
语法
어법이라고 쓰겠다. 단어의 구성 방식, 단어 간의 관계를 보여주는데 사용된다. 어법은 유효한 프로그램을 구성하는 문자 시퀀스를 설명한다고 보면 된다. C에서 x=y+z는 유효한 기호 시퀀스이고 xy+는 아닌것도 이 어법 덕분이다.
근데 어법만으론 부족하다. x=2.45+3.67가 있다면 어법은 x가 이미 선언되었던 변순지 아니면 실수로 선언된건지 알려줄 방법이 없다. 어법 구조 뿐만 아니라 语义도 있어야 순서 제어, 조작 등이 설명 될 수 있다.
어법의 규칙
易读性
프로그램이 나타내는 알고리즘과 데이터 구조가 읽었을때 쉽게 이해되는지의 여부다. 자연스러운 어구 형식, 구조화된 어구, 내장형 주석 메커니즘, 긴 식별자 제한 등이 가독성을 높이는데 용이하다.
가독성이 좋으려면 또한 서로 다른 어법은 다른 语义를 가져야 하고, 비슷한 일을 하는 프로그램의 구조는 비슷해야 한다.
易写性
어법 규칙이 억제되면 프로그램이 더 짧고 쓰기 쉽지만 읽기 쉽지 않고, 어법에 중복성이 많으면 읽기는 쉽지만 쓰기 쉽지 않다. 중복성이 많다는것은 같은 정보를 전달하는데 여러가지 방식이 있다는 뜻이다.
易验证性
수학적으로 프로그램이 정확하단걸 증명할 수 있어야 한다.
易翻译性
실행 가능한 형식으로 번역/컴파일되기 쉬워얗나다. 읽기 쉽고 쓰기 쉬운건 프로그래머 기준이지, 컴퓨터 기준에서 필요한 기준이 이거다. LISP 프로그램을 예로 들면 읽고 쓰기 어렵지만 어법이 간단하고 규칙적이어서 번역하기 쉽다.
无歧义性
언어의 정의는 각 문법 구조에 고유한 의미를 부여해야 하는데, 含混性结构는 2개 혹은 그 이상의 다른 해석을 허용한다. Fortran에서 A(I, J)는 배열 원소일수도 있고, 함수 호출일수도 잇는게 예시다.
또 다른 예시를 보자.
If Boolean exp1 then if Boolean exp2 then stat1 else stat2
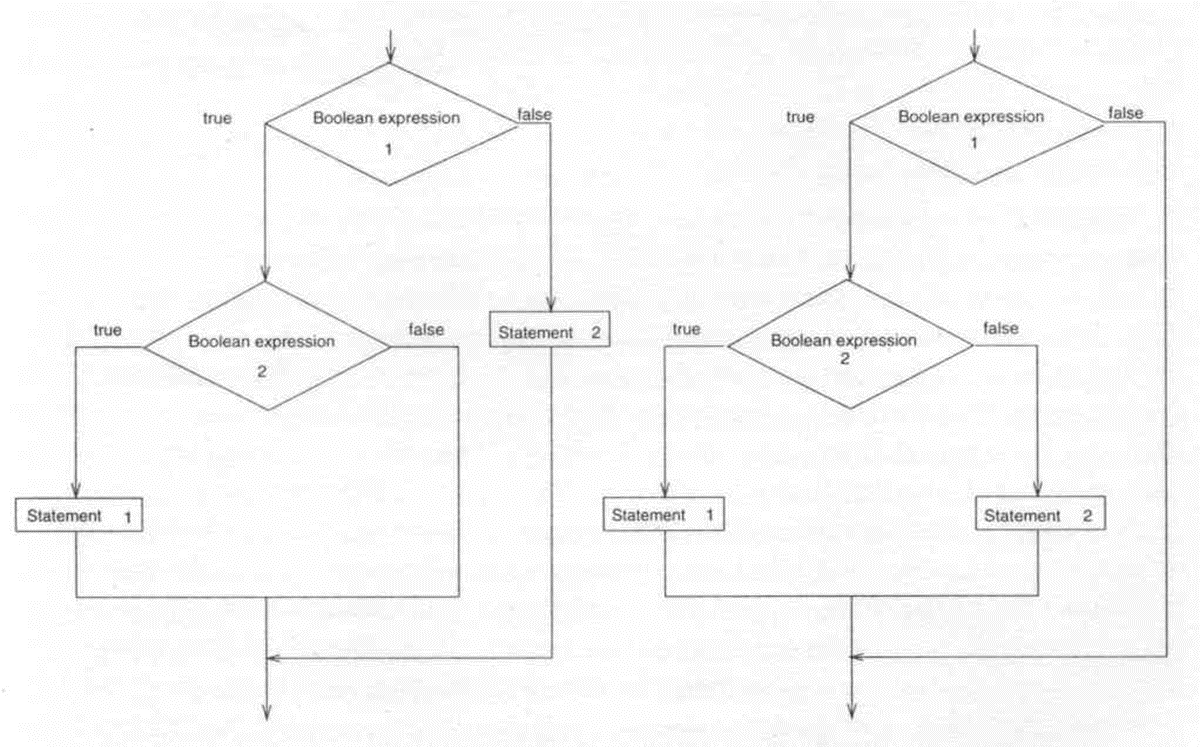
위의 코드에 대한 두개의 해석을 플로우차트로 나타낸 모습이다. 이를 해결키 위해선 마지막 else를 가장 가까운 then과 쌍을 이루거나, endif 경계자로 각 if를 끝나개 하던가 조치를 둬야 한다. 이렇게 歧义性을 해결할 수 있다.
