네트워크 주소 변환
어마한 발전속도 탓에 IP주소의 빠른 소모가 초래되었다. 서브넷과 CIDR개념은 주소 절약에 도움이 되었고, 여러 컴퓨터가 하나의 IP 주소를 공유하는 방법도 생겼다.
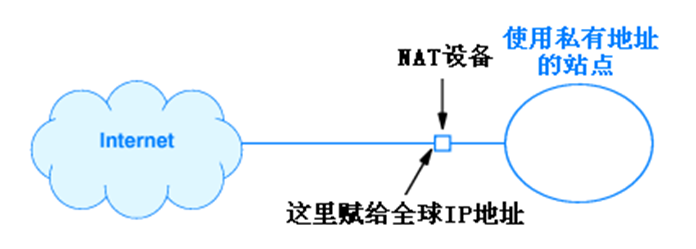
NAT (Network Address Translation) 메커니즘은 하나의 站点내에서 여러 컴퓨터가 단일 IP 주소를 사용하여 인터넷에 접속할 수 있게 하고, 내부와 외부 주소를 구분한다. 로컬에선 각 컴퓨터에 유일한 주소를 할당하고, 외부에선 이 주소를 전세계적으로 인식 가능한 글로벌 주소로 변환한다.
NAT
하드웨어 또는 소프트웨어로 구현될 수 있다. 소프트웨어 구현은 일반적으로 저렴하지만, 저속 네트워크에서만 작동하고, 일부 라우터에는 NAT의 소프트웨어 구현이 포함되어 있다.
주소 변환 기술
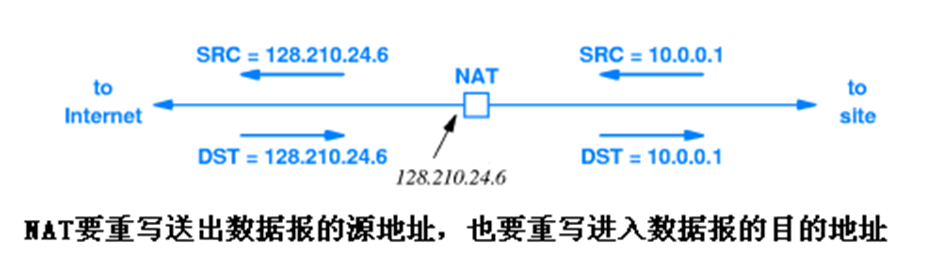
NAT의 목적은 가상 주소 지정 메커니즘을 제공하는 것이다. 이를 위해, NAT를 구현하는 장치는 사이트와 인터넷 간의 경로에 연결되어 작동하며, 사이트로 들어오고 인터넷으로 나가는 모든 데이터그램 헤더 필드를 재작성한다. IP 데이터그램의 주소 필드만 변경하면 체크섬 오류가 발생하기 떄문에, 소스 주소 또는 목적지 주소가 변경될 때마다 NAT는 IP 체크섬을 다시 계산해야 한다.

하나의 사이트 내 여러 컴퓨터가 같은 목적지와 통신하거나, 한 컴퓨터의 여러 응용 프로그램이 다른 목적지와 통신해야 하는 경우, 기본적인 NAT 변환 방법만으로는 충분하지 않다. 네트워크 주소 및 포트 변환(NAPT) 메커니즘은 IP 주소와 프로토콜 포트 번호의 조합을 사용하여 이러한 작업을 수행할 수 있는데, NAPT는 포트 번호를 이해할 수 있으므로, 각 데이터그램을 TCP 연결 또는 "일대일" UDP 세션과 연관시킬 수 있다. 즉, NAPT는 특정 컴퓨터가 아닌 특정 전송 연결에 대해 작동한다.

하나의 PC가 인터넷에 접속하면서 NAT 장치로도 작동할 수 있는 소프트웨어는 쉽게 구할 수 있다. 유닉스에서 slirp, 리눅스에서 Masquerade, 윈도우에서 ICS 등으로 구현되어 있다.
정적, 동적 라우팅

정적 라우팅은 시스템이 시작될 때 라우팅 테이블을 초기화한다. 오류가 감지되지 않는 한 라우팅은 변경되지 않는다.
동적 라우팅은 시스템이 시작될 때 라우팅 테이블을 초기화하고, 라우팅 전파 소프트웨어 (路由传播软件)를 로드하고 실행한다. 다른 컴퓨터의 라우팅 소프트웨어와 상호 작용하여 각 사이트로 가는 최적 경로를 학습하고 라우팅 테이블을 업데이트하고, 지속적으로 변경될 수 있다.
정적 라우팅
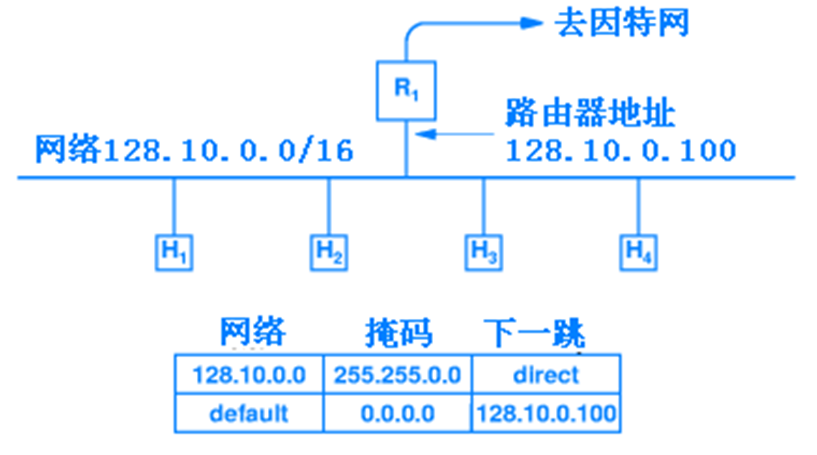
대부분의 호스트는 정적 라우팅을 사용한다. 이는 주로 호스트가 하나의 네트워크 연결과 하나의 라우터만을 사용하여 인터넷에 연결되는 경우에 적합하다. 보통 라우팅 테이블은:
- 직접 연결된 네트워크 → 직접 전달
- 그 외의 경우, 기본(Default) → 기본 라우트
두가지 항목만을 포함한다.
동적 라우팅
대부분의 라우터는 동적 라우팅을 사용한다. 경로가 지속적으로 바뀌기 때문이다. 모든 라우터가 각 가능한 목적지에 대한 정보를 유지하기 위해, 각 라우터 R은 경로 전파 프로토콜을 사용하는 라우팅 소프트웨어를 실행하여 다른 라우터에 접근 가능한 목적지에 대한 정보를 조회하고, R 자체가 접근 가능한 목적지에 대한 정보를 다른 라우터에 통지한다. 라우팅 소프트웨어는 수신된 정보를 사용하여 지역 라우팅 테이블을 지속적으로 업데이트한다.

