
이진트리
이진 탐색 트리(Binary Search Tree, BST)는 이진탐색과 연결리스트(Linked List)를 결합한 자료구조이다.
이진탐색
장점: 탐색에 소요되는 시간복잡도는 O(log n)으로 빠름
연결리스트
장점: 자료 입력, 삭제에 필요한 시간복잡도는 O(1)로 빠름
단점: 탐색하는데 O(n)의 시간복잡도를 가짐
이진 탐색 트리는 이 둘의 장점을 합쳐보고자 만들어진 자료구조이다.
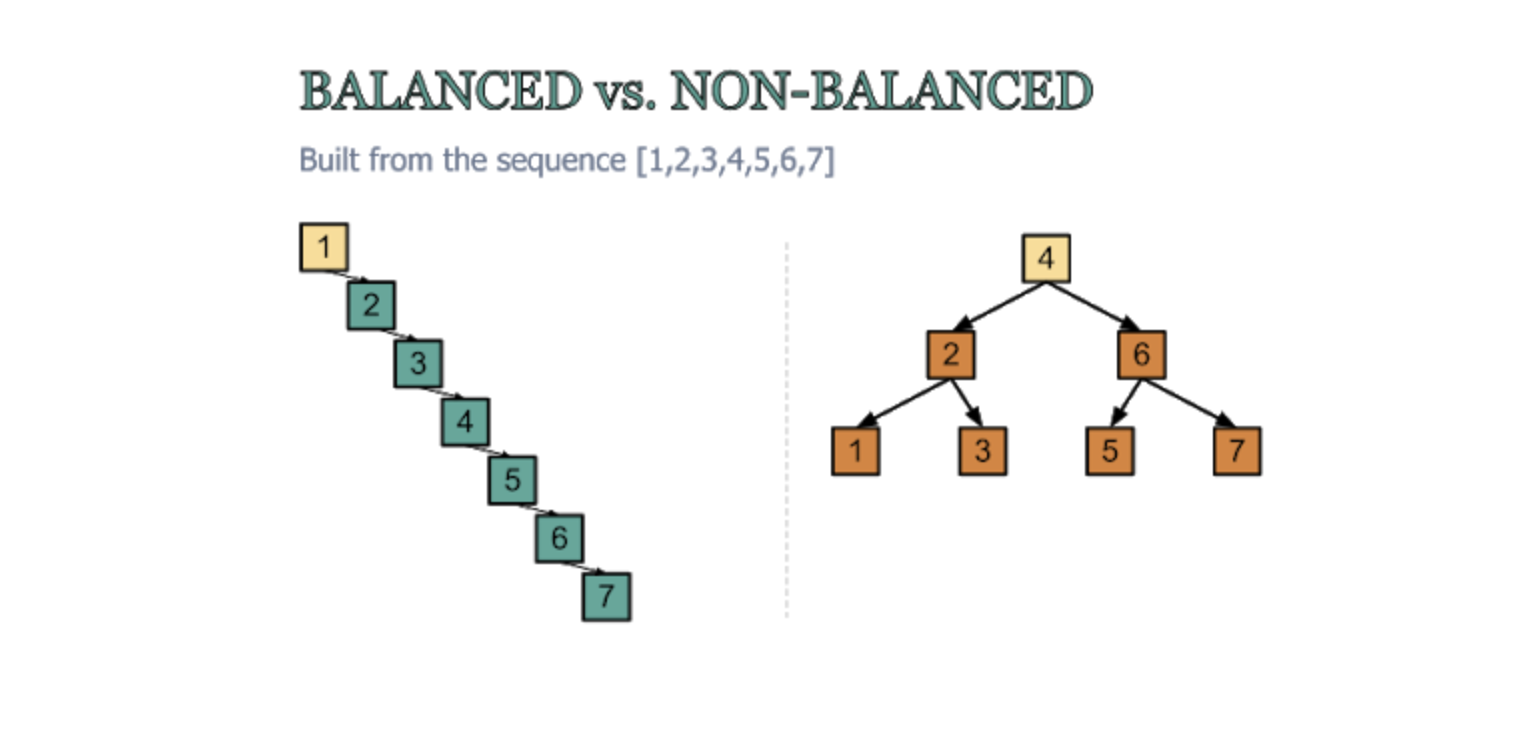
하지만 오른쪽 그림과 같이 균형이 잡힌 이진 탐색 트리의 경우 시간복잡도가 이진탐색의 시간복잡도인 O(log n)이 되지만 왼쪽 그림과 같이 균형이 잡히지 않은 이진 탐색의 경우 O(n)에 수렴하게 되면서 이진탐색의 장점을 가지기 어려웠다.