어법의 요소
언어의 어법 스타일은 여러 원소에 의해 결정되는데, 이는 문자 집합, 식별자, 연산자 기호, 키워드/예약어 등이 포함된다.
공백
일반적으로 공백은 구분자 (分隔符)로 자주 사용된다. 빈칸이 다른 용도로 쓰이는 언어도 있다.
구분 기호, 괄호
어법 단위의 시작과 끝을 표시한다, {}처럼.
표현식
프로그램의 데이터 객체에 액세스하고 값을 반환하는 기본 블록이다. 명령형 언어에서 표현식은 기본 조작을 형성하고, 상태가 문에 의해 변경된다. 작용형 언어에서 표현식은 프로그램의 기본 순서 제어를 결정한다.
语句
명령식 언어에서 가장 주요한 어법 부품이다. 문장의 어법은 언어 전체의 정규성, 가독성과 易写性에 모두 영향을 미친다.
文法
어법의 형식 정의를 문법이라고 한다. 문법은 하나의 규칙 집합으로 구성되며, 이 규칙은 产生式라고 하며 프로그램이 될 수 있는 문자열을 정해둔다.
BNF 문법(上下无关文法)
어법만으로 프로그램에 의미가 있을 순 없다. 语义를 고려하지 않고서, 언어는 그저 고정된 기호 집합에서 선택된 제한된 문자열의 집합일 뿐이다. BNF 문법은 언어의 문자열이 무엇인지 정확하게 결정하는 수학 규칙 집합을 제공한다.
<digit>:=0|1|2|3…8|9으로 비종결자, 종결자를 합쳐 제한된 언어의 모든 요소를 나열할 수 있다. 더 복잡하게 나아가면,
<conditional statement>::=
if <Boolean exp> then <statement> else <statement> | if <Boolean exp> then <statement>식으로 조건문도 정의할 수 있다. 또한 재귀적으로 비종결자 스스로가 규칙에 사용될 수도 있다:
<unsigned integer>::= <digit> | <unsigned integer><digit>처럼.
어법 분석 트리
어법이 주어졌을때, 替换规则로 串을 만들 수 있다. 문자열이 문법에 의해 정의된 언어에 의해 규정된 문법적 자격을 갖춘 프로그램인지 확인하기 위해서, 반드시 문법 규칙을 사용하여 이 문자열의 문법 분석 트리를 구성해야 한다. 분석에 성공하면 이 언어의 프로그램인 것이다.
