
Row Migration
행이전
1. UPDATE 인해 행 길이가 증가했을 때, 저장 공간이 부족한 경우 발생
2. 원래 정보를 기존 블록에 남겨두고 실제 데이터는 다른 블록에 저장
검색 시, 원래 블록에서 주소를 먼저 읽고 다른 블록을 찾아야 하므로 성능 감소3. 해결책: PCTFREE 영역을 충분히 할당한다
PCTFREE가 너무 큰 경우 데이터 저장 공간 부족으로 공간 효율성 감소
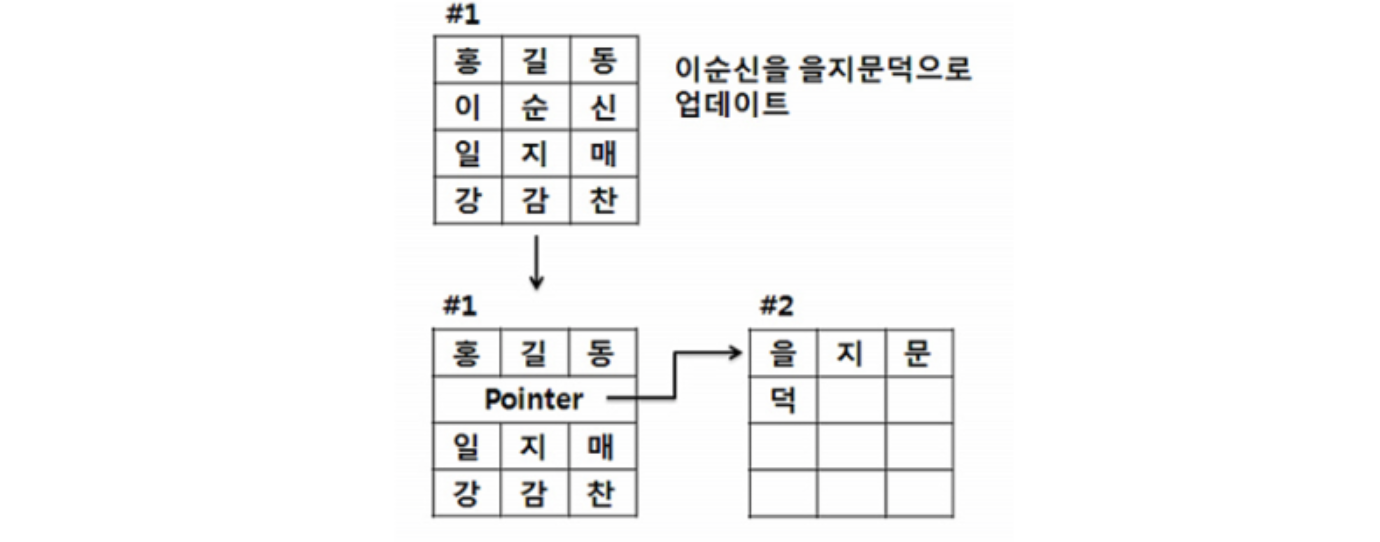
위 이미지에서 표는 데이터 블록에 해당하고 홍길동, 이순신 등의 텍스트는 저장된 데이터이며 전혀 남는 공간 없이 모든 블록에 데이터가 가득차 있는 상태이다. 그런데 여기서 이순신을 을지문덕으로 UPDATE 쿼리를 날린다고 가정하면 이미 데이터가 가득찬 데이터 블록에는 더 이상 늘어난 내용을 저장할 공간이 없어 바뀐 내용을 저장할 새로운 데이터 블록이 필요하게 된다. 그리고 기존 공간에는 새로운 저장공간에 대한 포인터 값이 남게 된다.
이런 Row Migration 현상이 발생하게 되면 한 번에 검색할 수 있었던 데이터를 2개의 데이터 블록을 검색하고 나서야 원하는 정보를 얻을 수 있게 되고 공간 낭비가 발생하게 된다. 이런 문제를 방지하기 위해 PCTFREE를 통해 여유공간 확보가 필요한 것이다.