각 라우터는 자체적으로 접근 가능한 목적지를 다른 라우터에 알린다. 예를 들어, R2가 다운되면 R1의 라우팅 소프트웨어는 Net 3이 더 이상 접근 불가능하다는 것을 감지하고 R1의 라우팅 테이블에서 관련 경로를 제거한다.
인터넷에서의 라우팅
라우터 간에 경로 정보를 교환하는 경로 전파 프로토콜을 사용할 수 있지만, 전 세계 인터넷 전체에서 이를 수행하면 백본 네트워크를 압도할 수 있는 정보 교환량이 발생해서 맛이 간다. 그래서 라우팅 업무량을 제한하기 위해 인터넷은 두 단계 라우팅 계층 구조를 사용한다.
- 인터넷 내의 라우터와 네트워크를 그룹으로 나누고, 각 그룹 내의 모든 라우터가 정보를 교환한다. 각 그룹 내에서 최소한 하나의 라우터가 정보를 수집하고 다른 그룹에 전달한다. 그룹의 크기와 그룹 내 라우팅 프로토콜의 채택은 충분히 유연해야 한다.
자율 시스템 (自治系统)
전 세계 인터넷의 라우터는 그룹으로 나뉘고, 각 그룹은 자율 시스템이라고 불린다. AS 내의 라우터는 서로 경로 정보를 교환한 후 다른 AS로 정보를 전달한다. AS의 규모 선택은 경제적, 기술적 또는 관리적 측면을 포함한 여러 측면을 고려할 수 있다. AS는 단일 기관이 관리하고, IANA에 의해 할당된다. 보통 각 ISP가 하나의 AS를 구성하고, 대규모 ISP는 여러 AS가 있을 수 있다.
인터넷 라우팅 프로토콜
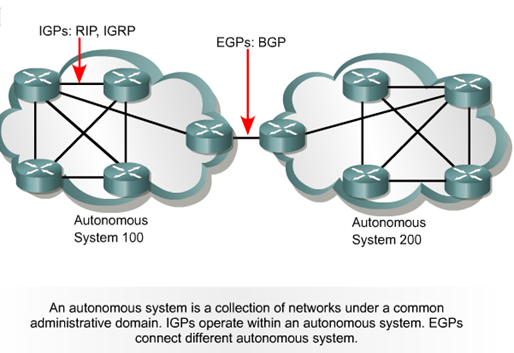
라우팅 선택 프로토콜은 내부 게이트웨이 프로토콜(Interior Gateway Protocols, IGPs)과 외부 게이트웨이 프로토콜(Exterior Gateway Protocols, EGPs)로 나뉜다. EGP는 다른 자율 시스템(AS) 간의 라우팅을 담당하며, 설치와 운영이 복잡하다.
라우팅 메트릭 (度量)
라우팅 소프트웨어는 각 목적지에 대해 가능한 모든 경로를 찾고 "최적"의 경로를 선택한다. "라우팅 메트릭"(routing metric)이란 라우팅 소프트웨어가 경로를 선택할 때 사용하는 경로의 측정치를 말한다. 예를 들어, 인터넷 라우팅에서는 다음과 같은 두 가지 메트릭의 조합을 사용한다.
- 관리 비용: 인위적으로 할당되며, 트래픽이 적합한 경로를 선택하는 데 사용된다.
- 홉 카운트: 중간 네트워크의 수다.
IGP는 라우팅 메트릭을 사용하지만, EGP는 사용하지 않는다. 각 자율 시스템은 라우팅 메트릭을 자유롭게 선택할 수 있다. 지만, 다른 자율 시스템 간의 메트릭이 일치하지 않을 수 있으며, EGP는 다른 메트릭(예: 경로의 홉 수와 처리량)을 의미 있게 비교할 수 없고, 경로만 발견 가능하다.
경로와 데이터 서비스, 알고리즘
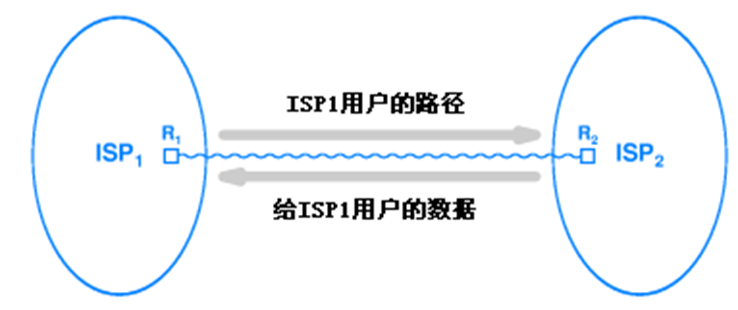
라우터가 자체 AS의 라우팅 정보를 발표한 후에야 다른 AS에서 온 데이터가 들어올 수 있다. 예를 들어, ISP1의 라우터가 사용자 경로를 발표한 후에야 사용자에게 데이터가 도달할 수 있다.
인터넷에서 사용되는 라우팅 선택 방법은 다양하지만, 본질적으로 두 가지 기본 알고리즘으로 분류된다.
- 距离矢量路由算法(Bellman-Ford算法)
- 链路状态路由算法(Link-status)
거리 벡터 라우팅 알고리즘
거리 벡터 라우팅 알고리즘은 제한된 라우팅 정보 교환을 기반으로 하는 라우팅 분류 알고리즘이다. 라우터는 모든 가능한 목적지에 대한 라우팅 테이블을 저장하며, 각 항목에는 목적지까지의 거리 D와 목적지로 가는 첫 번째 라우터(다음 홉)가 포함된다. 각 라우터는 주기적으로 이웃 노드에 라우팅 업데이트 정보를 전송하고, 업데이트 정보를 받은 라우터는 새로운 라우팅 거리 D'와 기존 라우팅 거리 D를 비교하고, D'가 D보다 작으면 기존 것을 대체한다. 위의 논의는 네트워크 토폴로지가 고정된 상태를 가정하고, 네트워크 구조가 변화하는 경우(예: 라우터 고장)에는 알고리즘을 조정해야 한다.
링크 상태 라우팅 알고리즘