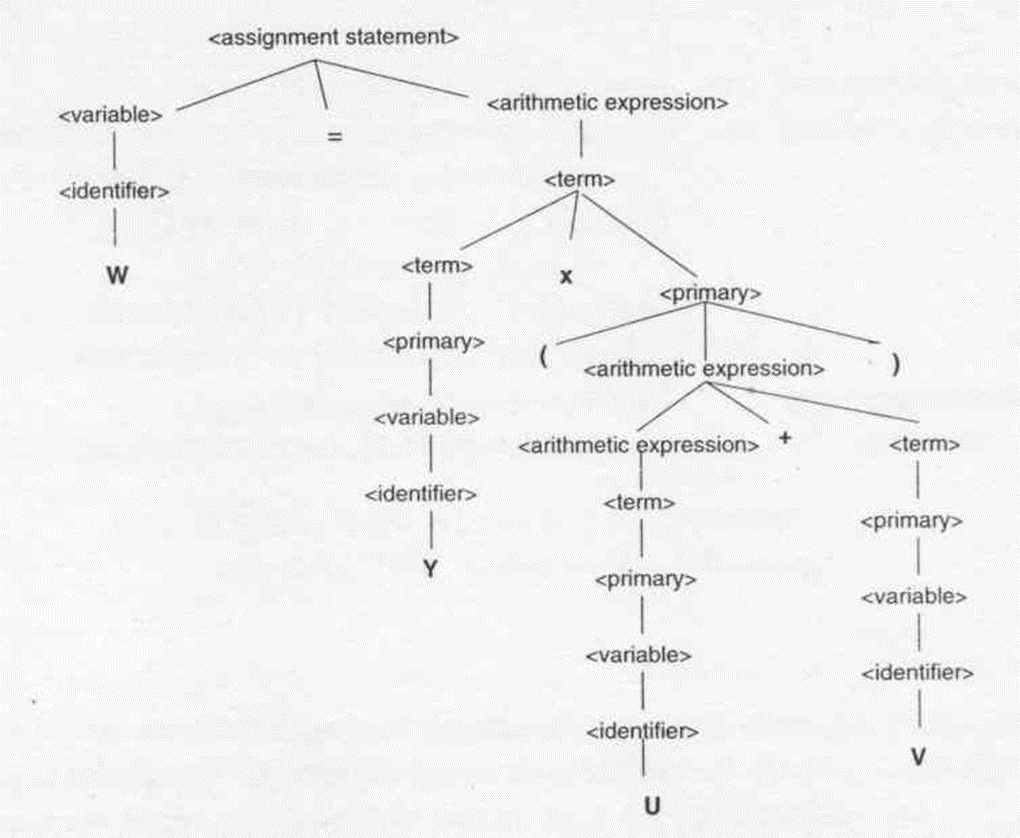
위는 의 어법 분석 트리다.
句型, 句子, 语言
起始符에서 추론된 字符串이 바로 句型이 된다. 句子는 서로 다른 替换操作를 통해 起始符에서 추론된, 终结符로 구성된 字符串이고 최종적으로 문법 G가 만드는 언어 는 모든 起始符에서 추론되어 终结符로 이루어진 句子들의 집합이다. 언어는 결국 终结符가 포함된 句型들의 집합인 것이다.
推导
위에서 말한 추론 과정이다.
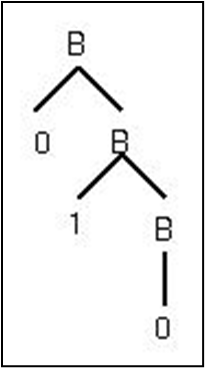
위를 보자. 문법이 B -> 0B | 1B | 0 | 1이라면 B -> 0B -> 01B -> 010을 추론해낼 수 있고, 위와 같은 분석 트리를 얻을 수 있다.
