서브루틴 호출과 활성 레코드
프로그램은 서브루틴을 단위로 하는 계층 구조로 볼 수 있다. 서브루틴 호출의 제어 메커니즘은 '복사' 규칙으로 설명할 수 있는데, 즉, 서브루틴 호출 문장의 효과는 서브루틴 본문의 복사본으로 호출 문장을 대체하고 (적절하게 매개변수와 충돌하는 식별자를 대체함으로써) 같은 결과를 얻을 수 있다.
이 관점에서 서브루틴 호출은 프로그램의 여러 위치에서 동일하거나 거의 동일한 문장을 복사할 필요가 없는 제어 구조로 볼 수 있다. 그러나 복사 규칙에 따르면, 프로그램 실행 중 어느 시점에서도 한 서브루틴을 동시에 여러 번 호출할 수 없다.
호출의 기본 원리
완전한 프로그램 실행 모델을 먼저 설정해야 한다.
- 서브루틴의 정의와 서브루틴의 활성화: 서브루틴이 호출될 때 활성화되며, 서브루틴의 정의를 기반으로 서브루틴에 실행 환경을 제공한다.
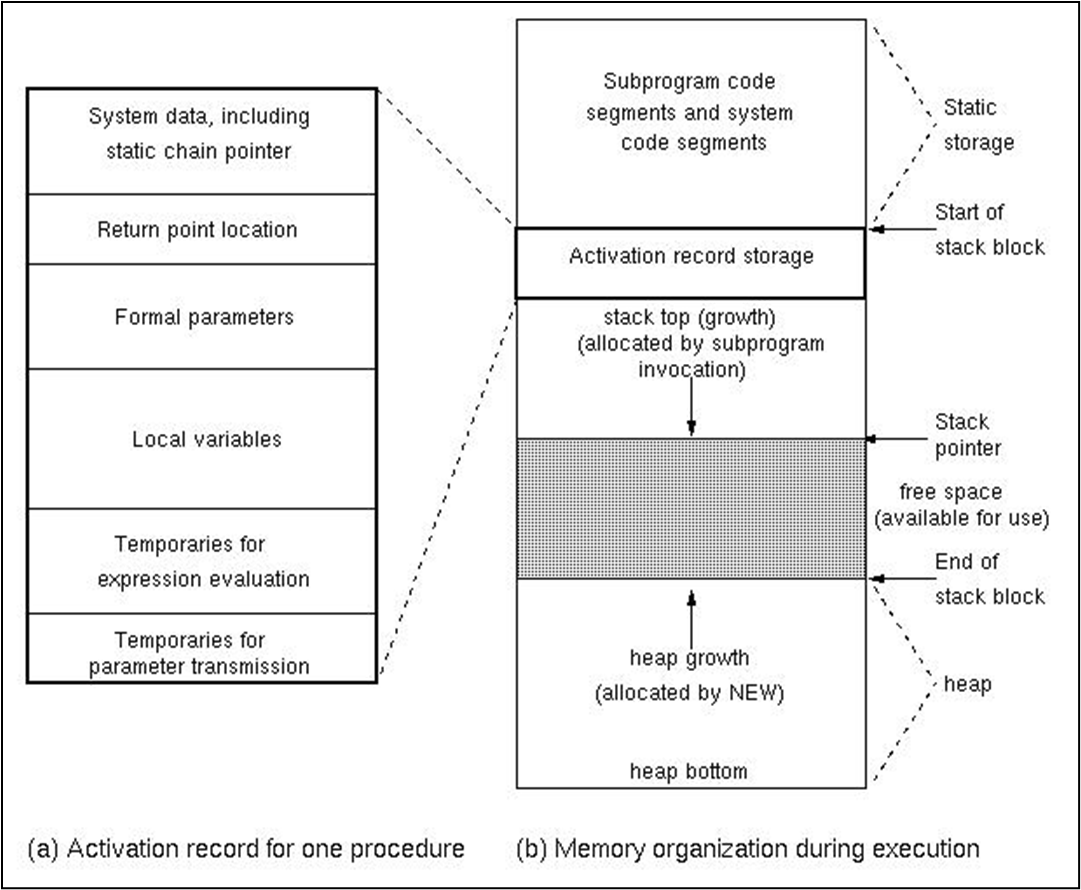
- 활성화는 코드 세그먼트와 활성화 레코드 두 부분으로 실현된다. 코드 세그먼트는 실행 중에 변경되지 않으며, 각 서브루틴 활성화는 동일한 코드 세그먼트를 사용한다. 활성화는 호출시 생성되고 반환시 소멸되며, 활성화 내용은 할당에 따라 자주 변경된다.
일반적으로 특정 서브루틴 문장이 실행된다기보다는 서브루틴의 활성화 레코드 내에서 특정 문장이 실행된다고 말한다.
CIP, CEP
프로그램 실행 지점을 추적하기 위해 두 가지 데이터, 즉 두 시스템 정의 포인터 변수에 대한 저장 공간이 필요하다.
현재 명령어 포인터 CIP는 현재 하드웨어나 소프트웨어 인터프리터가 실행 중인 명령어를 가리킨다.
현재 환경 포인터 CEP는, 동일한 서브루틴의 모든 활성화가 동일한 코드 세그먼트를 사용하기 때문에 현재 명령어만으로는 충분하지 않으며, 서브루틴의 참조 환경을 나타내는 활성화 레코드를 가리키는 포인터(따라서 환경 포인터라고 함)가 필요하기에 존재한다.
