프로토콜과 계층
프로토콜
컴퓨터 정보 교환에서 메세지의 형식과 의미를 규정하는 협정을 프로토콜이라고 한다. 대부분 하드웨어 대신 네트워크 프로토콜 소프트웨어를 사용하고, 프로토콜이 협동적으로 잘 작동하도록 하기 위해선 각 프로토콜을 고립적으로 개발할 것이 아니라 프로토콜 시리즈(protocol suite, 协议系列) 또는 프로토콜족(family, 协议组)이라는 완전하고 협동적인 집합으로 설계하고 개발해야 한다.
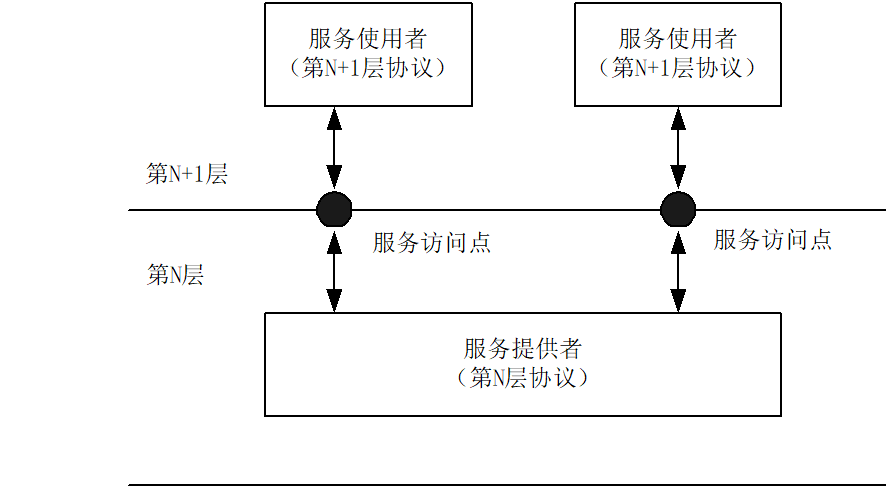
설계 시에 보통 계층형 보델을 사용하고, 복잡한 통신 문제를 여러 다른 부분으로 나누어 부분별로 집중이 가능하다. 프로토콜 계층화의 기본은 목적단의 N층에서 소스의 N층에서 진행된 변환을 역변환하는 것이다.
ISO/OSI 7계층
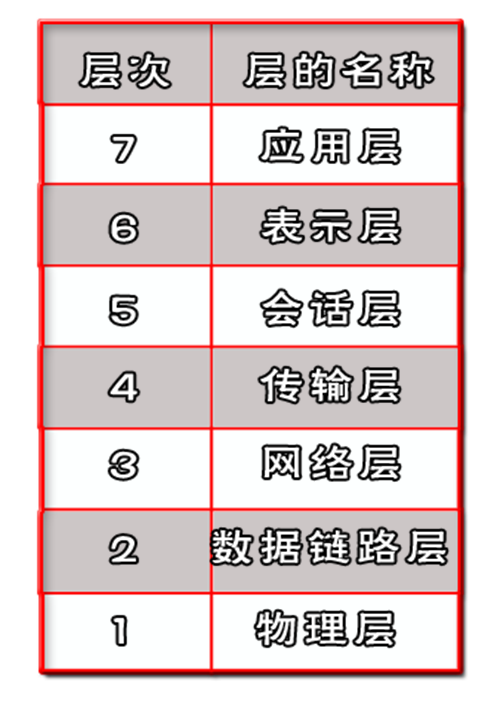
다시 등장한 친구다. 인터넷 프로토콜에 대한 설명이 충분친 않지만, 아직도 자주 인용된다.
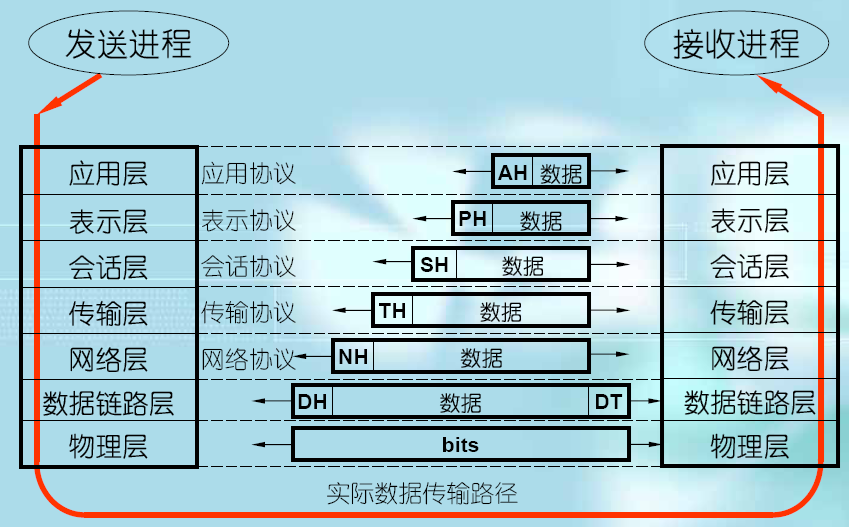
보이듯 보내진 순서에서 역행해서 해석된다. 첫 강의에서 편지봉투의 예시를 사용했었다. 각 계층은 模块에 해당하고, 이 모듈 세트를 스택이라고 총칭한다. 프로토콜 스택은 서로 호환도 안되는데, 근 50년간 여러 스택들이 개발되었지만 모두 TCP/IP로 전환되고 있다.
프로토콜 사용 기술
- 정렬을 사용한 난순/반복 패킷 처리
无连接网络는 순서를 보증하지 않고, 하드웨어 오류가 중복 패킷이 생기게 할 수도 있다. - 확인, 재발송을 사용하여 분실 패킷 처리
패킷 손실은 네트워크에 자주 일어나는 기본 문제다. - 고유한 세션 식별자를 통한 재전송 방지
이전 세션이 다음 세션에 간섭하는것을 방지해야 한다.
여기서 Stop-And-Wait 프로토콜이나 슬라이딩 윈도우 매커니즘으로 트래픽을 제어하고, 속도 감소를 사용해서 네트워크 혼잡을 처리할 수 있다.
Stop-And-Wait 프로토콜 (停-等协议)
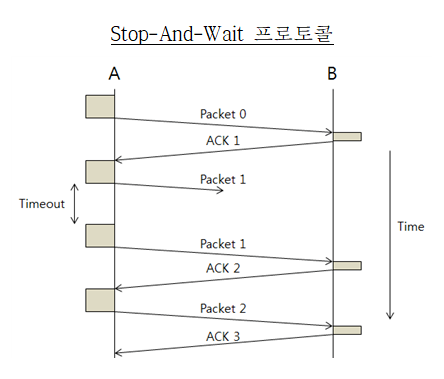
컴퓨터들이 모두 같은 속도로 실행되진 않는다. 네트워크를 통해 전송되는 속도가 컴퓨터보다 빠르면 데이터 과부하 (数据过载)가 발생하고, 이는 데이터 손실로 이어진다.
이를 해결하는 流量控制 메커니즘중 가장 간단한게 이 방식이다. 각 패킷을 보낼때마다 수신자의 응답을 기다리고, 수신측이 다음 패킷을 받을 준비가 되면 控制报文을 보내서 확인하고, 최종적으로 다음 패킷을 보낸다. 이 방식은 과부하 방지엔 좋지만, 네트워크 대역폭 활용도를 감소시킨다.
슬라이딩 윈도우 (滑动窗口)
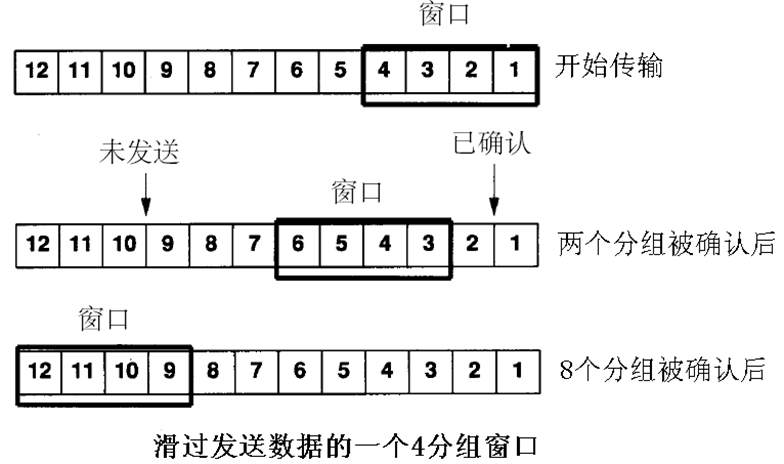
이 방식은 발송측과 수신측이 고정된 윈도우 사이즈를 사용해서 보낼 수 있는 최대 데이터 크기를 결정한다.