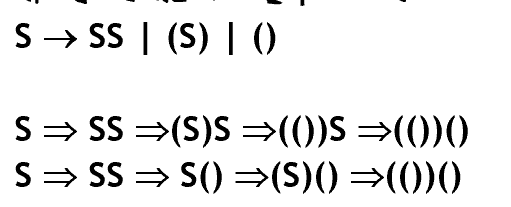
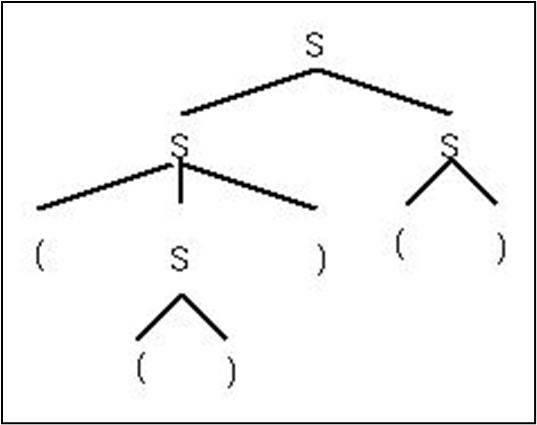
하지만 위를 보자. 같은 분석 트리가 나와도 추론이 유일하지 않을 수 있다.
문법의 歧义性
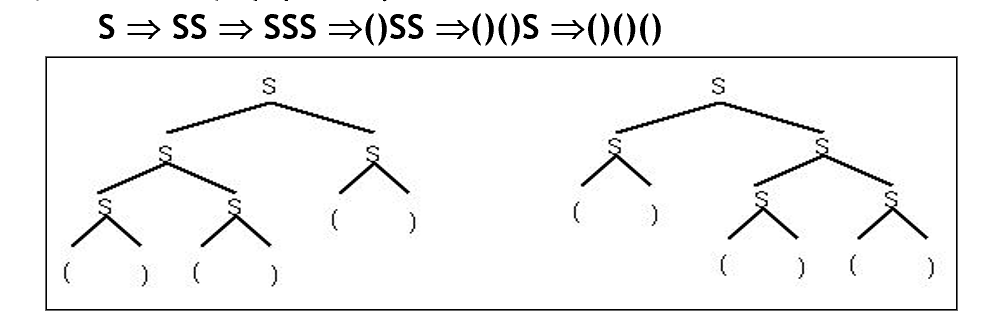
같은 字符串에 대해, 같은 문법 중에서 두가지 다른 분석 트리가 있다면 해당 문법은 歧义하다고 한다. 위같은 경우가 바로 그런 경우다. 无歧义해야만 제대로 语义를 이해할 수 있다.
엡실론 생성 규칙, 유한 상태 오토마타
길이가 0인 문자열이 표현 및 쓰이는 방법을 보자. 위와 같은 엡실론 생성식은 엡실론을 포함해, S가 빈 문자열을 생성 할 수 있음을 나타낸다.
밑의 FSA는 Finite State Automata를 뜻하고, 람다 이동(또는 엡실론 이동)은 입력 없이도 상태 전환이 가능하다는 것을 의미한다. 즉, 입력 문자열의 길이가 0일 때도 상태 변화가 일어날 수 있다.
연산의 우선순위
2 * 3 + 4 * 5라는 식은, 우리가 아는 개념대로면 6+20=26이어야 한다.

하지만 결과가 70, 50이 나오는 문법이 있을 수 있다. 모두 같은 언어를 생성하지만 语义가 달라지는 것이다.