일반적으로 호출 시 CIP와 CEP를 호출된 서브루틴의 활성화 레코드에 저장하고, 활성화 레코드에는 시스템 정의 데이터 객체인 반환 지점(두 포인터 값을 저장하는 곳)이 포함된다.
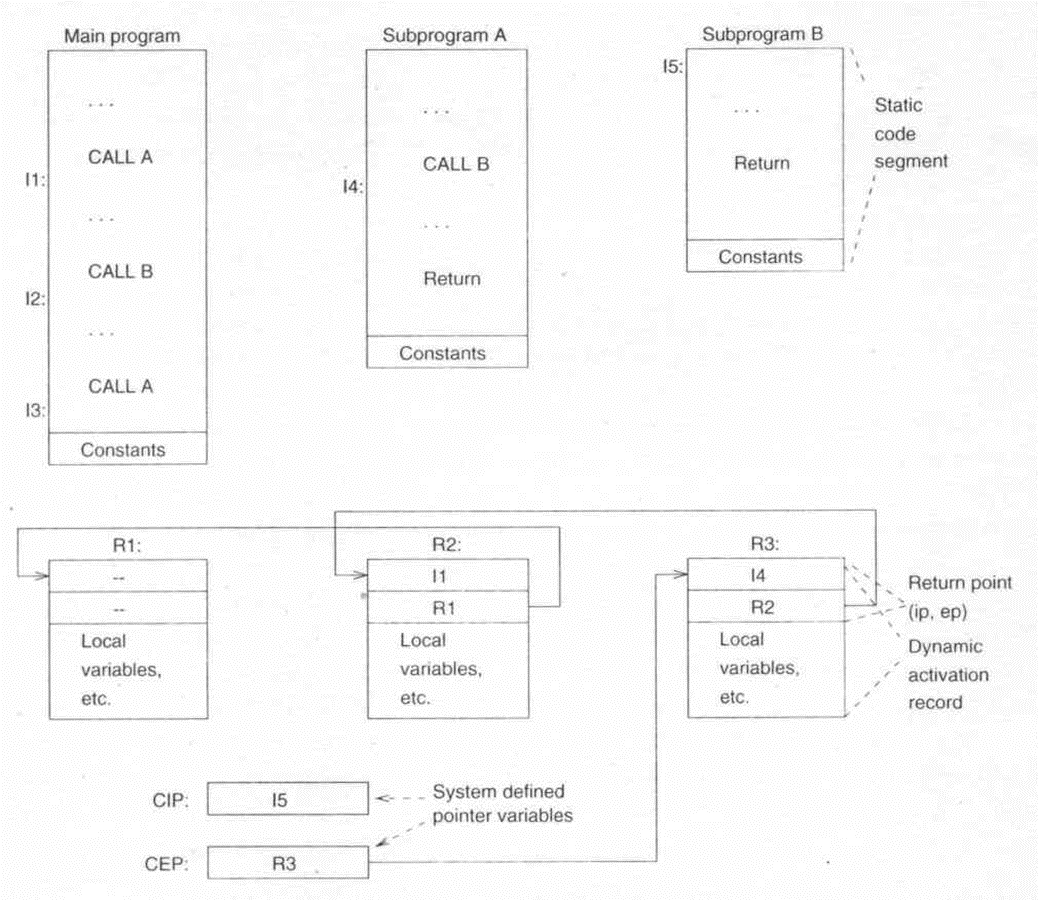
서브루틴 B가 시작될때의 상태다.
call 호출을 만날 때마다, 이전의 (ip, ep)를 활성화 레코드의 반환 지점에 저장하고, 새로운 (ip, ep)를 CIP, CEP에 할당하여 제어를 전환한다.
반환 문장을 만나면, 이전의 (ip, ep)를 가져와 CIP, CEP를 재설정하고 제어권을 반환한다.
서브루틴의 데이터 제어
프로그램을 작성할 때, 실행해야 할 연산과 그 순서는 일반적으로 알고 있지만, 이러한 연산의 피연산자에 대해서는 덜 알고 있다. 예를 들어: X := Y + 2 * Z에는 세개의 연산이 있는데, 연산자는 무엇일까?
2는 명백히 곱셈의 操作数지만, X, Y, Z는 단지 식별자일 뿐이며, 연산자가 아니라 연산자를 지정하는 방식이다. Y는 실수, 정수 또는 매개변수가 없는 서브루틴의 이름일 수도 있고, 프로그래머의 오류로 인해 Y는 실제로 불리언 값, 문자열 또는 문장 레이블일 수도 있다.
그렇다면 현재 Y는 무엇이며, 어디에서 왔는지(또는 어디에서 정의되었는지)는 어케 알까?
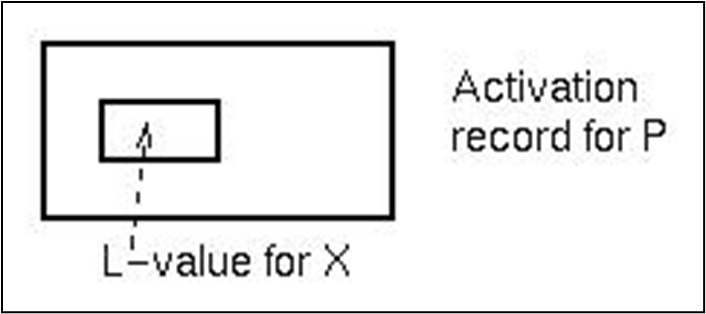
서브루틴의 데이터는 활성화 레코드에 저장된다. X의 L-값은 활성화 레코드의 특정 오프셋이다.