위의 과정을 거친다.
루프가 없고, 수렴성이 빠르며 정확한 메트릭 값을 지원하고, 동일 목적지에 대한 다중 경로 지원, 내부/외부 라우팅 구별 가능의 장점이 있다.
프로토콜들

시간상으로 볼때, 위와 같이 라우팅 프로토콜이 진화해왔다.

주요 프로토콜들이다.
RIP
내부 게이트웨이 프로토콜(IGP)의 하나로, 거리 벡터 알고리즘을 사용하여 라우팅 정보를 전파한다. RIP를 실행하는 라우터는 자신이 도달할 수 있는 목적지와 그 거리를 외부에 알리며, 인접한 라우터는 이 정보를 받아 라우팅 테이블을 업데이트한다. 거리는 홉 수로 측정되며, 소스와 목적지 사이의 각 네트워크는 하나의 홉으로 계산되며, 직접 연결된 네트워크도 하나의 홉으로 간주된다. 전송으로 UDP를, 거리 벡터 알고리즘을 사용하여, 브로드캐스트 또는 멀티캐스트로 전송된다.

RIP 패킷 형식이다. 홉 수로 측정된 목적지 및 각 목적지까지의 거리가 포함된 목록이 있다.
RIP의 문제점
거리 벡터 알고리즘에서, 인접 라우터 간에는 주기적으로 양방향으로 정보를 교환한다. 그러나, 교환되는 정보는 부분적일 수 있으며, 각 라우터는 전체 네트워크의 실시간 토폴로지를 정확히 알지 못할 수 있다. RIP의 주요 문제는 라우터가 네트워크의 전체 토폴로지를 알지 못해, 경로 정보의 변화가 라우팅 테이블을 업데이트하는 과정에서 라우팅 루프를 일으킬 수 있다는 것이다. RIP는 소규모 시스템에서는 잘 작동하지만, AS가 커지면 적합하지 않고, 대규모 조직의 라우팅 프로토콜 요구를 충족시키지 못한다. 각 메시지는 목적지와 거리의 완전한 목록을 포함하므로 메시지가 길어지고, 메시지를 처리하는 데 CPU 사이클을 소모하고 지연이 발생한다. 거대하고 복잡한 네트워크에서는 RIP 알고리즘의 새로운 라우팅 계산 수렴 속도가 매우 느리며, 계산하는 동안 네트워크는 전환 상태에 있어 일시적인 혼잡과 루프가 발생할 수 있다.
OSPF (开放最短路径优先协议)
IETF에서 만든 IGP다.

위 기능들을 지원한다. 문제는 오버헤드가 크다. 라우터가 전체 네트워크의 토폴로지 정보를 관리해야 하기 때문이다.
OSPF에 참여하는 라우터는 주기적으로 인접 라우터를 탐색하고 "링크 상태" 메시지를 브로드캐스트한다. 모든 라우터가 브로드캐스트 메시지를 수신하여 자체적으로 로컬 상태 그래프를 업데이트하고, 상태가 변경되면 Dijkstra SPF 알고리즘을 사용하여 최단 경로를 다시 계산해야한다.
OSPF는 계층화된 라우팅을 허용하며, 관리자는 AS 내의 라우터와 네트워크를 영역(areas)이라고 하는 서브셋으로 분류할 수 있다. 영역 경계는 라우터로 나누어지고, OSPF가 허용하는 경우, 주어진 영역 내의 라우터는 통신 전에 ABR(영역 경계 라우터)에서 해당 영역의 정보를 집계하고 정기적으로 링크 상태 메시지를 교환한다. 브로드캐스트를 영역 내로 제한하여 오버헤드를 감소시키며, 이는 대규모 인터네트워크 처리에 더 적합하다.
BGP (边界网关协议)

위가 지원되는 EGP다. 거리 벡터 알고리즘을 사용하여 확장성이 높고 수렴 속도가 느리다. 라우팅 정보 전달 과정에 AS 번호 접두사를 추가하여 라우팅 루프가 발생하지 않도록 한다.
EBGP와 IBGP로 나뉘는데, EBGP는 AS 간 라우팅 선택을 구현하며, IBGP는 주로 AS 경계 라우터가 동일한 AS 내부의 라우터에게 AS 외부의 라우팅 정보를 제공하여 정보를 동기화하는 데 사용된다. BGP 프로토콜을 사용하는 라우터는 전 세계 모든 IP 주소까지의 경로를 알 수 있으며, CIDR을 사용하여 많은 라우팅 엔트리를 줄인다.
네트워크 중계 장비/시스템
네트워크를 서로 연결하기 위해서는 중간 장비(또는 중간 시스템)를 사용해야 하는데, 이를 중계(relay) 장비 또는 시스템이라고 한다.