발송측은 발송을 시작할때 데이터를 추출해서 첫 창에 넣고, 각 패킷의 사본을 전송한다. 신뢰성관련 요구 사항이 있다면 발송측은 사본을 저장해놔서 재발송에 대비해야 한다.
수신측은 전체 윈도우를 수신하기 위해 버퍼 공간을 준비하고, 패킷이 순서대로 도착하면 이를 응용 프로그램에 전달하고 발송측에게 확인을 보내준다.
이후 발송측은 확인된 데이터의 사본은 버리고, 창을 앞으로 밀어서 다음 패킷을 보내는 방식이다. 이 방식은 창 크기를 조절하여 하드웨어 대역폭을 최대한 활용 가능하다.
네트워크 정체, 그리고 해결책
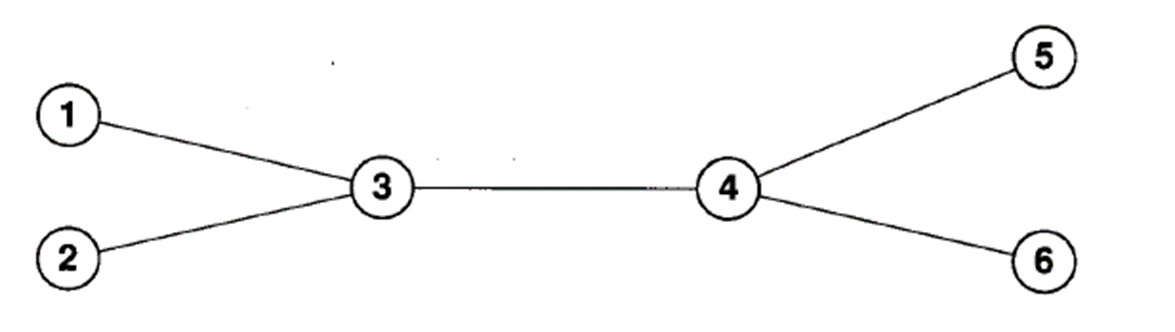
위 예시를 보자. 6개의 패킷 스위치가 있고, 3에 도착하는 데이터 속도가 사이트 3이 4에 전송할 수 있는 데이터 속도보다 훨 빠르다면 3은 계속 데이터를 대기열에 놓을 수밖에 없고, 이러면 대기열은 한없이 커지고 유효 지연은 증가해 정체 (拥塞, congestion)가 발생한다. 이가 이어지면 패킷 스위치에서 메모리 오버플로우가 발생해서 패킷을 폐기하고 다시 받아야 한다.
이게 계속 이어지면 네트워크 전체가 맛이 가고, 이를 정체 붕괴 (拥塞崩溃, congestion collapse) 라고 한다.
이를 해결하려면, 프로토콜은 네트워크를 모니터링하고 정체가 발견되면 아주 신속하게 대응해서 붕괴를 막아야한다.
만약 정체가 발견되면, 스위치는 신속하게 발송측에 이를 알리고, 지연되는 각 패킷의 헤더에 码位를 설정한다. 이 패킷을 받는 컴퓨터는 이 码位를 발견하면 확인 메세지에 관련 메세지를 넣어 원본 발송자에게 알리거나, 교환기가 스스로 원본 발송자에게 특수 메세지를 보낸다.
네트워크 분실은 정체의 정도를 예측할수 있는 지표로 쓰이는데, 현대 네트워크에서 하드웨어는 다 잘 작동하는 편이고 패킷 손실은 대부분 정체때문인 경우여서다. 정체에 대응하기 위해선, 패킷 전송 속도를 낮추는 방법이 주로 사용된다.
프로토콜 설계 시 주의점
通盘考虑하라고 ppt에 적혀 있는데, 전반적으로 고려해야 한다는 뜻이다. 프로토콜 메커니즘은 항상 상호 작용하기에, 예를 들어 트래픽 제어 매커니즘과 정체 메커니즘간의 상호작용을 고려해 슬라이딩 윈도우 방안은 대역폭을 사용해 처리 성능을 향상시키려 하고, 정체 방지 메커니즘은 반대로 한번에 주입되는 패킷 수를 줄여 붕괴를 방지한다.
효과적으로 통신하기 위해선 세부사항의 선택도 중요한데, 예를 들어 序列号는 패킷 헤더 부분의 고정 도메인에 배치되는데 이 도메인은 일련번호가 자주 재사용되지 않도록 충분히 커야하는 동시에 대역폭을 낭비하지 않도록 최소화되어야한다.
또한 계층화는 중요하지만, 무선 네트워크같은 친구는 성능 향상을 위해 계층간을 뛰어넘기도 해야하기 때문에 계층화를 필수 불가결 원칙으로 삼지 말고 도구로 사용해야 한다.
인터네트워킹의 개념
네트워크들은 종류도 많고, 많이 다르다. 만약 이런데 서로 사용/호환이 안된다면 네트워크는 섬처럼 고립되어버린다. 컴퓨터 통신 시스템이 임의의 두대의 컴퓨터가 통신할 수 있도록 허용하는것이 바로 범용 서비스 (通用服务)다. ATM 등 기술들이 범용 서비스를 제공하기 위해 노력하고 있다.
하지만 네트워크들은 전기 방면의 비호환성 때문에 단순히 도선으로 서로 잇는것으로 네트워크 형성은 불가능하고, 네트워크 기술들은 또 패킷 형식, 주소 지정 체계등이 다르기에 호환이 되지 않는다. 그래서 서로 기술이 다른 네트워크를 브릿지로 이어버릴 순 없다.
라우터와 네트워크 연결
그래서 이걸 해결하기 위해, 궁극적으로 네트워크간 연결 (internetworking, 网络互联)을 실현하기 위해 많은 방안들이 설계되었다.
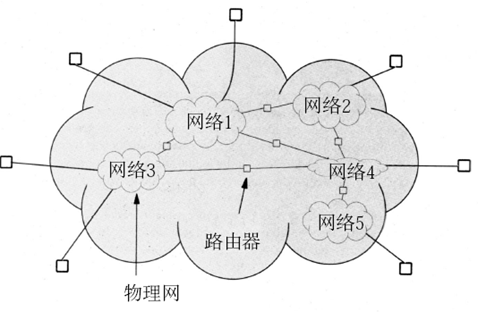
서로 다른 异构한 네트워크를 연결하기 위해 라우터 (路由器)라는 하드웨어가 등장한다. 라우터는 인터네트워킹을 전문적으로 수행하는 전용 컴퓨터라 보면 된다. 라우터는 다양한 介质, 물리 주소 지정 체계, 프레임 형식 등이 다른 기술들의 네트워크를 이어준다. 그리고 라우터를 통해 서로 다른 물리적 네트워크가 연결되어 형성되는 시스템이 바로 인터네트워크, 혹은 인터넷 (互联网, 因特网) 되시겠다.
세계에서 가장 큰 互联网이 바로 인터넷이다. 물리적 네트워크, 프로토콜, 어플리케이션과 정보가 인터넷을 구성한다.
思考:브릿지, 스위치와 라우터의 비교

인터넷 아키텍쳐
인터넷은 라우터를 통해 연결된 네트워크 그룹들로 구성된다. 상업용 라우터는 한번에 많은 네트워크를 이을 수 있지만, CPU, 메모리가 너무 많은 트래픽을 처리 할 수는 없어서 하나의 라우터로 네트워크를 다 잇지는 않는다. 冗余度, 즉 중복도를 높혀 어떤 네트워크나 라우터가 고장났을 시 다른 경로를 사용하게 하는 편이 더 좋다.
네트워크 수와 유형, 상호 연결을 위한 라우터 수와 상호 연결 토폴로지 구조가 아키텍쳐의 설계 요소가 된다.
이제 异构한 네트워크들을 어떻게 이어서 범용 서비스를 실현 할 수 있을까? 네트워크마다 사용되는 프레임 형식과 주소 지정 체계가 다르니, 인터넷 프로토콜이 나서서 프레임 형식과 물리주소의 차이를 극복하고 통신을 실현 해줘야 한다.
네트워크 가상화 (虚拟网络)
논리적으로 볼때, 인터넷은 단일한, 빈틈없는 통신 시스템이다. 인터넷 위의 모든 컴퓨터 쌍은 하나의 네트워크에 연결된 것처럼 통신이 가능하다.
