웹 브라우저
HTML 문서와 그림, 멀티미디어 파일 등 WWW를 기반으로 한 인터넷 컨텐츠 검색 및 열람을 위한 응용프로그램을 웹 브라우저라고 합니다.
브라우저의 구성요소
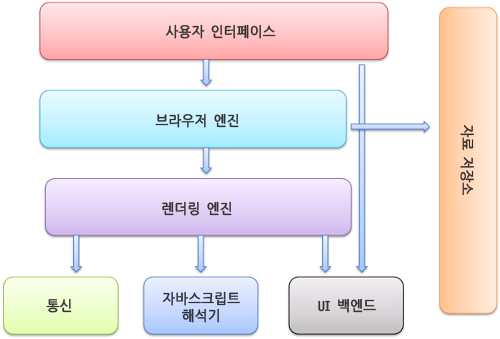
사용자 인터페이스
- 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등을 포함합니다.
브라우저 엔진
- 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어합니다.
- HTML 문서와 리소스를 시각 표현으로 변환시키고, 문서 객체 모델(DOM) 자료구조를 구현합니다.
- 브라우저 엔진과 렌더링 엔진을 묶어 브라우저 엔진으로 부르기도 합니다.
- 웹 브라우저마다 전용 브라우저 엔진을 사용합니다.
- Gecko : Firefox
- Webkit : Safari
- Blink : Chrome, Opera
- Trident : Outlook Express, Microsoft Outlook
렌더링 엔진
- 요청한 콘텐츠를 표시합니다.
- HTML과 CSS를 파싱해 화면에 표현합니다.
통신
- HTTP 요청과 같은 네트워크 호출에 사용됩니다.
UI 벡엔드
- 콤보박스, 윈도우 등 UI를 그려주는 역할을 합니다.
- 여러 OS의 API들을 사용할 수 있습니다.
자바스크립트 해석기
- Javascript 코드를 해석하고 실행하는 해석기입니다.
- 자바스크립트 엔진이라고 불립니다.
- 웹 브라우저마다 전용 자바스크립트 엔진이 탑재되어 있습니다.
- Rhino : Java로 개발됨
- SpiderMonkey : 최초의 JS엔진, Firefox
- V8 : Chrome
- JavascriptCore : Safari, React Native App
- Chakra : Microsoft Edge
자료 저장소
- 브라우저의 쿠키, 캐시, 서비스워커, 로컬 스토리지 등을 저장합니다.
브라우저의 동작 원리
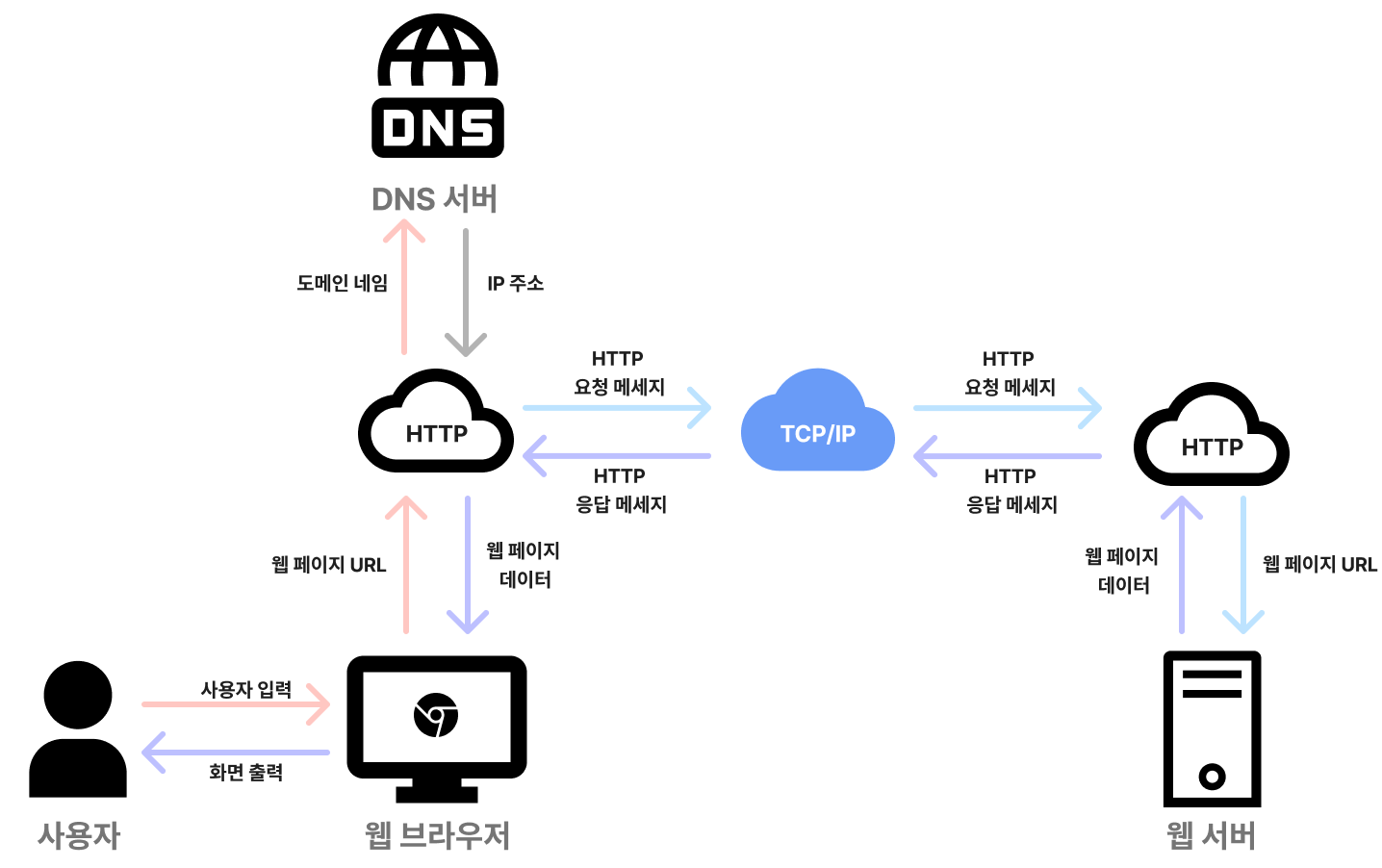
1. 사용자가 브라우저를 통해 찾고 싶은 웹 페이지의 URL 주소를 입력합니다.