Row Chaining
행연결
1. 데이터가 커서 여러 블록에 나누어 저장하는 현상
2. Initial Row Piece(행 조각)와 Row Pointer로 블록 내에 저장
3. 한 개의 row에 들어가는 컬럼의 수나 컬럼당 데이터 크기 최소화 또는 데이터 압축으로 로우 체이닝 방지
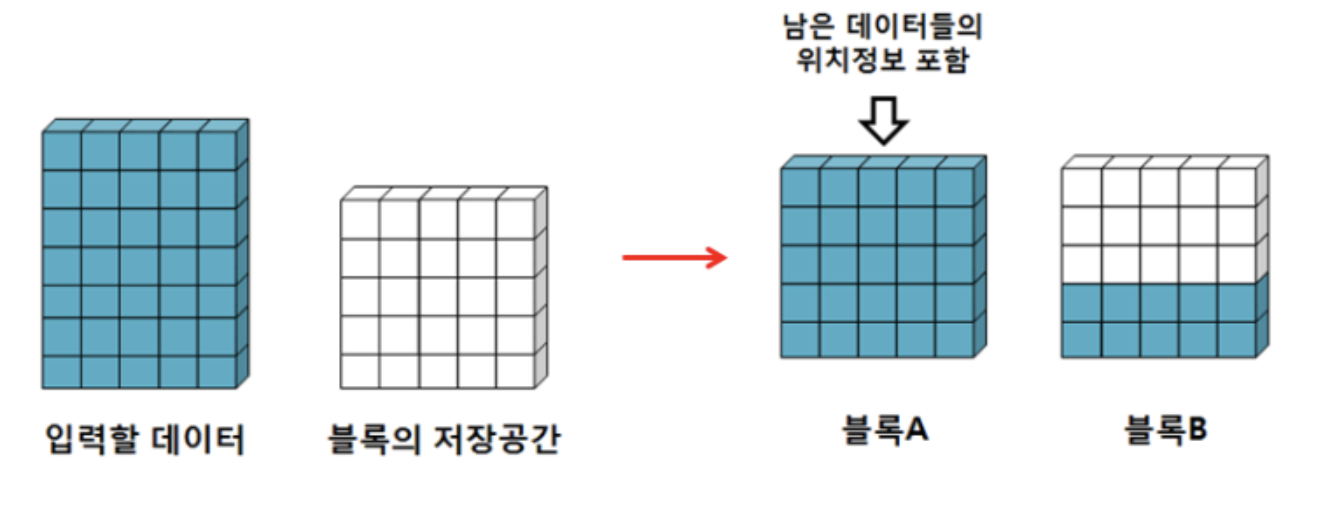
Row Chaining은 데이터 블록의 저장공간이 부족해서 생기는 점은 Row Migration과 같지만 발생원인이 다르다. Row Migration은 이미 저장된 데이터에 대해 UPDATE시 공간부족에 따른 문제 발생이라면, Row Chaining은 애초에 저장을 할 때 공간이 부족해 발생하는 문제이다.
에를 들어, 8K 데이터 블록에 12K 데이터가 들어가면 8K + 4K로 나누어 저장하는 것이다. 이전에서 봤던 것과 마찬가지로 동일한 데이터를 읽어올 때 1개가 아닌 2개 이상의 블록에서 데이터를 읽어 확인해야 하므로 이 현상이 많이 발생하면 성능이 떨어질 수 밖에 없다.
오라클이 자동으로 처리해주기 때문에 크게 신경쓰지 않아도 되는 문제이지만 시스템 내부적으로는 데이터 블록 하나를 읽기 위해 각종 락, 트랜잭션, 버퍼캐시 등과 관련하여 많은 처리가 이루어지므로 당연히 시스템 부하를 줄여주는 것이 좋다.