하지만 이는 착각이다! 메모리 가상화가 떠오르는듯한 방식으로 만들어 지는 착각이다 이거다. 이 착각은 프로토콜 소프트웨어가 만들어내며, 인터넷의 모든 컴퓨터와 라우터는 이를 실행해서 패킷을 교환하고, 저층 물리 연결의 디테일을 숨겨 0개, 혹은 여러 개의 라우터를 통해 목적지까지의 패킷 전송을 책임진다.
TCP/IP 프로토콜
가장 널리 쓰이는, 인터넷을 위해 개발된 첫 번째 프로토콜이며, 전세계 인터넷을 가능케 하는 핵심이다.
인터넷의 표준 통신 프로토콜로써, TCP/IP는 인터넷 계층에서의 인터넷의 패킷 형식과 규칙을 정하고, 데이터 전송 계층에서의 타겟 시스템으로의 데이터 전송을 보장한다.
세분화해서 IP 프로토콜은 데이터 전송에 정확한 경로를 제공하고, 인접 노드간 데이터 전송을 맡는다. 이를 통해 호스트 간 동일한 형식의 데이터 전송이 실현되지만, 데이터 패킷이 전송중 오류가 발생하지 않을거라 보장할 수는 없다.
TCP 프로토콜은 패킷 재전송 기술, 시퀀스 조정과 정체 제어 메커니즘 등 기능이 포함되어, 인터넷에서의 신뢰성 있는 데이터 전송을 보장한다.
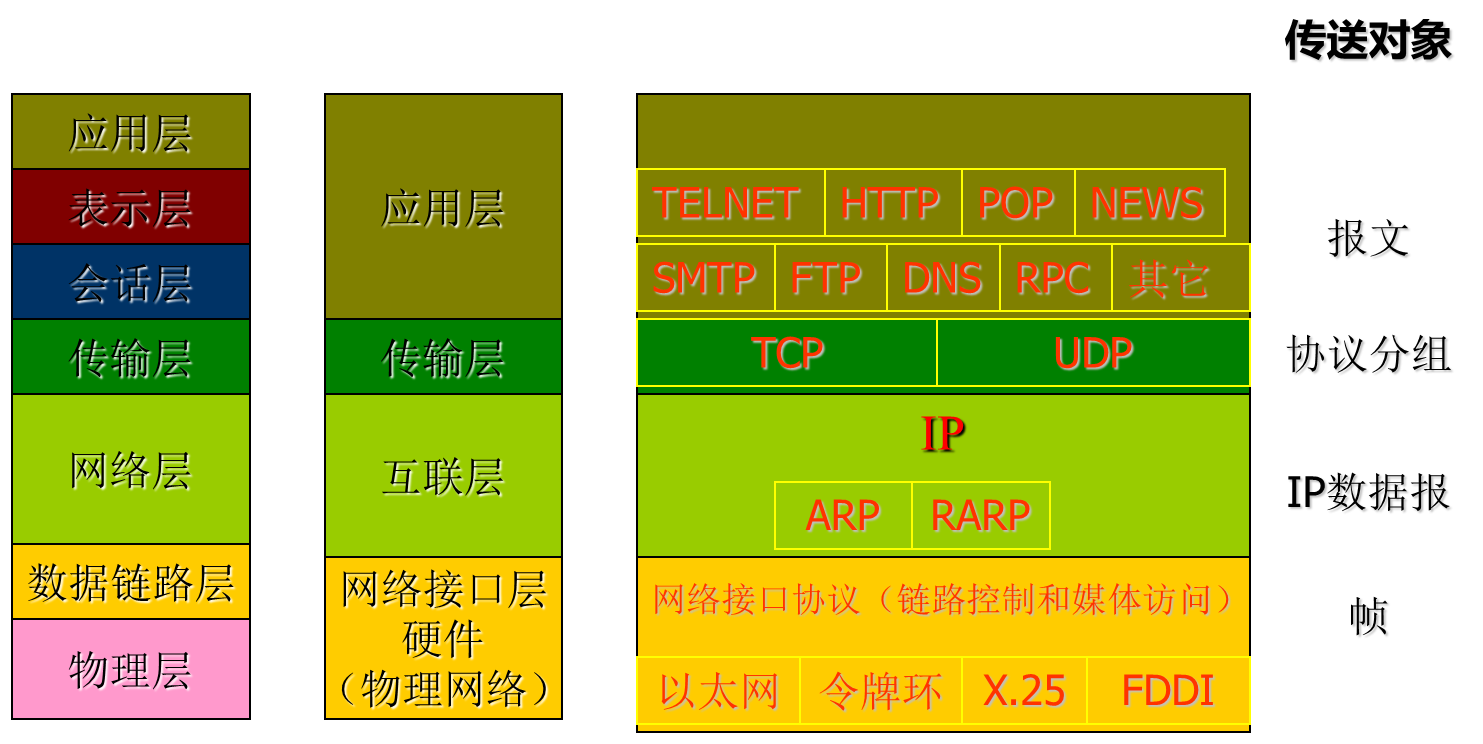
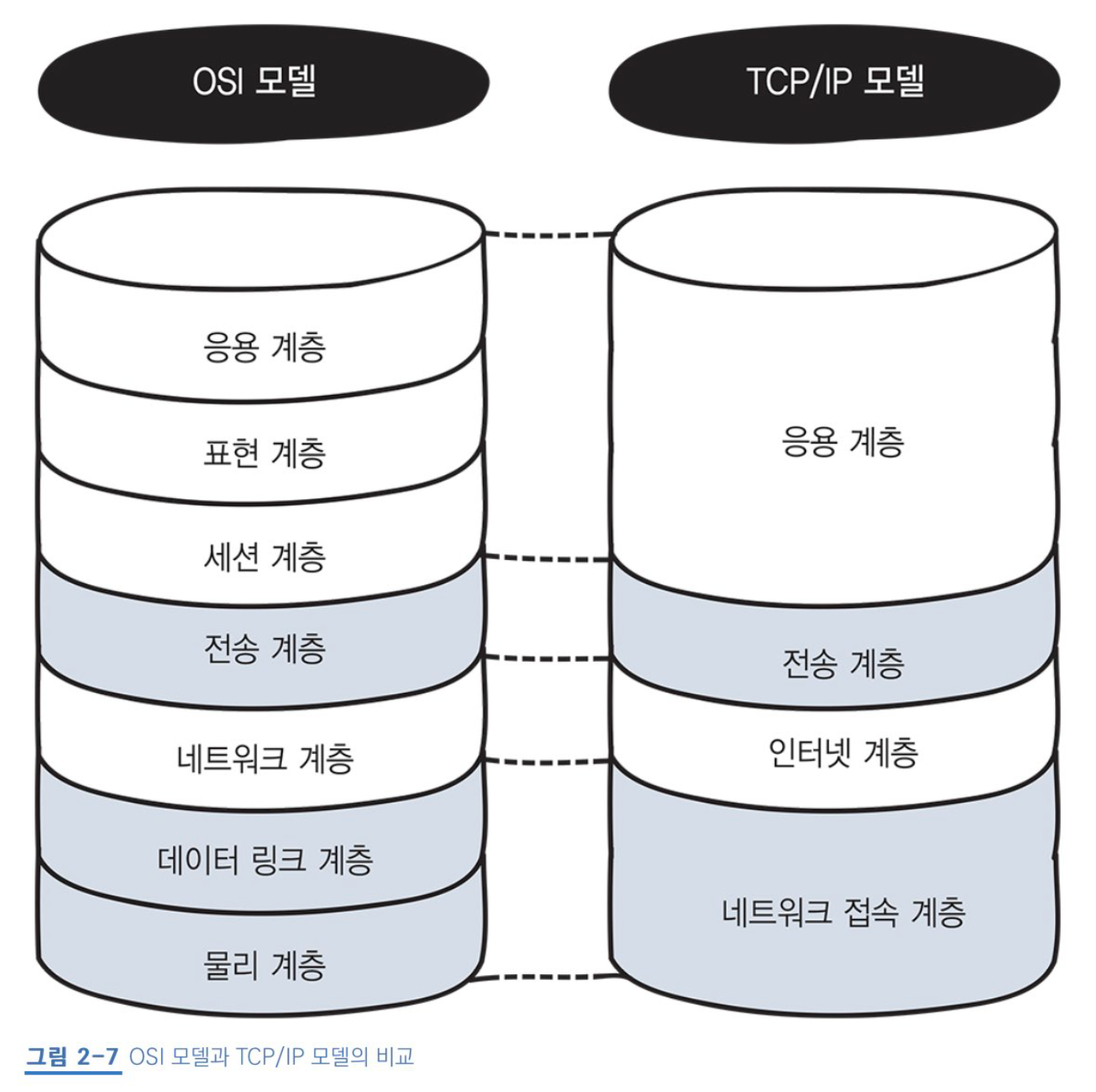
TCP/IP는 네트워크 접속 계층, 인터넷 계층, 전송 계층와 응용 계층으로 나뉘어져 있다.