语法图
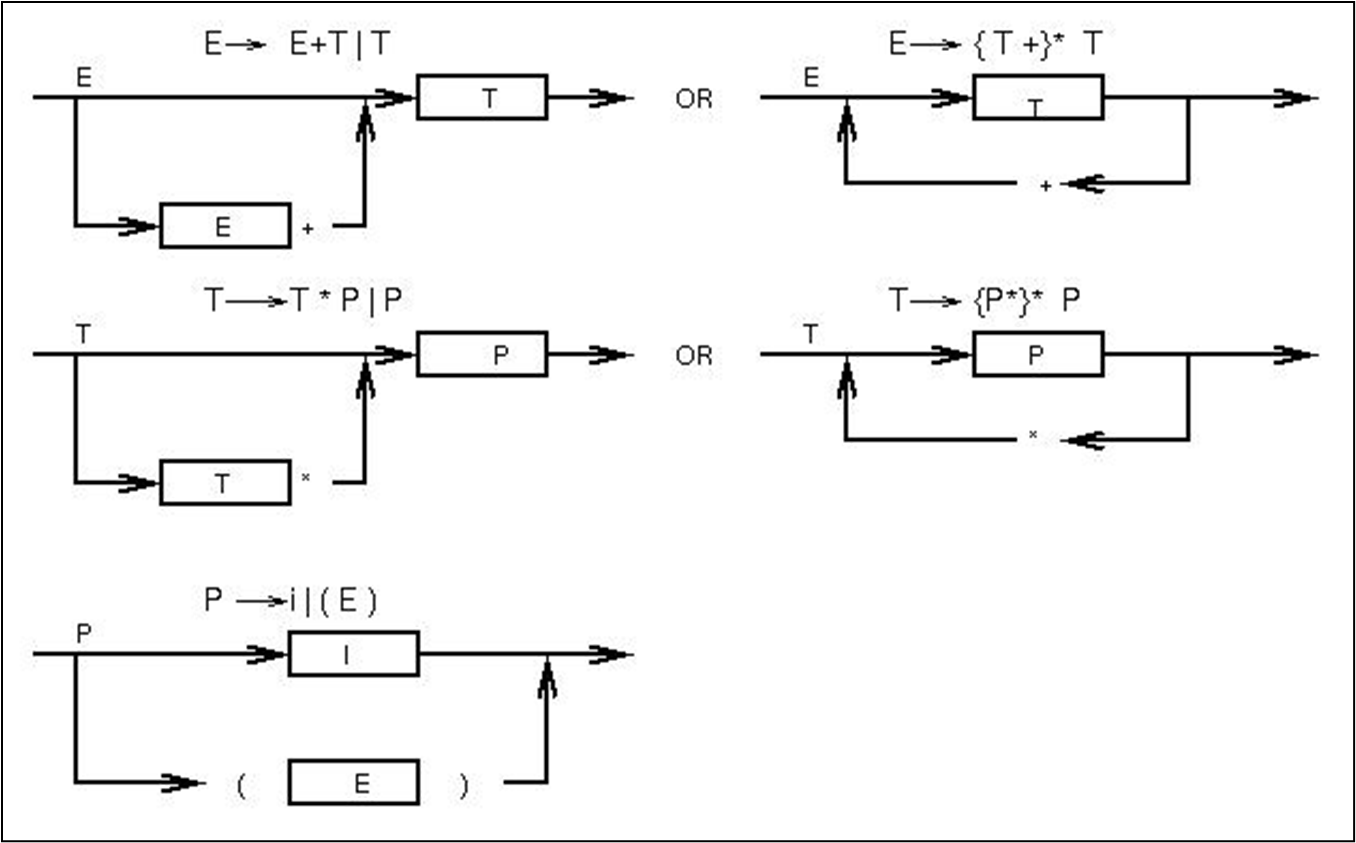
확장 BNF 언어를 편하게 보여주는 그림이다.
문법의 분류
BNF 형식은 문맥과 무관하고, 2형 문법이라 한다.
正则文法는 BNF 문법의 부분집합이고, 3형 문법이라 한다. BNF 규칙에 제한을 두어 이진수나 식별자를 표현하는데 사용된다.
유한 상태 자동기계 (FSA)
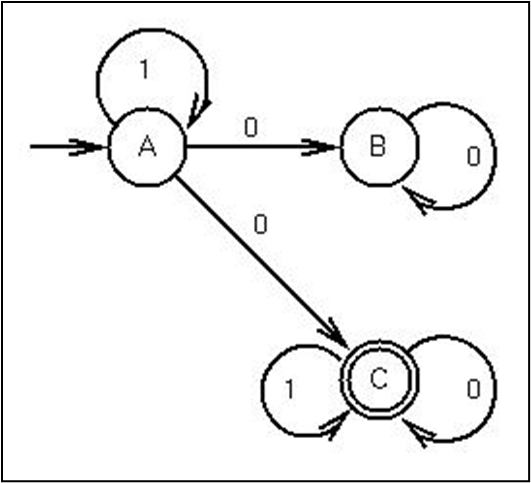
언어는 토큰으로 구성되어있고, 토큰의 구조는 간단하다. FSA는 이를 인식하는데 효과적이고, 방향성 그래프로써 终止,非终止상태의 두개의 노드 종류와 고유한 시작 상태를 나타낸다. 어떤 문자열이 시작상태에서 종료 상태로 이동할 수 있는지를 나타낸다. 두줄 동그라미가 최종상태를 나타낸다.