2. DNS서버를 통해 사용자가 입력한 도메인 네임에 일치하는 IP주소를 찾아 URL과 함께 전달합니다.
3. IP주소와 URL을 가지고 HTTP 요청 메시지를 생성합니다.
4. TCP/IP 프로토콜로 해당 IP 컴퓨터로 HTTP 요청을 전송하고, 도착한 요청은 HTTP 프로토콜을 이용해 웹 페이지 URL 정보로 변환됩니다.
5. 서버는 요청한 데이터를 찾은 뒤, HTTP 응답 메시지를 생성합니다. 이 메시지는 TCP/IP 프로토콜을 통해 사용자 컴퓨터에 전송됩니다. 전송된 메시지는 HTTP 프로토콜을 통해 웹 페이지 데이터로 변환됩니다.
6. 변환된 데이터가 웹 브라우저에 출력되어 사용자가 볼 수 있게 됩니다.
브라우저 렌더링 과정
1. DOM 트리 구축
구문분석기는 토큰화와 트리생성을 통해 HTML을 처리하여 DOM 트리를 만듭니다. DOM 노드의 개수가 많아질수록 DOM 트리를 만드는데 더 오랜 시간이 걸립니다.
+ 프리로드 스캐너
브라우저의 메인 쓰레드가 DOM트리를 만드는 동안, 프리로드 스캐너는 CSS, JS, 웹 폰트와 같은 우선순위가 높은 자원을 요청합니다. 구문분석기가 외부 자원에 대한 참조를 직접 요청하지 않기 때문에 구문분석기가 자료를 기다리지 않아도 됩니다.
2. CSSOM 트리 생성
CSS를 처리하고 CSSOM을 만듭니다. DOM트리와 비슷한 구조를 가졌지만 DOM과는 독립적인 자료구조입니다. CSS 선택기에 기반해 부모, 자식, 형제 노드를 만들어냅니다.
+ Javascript 컴파일
CSSOM이 생성되는 동안 프리로드 스캐너가 JS파일을 다운로드합니다. 다운로드된 JS파일은 해석, 컴파일, 구문분석 및 실행됩니다.
3. 렌더링 트리 생성
DOM트리와 CSSOM을 합성해 렌더링 트리를 생성합니다. 렌더링 트리는 DOM 트리의 루트부터 시작하여 눈에 보이는 노드를 순회하며 만들어집니다.
4. 레이아웃
렌더링 트리를 기반으로 각 노드의 도형값을 계산합니다.
- 레이아웃 : 렌더 트리에 있는 모든 노드의 너비, 높이, 위치를 결정하는 프로세스
- 리플로우 : 레이아웃 이후에 있는 페이지의 일부분이나 전체 문서에 대한 크기나 위치에 대한 결정
