[EFK 구축] kubernetes의 cluster-level logging 아키텍처 알아보기

1 Logging Architecture
EFK를 적용하기에 앞서 먼저 kubernetes의 cluster-level logging 아키텍처를 이해하는 것이 중요하다.
우리가 EFK를 사용하는 이유는 컨테이너 런타임에서 제공하는 기본 기능으로 로그를 저장하고 분석 및 조회하기가 어렵기 때문이다. 예를 들어 컨테이너가 죽거나, 파드가 노드에서 퇴출 당하거나, 노드가 죽었을 경우에도 애플리케이션의 로그를 보고 싶지만 컨테이너 런타임에서 제공하는 기본 기능으로 이러한 요구사항을 완벽히 충족시키긴 어렵다. 컨테이너의 로그는 현재 실행 중인 컨테이너와 이전 컨테이너의 로그만 보관하고 있기 때문에 예전 컨테이너의 로그를 별도의 장치 없이 볼 수 없다.
또한 쿠버네티스를 사용하면 애플리케이션 파드의 복제본 수를 설정해 요청을 로드 밸런싱 할 수 있다. 애플리케이션 파드가 HTTP API 서버일 때 클라이언트의 요청으로 INTERNAL SERVER ERROR가 발생했을 때 원인을 파악하기 위한 로그가 필요하다. 로드 밸런싱을 사용 중이라면 클라이언트의 요청이 여러 파드로 분산된다. 따라서 디버깅을 위해 모든 파드의 로그를 일일이 찾아야 하는 번거로움이 있다. cluster-level logging을 적용하면 중앙화된 로그 저장소에서 쉽게 관련 로그를 조회할 수 있다.
cluster-level logging 솔루션을 적용하면 애플리케이션의 로그는 노드, 파드, 컨테이너와 별개로 독립적인 backend에 저장된다. 추가적으로 backend는 로그를 분석하고 조회하는 기능을 제공한다. Kubernetes는 기본적인 cluster-level logging 솔루션을 제공하지 않지만 여러 종류의 logging 솔루션을 Kubernetes는에 적용할 수 있다. 이번 포스팅에서는 EFK를 logging 솔루션으로 사용해보도록 하자.
2 Pod and container logs
쿠버네티스는 실행 중인 파드에서 각각의 컨테이너로부터 로그를 캡처한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']위 예제는 1초마다 standard output stream으로 텍스트를 쓰는 pod이다.
$ kubectl logs counter
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022쿠버네티스가 캡처한 로그는 kubectl logs 명령어로 볼 수 있다.
2.1 노드가 컨테이너 로그를 다루는 방법
쿠버테니스의 모든 노드에는 Kubelet과 컨테이너 런타임 작동하고 있다. kubelet이 CRI를 통해 컨테이너 런타임에게 명령을 전달하면 컨테이너 런타임이 주어진 위치에 컨테이너 로그를 기록하는 방식으로 작동한다. 컨테이너 런타임은 컨테이너에서 만들어지는 stdout and stderr streams을 처리하고 리다이렉트 한다. 즉 컨테이너에서 생성되는 로그를 캡처해서 지정된 로그 파일에 쓴다. 노드에서 동작 중인 컨테이너의 로그는 노드의 어느 위치에 위치한 로그 파일에 쓰이고 있다.
Kubelet은 기본적으로 컨테이너를 다시 시작하면 종료된 컨테이너 하나를 로그와 함께 보관한다. 만약 파드가 노드에서 퇴출당하면 포함된 모든 컨테이너와 로그가 함께 제거된다. 로그의 생명 주기가 파드와 같기 때문에 파드가 퇴출되면 cluster-level logging이 없으면 더 이상 로그를 보는 것이 불가능하다.
Container Runtime Interface (CRI)
Kubelet과 컨테이너 런타임은 긴밀한 협력 관계를 통해 작동한다. Kubelet이 각 노드의 컨테이너 런타임을 관리하는 역할을 하기 때문이다. 그런데 컨테이너 런타임에는 여러 가지 종류가 존재하는데 Kubelet은 어떻게 서로 다른 컨테이너 런타임과 협력할 수 있을까? 이유는 Kubelet과 컨테이너 런타임 사이의 표준 프로토콜 CRI가 존재한다. 따라서 CRI를 만족시키는 컨테이너 런타임들은 교체해도 Kubelet은 무리 없이 협력이 가능하다.