서브루틴 데이터 제어의 목표는 데이터가 있는 서브루틴의 활성화 레코드를 찾는 것이다. 주어진 표현식이 X = Y + Z라면, Y를 포함하는 활성화 레코드를 찾고 활성화 레코드의 고정된 위치에서 Y의 L-값을 얻은 후, Z와 X에 대해서도 동일한 과정을 반복한다.
데이터 제어에서의 문제
데이터 제어의 핵심 문제는 Y가 이러한 할당 문의 각 실행에서 무엇을 의미하는가이다. Y는 지역 또는 비지역 변수일 수 있으며, 이 문제는 선언의 범위 규칙을 알아야한다. (식별자의 사용 범위 및 참조 환경)
식별자와 데이터 객체(또는 서브루틴)의 연관성
데이터 객체를 연산의 피연산자로 사용하는 두 가지 방법은 아래와 같다.
- 직접 전달: 어떤 데이터 객체가 어느 장소의 연산의 계산 결과로서 다른 연산에 직접 피연산자로 전달될 수 있다. 예를 들어 2×Z가 덧셈의 피연산자라면, 이러한 객체에는 이름을 지정할 필요가 없으며, 일시적인 저장소가 할당된다.
- 데이터 객체에 대한 참조에 이름을 부여: 데이터 객체가 생성될 때 이름을 부여할 수 있으며, 이름을 사용하여 연산자로 사용할 수 있다.
关联
데이터 제어는 식별자(단순 변수)를 특정 데이터 객체와 서브루틴에 바인딩하는 것과 관련이 있고, 이러한 바인딩을 关联이라고 하며, (식별자, 데이터/서브루틴)의 쌍으로 표시된다.
대부분의 프로그래밍 언어에서 프로그램 실행 중에 关联의 "생성-사용-제거" 과정이 진행된다.
- 프로그램 실행의 시작점에서 완료된 关联에는 선언된 변수명 → 특정 데이터 객체, 호출된 서브루틴명 → 특정 서브루틴 정의가 포함된다.
- 프로그램 런타임에, 식별자와 관련된 특정 객체 또는 서브루틴을 결정하기 위해 참조 연산을 호출한다. 예를 들어 A := B + FN(C)는 A, B, C, FN에 해당하는 4개의 참조 연산이 필요하다.
- 새로운 서브루틴을 호출할 때, 해당 서브루틴에 대한 关联집합이 생성되며, 이는 로컬 식별자와 연관이 있다.
- 서브루틴이 실행되는동안, 참조 연산을 호출하여 각 식별자의 연관성을 결정한다. 어떤 참조는 서브루틴 내에서 생성된 것을 가리킬 수도 있고, 어떤 것은 주 프로그램 내에서 생성된 것을 가리킬 수도 있다.
- 서브루틴이 제어권을 반환하면, 그 关联은 제거된다.
- 주 프로그램이 제어권을 되찾으면, 계속 실행된다.
참조 환경 (引用环境)
참조 환경은 실행 중에 참조를 위한 식별자 关联의 집합이다. 서브루틴의 참조 환경은 일반적으로 실행 중에 변경되지 않는다. 참조 환경의 구성 요소는 아래와 같다:
- 로컬 참조 환경(局部引用环境): 서브루틴에 진입할 때 생성되며, 매개변수, 지역 변수, 지역 정의 서브루틴을 포함한다.
- 비지역 참조 환경 (非局部引用环境): 특정 서브루틴 내에서 사용되지만, 해당 서브루틴 진입 시 생성되진 않는다.
- 전역 참조 환경(全局引用环境): 메인 프로그램 시작 시 생성되며 모든 서브루틴에서 사용할 수 있다.
- 미리 정의된 참조 환경(预定义引用环境): 어떤 식별자들은 미리 정의된 참조를 가지며, 이는 언어 정의 내에서 직접 지정된다. 어떠한 프로그램이나 서브루틴에서도 직접 사용할 수 있다.
관련 개념
- 가시성(可见性): 특정 서브루틴 내에서 어떤 식별자의 关联이 '가시적'이라고 할 때, 그것은 서브루틴의 참조 환경의 일부다. 关联이 존재하지만 현재 실행 중인 서브루틴의 참조 환경에 포함되지 않는 경우, 그것은 해당 서브루틴에 대해 '숨겨진' 것으로 간주된다. 숨김은 주로 식별자의 재정의로 인해 발생한다.
- 동적 스코프 (动态作用域): 关联의 동적 스코프는 가시한 서브루틴 활성화로 구성된다.
스코프 규칙
식별자의 스코프는, 프로그램 내에서 해당 식별자를 접근(또는 명명)할 수 있는 명령문의 집합을 의미한다.
정적 스코프는 문법에 의해 결정되고, 동적 스코프는 실행에 의해 결정된다.
동적 스코프
식별자 연관의 동적 스코프는 실행 중 关联이 가시적인 서브루틴 활성화의 집합이다.