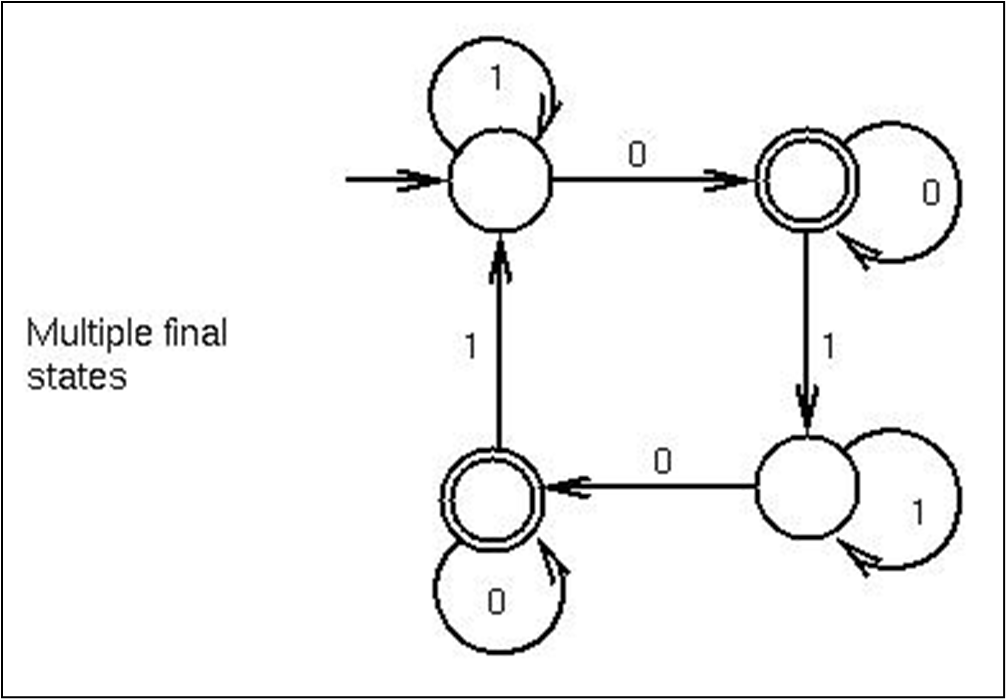
위는 여러개의 final stages를 가진 FSA의 예제다.
확정형, 비확정형 FSA (FSA, NDFSA)
각 상태와 심폴 테이블에 대해 단 하나의 전환만 존재하는 FSA가 확정형이고, 비확정형은 같은 조건에서 여러 전환을 허용한다.
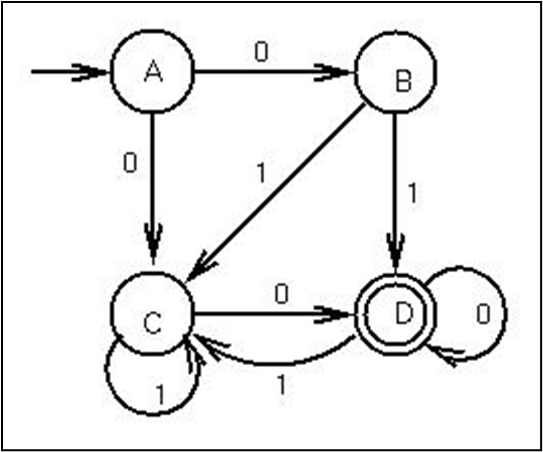
위는 비확정형의 예시인데, 위에서 문자열 01은 ABD 경로를 통해 수용 가능하지만, ACC나 ABC로는 C가 최종 상태가 아니기에 수용 불가능하다.