계층에 따라 위 시스템들이 있다.
게이트웨이
게이트웨이는 초기에는 복잡한 개념이 아니었으며, 단순히 자체 네트워크 또는 네트워크 세그먼트의 출입구를 의미했고, 기본적으로 라우터를 지칭했다.
네트워크의 규모와 기술이 발전함에 따라, 게이트웨이와 라우터의 개념이 명확히 구분되기 시작했다. 라우터는 네트워크 계층의 장비로, 다른 네트워크 간의 데이터 전달 및 라우팅 선택을 담당한다. 게이트웨이는 서로 다른 프로토콜 패밀리를 사용하는 전송 계층 또는 응용 계층 프로그램 간의 데이터 통신 시, 게이트웨이는 프로토콜 변환을 담당한다 (예: 이메일 게이트웨이 등). 게이트웨이는 종종 네트워크 보안을 담당하는 응용 기능(예: 방화벽, VPN 등)과 결합된다.
思考:라우팅 프로토콜들이 특정 통신 프로토콜을 사용하는 이유는?


멀티캐스트 라우팅 기술
IP 멀티캐스팅
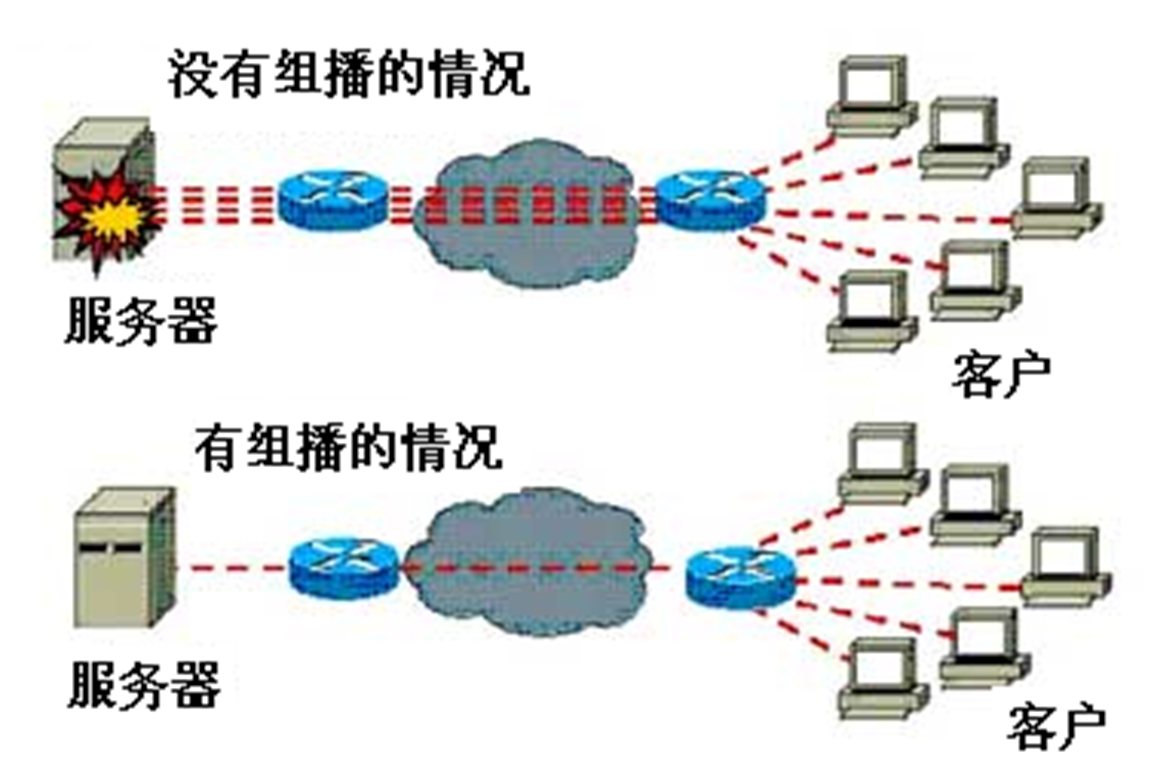
멀티캐스트는 한 호스트가 특정한 여러 수신자에게 메시지를 보내는 방식이다. 구성원은 동적이다.
인터넷에서 스트리밍 미디어, 비디오 회의, 비디오 온 디맨드 등과 같은 멀티미디어 서비스가 중요한 정보 전송의 일부가 되고 있기에, 포인트 투 포인트 전송 방식의 유니캐스트는 "한 지점에서 발송, 다수 지점에서 수신"하는 이러한 서비스의 특성에 적합하지 않다. 이는 서버가 각 수신자에게 동일한 내용의 IP 메시지 복사본을 제공해야 하며, 동시에 네트워크상에서 같은 내용의 메시지가 중복 전송되어 많은 리소스를 차지하기 때문이다. 위처럼 서버가 펑해버릴수도 있다.
멀티캐스트는 IP 메시지가 '호스트 그룹'에 전송되는 것을 의미한다. 이 그룹은 하나 이상의 호스트로 구성되며 단일 IP 주소로 식별된다. 목적지 주소를 제외하고 멀티캐스트 메시지는 일반 메시지와 차이가 없으며, 네트워크는 멀티캐스트 메시지를 최선을 다해 전송하지만 반드시 도착을 보장하지는 않는다. (UDP)
멀티캐스트 주소

호스트 그룹 주소는 '멀티캐스트 주소' 또는 D 클래스 주소로도 알려져 있다. 접두사와 범위는 위와 같다. 어떤 D 클래스 주소로 데이터그램을 보내면, 그 주소의 모든 그룹 구성원이 데이터를 수신한다.

예약된 주소는 각각 위와 같다. D클래스 주소는 동적으로 할당되고 회수되는 일시적 주소고, 각 멀티캐스트 그룹은 동적으로 할당된 하나의 D 클래스 주소와 연관된다. 멀티캐스트 그룹이 멀티캐스팅을 종료하면, 해당 D 클래스 주소는 회수되어 이후의 멀티캐스팅에 사용된다.