동적 범위는 반드시 关联이 생성된 서브루틴 활성화를 포함하며, 이는 해당 关联이 그 서브루틴의 지역 환경의 일부이기 때문이다. 또한 다른 프로그램 활성화에서 비지역 연관으로서 가시적일 수도 있다.
동적 스코프의 규칙으로, 프로그램의 실행을 기반으로 각 关联의 동적 스코프를 정의한다. 예를 들어, 특정 동적 스코프 규칙은 서브루틴 P의 활성화에서 생성된 어떤 연관의 범위는 그 활성화를 포함하고, P가 호출하거나 전달 호출한 서브루틴의 활성화도 포함한다고 명시할 수 있다.
정적 스코프
모든 선언이나 식별자의 정의는 일정한 범위가 있으며, 이를 정적 스코프라고 한다. 선언의 정적 스코프는 프로그램 텍스트의 일부로서, 식별자의 사용이 해당 식별자의 특정 선언에 대한 참조로 간주되는 영역이다.
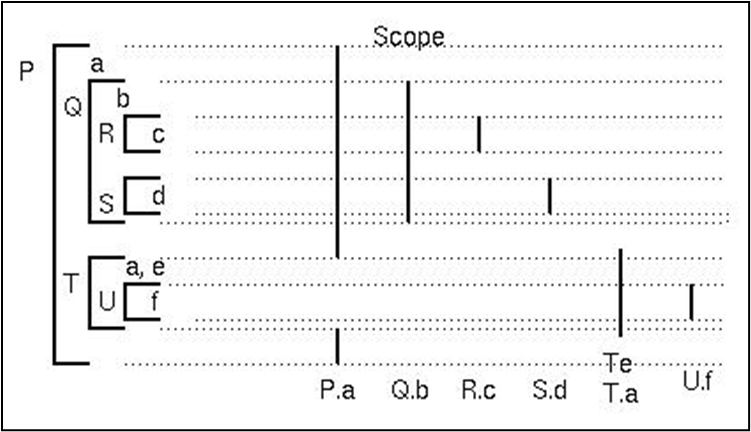
규칙의 예시를 보자.
Q와 T는 P 내부에 선언된 프로시저이므로, Q와 T의 스코프는 a의 스코프와 같다.
R과 S는 Q 내부에 선언된 프로시저다.
U는 T 내부에 선언된 프로시저다.
프로시저가 호출되면, 활성 레코드가 레코드 스택 안에 들어간다.
활성 레코드 스택
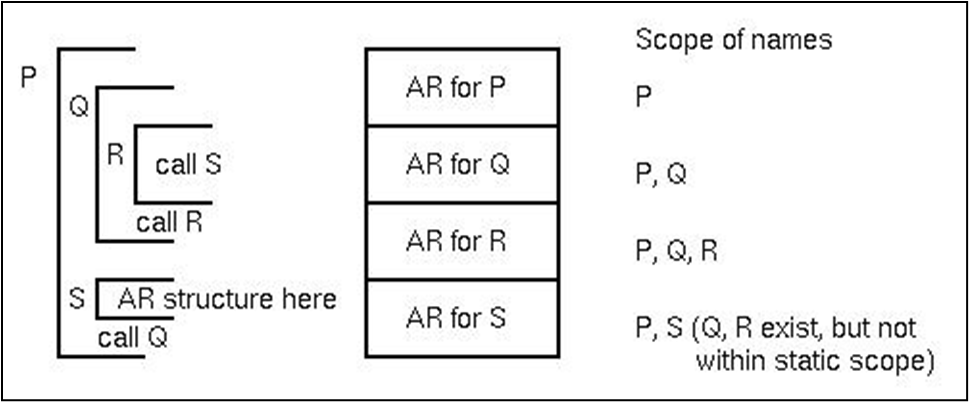
- 동적 체인 포인터 (动态链指针, DL) 는 현재 활성 레코드를 호출한 활성 레코드를 가리킨다. 이는 현재 프로시저에서 호출 프로시저로 반환할 때 사용된다.
- 정적 체인 포인터 (静态链指针, SL)는 현재 활성 레코드의 상위 활성 레코드를 가리킨다. 즉, 현재 프로시저를 포함하는 프로시저의 활성 레코드를 가리킨다.