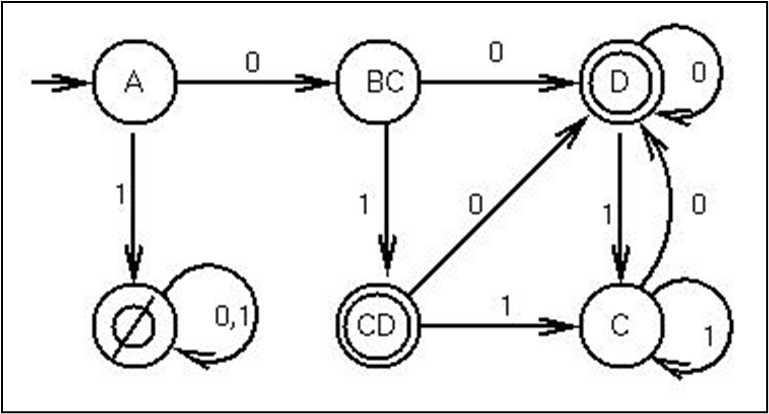
NDFSA의 상태의 부분집합을 DFSA의 상태로 사용할 수 있다. 위 사진에서의 A에서 D로 혹은 CD로 가는 경로는 원래 NDFSA (첫 사진)의 A에서 D로 가는 경로를 나타낸다.
정규표현식과 FSA
정규언어를 표현식으로 쓸 수 있다.
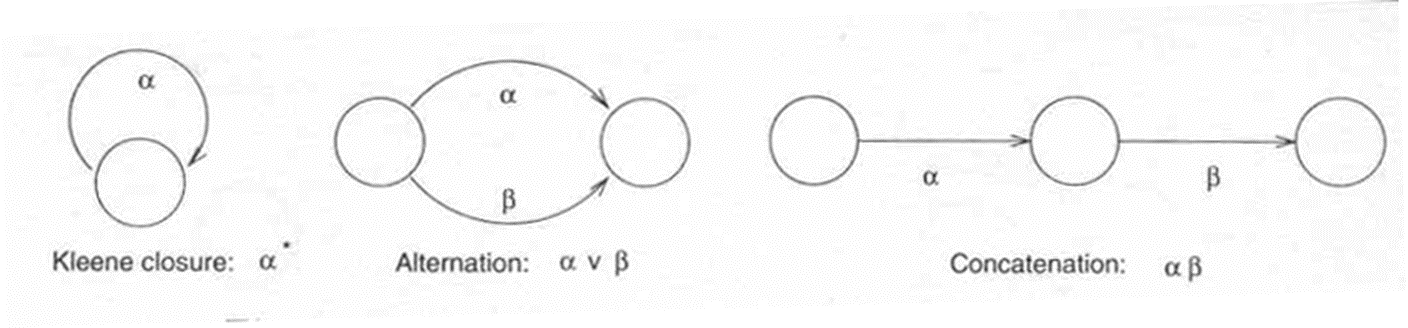
위의 방식으로 FSA를 표현할 수 있다.