2.2 Log Rotation
- 파드를 계속해서 실행하게 되면 로그 파일에 쌓이는 로그의 양이 많아질 텐데 쿠버네티스는 이를 어떻게 관리할까?
- kubelet의 Log Rotaion 설정을 통해 로그 파일을 일정한 크기로 관리할 수 있다.
- kubelet이 CRI를 통해 컨테이너 런타임에게 명령을 전달하면 컨테이너 런타임이 주어진 위치에 컨테이너 로그를 기록하는 방식으로 작동한다.
- kubelet의
containerLogMaxSize,containerLogMaxFiles설정해서 로그 파일을 관리한다.
-containerLogMaxSize: 로그 파일 하나의 최대 크기(Default: "10Mi")
-containerLogMaxFiles: 컨테이너 하나가 가질 수 있는 최대 로그 파일의 개수(Default: 5) - kubelet의 Log Rotation을 직접 설정하고 싶다면 configuration settings, kubelet configuration file를 참고한다.
3 Cluster-level logging architectures
3가지 방식으로 아키텍처를 구성할 수 있다.
1. 모든 노드에 logging agent를 놓는 방식
2. logging을 위한 사이드카 컨테이너를 pod에 포함시키는 방식
3. 애플리케이션에서 logging backend로 직접 로그를 전송하는 방식
3.1 모든 노드에 logging agent를 놓는 방식
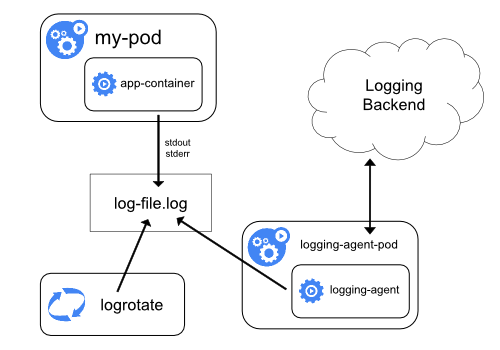
- logging agent를 각각의 노드에 하나씩 배치시키는 방법이다.
- logging agent가 로그를 logging backend로 보내는 역할을 한다.
- 일반적으로 logging agent는 해당 노드에서 작동하는 모든 컨테이너의 로그 파일에 직접 접근이 가능하다.
- 노드 당 하나의 logging agent가 필요하기 때문에
DaemonSet을 이용해 agent를 배포하는 것이 좋다. - Containers가 생성하는 로그의 포맷은 통일성이 없기 때문에 logging agent이를 파싱해서 logging backend 기능이 추가적으로 필요할 수 있다.
3.2 logging을 위한 사이드카 컨테이너를 pod에 포함시키는 방식
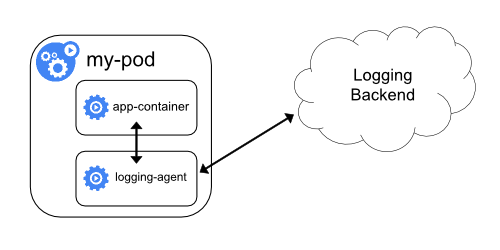
- 만약 노드 레벨의 logging agent가 적합하지 않은 상황이라면 파드에 사이드카로 logging agent를 추가할 수 있다.
- logging agent를 사이드카로 사용하는 것은 엄청난 양의 리소스를 소비할 수 있으니 주의하자.
3.3 애플리케이션에서 logging backend로 직접 로그를 전송하는 방식
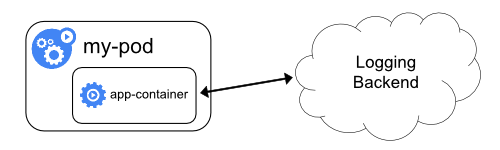
- 애플리케이션 컨테이너가 직접 logging backend로 로그를 전달하는 방식
4 EFK의 아키텍처
logging agent를 사이드카로 사용하는 것은 엄청난 양의 리소스를 소비할 수 있으니 우선적으로 모든 노드에 logging agent를 놓는 아키텍처로 진행한다. 즉 모든 노드에 하나씩 logging agent(Fluent Bit)을 배치하고 logging backend(ElasticSearch)로 로그를 전달하는 방식으로 EFK를 구축해 보자.
참고