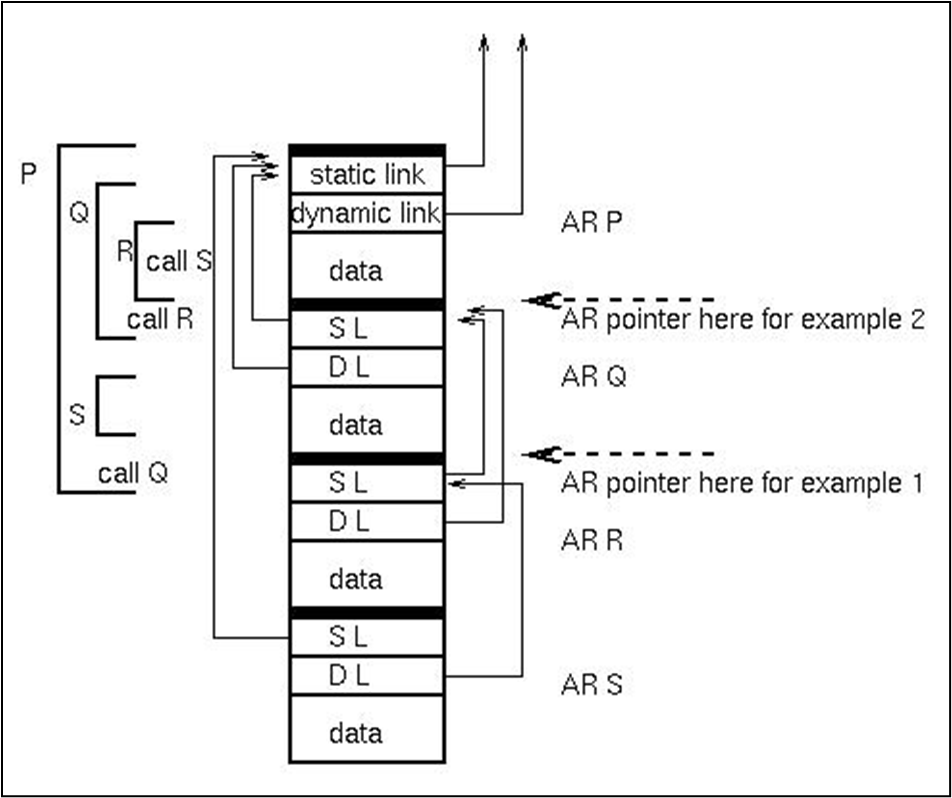
위 그림으로 예시를 보자.
- R: C := B+A에서; C는 지역 변수이고, A와 B는 전역 변수다.
- 각 변수에 대해 올바른 레코드를 가리키는 포인터를 얻는다.
- AR은 현재 활성 레코드의 포인터(R)라고 가정한다.
- B는 상위 레벨의 변수니, AR.SL을 따라 B를 포함하는 AR을 얻는다. 고정된 오프셋 주소 (L-값)에서 B의 R-값을 얻는다.
- A는 두레벨 상위 변수다. AR.SL.SL을 따라 AR을 얻고, 똑같이 A의 값을 얻는다.
- C는 지역 변수니, AR은 현재 활성화 레코드를 가리킨다. B+A의 값을 C의 L값에 저장한다.
예시2:
- Q에서 A:=B 실행, B는 로컬, A는 전역 변수다. AR은 Q의 활성화 레코드를 가르키고 있다.
- B가 로컬 변수니, 로컬 레코드에서 B의 R값을 받아온다.
- A는 상위 계층이니 AR.SL로 P의 레코드를 받아오고, B의 R값을 A에 저장한다.
컴파일러는 프로그램의 정적 구조를 알고 있기 때문에, 지정된 데이터 객체를 포함하는 활성 레코드에 올바르게 접근하기 위해 방문해야 하는 정적 링크의 개수를 생성할 수 있다.
활성 레코드 디스플레이 (激活记录陈列表)
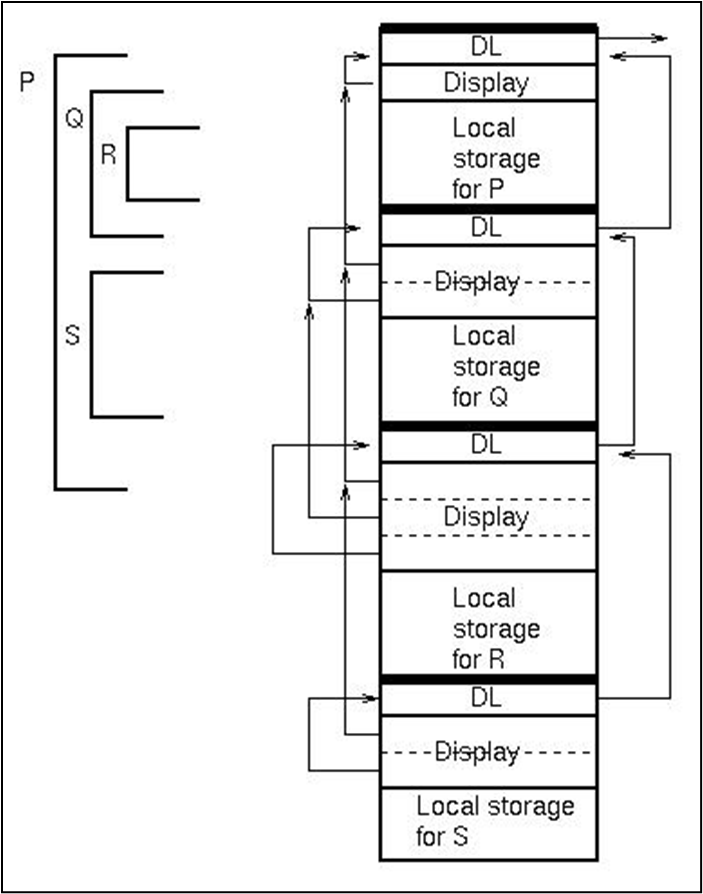
정적 체인의 문제점으로, 만약 중첩의 깊이가 많다면, 링크를 여러 번 검색해야 한다. 디스플레이를 사용하면 접근 횟수를 두개의 명령으로 줄일 수 있다.
- I번째 레벨의 활성 레코드 포인터에 접근: Display[I] = 활성 레코드 포인터
- 변수의 L-값 얻기.