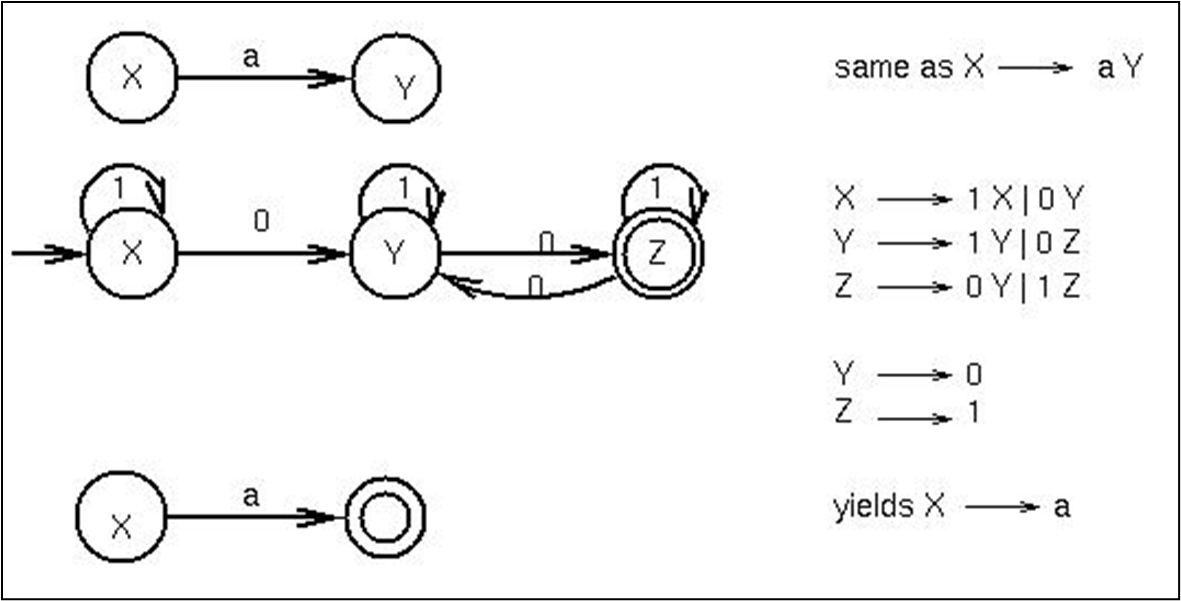
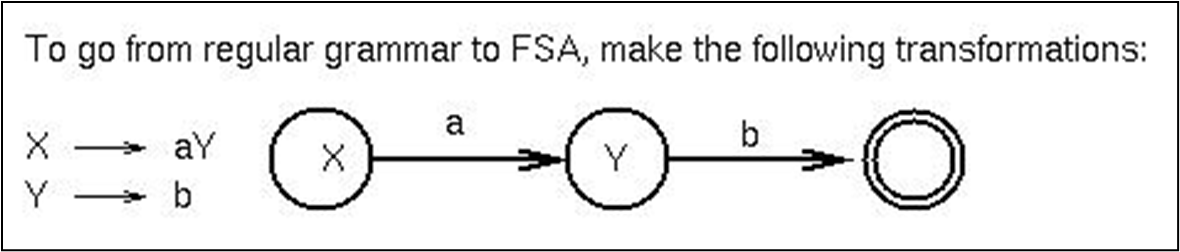
정규 문법의 생성 규칙은X → aY 또는 X → a중 하나를 따르고, 정규 문법으로 정의된 언어는 FSA가 수용하는 언어와 등가하다. 위처럼 전환 가능하다.
하향식 자동기계 (PDA, 下推自动机)
FSA와 유사한 추상 모델이다. 유한한 상태 집합과 하향식 스택을 가진다. PDA는 입력 심볼과 스택의 최상위 심볼을 같이 읽고, 읽은 두 심볼에 따라 새 상태로 전환하고 스택에 0개 이상의 심볼을 쓴다. 스택이 비어있다면 입력 문자열을 수용하는데, 이는 즉 종료 상태에 도달한 것이다.
BNF가 주어졌을 때 PDA는 문자열의 最左推导를 생성 할 수 있다. 스택 최상단이 终结符이면 다음 입력과 비교하고, 같다면 스택 최상단 심볼을 꺼내고, 아니라면 에러를 뿜는다.
스택 최상단이 非终结符 X라면 X의 产生式 X->a를 사용해 a로 스택 최상단 X를 대체한다.
확정, 비확정형 PDA

위 예시를 보자. 회문 문법이다. 확정형 PDA로 식별할 떄, 0과 1을 읽으면 스택에 넣고, 2를 읽으면 새로운 상태에 들어간다. 이후 스택 탑과 새로 입력한 글자를 비교하고, 스택 위의 원소를 빼낸다.

하지만 회문이 이런 식이라면 회문의 중간 지점이 어딘지 맞춰야만 하기 때문에 비확정형이 된다.
