원장,와이드 컬럼등 8개의 카테고리로 분류하였고 AWS는 이에 맞게 각 카테고리에 적합한 데이터베이스 서비스를 제공하고 있습니다.

카테고리별 데이터베이스
각 카테고리별 데이터베이스를 간단히 살펴보겠습니다.
관계형 데이터베이스
관계형 데이터베이스로서는 Aurora와 RDS가 있습니다. Aurora는 대용량 트래픽을 빠른 성능으로 동시에 처리할 수 있는 분산 스토리지 데이터베이스이며, MySQL 또는 Postgresql을 선택할 수 있습니다. RDS는 오라클, MS-SQL Server 등의 사용 데이터베이스 서버들과 MySQL, Postgresql 등의 오픈소스 데이터베이스를 지원합니다.
온프레미스에 있는 관계형 데이터베이스를 리프트앤시프트로 전환하거나 금융 등 데이터 무결성과 트랜잭션을 보장해야 하는 경우에 좋은 선택지가 될 것입니다.
Key-Value 데이터베이스
다음으로 초당 수백만의 높은 요청 처리와 10밀리세컨드 미만의 응답 성능을 일정하게 보장하는 NoSQL Key-Value DataStore로 DynamoDB가 있습니다. DynamoDB는 NoSQL Database이지만 보조 인덱스 및 ACID 트랜잭션을 제공하며 온라인 쇼핑의 장바구니나 제품 카탈로그 등의 서비스에서 주로 사용될 수 있습니다. 또 하나의 NoSQL 데이터베이스로 문서형 데이터를 효율적으로 저장하고 모든 속성에 대해서 빠른 조회 성능을 제공할 수 있는 MongoDB와 호환성을 가지고 있는 DocumentDB가 있습니다. 스키마리스 DB이므로 개발의 유연성을 최대한으로 활용할 수 있습니다. DocumentDB는 초당 수백만의 요청량을 처리할 수 있고 밀리세컨드 수준의 응답시간을 제공합니다.
인메모리
다음으로 완전 관리형의 인메모리 데이터 저장소로 Amazon ElasticCache가 있습니다. ElasticCache는 Redis, Memcached와 호환되며 마이크로세컨드 수준의 응답시간을 제공합니다.
자주 사용되는 데이터를 캐싱하는 용도로 많이 사용하고 특히 Redis의 경우 다양한 데이터 저장 방식을 저장하는데 Sorted set을 사용하여 실시간 리더보드 서비스를 손쉽게 구축할 수 있습니다.
그밖의 데이터베이스들
이 외에도 수십억 개의 관계를 저장하고 데이터 간의 관계를 손쉽게 쿼리할 수 있게 해주는 그래프 기반의
Neptune, IoT 디바이스에서 들어오는 데이터들을 시간 기준으로 빠르게 저장하고 조회할 수 있는Amazon Timestream, 원장 데이터의 변조를 방지하고 모든 변경 이력을 체이닝 방식으로 관리하는Amazon Quantum Ledger Database, 카산드라와 호환성을 가지는Amazon Keyspaces 데이터베이스가 있습니다. 앞에서 간단히 살펴본 것과 같이 AWS는 데이터 중심으로 뛰어난 확장성을 가진 분산된 애플리케이션을 구축할 수 있도록 다양한 목적 별 데이터베이스 포트폴리오를 제공합니다. 이를 통해 신뢰성이 높고 안전한 데이터 인프라스트럭쳐를 구축할 수 있고 데이터베이스 운영에 들어가는 시간과 비용을 절약하고 규모에 맞게 성능을 개선하여 빠르게 혁신할 수 있습니다. AWS 데이터베이스들은 처음부터 마이크로서비스 아키텍처를 기반으로 모던 애플리케이션의 확장성, 성능, 가용성의 요구사항을 충족시키기 위해 설계되었기 때문에 고객의 다양한 워크로드를 유연하게 지원할 수 있습니다.
Hands-Lab 개요
다음 핸즈랩은 웹서비스에서 일반적으로 많이 사용되는 네 개의 비즈니스 워크로드를 대상으로 합니다. 각 서비스들은 하나의 통합된 오라클 데이터베이스에 스키마로 구분되어 데이터를 저장하고 있습니다. 우리는 핸즈온랩을 통해 각각의 서비스와 그 서비스에 해당하는 데이터를 목적에 맞는 데이터베이스 서비스로 전환합니다. 이를 통해 목적별 데이터베이스로 전환하는 방법을 습득하고, 목적별 데이터베이스 구축의 장점을 이해하게 될 것입니다.