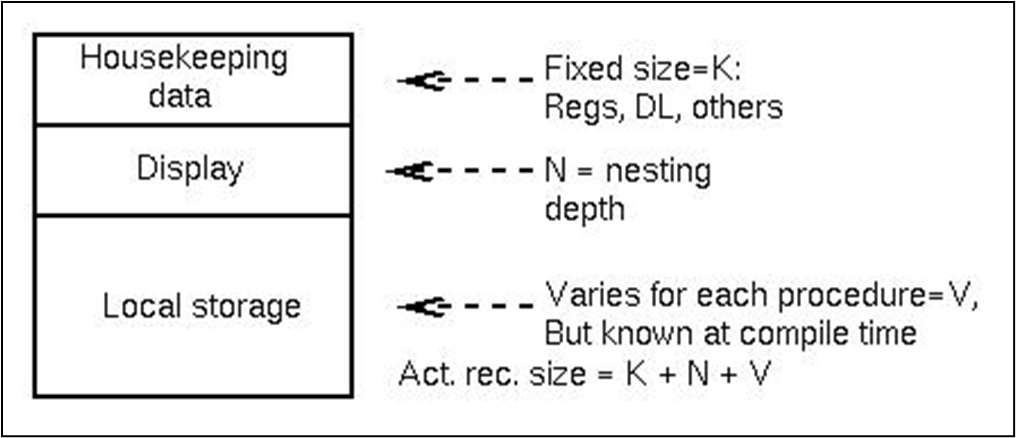
위는 활성 레코드의 구조다.
변수 접근
데이터 접근은 항상 두 단계로 나누어진다.
- [비지역 변수인 경우] Reg1에 Display[I]를 로드한다.
- [모든 변수에 대해] Reg2에 L-값의 오프셋 주소를 로드한다. (Reg1).
활성 레코드 생성
P가 Q를 호출했을 때 생성 과정을 보자. P의 활성 레코드를 가리키는 포인터가 있다고 가정한다.
- P의 활성 레코드에서 EndStack 포인터를 얻는다. 이는 Q의 활성 레코드의 시작 주소다.
- K+NewDisplaySize+LocalStorageSize를 더한다.
- 이것을 Q의 활성 레코드의 EndStack으로 저장한다.
- Q의 DL을 이전 활성 레코드(P)를 가리키는 포인터로 설정한다.
- Q의 활성 레코드의 내부 저장소에 채워 넣는다.
- Q의 활성 레코드에서 새로운 디스플레이를 생성한다.
I번째 레벨에서 J번째 레벨로 호출할 때, 호출 활성 레코드에서 Display[1..J-1]를 복사하고 새로운 활성 레코드 포인터를 Display[J]로 추가하여 새로운 디스플레이를 생성한다.
리턴 시엔 현재 활성 레코드의 링크를 사용하여 이전 활성 레코드를 얻고, 내부 저장소의 리턴 주소를 사용하여 이전 활성 레코드로 점프한다.

C 언어에서의 예시다. J와 K는 동시 존재가 불가능하니, 같은 저장공간을 사용해도 된다.
활성 레코드의 성능 최적화
디스플레이 대신 M 레지스터만을 사용하는 경우, M1, M2, M3, M4만 사용할대 프로시저가 5레벨 충첩되면 어떻게 될까? 비합법적일까?
C언어는 효율적인 실행을 위해, 중첩 프로시저가 없고, 디스플레이나 정적 링크도 필요없지만 동적 링크는 필요하다.
C에서의 스토리지 엑세스
- 프로시저의 저장 공간 할당은 C언어의 일반 규칙을 따라서, 스택 내에 활성 레코드를 할당한다. 정적 링크는 필요하지 않지만, 동적 링크가 필요하다.
- 클래스 변수도 C의 구조체와 같이 저장 공간에 할당된다. 구조체는 함수 멤버를 가질 수 있고, 이경우 함수는 기본적으로 public이고 클래스의 함수는 private가 기본이다.
- 정적 함수는 런타임 활성 레코드에 포함되지 않는다.
- 동적으로 연결이 필요한 객체 (가상 함수)는 런타임에 활성 레코드에 포함된다.
class A {
public: int x;
virtual void p() {...};
void q() {...p()...};
protected: int y;
private: int z;
...}
class B : A {
public: int w;
virtual void p() {...};
void r() {...p()...};
private: int v;
virtual void s() {...};
...}
위의 예시를 보자.


동적, 정적 스코프 정리
스코프 규칙은 일관성을 유지해야 한다.
예를 들어, Pascal의 정적 규칙은 C:=C+B에서 변수 B의 참조를 주 프로그램의 B 선언과 연결한다. 그러니 동적 규칙도 B의 인용을 주 프로그램에서 B로 선언된 객체와 연결해야 한다.
코드에서 B의 여러 선언이 있을 수 있고, 실행 중인 서브프로그램 활성에서도 여러 명명된 B 데이터 객체가 있을 수 있다. 따라서 정적과 동적 규칙 간의 일관성을 유지하는 것이 중요하다.
정적 스코프 규칙이 없다고 가정하고 서브프로그램 내의 문장 X:=X+Max를 생각해 보자. 정적 스코프 규칙이 없으면, 번역 시 X와 Max에 대해 확신할 수 없다. 실행 시에, 참조 연산은 먼저 X와 Max와 관련된 연관을 찾아야 하고, 그 후에 타입과 기타 속성을 결정해야 한다.