IEEE는 할당에 위 원칙을 권장한다.
IP 멀티캐스트 주소와 이더넷 하드웨어 멀티캐스트 주소의 매핑
MAC주소는 48비트로 구성되고, IANA는 MAC 멀티캐스트 주소의 상위 24비트를 소유하고 있다. (0X01005E)
이더넷 멀티캐스트 주소 범위는 0X01005E 000000-0X01005E 7FFFFF다. IP 주소의 마지막 23비트를 MAC 주소의 마지막 23비트로 복사하고, 이 23비트 앞에 있는 비트를 0으로 설정한다.
예를 들어, 멀티캐스트 IP 주소 224.0.1.16은 16진수로 0xE0-00-01-10으로 표시되며, 하위 23비트는 0x00-01-10다. 계산된 MAC 주소는 0x01-00-5E-00-01-10가 된다.
멀티캐스트 그룹 관리
호스트는 언제든지 특정 호스트 그룹에 가입하거나 탈퇴할 권리가 있다. 동시에 여러 호스트 그룹도 가입 가능하며, 자신이 가입하지 않은 호스트 그룹에 데이터를 보낼 수도 있다.
IGMP
IGMP는 멀티캐스트 라우터가 가입된 그룹 구성원을 식별하는 데 도움을 준다. 이 프로토콜은 호스트와 라우터 간의 네트워크에서만 사용되며, 프로토콜은 그룹 구성원을 컴퓨터(프로세스가 아닌)로 정의한다.
멀티캐스트 라우터는 IGMP 프로토콜을 통해 각 포트에 대한 호스트 그룹 구성원 테이블을 유지 관리하며, 정기적으로 테이블에 있는 호스트 그룹의 구성원을 폴링하여 해당 호스트 그룹이 활성 상태인지 확인한다.
IGMP 메시지는 IP 데이터그램 내에 포장되어 전송되고, IGMPv1에는 '호스트 구성원 보고서'와 '호스트 구성원 질의'의 두 가지 메시지 유형이 정의되어 있다.
어떤 호스트가 특정 멀티캐스트 트래픽을 수신하려고 하면, 로컬 멀티캐스트 라우터에 '호스트 구성원 보고서' 메시지를 보내어 수신하고자 하는 멀티캐스트 주소를 알리고, 멀티캐스트 라우터는 '호스트 구성원 보고서' 메시지를 받으면 해당 호스트를 지정된 호스트 그룹에 추가하고 설정된 주기 내에 멀티캐스트 주소 224.0.0.1(모든 멀티캐스트를 지원하는 호스트를 대표)에 '호스트 구성원 질의' 메시지를 보낸다.
IGMPv1에서는 어떤 호스트가 특정 멀티캐스트 그룹을 떠날 때, 그것은 어떤 멀티캐스트 라우터에도 알리지 않고 자연스럽게 탈퇴한다. 멀티캐스트 라우터는 주기적으로(예: 120초) IP 서브넷 내의 모든 멀티캐스트 그룹에 질의를 보내고, 만약 어떤 멀티캐스트 그룹에 IP 서브넷 내에 더 이상 구성원이 없으면 사실을 확인한 후 해당 멀티캐스트 그룹 데이터를 서브넷에서 더 이상 전송하지 않으며, 동시에 라우팅 정보 교환을 통해 해당 멀티캐스트 라우터를 특정 멀티캐스트 그룹 할당 트리에서 제거한다.
멀티캐스트 프로토콜의 데이터그램 전달
멀티캐스트 프로토콜은 동적인 그룹 멤버십과 익명 발신자에 대한 지원을 허용하며, 멀티캐스트 라우팅 프로토콜은 빠르고 지속적인 라우팅 변경을 수행할 수 있어야 한다. 예를 들어, 새 멤버가 가입할 때 멀티캐스트 라우팅 소프트웨어는 먼저 다른 그룹 멤버를 찾아 최적의 전달 경로 구조를 만들어야 한다.