그래서 이를 해결하기 위한 자료구조가 탄생했고 그중 B-Tree와 B+Tree가 있다.
B-Tree와 B+Tree을 살펴보기 전에 가장 먼저 인덱스에 대해서 알아보자.
인덱스란 ?
인덱스(Index)는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다. 테이블의 특정 컬럼(Column)에 인덱스를 생성하면 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다. 컬럼의 값과 물리적 주소를 (key, value)의 한 쌍으로 저장한다.
인덱스는 쉽게 말해 책에서의 목차 혹은 색인이라고 생각하면 된다. 책에서 원하는 내용을 찾을 때 목차나 색인을 이용하면 훨씬 빠르게 찾을 수 있는데 마찬가지로 테이블에서 원하는 데이터를 찾기 위해 인덱스를 이용하면 빠르게 찾을 수 있다. 그러므로 데이터 = 책의 내용, 인덱스 = 책의 목차, 물리적 주소 = 책의 페이지 번호라고 생각하면 된다.
Index는 데이터의 검색속도를 향상시키기 위한 자료구조이며 데이터의 검색속도를 빠르게 도와준다. 자료를 조회하는 SELECT 외에도 UPDATE, DELETE 등 자료 색인이 선행되는 연산에서도 성능에 도움을 준다.
인덱스 자료구조 추가에 따른 추가 연산
INSERT: 새로운 데이터에 대한 인덱스를 추가한다.DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행한다.UPDATE: 기존의 인덱스를 사용하지 않음 처리하고 갱신된 데이터에 대해 인덱스를 추가한다.
인덱스의 장점과 단점
장점
인덱스의 장점으로는 단연 테이블을 검색하는 속도와 성능이 향상된다. 또 그에 따라 시스템의 전반적인 부하를 줄일 수 있다. 핵심은 인덱스에 의해 데이터들이 정렬된 형태를 갖는다는 것이다. 기존엔 WHERE 문으로 특정 조건의 데이터를 찾기 위해서 테이블의 전체를 조건과 비교해야 하는 Full Table Scan 작업이 필요했는데 인덱스를 이용하면 데이터들이 정렬되어 있기 때문에 조건에 맞는 데이터를 빠르게 찾을 수 있다. 또 ORDER BY 문이나 MIN/MAX 같은 경우도 이미 정렬이 되어 있기 때문에 빠르게 수행할 수 있다.
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
단점
- 인덱스를 관리하기 위해 DB의 추가 저장공간이 필요하다.
- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용하는 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
Index로 인한 성능저하
CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 사용하게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다. 그러한 이유 중 하나는 DELETE, UPDATE 연산 때문이다. 왜냐하면 UPDATE, DELETE는 기존의 인덱스를 삭제하지 않고 '사용하지 않음'처리를 한다. 그래서 UPDATE, DELETE가 빈번하게 발생하면 실제 데이터보다 인덱스가 더 커질 수 있다. 이렇게 비대해진 인덱스를 처리한다면 기존보다 더 성능이 떨어질 수 있다.
Index를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
인덱스의 자료구조
해시테이블
- 시간복잡도: O(1)
- 하지만 해시는 제한적이며 등호(=) 연산에 특화되어 있다. 1이라도 값이 다르면 다른 해시값을 생성하기 때문에 >, < 연산이 자주 사용되는 DB 검색에 해시테이블은 적합하지 않다.
B-Tree
- 리프 노드, 브랜치 노드 모두 데이터 저장 가능
- 풀 스캔 시 모든 노드를 탐색
- 자주 access 되는 노드를 루트 노드 가까이 배치할 수 있고, 루트 노드에서 가까울 경우 브랜치 노드에도 데이터가 존재하기 때문에 검색 속도가 빠르다.
B+Tree
- 시간복잡도: O(log n)
- 데이터 검색 시에 모든 노드의 데이터를 순회하는 B-Tree와 달리 리프에만 데이터를 가지고 있고 나머지 노드는 인덱스만 갖는다.
- 무조건 리프까지 도달해야 하며 리프 노드에 모든 데이터가 있기 때문에 키 중복이 있을 수 있다.
- leaf 노드 간 연결리스트로 연결되어 있어 순차검색이 용이하다.