Max가 서브프로그램 이름인지, 변수 이름인지, 문장 레이블인지, 타입 이름인지, 형식 매개변수 이름인지도 모르고, X가 변수 이름이라면, Max와 더할 수 있는 타입인지도 모른다. 게다가, 해당 문장이 두 번 실행될 때마다, X와 Max의 연관이 변경될 수 있기 때문에, 전체 프로세스를 매번 반복해야 한다.
정적 스코프
정적 스코프 규칙은 이 프로세스의 대부분을 프로그램 번역 시 한 번만 수행하도록 허용하고, 반복할 필요가 없도록 한다. 예를 들어, X:=X+Max에서 Max는 상수 const Max=30이다. 따라서 컴파일러는 Max의 값이 항상 30이라는 것을 알 수 있으며, 문장은 X에 30을 더하는 것으로 번역되므로 Max에 대한 참조 연산이 필요 없다.
X에 대해, 선언이 X: real이라면, 컴파일러는 정적 검사를 수행하여 문장이 실행될 때:
- X에 데이터 객체에 대한 연관이 존재한다는 것을
- 데이터 객체가 실수 타입이라는 것을
- 그 값이 더하기 연산을 수행할 수 있는 타입이라는 것을
확인 가능하다.
로컬 데이터와 로컬 참조 환경
로컬 참조 환경은 가장 단순한 데이터 제어 구조를 형성한다.
서브프로그램 Q의 로컬 환경은 Q의 헤더에 선언된 식별자, 변수 이름, 형식 매개변수 이름, 서브프로그램(서브프로그램 내에 선언된 서브프로그램) 이름 등을 포함한다.
지역 환경에 대해, 정적과 동적 규칙은 일치하기 쉽다. 정적 규칙을 구현하기 위해, 컴파일러는 식별자와 지역 선언 테이블을 유지한다. Q의 본문을 컴파일할 때 식별자의 선언이 필요할 때마다 이 테이블을 조회하면 된다.

서브프로그램 P, Q, R과 지역 변수 X가 Q에 선언되었다고 가정한다.
X 실행 순서:
- P가 실행될 때, X는 P에게 보이지 않고 Q에만 지역적이다.
- P가 Q를 호출하면, X가 보이기 시작하고, 이름은 정수 데이터 객체로 초기값은 30이다. P가 실행을 재개하면 첫 번째 문장에서 X를 참조하고 현재 값인 30을 인쇄한다.
- Q가 R을 호출하면, X에 대한 연관은 숨겨져 있지만 R이 실행되는 동안 유지된다.
- R이 제어권을 Q에게 반환하면, X에 대한 연관은 다시 보이며 X는 여전히 30이다.
- Q가 실행을 재개하면, X가 참조되고 31로 증가된다.
- Q가 제어권을 P에게 반환하면, X에 대한 연관은 다시 숨겨진다.
지역 참조 환경
제어가 서브프로그램 Q에서 P로 반환될 때, Q의 지역 변수 X에 대한 연관은 다시 숨겨지지만, 이 연관에 대해 두 가지 다른 의미를 부여할 수 있다.
- Retention(유지): X의 연관은 Q가 다시 호출될 때까지 유지될 수 있다. 유지되는 경우, Q가 다시 호출될 때 여전히 동일한 객체와 연결되며 그 값은 31이다.
- Deletion(삭제): X의 연관은 삭제될 수 있다. Q가 호출될 때 새로운 데이터 객체가 생성되고 초기값은 30으로 설정되며 연관도 재구성된다.

참조 환경을 구현하는 편리한 방법은 서브프로그램의 지역 변수를 지역 환경 테이블로 나타내는 것이다. 지역 환경 테이블을 사용하면 유지(보존)와 삭제 방법의 구현이 간단한다.
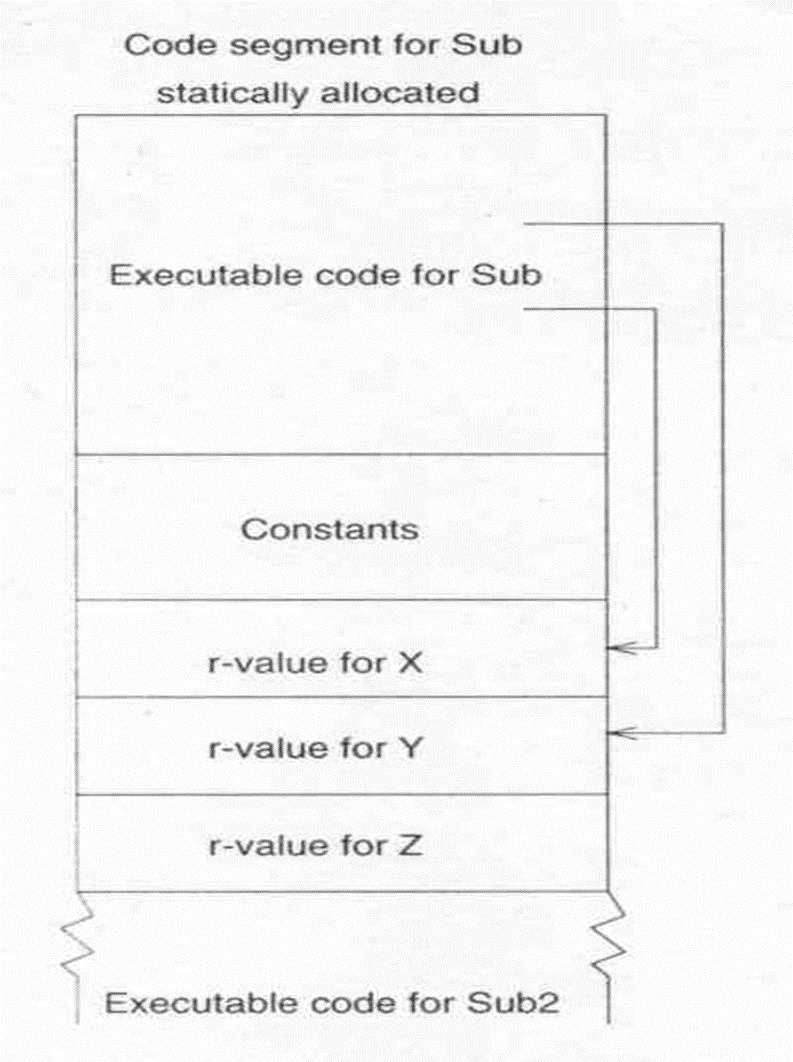
- 保持 (유지, 보존): 유지되는 변수를 포함한 지역 환경 테이블은 코드 세그먼트의 일부로 할당된다. 정적 할당이므로 실행 중에 계속 존재하고, 이터 객체의 값을 유지하기 위해 특별한 조치가 필요하지 않다.