대상이 되는 비즈니스 워크로드는 다음과 같습니다.
온라인 마켓의한정판매 서비스,리더보드 조회 서비스,CRM 고객 상담 서비스,사용자의 구매내역 조회 서비스입니다. 한정판매 서비스는 Hot Block으로 인한 문제를 해결하기 위해 Redis로 전환을 하고 LeaderBoard 역시 고객의 실시간 요구사항을 충족시키기 위해 Redis로 데이터를 전환합니다. CRM 콜센터 상담 내역 조회 서비스는 문서 기반 NoSQL MongoDB로 구매내역 조회는 AWS의 Key-Value 데이터베이스인 DynamoDB로 전환하게 됩니다.
핸즈온랩 1
Oracle과 같은 RDBMS는 그 특성상 리포트나 Document 형식의 데이터를 처리하기 위해서 여러 Table들을 조회하거나 조인을 해야 했습니다. 그리고 여러 테이블 간의 Join은 DB 전체의 부하를 크게 증가시키고 개발과 운영의 난이도를 높이게 됩니다. 첫 번째 핸즈온은 자바와 오라클을 사용하는 모놀리틱 CRM 시스템 중, 고객 상담 업무 서비스를 파이썬 플라스크와 몽고디비로 전환하는 핸즈온입니다.여러분은 CRM 업무중 고객상담 업무를 별도의 서비스로 분리할 것입니다. 고객 상담 업무의 경우 오라클 DB의
CUSTOMERS,CALL_HISTORY등 여러 개의 Table들이 조인되어 고객의 과거 상담 이력을 리포트 형태로 보여주게 됩니다. 그리고 이렇게 여러 테이블을 조인하는 과정에서 DB의 부하는 크게 증가하게 되고, 결국 전체 시스템의 성능이 떨어지게 됩니다. 이런 문제를 해결하기 위해서 고객 상담업무를 별도의 서비스로 분리해 보겠습니다. 먼저 백엔드에서 '고객상담업무' 서비스를 레거시 자바 어플리케이션에서 경량화된 파이썬 플라스크로 변경합니다.리파지토리에서 고객상담업무 리포트에 필요한
CUSTOMERS와CALL_HISTORYTable의 데이터를 이관합니다. Join이 필요한 두 개 테이블의 데이터를 몽고디비의 Document로 전환함으로써 메인 CRM 디비의 부하를 줄이면서 동시에 개발자들은 몽고디비의 Document를 사용하여 더 쉽게 개발을 할 수 있게 됩니다.데이터 이관
RDB의 데이터를 Document로 변경하는 방법은 여러 가지 방법이 있는데 AWS Database Migration Service를 사용하여 손쉽게 오라클의 관계형 디비 데이터를 몽고디비의 도큐먼트 데이터로 마이그레이션 합니다.