위 세가지 방법으로 데이터그램을 전달한다.
확산 및 가지치기
- 도착하는 데이터그램에 대해 라우터는 하드웨어 멀티캐스팅 기능을 사용하여 직접 연결된 모든 네트워크에 보낸다 (지속적인 확산).
- 루프 형성을 방지하기 위해 Reverse Path Broadcasting(RPB) 기술을 사용한다.
- 확산하는 동안 라우터 간에 그룹 멤버 정보를 교환한다.
- 어떤 라우터가 특정 네트워크에 해당 그룹의 호스트가 없다는 것을 발견하면, 그 네트워크로 멀티캐스트 데이터그램을 더 이상 전송하지 않는다. (가지치기)
이 방법은 소규모 그룹에 적합하며, 멤버들이 인접한 LAN에 연결되어 있을 때 사용된다.
설정 및 터널링
멤버들의 지리적 위치가 분산되어 있는 경우에 적합하다.
- 각 사이트의 라우터는 구성을 통해 다른 사이트의 정보를 알고 있다.
- 멀티캐스트 데이터그램이 라우터에 도착하면 하드웨어 멀티캐스팅 기능을 이용하여 직접 연결된 LAN에 데이터그램을 보낸다.
- 그 다음 자체 구성 테이블을 조회하여 어떤 사이트로 더 전송해야 하는지 결정한다. 라우터는 'IP-in-IP' 터널링 방법을 사용하여 다른 사이트로 멀티캐스트 데이터그램의 복사본을 전송한다.
코어 기반 발견
"소규모에서 대규모" 그룹으로의 전환 상황에 대한 해결책을 제공한다.
- 멀티캐스트 라우팅 프로토콜은 각 멀티캐스트 그룹에 대해 코어라는 단일 유니캐스트 주소를 지정한다.
- 라우터 R1에서 어떤 그룹으로 전송할 때, 그룹의 코어 주소로 유니캐스트 데이터그램을 보내는 터널링 방법을 사용한다. 데이터그램이 인터넷을 통과할 때, 각 라우터는 그 내용을 검사한다.
- 유니캐스트 데이터그램이 지정된 그룹의 라우터 R2에 도착하면, 그것은 외부 캡슐화를 제거하고 내부의 멀티캐스트 메시지를 처리한다.
- 데이터그램의 목적지 주소가 그룹 주소와 일치하면, 해당 그룹 멤버에게 전송한다.
이 외에도 DVMRP, IETF, CBT등 프로토콜들이 제안되었다.
멀티캐스트 백본 MBONE
멀티캐스트 규격은 1989년에 발표되었지만, 그 사용은 제한되어 있다. 인터넷상의 라우터는 모두 멀티캐스트 기능을 갖추고 있지 않기에, 연구자들은 기존 상황에서 멀티캐스트 프로토콜의 개발과 테스트를 위해 멀티캐스트 백본(Multicast Backbone, Mbone)을 구축했다.
Mbone은 몇 대륙에 걸쳐 있는 실험적인 가상 네트워크로, 자발적인 협력으로 완성되었다. 상호 연결된 서브넷과 라우터의 집합으로 구성되어 있으며, 이들은 IP 멀티캐스트 트래픽을 전송하는 데 지원한다. Mbone은 터널링 기술을 사용하여 인터넷상의 멀티캐스트 기능이 없는 라우터를 우회하여 멀티캐스트 패킷의 라우팅을 지원하면서 다른 인터넷 트래픽에 영향을 주지 않는다.
대화형 IP 멀티캐스트
전통적인 IP 멀티캐스트의 가장 큰 단점은 모든 사용자가 수동적 수신자라는 것이다. 즉, IP 멀티캐스트는 사용자가 상호 작용에 적극적으로 참여할 수 있는 내장된 메커니즘을 제공하지 않는다.
H.323 국제 표준에서 회의 참가자 관리, SAP(Session Announcement Protocol), SDP(Session Description Protocol), RTCP(Real-time Transport Control Protocol) 등의 프로토콜을 사용하면 전통적인 IP 멀티캐스트 기술에 대화 기능을 부여할 수 있다.
도메인 이름 해석과 DNS
도메인 이름 시스템 (DNS)
IP 주소를 직접 사용하는 것은 불편하다. 도메인 이름 시스템(DNS)은 컴퓨터의 도메인 이름과 해당하는 IP 주소 간의 자동 매핑을 제공한다. 각 컴퓨터 도메인 이름은 점으로 구분된 문자와 숫자 필드의 문자열로, 계층적이다.