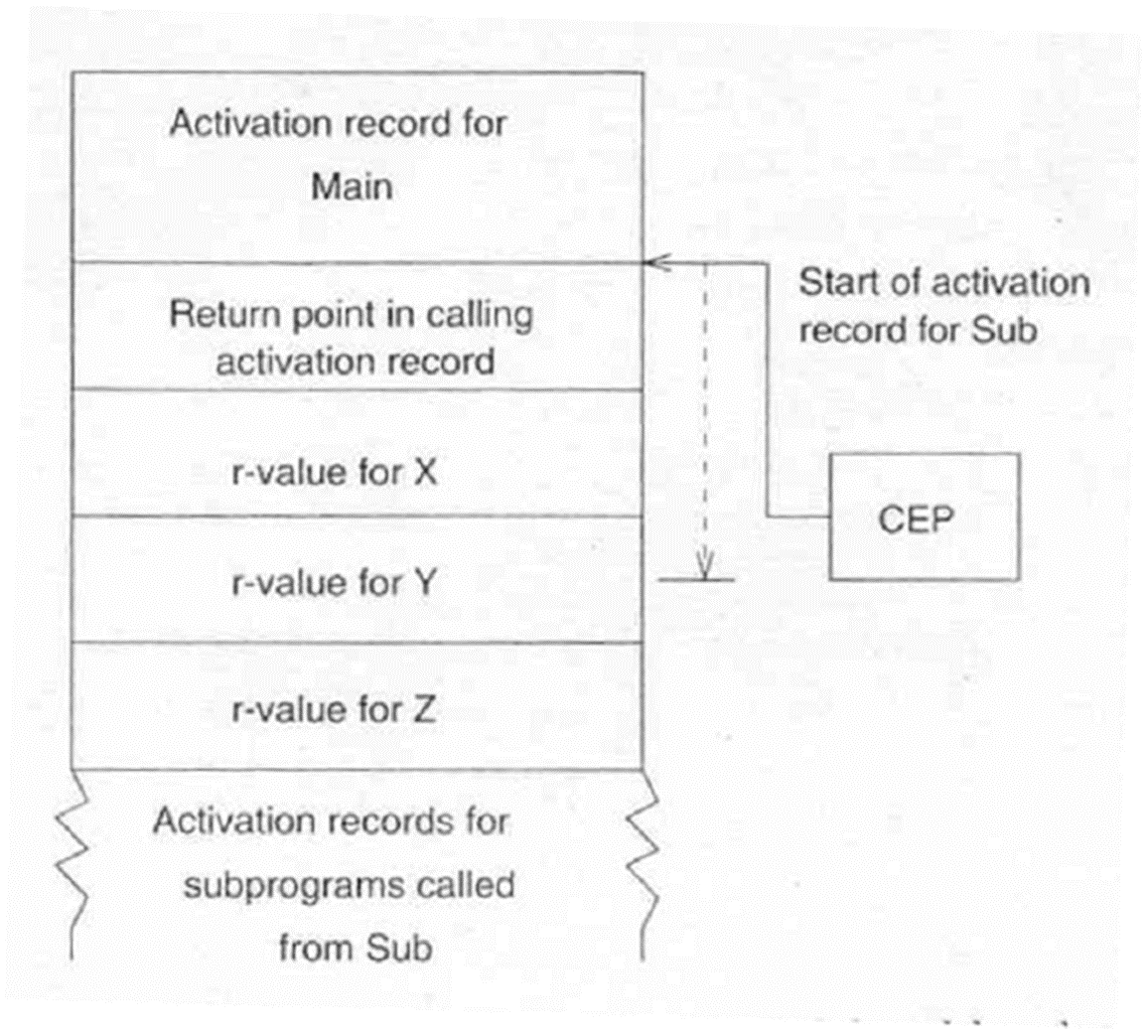
- 삭제 (删除): 삭제될 변수를 포함한 지역 환경 테이블은 활성화 레코드의 일부로 할당된다. CEP는 현재 활성화 레코드의 기본 주소를 가리킨다.