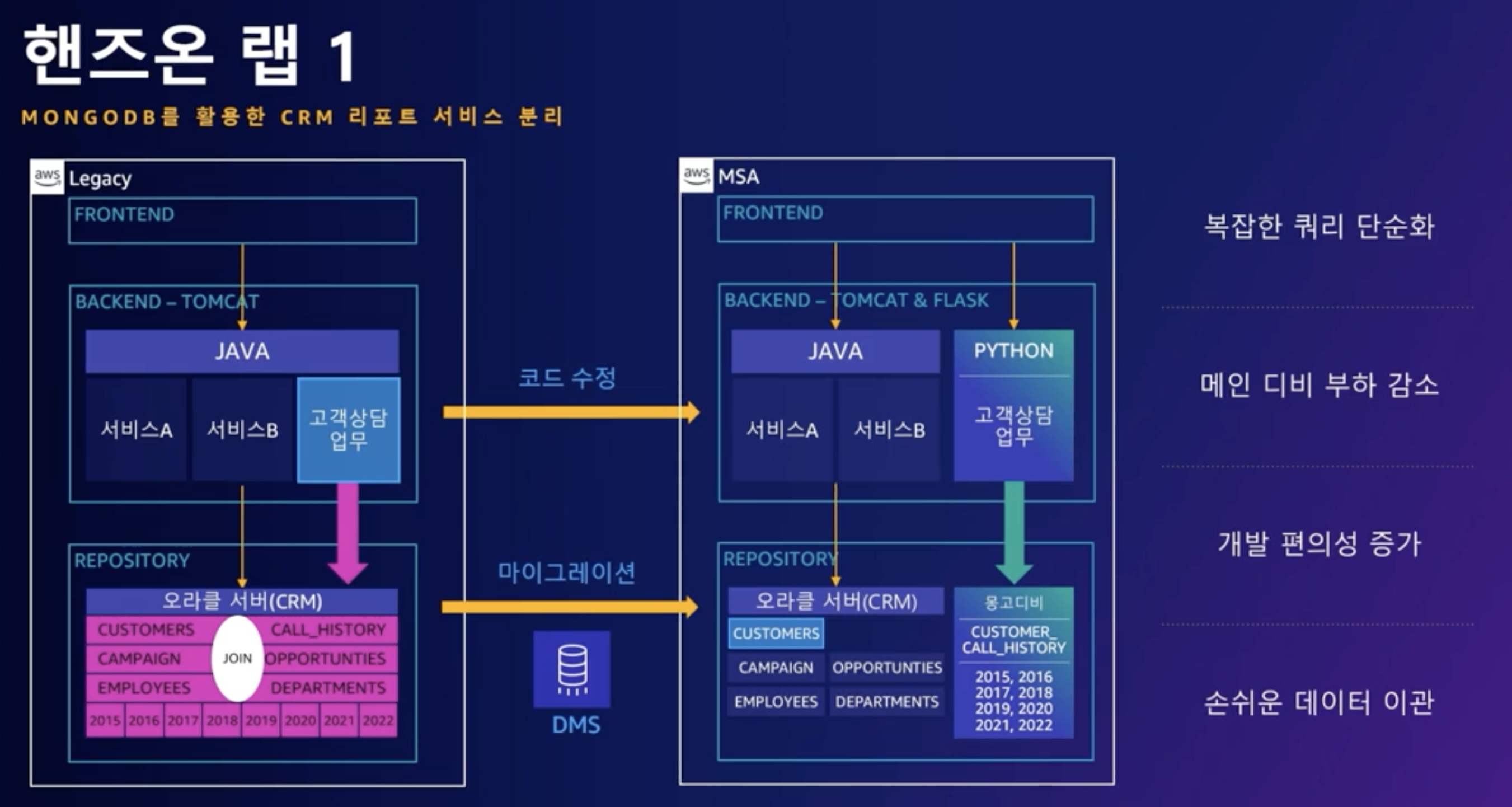
CRM 고객 상담 업무 데이터를 오라클에서 몽고디비로 전환함으로써 복잡했던 SQL을 단순화할 수 있으며 조인 과정이 필요 없기 때문에 DB의 부하도 줄어들게 되었습니다. 또한 코드 변경을 최소화하면서도 API를 사용하면서 개발 편의성이 증가하였습니다.
핸즈온랩 2
기존 관계형 데이터베이스에 있는 데이터를 Redis로 전환하고 실시간 리더보드를 구성합니다. 먼저 원본 시스템인 오라클의 리더보드 구성 방식을 살펴보겠습니다. 일반적으로 관계형 데이터베이스에서는 랭크 함수를 사용하여 리더보드 데이터를 만들게 됩니다. 데이터가 많을 경우 리더보드를 생성하는 쿼리가CPU,디스크,메모리등의 많은 시스템 자원을 사용하기 때문에 이 쿼리를 실행할 경우 사용자로부터 유입되는 실시간 요청을 지연시키는 원인이 됩니다.그래서 보통은 별도의 서버에 원본 데이터를 복사하고 거기서 리더보드 데이터를 만든 다음 다시 원래 서버로 데이터를 복사하는 방식을 취합니다. 이런 이유로 실시간 리더보드 서비스를 제공하기가 쉽지 않습니다. 이 문제를 해결하기 위해서 원본 오라클을 바라보던 리더보드 서비스를 분리하여 Redis를 바라보도록 수정하고 오라클의
USER_SCORE와LeaderBoard테이블을 Redis의 Sorted set 형식으로 전환합니다. Sorted set을 사용하면 데이터가 저장될 때 키에 정의된 스코어 기준으로 저장되고 데이터의 순위 관련 함수들을 사용할 수 있기 때문에 오라클에서처럼 별도의LeaderBoard테이블을 유지할 필요가 없습니다. 리더보드 서비스를 Redis로 전환함으로써 Redis가 제공하는 기능을 활용하여 손쉽게 고객의 요구사항인 실시간 리더보드를 제공할 수 있데 되었고 순위 데이터를 만들기 위한 용도로 별도의 인프라를 구성할 필요가 없기 때문에 시스템 유지와 운영을 위한 비용을 절감할 수 있습니다.데이터 이관
먼저 Redis의 Sorted set 구조에 맞게 오라클에 스테이징 테이블을 만듭니다. 이 테이블의 컬럼은 Redis sorted set의 키이름, 레벨과 경험치를 조합한 스코어, 유저 아이디로 구성됩니다. 그 데이터를 csv 파일로 만든 후 리눅스의 awk 커맨드와 redis의 cli 파이프 옵션을 조합하면 간단하게 데이터를 redis로 전환할 수 있습니다. 전환된 데이터는 스코어를 기준으로 정렬되어 저장됩니다.