네트워크 인터페이스 계층 (网络接口层)
OSI 모델에서의 물리 계층과 데이터 링크 계층을 포함하며, 네트워크에서 TCP/IP 데이터 패킷의 발송/수신을 책임진다. TCP/IP는 네트워크 엑세스 방법, 프레임 형식과 미디어의 제한을 받지 않게 설계되었기에, 여러가지 네트워크를 연결할 수 있다.
인터넷 계층 (互连层)
OSI 모델의 네트워크 계층에 해당한다. 인터넷에서 전송되는 패킷 형식을 지정하고, 소스에서 하나 혹은 여러개의 라우터를 통해 목적지에 패킷이 전송 될 수 있도록 寻址,封装과 路由기능을 포함한다.
인터넷 계층의 핵심은 IP 프로토콜이다. ARP, ICMP, IGMP 기술도 있다.
ARP는 주소 분석 프로토콜로 인터넷 계층의 주소를 하드웨어 주소로 해석하는 등 인터넷 계층의 주소 분석를 책임진다. ICMP는 控制报文 프로토콜로, IP 데이터 패킷 전송에 대한 오류나 정보를 보고하는 진단 기능을 제공한다. IGMP는 IP 다중 전송 그룹의 관리를 담당하는 인터넷 그룹 관리 프로토콜이다.
전송 계층 (传输层)
전송 계층은 OSI모델의 전송 계층과 세션 계층의 일부를 포함한다. 두 어플리케이션 간 세션 및 정보 통신 서비스를 구축하며 신뢰성, 트래픽 제어 및 재전송등 일반적 문제를 해결한다.
전송 계층의 핵심은 TCP (传输控制协议)와 UDP (用户数据报协议) 프로토콜 이며, TCP는 일대일 방식으로 오류 없는, 신뢰성 있는 데이터 전송 서비스를 제공하고 UDP는 일대일 혹은 일대다 방식으로 연결 없이, 신뢰성 보장이 안되는 통신 서비스로 데이터 전송의 순서가 중요하지 않은 경우 사용된다.
응용 계층 (应用层)
응용 계층은 응용 프로그램의 인터넷 사용 규칙을 정의한다. 이는 해당 계층의 프로토콜 처리, 표현, 인코딩과 대화 제어 등이 포함된다. TELNET, HTTP, FTP, SMTP, POP, IMAP등이 모두 여기 속하고 새로운 프로토콜들도 개발되고 있다.
인터넷 프로토콜 주소

빈틈 없는 통신 시스템 구축을 위해서, 编址 즉 주소 지정은 인터넷 추상의 핵심 구성 부분이다.
통합 주소를 제공하기 위해 프로토콜 소프트웨어는 각 호스트에 고유한 주소를 할당하는 추상적인 주소 지정 체계를 정의하고, 사용자, 어플리케이션 및 상위 프로토콜은 이 추상 프로토콜 주소를 사용해야 통신이 가능하다. 이 통합 주소는 하층의 물리적 네트워크 주소의 디테일을 屏蔽하여 거대하고 빈틈없는 네트워크의 환상을 만드는데 일조한다.
IP 주소 지정
TCP/IP 프로토콜 스택에서의 주소 지정은 IP (Internet Protocol)에 의해 결정된다.
IP 표준은 호스트당 32비트 이진수를 할당하여 해당 호스트의 IP 주소로 사용하게 하고 있으며, 인터넷에서의 모든 패킷은 송신, 수신측의 IP 주소가 포함된다.
IP 주소
IP는 인터넷 주소를 두개의 층으로 구분한다. 前缀는 컴퓨터가 연결된 네트워크를 나타내고, 后缀는 이 네트워크에서의 특정 컴퓨터를 나타낸다. 주소의 고유성을 위해 ICANN이 前缀를 할당하고, 로컬 네트워크 관리자가 각 호스트에 고유한 后缀를 할당하고, 이런 계층 구조는 경로 찾기를 편하게 해준다.
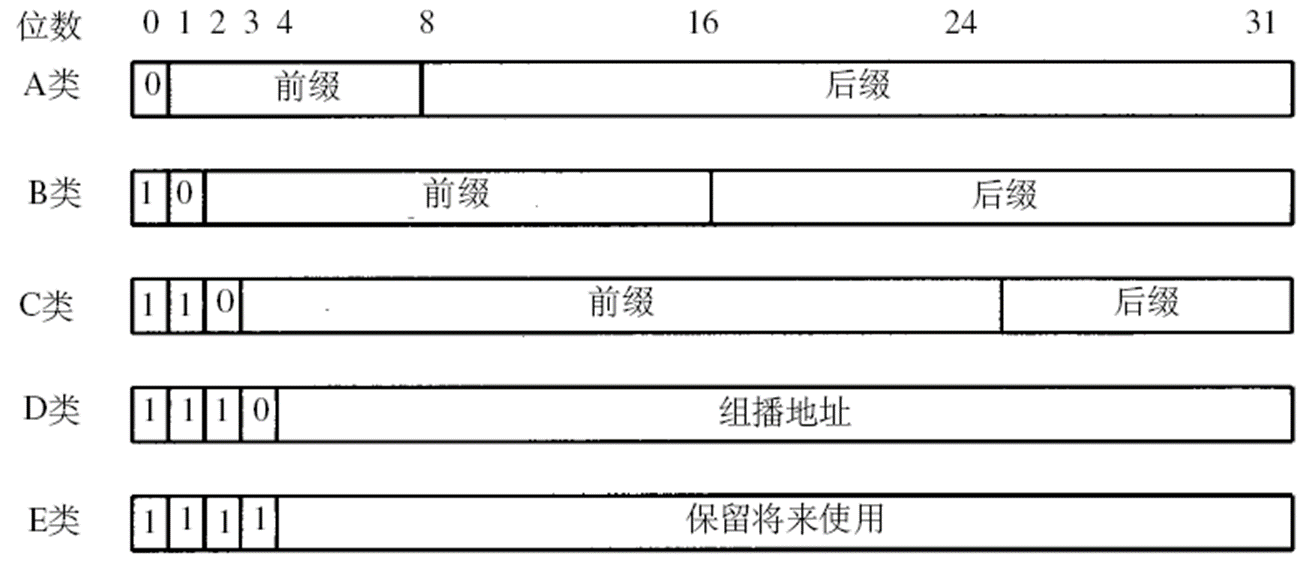
A부터 E클래스까지 5개의 클래스가 있고, 주소의 클래스는 첫 4비트에 의해 결정된다. B클래스 IP 주소는 255~65534개의 호스트를 포함하고, 더 작은 네트워크는 클래스 C, 더 큰 네트워크는 클래스 A가 할당된다.
Dotted-Decimal Notation (온점-십진 주소 표기법, 点分十进制表示法)

IP 소프트웨어가 유저와 상호작용할때 쓰는 어법이라 보면 된다. 이 표기법은 32자리의 각 8비트를 십진수로 표기하고 점으로 각 그룹을 구분한다. 이를 통해 우리가 흔히 아는 IP주소의 형식이 된다.
