서론
필자는 현재 논문 검색 및 사용자 pdf 관련해서 vectorization을 통해 rag 챗봇을 만드는 프로젝트를 진행중이다. 그래서 weaviate를 사용하기로 했고 공식문서롤 봐도봐도 기억이 리셋돼서 장기메모리에 남기 위해 글을 작성해보겠다.
그리고 python client v4로 업데이트되어 사용할 수 있는 소스가 공식문서를 참고해야되기에 다른 개발인들에게 도움이 될까 해서 작성해본다.
모든 문서는 python 기준으로 작성되었다.
collection 생성
컬렉션을 생성하기 위한 가장 기초적인 코드는 다음과 같다.
from weaviate.classes.config import Property, DataType
client.collections.create(
"Article",
vectorizer_config=[
# Set a named vector
Configure.NamedVectors.text2vec_cohere( # Use the "text2vec-cohere" vectorizer
name="title", source_properties=["title"] # Set the source property(ies)
),
# Set another named vector
Configure.NamedVectors.text2vec_openai( # Use the "text2vec-openai" vectorizer
name="body", source_properties=["body"] # Set the source property(ies)
),
# Set another named vector
Configure.NamedVectors.text2vec_openai( # Use the "text2vec-openai" vectorizer
name="title_country", source_properties=["title", "country"] # Set the source property(ies)
)
],
properties=[
Property(name="title", data_type=DataType.TEXT),
Property(name="body", data_type=DataType.TEXT),
]
)이름과 데이터 타입을 properties에 작성하면 된다.
그리고 사용하는 vectorizer를 사용가능하고 사용할 예정인 모듈을 적으면 된다. 원본 소스에 해당되는 속성들과 그것에 대한 이름을 적으면 된다.
사용가능한 모듈
(굉장히 다양하게 지원중이다. 필자는 자본 문제로 인해 허깅페이스 모듈을 사용할 것이다...)
만일 python v3로 사용한다면 아래와 같은 코드로 생성해줄 수 있다.
client.collections.create_from_dict({
"class": "Article",
"properties": [
{
"name": "title",
"dataType": ["text"],
},
{
"name": "body",
"dataType": ["text"],
},
],
})근데 v4로 업데이트 된 만큼 duplicated code가 될 확률이 높아서 v3보다는 v4 코드에 익숙해지는 게 좋을 것 같다.
Property 자세히
파라미터로 속성 이름을 벡터화할지 여부와 속성을 벡터화에 포함할지 여부 및 토큰화 유형을 선택하도록 각 속성을 구성할 수 있다.
from weaviate.classes.config import Configure, Property, DataType, Tokenization
client.collections.create(
"Article",
vectorizer_config=Configure.Vectorizer.text2vec_huggingface(),
properties=[
Property(
name="title",
data_type=DataType.TEXT,
vectorize_property_name=True, # Use "title" as part of the value to vectorize
tokenization=Tokenization.LOWERCASE # Use "lowecase" tokenization
),
Property(
name="body",
data_type=DataType.TEXT,
skip_vectorization=True, # Don't vectorize this property
tokenization=Tokenization.WHITESPACE # Use "whitespace" tokenization
),
]
)skip_vectorization 을 설정하지 않으면 기본적으로 벡터화가 수행된다고 하니(TEXT 속성만) 벡터화를 하지 않은 것에 대해서는 설정을 해주자. (또는 vectorizer를 none으로 설정하기)
vector indexing
weaviate는 벡터 검색을 통해 유사한 데이터를 찾는 기능을 제공하는데 이를 위해 벡터를 효율적으로 저장하고 검색할 수 있는 벡터 인덱스를 사용한다. 이는 고차원 공간에서 벡터 간의 유사성을 빠르게 계산할 수 있도록 도와준다.
기본적으로 HNSW(Hierarchical Navigable Small World) 그래프를 사용해 벡터 인덱싱을 수행한다. 이외에도 다양한 방법론이 존재한다. 또 거리를 계산하는 알고리즘을 바꿀 수 있다.(디폴트는 cosine이다. 텍스트 데이터 즉 문서나 문장의 유사성 비교에 적합하다.)
from weaviate.classes.config import Configure, Property, DataType
client.collections.create(
"Article",
# Additional configuration not shown
vector_index_config=Configure.VectorIndex.flat(
quantizer=Configure.VectorIndex.Quantizer.bq(
rescore_limit=200, # 검색결과를 재평가하는 최대 벡터 수
cache=True # 벡터 양자화 캐시 사용 여부
),
vector_cache_max_objects=100000 # 벡터 캐시에 저장할 수 있는 최대 객체 수
),
)
# 또는
client.collections.create(
"Article",
vector_index_config=Configure.VectorIndex.hnsw(
distance_metric=VectorDistances.COSINE
),
)
코드를 보면 VectorIndex의 방법이 두가지로 나온다. 위에 링크를 임베드해놨지만 간단히 방법에 대해서 비교한 표는 아래와 같다.