핸즈온랩3
Database에서 특정 데이터 블록에 대한 요청이 늘어나게 되면 Hot block이 발생할 수 있습니다. 그리고 핫 블록의 발생은 사용자 요청 처리를 느리게 만드는 원인이 됩니다. 특히 한정 판매 이벤트나 주문 시스템 등은 동시에 수많은 사용자들의 요청을 받게 되고 이에 따라 Hot Block이 발생할 가능성이 높아집니다. 세 번째 핸즈온은 파이썬 플라스크와 오라클을 사용하는 모놀리틱 온라인 쇼핑몰 시스템 중 한정 판매 이벤트 서비스를 레디스로 전환하는 핸즈온입니다.온라인 쇼핑 업무 중 "한정판매"를 별도의 서비스로 분리할 것입니다. 레거시 한정 판매 어플리케이션의 경우 오라클 DB의
HOTDEAL_LISTTable에서 남은 수량을 조회하고 남은 수량이 있으면 판매가 되는 구조로 되어 있습니다. 그리고 데이터의 정합성을 보장하기 위해서 남은 수량에 대한 Data Row가 Locking 되고 이는 전체 사용자 요청 처리가 지연되는 원인이 됩니다. 이러한 문제점을 해결하기 위해서 한정 판매 서비스의 DB를 RDBMS인 오라클에서 인 메모리 DB인 레디스로 전환해 보겠습니다.먼저 Backend는 단일 모놀리틱 플라스크 어플리케이션에서 별도의 모듈로 분리됩니다. 리파지토리는 오라클의
HOTDEAL_LIST테이블에서 레디스의 컬렉션으로 변경됩니다. 무거운 Lock 매커니즘의 오라클에서 경량화된 레디스로 변경을 하게 되면 사용자 요청 프로세스 간의 경합이 줄어들게 되고 전체 성능이 개선됩니다.
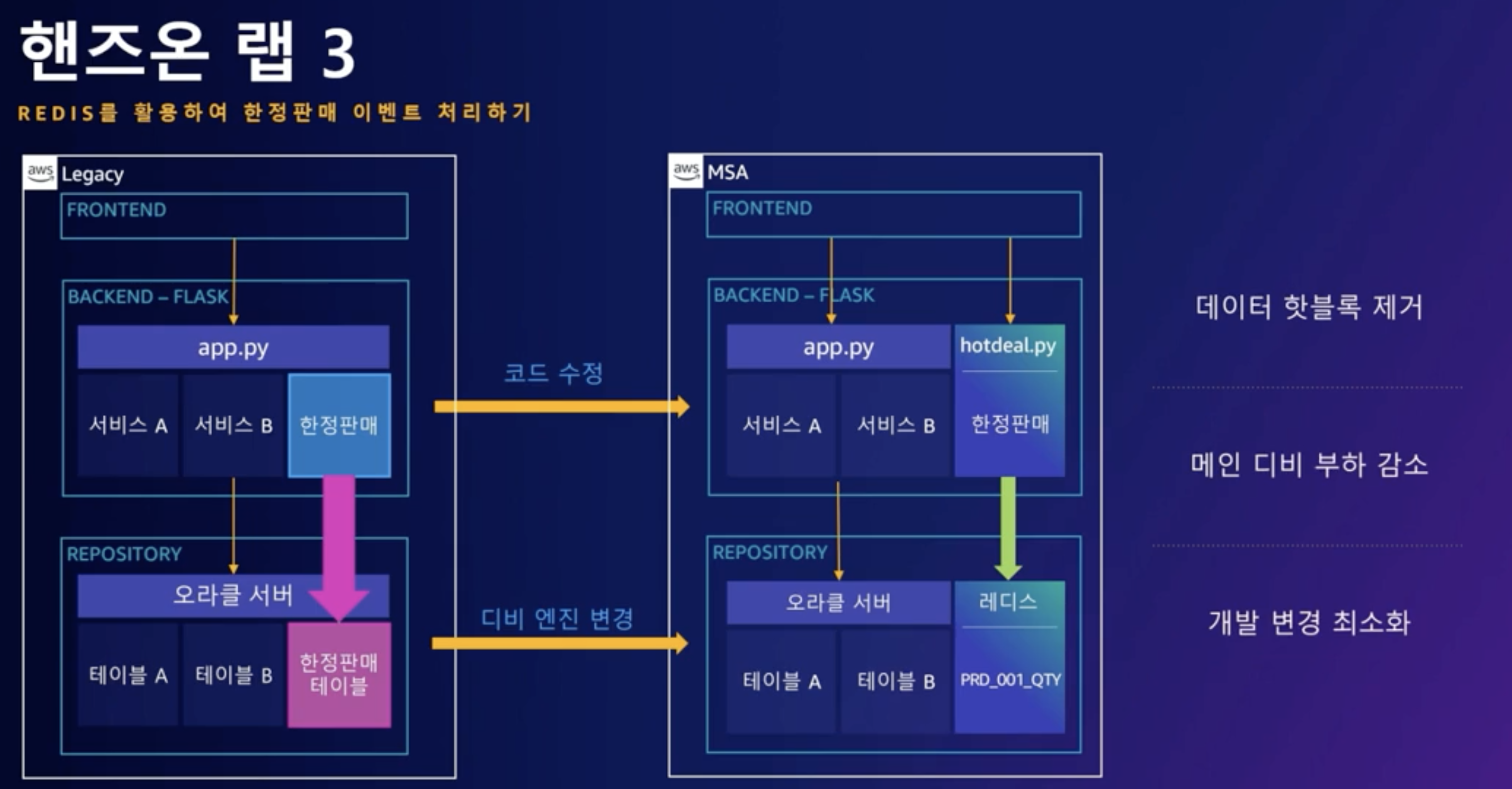
기존 레거시에서 100초가 걸리던 처리가 신규 MSA 구조에서는 25초 정도로 줄어들게 만들었습니다. 한정 판매 서비스를 오라클에서 레디스로 전환하면서 개발 코드의 변경은 몇 줄 되지 않았습니다. 그러나 이 작은 변경으로 인해서 데이터 핫 블록이 제거되고 이로 인해 메인 디비의 부하도 줄이면서 동시에 한정 판매 서비스의 성능이 약 4배 가까이 개선되었습니다.