A, B, C클래스
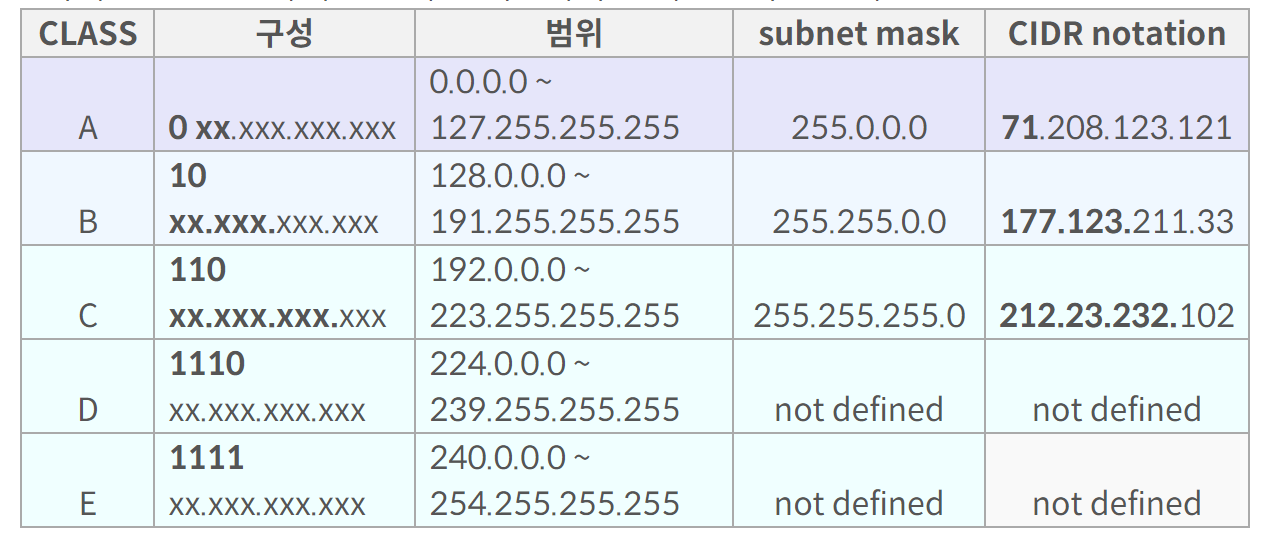
W.X.Y.Z라고 표시되는 IP 주소가 있다고 하자.
A 클래스
매우매우매우 큰 네트워크를 위한 클래스다. 전세계에 126개의 클래스 A주소만이 존재하고, 前缀는 7이다. W만이 네트워크 식별자고, X, Y, Z는 호스트 식별자다. 총 16777214개의 호스트를 가질 수 있고, 전부 0이거나 1인 주소는 사용 불가하다. 더이상 신청이 불가능한 클래스의 주소다.
B 클래스
중간 규모 네트워크 용이다. W와 X가 네트워크 식별자지만, W는 128~191사이의 숫자일 뿐이고 X가 더 자세하게 네트워크의 주소를 보여준다. Y와 Z가 호스트 식별자다. 16384개의 B클래스 네트워크가 있고, 각 네트워크는 A클래스처럼 전체 0과 1인 호스트 주소 빼고 65534개의 호스트를 지원한다.
C 클래스
소규모 네트워크 용이다. W, X, Y는 네트워크 식별자인데, W는 192~223사이의 임의 숫자다. Z는 호스트 식별자다. 2097152개의 C클래스 네트워크가 있고 각 네트워크는 254개의 호스트를 지원한다.
특수 IP 주소
- 로컬 주소 (전부 0): 컴퓨터를 켜고, TCP/IP프로토콜중 하나로 자신 스스로의 IP를 얻을수 있는데, 이를 위해 우선 모두 0인 주소를 남겨둬 스스로를 나타낸다.
- 네트워크 주소 (네트워크前缀+后缀모두0): 네트워크 자체를 나타낸다. 예를 들어 128.211.0.0은 B 클래스에 분배된 128.211에 할당된 네트워크를 나타낸다.
- 直接广播 (네트워크前缀+后缀모두1): 지정된 네트워크의 모든 站点에 직접 브로드캐스팅을 하는 주소다. 예를 들어 190.34.255.255에 정보를 보내면 190.43 B클래스 네트워크의 모든 호스트에 정보가 전송된다.
- 有限广播 (전부 1): 로컬 물리적 네트워크에서 제한된 브로드캐스팅을 진행하는 주소다.
- 루프백 주소 (回送地址): 127로 시작되고, 루프백 테스트용으로 쓰인다. 우리와 아주 친근한 localhost 주소가 127.0.0.1이고, 여기에 정보를 보내면 스스로에게 돌아온다.
- 멀티캐스트 주소 (多址通信,组播, 前缀1110): W는 223보다 크지 않고, 멀티캐스트 용 혹은 향후 사용을 위해 예약해둔 주소다.
서브넷, Classless 주소
인터넷의 덩치가 너무 커졌다. 때문에 클래스 형식으로 주소를 분배하긴 제한이 생기기 시작했다. 분배된 클래스가 작으면 주소가 충분하지 못하고, 크면 많은 주소들이 쓸데없이 낭비되기 때문이다.
이를 해결하기 위해, 서브넷 주소 혹은 无类编址 (Classless adressing)이 등장한다. 3개의 클래스를 사용하지 않고도 前缀와 后缀의 임의 码位를 사용해 유연하게 경계를 나눌 수 있다. 예를 들어, 9개의 호스트만 있는 네트워크에서 ISP는 28비트의 前缀를 할당하고 남은 4개 비트 (14개 호스트 수용 가능)을 호스트용으로 할당하고, C클래스 주소를 할당할 필요가 없다.
서브넷 주소 지정 체계에서는 地址掩码 (Address mask) 혹은 子网掩码 (Subnet mask)라고 하는 32비트의 지정된 前缀와 后缀의 경계값을 IP주소와 함께 저장한다. 1로 前缀를 표시, 0으로 호스트 后缀를 표시하고, 이 마스킹과 목적 주소에 AND 연산을 하여 목적 주소의 前缀를 얻을 수 있어, 계산 효율이 올라간다.
CIDR 표시법 (Classless Inter-Domain Routing)
위에 한말이 뭔소린지 감이 안오니 예시와 함께 보자.
CIDR 표기법은 주소 뒤에 /와 함께 10진수 마스크 크기 값을 추가하여, 이 주소의 마스크를 지정하는 방식이다.
128.10.0.0이라는 주소를 보자. 이 주소는 16비트의 네트워크 前缀와 16비트 호스트 后缀로 이루어져 있고, 128.10.0.0/16으로 표기된다. 만약 두 고객이 모두 12개의 호스트만 있다면 ISP는 CIDR을 사용해서 192.211.15.0같은 C 클래스 네트워크를 192.211.15.16/28과 192.211.15.32/28 2개로 나누어 각 고객에게 주고 남은건 예비용으로 두어 3분할할 수 있다. 고객은 모두 28비트 길이의 마스크를 가지지만 前缀가 달라 혼동이 발생하지 않는다.
라우터와 IP 주소
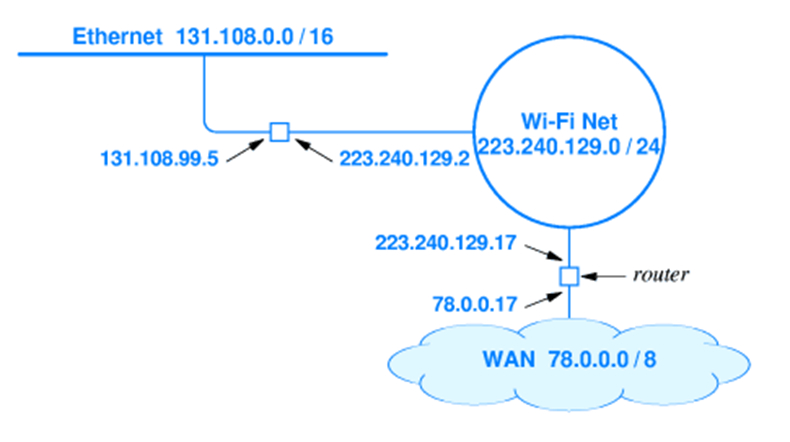
라우터에도 IP 주소가 할당된다. 실제로도 사진처럼 2개 이상 할당되고, 하나의 라우터는 여러 물리적 네트워크의 연결되면서 각 주소는 하나만의 특정된 물리 네트워크 前缀를 가진다. IP 주소는 특정 컴퓨터를 식별하기보단, 한 컴퓨터와 한 네트워크 사이의 연결을 식별한다 보면 된다. 여러 네트워크에 연결된 컴퓨터나 라우터는 각 연결에 이때문에 하나씩 IP 주소를 할당해야 한다.
위 사진을 보면 실제로 라우터의 각 接口는 해당 네트워크의 前缀주소를 가진다.
주소 결정 (地址解析)
프로토콜 주소와 패킷 전송
대형 가상 네트워크의 환상을 위해 네트워크 소프트웨어는 IP 주소로 패킷을 전달한다. 하지만 프로토콜 주소는 ㅅ프트웨어가 제공하는 추상적인 주소이기에, 물리적 네트워크의 하드웨어는 프로토콜 주소만으론 목적 컴퓨터를 못찾는다. 특정 물리적 네트워크의 프레임 형식을 사용해야 할 떄도 있고, 프레임 내부의 모든 주소는 또 하드웨어 주소를 사용한다. 그래서 프레임 라우팅 전에 꼭 IP주소를 동등하게 유효한 하드웨어 주소로 번역해야한다.