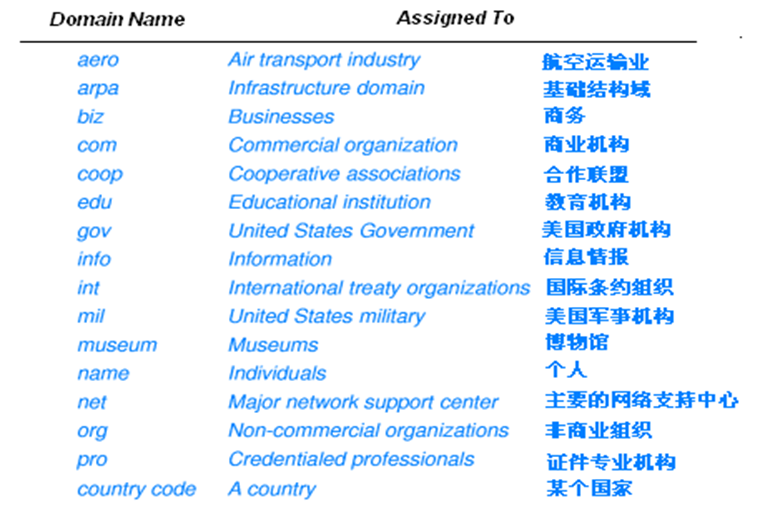
도메인 이름 중 세그먼트의 수에는 표준이 없다. 왜냐하면 각 조직은 자체 계층을 어떻게 정의할지 자유롭게 선택할 수 있기 때문이다. 도메인 이름 시스템은 가장 중요한 세그먼트의 값만을 규정하며, 이를 위 사진의 DNS의 최상위 도메인(TLD, Top-level Domain)이라고 한다.
DNS 클라이언트/서버 모델
도메인 이름 시스템의 주요 특징 중 하나는 자치성이다. 시스템 설계상 각 조직이 중앙 기관에 통지하지 않고도 컴퓨터에 도메인 이름을 할당하거나 변경할 수 있도록 허용한다. 그 덕분에 내가 웹 앱을 배포할때도 AWS Route 53으로 등록 할 수 있나보다. 특정 접미사를 사용하여 모든 도메인 이름을 제어함으로써 조직의 자치성을 돕는 이름 체계를 통해 이를 실현한다.
계층적인 도메인 이름 외에도, DNS는 클라이언트/서버 상호작용을 통해 자치성을 지원합니다. 본질적으로, 전체 도메인 이름 시스템은 큰 분산 데이터베이스로 작동한다. 애플리케이션이 도메인 이름을 IP 주소로 변환할 필요가 있을 때마다, 그 애플리케이션은 도메인 이름 시스템의 클라이언트가 된다. 이 클라이언트는 변환할 도메인 이름을 DNS 요청 메시지에 넣고 DNS 서버로 보낸다.
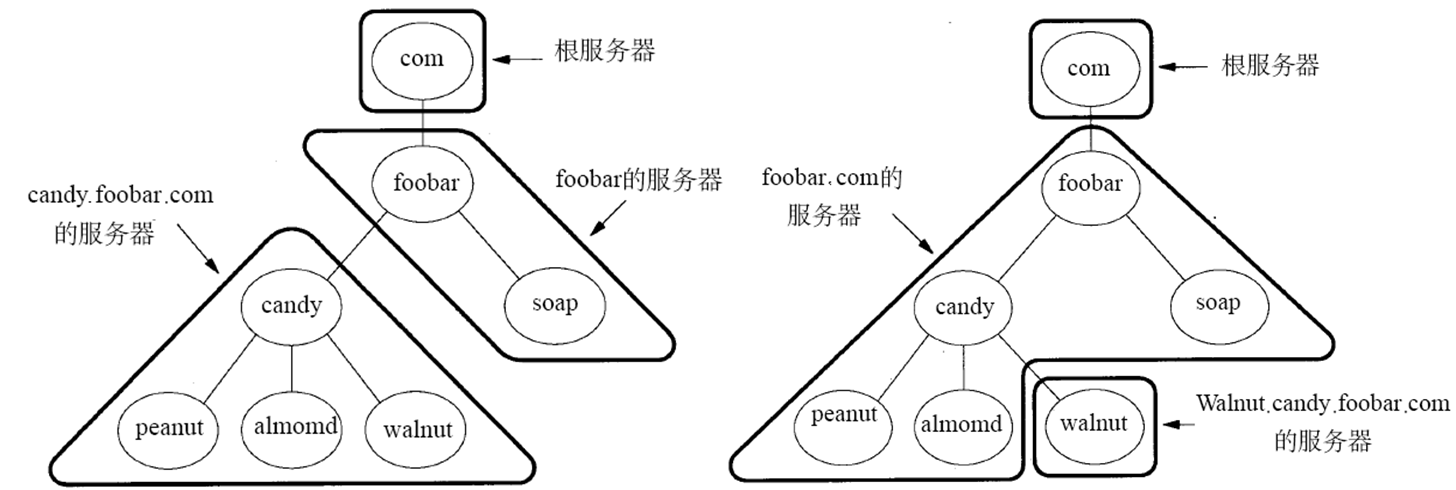
DNS 서버는 계층적으로 배열되어 있으며, 이 계층은 도메인 이름의 계층에 해당한다. 각 서버는 도메인 이름 체계의 일부분에 대한 권한을 가지고 있고, 루트 서버(root server)는 이 계층 구조의 정점에 위치한다.
접근 지역성
LAN의 접근 지역성 원칙(locality of reference principle)은 도메인 이름 시스템에도 적용되며, 지역성 원칙을 두 가지 측면에서 준수한다.
- 사용자는 원격 컴퓨터의 도메인 이름보다 로컬 컴퓨터의 도메인 이름을 더 자주 조회한다.
- 사용자는 종종 동일한 그룹의 도메인 이름을 반복해서 조회한다.
도메인 이름 해석
모든 도메인 이름 서버는 하나의 통합된 시스템을 형성하여 연결된다. 각 서버는 루트 서버를 찾는 방법과 더 낮은 계층의 도메인 이름에 대한 권한을 가진 서버를 찾는 방법을 알고 있다.
도메인 이름을 해당 IP 주소로 변환하는 과정을 도메인 이름 해석(name resolution)이라고 하며, 이름을 주소로 해석하는 소프트웨어를 도메인 이름 해석기(name resolver) 또는 단순히 해석기 소프트웨어라고 한다. 해석은 기본적으로 위에서 아래로 진행된다.
해석 패턴
- 클라이언트가 인터넷상의 특정 호스트에 접근할 필요가 있을 때, 먼저 로컬 DNS 서버에 상대방의 IP 주소를 조회한다. 보통 로컬 DNS 서버는 다른 DNS 서버에 조회를 계속하여 접근해야 할 호스트의 IP 주소를 해석한다. 재귀 해석이 자주 쓰인다.
- 클라이언트는 DNS 조회 메시지를 로컬 DNS 서버에 보내 도메인 이름 N을 해석하도록 요청한다.
- 만약 로컬 DNS가 도메인 이름 N의 권한자라면, DNS 응답 메세지를 회신한다.
- 도메인 이름 N의 권한자 서버를 안다면, 해당 서버에 DNS 조회 메시지를 보낸다.
- 위 경우가 다 아니면 루트 서버에 조회 메시지를 보내고, 위에서 아래로 해석을 진행한다.
- N의 해석된 주소를 포함한 DNS 응답 메시지를 받으면, 그 주소를 캐시해둔다.
- 최종적으로 클라이언트에게 DNS 응답 메시지를 보낸다.
예시