핸즈온랩4
구매내역 데이터를 DynamoDB로 전환하고 Flask로 작성된 구매내역 조회 서비스를 gatling을 활용하여 호출합니다. Legacy 관계형 데이터베이스에서 구매내역을 조회하기 위해서는 여러 테이블들을 조인하여 데이터를 만들어야 합니다. 구매내역을 기록할 때도 여러 테이블에 기록해야 하며 이때 각 테이블 간 트랜잭션을 유지하고 참조키 제약조건을 체크하는 등의 추가적인 비용이 발생됩니다. 이런 이유로 트래픽이 늘어날 경우 관계형 데이터베이스는 성능상의 한계 상황에 직면합니다. 이를 해결하기 위해 구매 내역 조회에 사용되는 4개 테이블을 통합하여 하나의 DynamoDB 테이블로 전환합니다. 데이터를 전환하는 방법은 여러가지가 있겠지만 여기서는 AWS Database Migration Service를 활용하겠습니다. 데이터베이스 마이그레이션 서비스는 파티션키와 소트키, 그리고 이관 대상 속성들을 지정할 수 있는 기능을 제공하기 때문에 손쉽게 필요한 데이터를 원하는 형식으로 전환할 수 있습니다. 이렇게 함으로써 요청량이 증가하더라도 일관된 쿼리 성능을 보장하고 유연하게 확장할 수 있으며 스키마 플렉서블한 DB의 장점을 활용한 개발의 유연성을 확보할 수 있습니다.데이터 이관
데이터 전환 방법을 간단히 살펴보겠습니다. 먼저 DynamoDB에 맞게 원본 데이터베이스에 스테이징 테이블을 구성하였습니다. 왼쪽 쿼리는 원본에서 조인 결과로 나온 여러 행들을 하나의 행으로 피버팅하는 쿼리입니다. 이렇게 한 개의 행으로 변환한 다음 AWS의 데이터베이스 마이그레이션 서비스를 사용하여 전환하면 오른쪽과 같이 JSON 형태의 하나의 아이템으로 DynamoDB에 데이터를 저장할 수 있습니다. 파티션키, 소트키, 전환 대상 속성들을 지정하는 방법은 실습과정에서 데이터베이스 마이그레이션 서비스의 Task Json 파일을 통해 상세히 확인할 수 있습니다.