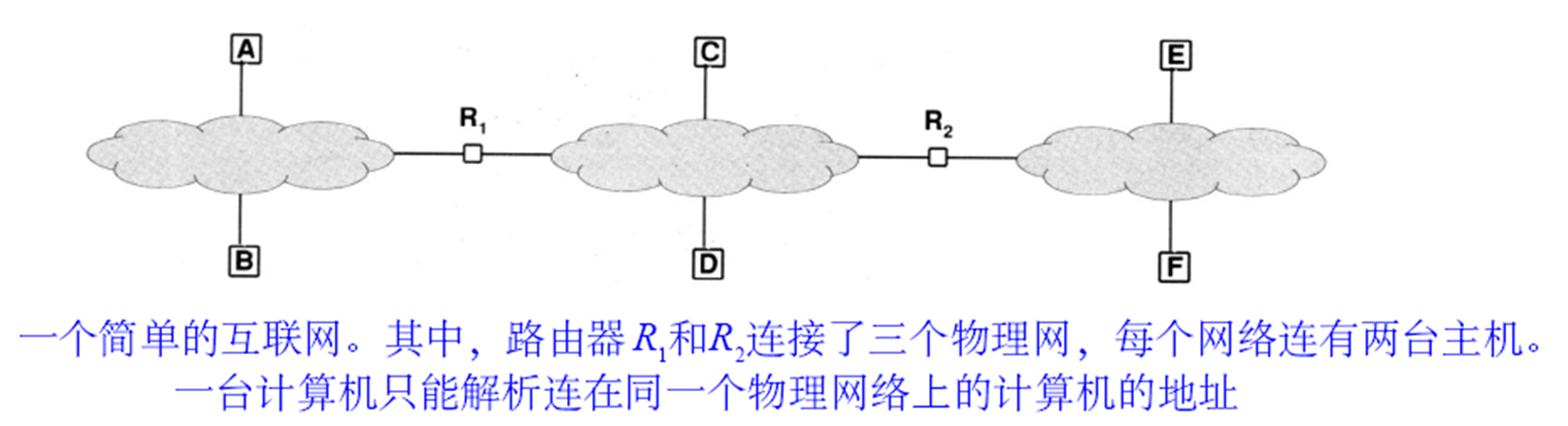
그래서 주소 결정, Address resolution이 이 번역 과정이다. 호스트나 라우터는 동일한 물리 네트워크 내의 다른 컴퓨터에게 데이터를 전송할때 주소 결정을 진행한다.
위 그림에서 호스트 A가 원격 네트워크에 있는 F에 전송하려면, A의 프로토콜 소프트웨어는 F의 주소를 확인할 방법이 없다. A의 소프트웨어는 패킷이 R1 라우터를 거치는것을 확인, R1의 주소를 결정하고 R1에 패킷을 보낸다. 그후 R1의 소프트웨어는 R2의 주소를 결정하고 전달, 이후 R2는 목적지인 F가 오른쪽 물리적 네트워크에 연결되어있음을 확인하고 F의 주소를 결정 후 F에게 보낸다.
주소 결정 기술

크게 세가지로 나뉜다.
查表法 (Table Lookup)
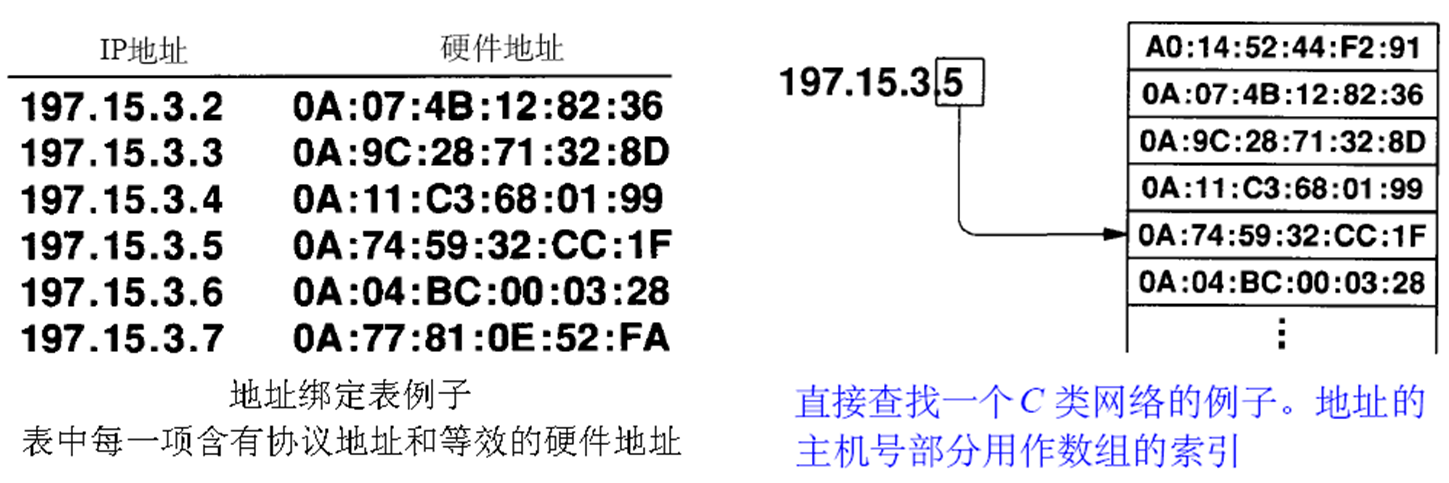
이 방법은 주소 바인딩 정보가 포함된 표가 필요하다. 표는 프로토콜 주소, 물리적 주소 두개 항목이 있으며 직관적으로 각 IP 주소와 하드웨어 주소가 바인딩된다. 호스트가 적은 네트워크는 순차검색을 해도 되고, 크다면 해싱이나 Direct indexing을 사용한다.
封闭式计算法 (Closed-form computation)
몇몇 기술들은 동적 물리 주소를 사용해, 네트워크 인터페이스가 특정된 하드웨어 주소에 바인딩 될수 있도록 한다. 이런 경우 이 계산법이 사용 가능하다.
이런 네트워크에 C클래스 네트워크 주소 220.123.5.0/24가 할당되면 첫 호스트의 IP는 220.123.5.1, 하드웨어 주소는 1로 지정된다 하자. 이 다음부터는 IP와 하드웨어 주소가 모두 1씩 올라간다. 이경우 IP주소 & 0xff 논리 연산을 하면 곧바로 하드웨어 주소가 나온다!
报文交换法 (Message Exchange)
두가지 방안이 있다.
첫 방안은 네트워크에 하나 이상의 서버가 있고, 이 서버가 주소 확인 요청에 응답한다. 두번째 방안은 주소 확인 서버 없이, 네트워크의 모든 컴퓨터가 주소 확인에 참여해서, 주소 확인 필요시 요청이 네트워크에 브로드캐스팅되고 모든 기기가 주소를 검사한 후 자신의 주소면 응답한다.
방식 비교

WAN에서는 검표법이 많이 쓰이고, 폐쇄식 계산은 동적 주소 할당 네트워크에 많이 쓰이며, LAN은 정적 주소 할당이니 마지막 방식이 많이 쓰인다.
ARP
TCP/IP는 착하다. ARP (Address Resolution Protocol, 地址解析协议)가 포함되어, 컴퓨터가 교환하는 ARP 메세지 형식과 규칙을 정의해놨다. 현실에선 IP주소를 이더넷 주소로 번역하는데 쓰이고 있다.
ARP 메세지 발송 & 식별 & 처리
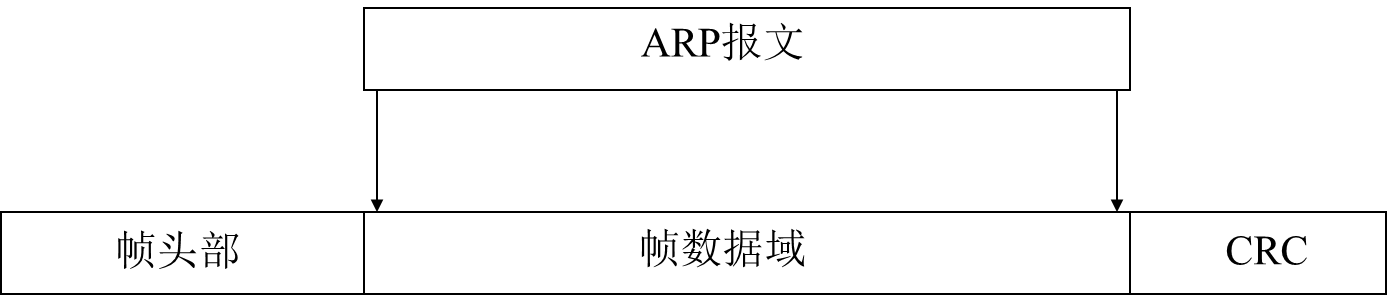
ARP 메세지는 프레임에 내장되어 전송된다. 이를 프레임에 넣는걸 封装 (encapsulation)이라 한다. 하드웨어는 ARP 메세지 형식 이해를 못한다.