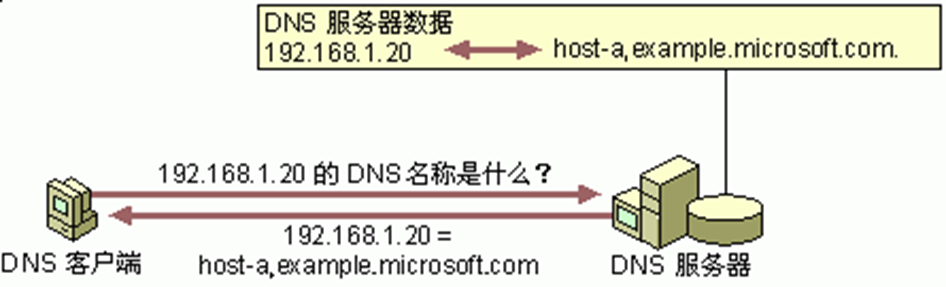
cs02.cmu.edu 이라는 컴퓨터가 mail.pku.edu.cn 을 해석하고자 한다.
- 먼저 로컬 DNS 서버(예: dns.cmu.edu)에 '해석' 요청을 보낸다. 만약 로컬 DNS 서버가 mail.pku.edu.cn의 IP 주소를 알고 있으면 바로 IP 주소를 반환하고, 모르지만 pku.edu.cn의 도메인 서버를 알고 있다면 해당 서버에 DNS 조회 메시지를 보내고, 둘다 아니라면:
- 루트 도메인 서버에 mail.pku.edu.cn의 주소를 조회한다. 루트 도메인 서버는 cn 도메인 서버의 IP 주소를 반환한다.
- 로컬 DNS는 cn 도메인 서버에 동일한 질문을 조회하고, edu.cn 도메인 서버의 IP 주소를 반환받는다.
- 로컬 DNS는 edu.cn 도메인 서버로부터 pku.edu.cn 도메인 서버의 IP 주소를 획득한다.
- 로컬 DNS 시스템은 pku.edu.cn 도메인 서버로부터 mail.pku.edu.cn의 IP 주소를 얻는다.
- 만약 모든 DNS 서버에서 찾지 못하면, 오류 메시지를 반환한다.
정방향, 역방향 조회
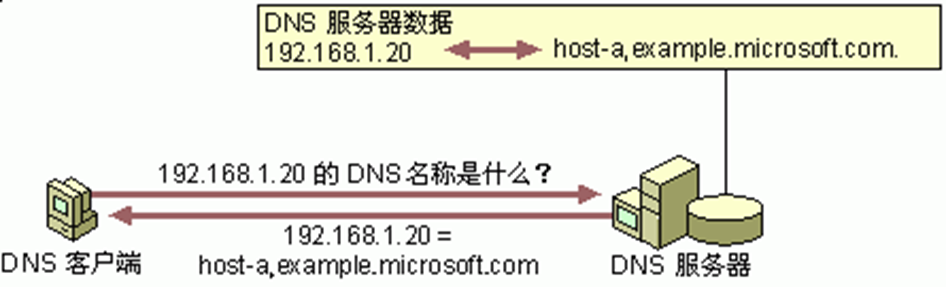
정방향 조회는 다른 컴퓨터의 DNS 이름을 검색하는 기반으로, 주소 리소스 레코드에 저장된 것을 기반으로 한다. 역방향 조회는 클라이언트가 이름 쿼리 중에 알려진 IP 주소를 사용하고 그 주소에 따라 컴퓨터 이름을 찾을 수 있게 한다.
DNS 성능 최적화
최적화되지 않은 상태에서 루트 서버의 통신량은 좀 많다. 지역성 원칙에 따르면 주어진 컴퓨터가 동일한 요청을 반복적으로 발생시킬 확률이 높기에, 사용자가 원격 컴퓨터의 도메인 이름을 입력했다면, 나중에 같은 도메인 이름을 다시 언급할 확률이 높다.
복제
루트 서버는 복제되어 전 세계에 많은 복사본이 존재한다. 새로운 사이트(네트워크)가 인터넷에 연결될 때, 해당 사이트는 로컬 DNS 서버에 루트 서버 테이블을 구성한다. 해당 사이트의 서버는 주어진 시간 동안 가장 빠르게 응답하는 루트 서버를 사용한다.
캐싱
캐싱은 복제보다 더 중요하다.
각 서버는 도메인 이름 캐시를 유지한다. 새로운 도메인 이름을 조회할 때마다, 서버는 해당 바인딩의 복사본을 캐시에 저장한다. 서버는 다른 서버와 통신하여 바인딩 정보를 요청하기 전에 항상 캐시를 확인하고, 캐시에 이미 답이 포함되어 있으면 서버는 이 답을 사용하여 응답을 생성한다.
주소 매핑이 만료되지 않도록, 캐시에 있는 매핑 정보는 모두 수명 시간(TTL)를 가지고, 만료되면 무효화한다.
다중 유형
DNS 데이터베이스의 각 항목은 세 가지 요소를 포함한다: 도메인 이름, 레코드 유형, 값. 해석기가 도메인 이름을 찾을 때, 원하는 유형을 명시해야 하며, DNS 서버는 해당 유형에 맞는 항목만 반환한다. DNS의 유형 체계는 관리자가 단일 이름을 여러 목적으로 사용할 수 있게 해주므로 큰 편리함을 제공한다.
어떤 컴퓨터로 이메일을 보낼 수 있지만 ping이나 traceroute로 통신하려고 하면 "컴퓨터가 존재하지 않음"이라는 메시지가 나타날 수 있다. 이러한 명백한 불일치는 이메일의 DNS 요청 유형과 다른 애플리케이션의 요청 유형이 다르기 때문이다.
약어와 DNS
사용자는 원격 컴퓨터의 도메인 이름보다 로컬 컴퓨터의 도메인 이름을 더 많이 사용하는 경향이 있기 때문에, 로컬 도메인 이름의 약어를 사용하면 편리하다.
예를 들어, Foobar 회사는 사용자가 도메인 이름을 입력할 때 foobar.com 접미사를 생략할 수 있도록 허용할 수 있다. 이러한 약어의 결과로 사용자가 venus.walnut.candy 라는 도메인 이름을 입력하여 candy 부서의 walnut 분사의 venus 컴퓨터를 나타낼 수 있다.
하지만 도메인 이름 서버는 약어를 인식하지 못하고, 서버는 전체 이름에만 반응한다. 약어를 처리하기 위해, 예를 들어, Foobar의 각 해석기는 도메인 이름을 한 번은 원래 이름으로, 다른 한 번은 foobar.com 접미사를 추가한 이름으로 두번 조회 할 수 있다.
숙제: 멀티캐스트 프로토콜 선택

PIM-SM (Protocol Independent Multicast - Sparse Mode): PIM-SM은 스파스 모드로 동작하며, 멤버십이 상대적으로 희소한 대규모 네트워크에 적합합니다. 멀티캐스트 그룹 멤버가 넓은 지역에 걸쳐 흩어져 있을 때 좋습니다.
세 학교가 멀리 떨어져 있고 멀티캐스트 그룹 멤버십이 비교적 안정적이라면 PIM-SM을 사용하는 것이 가장 적합할 수 있습니다. PIM-SM은 효율적인 트리 구조를 사용하여 멀티캐스트 데이터를 전송하고, 멤버십이 드문드문 있는 네트워크에서 데이터 전송을 최적화합니다. 또한, PIM-SM은 Rendezvous Point(RP)를 사용하여 멀티캐스트 소스와 리시버 사이의 경로를 관리하므로, 멀티캐스트 데이터가 그룹의 모든 멤버에게 효과적으로 전달될 수 있습니다.