프레임 헤더의 类型域 (Type Field)는 프레임에 ARP 메세지가 있음을 알린다. 이더넷 표준에서 ARP 메세지가 있으면 이 필드에 0x806이 들어간다. ARP 요청 메세지를 포함한 프레임과 ARP 응답 메세지가 포함된 프레임의 유형값은 같고, 수신자는 요청인지 응답인지 확인하기 위해 操作域를 확인해야한다.
이제 처리할 단계다. 우선 수신측은 발송자의 주소 바인딩 정보를 꺼내서 캐시에 발송자의 주소가 있는지 확인한다. 없으면 발송자의 주소 바인딩 정보를 캐시에 추가해두고, 있으면 방금 꺼낸 정보로 업데이트한다.
그후 수신측이 응답인지 요청인지 확인한다. 응답이라면 이미 요청을 보냈었을 거고, 요청이라면 목적지의 프로토콜 주소 도메인과 스슬의 프로토콜 주소를 비교하고 똑같다면 ARP 응답을 보내준다.
물리 주소 할당의 隐藏
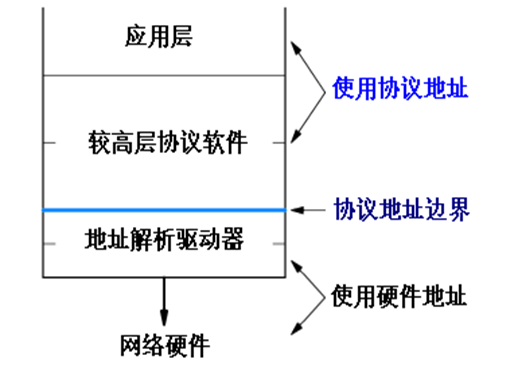
TCP/IP 계층에서 최하층은 물리 네트워크 하드웨어에 대응하고, 그 위 계층은 패킷 수신/발신을 하는 네트워크 인터페이스 소프트웨어에 해당한다. 주소 결정은 이 네트워크 인터페이스 계층의 기능이고, 물리 주소 할당의 디테일을 숨겨 더 고위 계층의 소프트웨어가 바로 프로토콜 주소, 즉 IP 주소를 쓸수 있게 해준다.
그래서 네트워크 인터페이스 계층과 응용층의 경계는 명확하고, 프로토콜 주소를 기반을 모든 상위 계층 소프트웨어, 어플리케이션이 구축된다.
DHCP (动态主机配置协议, Dynamic Host Configuration Protocol)
초기에는 새 호스트의 IP 주소를 얻기 위해 역방향 주소 확인 프로토콜 RARP를 사용해 서버에서 IP 주소를 얻어왔다. 현재는 DHCP가 이 기능을 한다.
관리자는 보통 서버에 고정 주소를, 호스트에 동적 주소를 할당한다. 호스트가 시작되면, DHCP 요청을 브로드캐스트하고, 서버는 DHCP 응답을 보내준다. 온디맨드로 DHCP가 배분하는 주소는 영구적이지 못하고, 유한한 임대 기간이 있다. 기간이 만료되면 호스트는 주소를 해제하거나 DHCP 서버와 다시 쇼부를 쳐서 임대 기간을 연장하는데, 이 통제권은 서버에 있다.
DHCP 최적화
-
패킷 분실/중복 시
이 경우 호스트가 응답을 못받으면 요청을 다시 보내야 한다. 응답이 중복으로 오면 중복으로 온 복사본을 무시한다. -
서버 주소 캐싱
호스트가 DHCP Discover 메세지를 통해 서버를 찾으면 이 주소를 캐싱해두면 임대/갱신 프로세스가 빨라진다 -
동시 다량 요청시 阻塞방지
많은 호스트가 동시에 요청하는걸 막기 위해 각 호스트가 요청 전송/재전송 하기 전 일정 시간을 가지게 해야 한다.
IPv6
IPv4는 확실히 성공했지만, 주소가 고갈되고 있다. 많은 기업들은 어쩔수 없이 NAT를 사용해서 여러 내부 주소를 하나의 공용 IP로 매핑하고 있는데, 이를 사용하면 개인 주소 네트워크의 연결 문제가 있을 수도 있다. 또 보안적 문제등 이유가 있어 개혁이 필요한데 IP를 바꾸면 인터넷 전체가 바뀌는것이기 때문에 어려움이 많다.
IPv6의 특징
-
IPv6은 주소 공간이 방대하고, 계층화가 실현되어 있다. 128비트이고, 개의 주소가 있으며, 세계 인구로 볼때 인당 개의 주소나 분배가 가능하다. 계층화를 통해 인터넷 핵심 백본방에서부터 기업 내부 서브넷까지 다중 서브넷 주소 할당 박싱이 지원된다.
-
헤더부분이 단순화되고, 확장이 유연해진다. 데이터그램의 확장 헤더 부분은 IPv6 데이터그램의 최대 바이트 수에만 제한을 받는다.
-
네트워크 계층의 인증 및 암호화 기능이 있다. IPSec을 전체 지원하여 표준 기반 네트워크 보안 솔루션이 제공된다. 네트워크 계층의 데이터가 암호화되고, IP 메세지 검증이 가능해 보안이 향상된다.
-
QoS가 충족된다. 라우터는 패킷 헤더의 流表示 (Flow label)에 따라 특정 데이터 스트림에 해당하는 패킷들을 식별하여 특정 처리 (실시간 처리 등) 가 가능하다.
-
이동성에 대한 지원이 좋아진다. 자동 구성을 통해 동적으로 물리적 위치의 제한 없이 같은 주소를 유지하며 이동이 가능하다.
-
계층 주소 지정과 라우팅 구조가 효율적으로 변한다. 聚合 (Aggregation)의 원칙을 따라 라우터가 라우팅 테이블에서 하나의 기록으로 서브넷을 표시할 수 있다. 따라서 라우터는 더이상 分段작업을 하지 않고, 발송측 호스트에서 이를 수행하여 라우터의 경로 찾기를 향상시키고 스토리지 오버헤드를 줄인다.
-
브로드캐스팅과 트래픽 제어 향상. 브로드캐스팅 주소가 없는데, 대신 링크된 로컬 범위 내의 모든 노드를 대상으로 하는 그룹 브로드캐스팅 주소가 사용된다. 이는 멀티미디어 응용에 좋은 기회다.
-
자동 구성 기술. DHCP에 대한 개선이라 보면 되는데, 全状态와 无状态주소 배분 방식이 있어 후자에서 온라인 호스트는 로컬 라우터 주소의 前缀와 링크 로컬 주소의 설정을 자동으로 획득한다.
-
인접 노드 상호작용을 위한 새 프로토콜의 등장. 邻居发现协议 (Neighbor Discovery Protocol) 은 IPv6 제어 메세지 (ICMPv6)를 통해 인접 노드의 상호작용 관리를 수행한다. ARP, ICMPv4 라우터 검색 및 리다이렉션 메세지를 훌륭히 대체한다.
IPv6의 장점
- 플러그 앤 플레이 네트워크 연결. 서버, 클라이언트 네트워크 변수 구성 및 스트리밍 시스템의 배포가 단순화되어 사용자 관리 기능이 향상되었다.
- IPSec을 통한 인증 및 암호화 기술. 비디오 암호화 키와 같은 데이터 전송을 위한 조건부 수신 기술이 있다.
- 고성능 전송 네트워크. 간편한 패킷 헤더, 효율적인 라우팅 메커니즘을 네트워크 성능과 패킷 비용이 절감된다.
- QoS. 미디어의 정보, 긴급성과 서비스 범주에 따라 우선등급을 매길 수 있게 되었고, RSVP(Resource Reservation Protocol)의 오버헤드를 크게 줄이는 특수 QoS 도메인이 정의되었다.
- 그룹 브로드캐스팅 기능 강화.
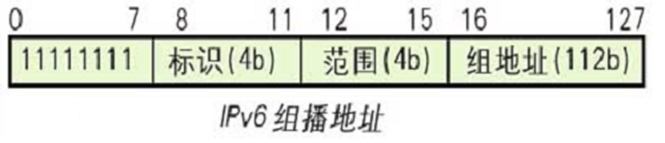
성능이 보장되는 대규모 화상 회의, 고해상도 TV 브로드캐스팅을 위한 고대역폭 어플리케이션 등의 구현이 쉬워진다. 广播가 사라지고, 모든 노드에 보내는 그룹 주소를 지정하면 IPv4의 기능도 유지되고, 로컬 브로드캐스트는 유한 브로드캐스팅 주소로 대체, 범위 필드와 标识를 추가해 임시 그룹 브로드캐스팅 주소가 내부에만 유효하도록 해 충돌을 막는다.
IPv4와 IPv6 호환
아직까진 IPv4가 많이 쓰이니 업그레이드가 필요하다. 새로운 IPv6 프로토콜 기반 네트워크를 IPv6 Island라고 하며, 주소 및 프로토콜 계층 간의 IPv4 네트워크와의 상호 연결을 고려해야 한다.
双栈机制
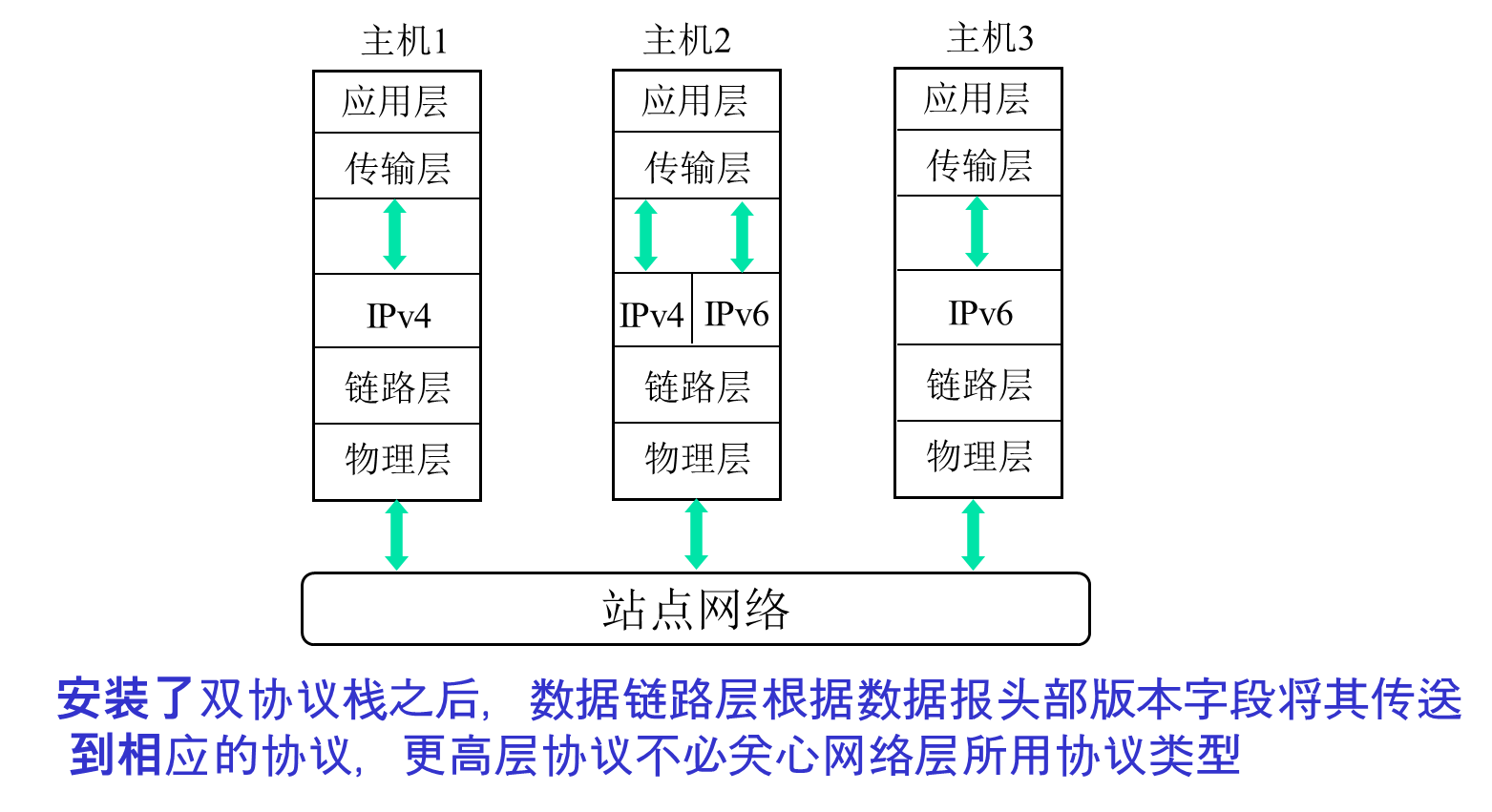
이중 프로토콜 스택을 설치하고, 데이터그램의 헤더에서 버전을 알아내어 해당 스택으로 보내 처리한다. 상위 프로토콜은 네트워크 계층의 프로토콜 유형을 신경쓸 필요가 없다.
隧道机制
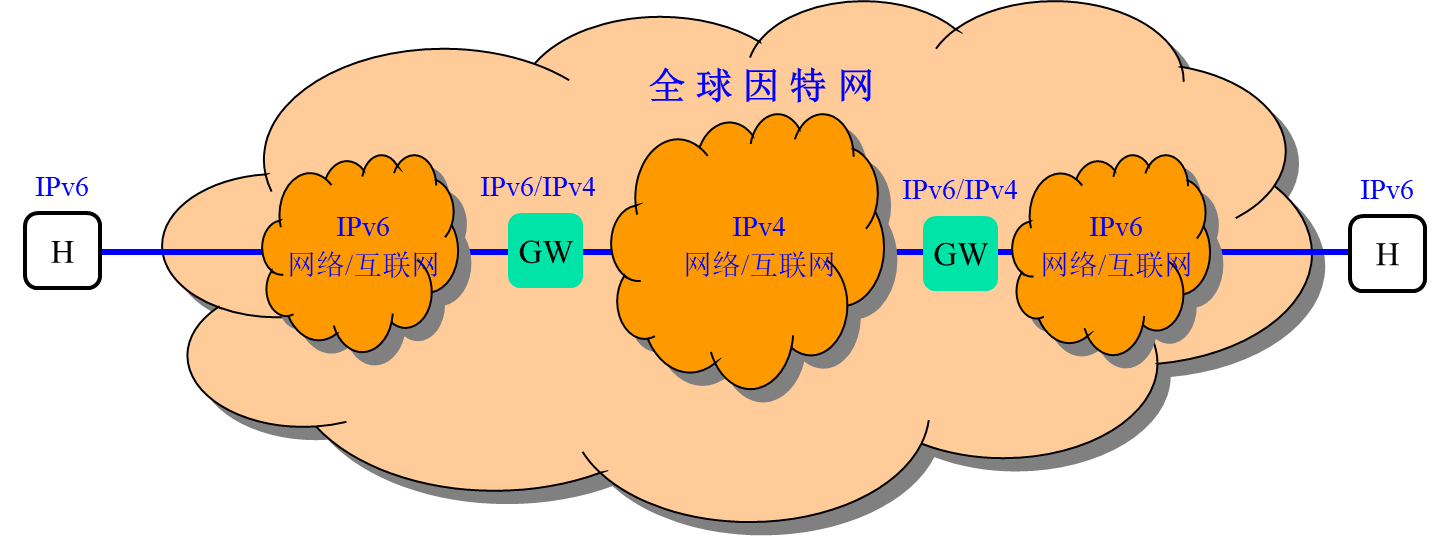
IPv4와 IPv6 섬을 연결하는 라우터/게이트웨이는 두개의 스택을 보유하고 상호간 패킷 패키징을 진행해 전송한다.
转换机制
호스트간에 통신 가능하도록 게이트웨이에서 변환을 진행한다. NAT(network address translator)와 PT(protocol translator)가 필요하고, 이를 NAT-PT 게이트웨이라고 한다. NAT는 IPv4/IPv6의 주소 변환을, PT는 ICMPv4 메시지를 ICMPv6 메시지로 변환하는 등의 헤더 및 의미 번역을 담당한다.