그리고 파라미터에 대해서 짧게 설명하자면
Configure.VectorIndex.flat: 기본적인 평면 벡터 인덱스를 사용
quantizer: 벡터 양자화를 사용하여 벡터 데이터를 압축하고 검색 성능을 최적화
rescore_limit: 검색 결과를 재평가하는 최대 벡터 수를 설정하여 정확성을 높임
cache: 벡터 양자화 캐시를 사용하여 검색 속도를 높임
vector_cache_max_objects: 벡터 캐시에 저장할 수 있는 최대 객체 수를 설정하여 검색 성능을 최적화
그래서 필자의 프로젝트의 경우 소규모의 데이터셋과 높은 정확도가 요구되기에 벡터 인덱스를 사용하는 경우 Flat이 좋을 것이라 판단되었다. 그러나 데이터셋이 커질수록 검색 성능이 급격히 저하될 수 있으니 조심하자. 사용하지 않을 경우 벡터간의 유사성 계산이 비효율적이거나 검색속도가 상대적으로 느리다
후에 적용하지 않고 검색하는 속도와 적용한 후의 속도를 비교한 포스팅을 업로드 하겠다.
더불어 캐시 기능까지 있다니...! redis를 사용해야되나.. 생각중이였는데 참 다행이다 ...
역색인 설정
그리고 inverted_index_config를 설정할 수 있다.
from weaviate.classes.config import Configure, Property, DataType
client.collections.create(
"Article",
# Additional settings not shown
properties=[ # properties configuration is optional
Property(
name="title",
data_type=DataType.TEXT,
index_filterable=True,
index_searchable=True,
),
],
inverted_index_config=Configure.inverted_index( # Optional
bm25_b=0.7,
bm25_k1=1.25,
index_null_state=True,
index_property_length=True,
index_timestamps=True
)
)역색인 설정에 대해서 정의할 수 있는데 이는 텍스트 검색 성능을 향상시키기 위해 사용된다.
파라미터에 대해서 간단히 설명하면 아래와 같다.
bm25_b: BM25 알고리즘의 b 매개변수이다. 문서 길이에 대한 민감도를 조절하고 기본값은 0.75이다.
bm25_k1: BM25 알고리즘의 k1 매개변수이다. 용어 빈도에 대한 민감도를 조절한다. 기본값은 1.2이다.
index_null_state: True로 설정하면, null 상태인 속성도 인덱싱한다.
index_property_length: True로 설정하면, 속성의 길이를 인덱싱한다.
index_timestamps: True로 설정하면, 타임스탬프를 인덱싱한다.
bm25알고리즘은 간단히 설명하자면 TF-IDF의 개선된 버전이다.
불용어 설정
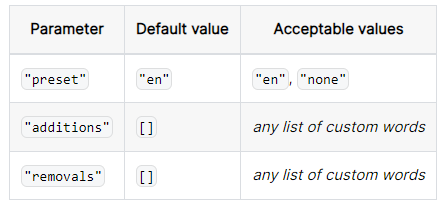
텍스트 속성의 경우 매우 일반적인 단어 즉 불용어를 포함할 수 있다. 그래서 이 단어들을 무시하면 중지 단어가 포함된 쿼리가 쿼리에서 자동으로 제거될 수 있기에 속도가 빨라진다.
"invertedIndexConfig": {
"stopwords": {
"preset": "en",
"additions": ["star", "nebula"],
"removals": ["a", "the"]
}
}en을 사용하여 불용어를 설정할 수 있고 none을 사용해 사용자 정의 불용어 목록을 설정할 수 있다.
generative module설정
RAG를 위해서 생성형 모듈을 설정해줄 수 있다.
from weaviate.classes.config import Configure, Property, DataType
client.collections.create(
"Article",
vectorizer_config=Configure.Vectorizer.text2vec_openai(),
generative_config=Configure.Generative.openai(
model="gpt-4"
),
)이 코드는 벡터라이저와 생성형 모듈을 openai로 설정해준 것이다. 사용가능 모듈은 위 링크에 나와있다.
collection 관련 설정
articles = client.collections.get("Article")
articles_config = articles.config.get()
response = client.collections.list_all(simple=False)
# delete collection "Article" - THIS WILL DELETE THE COLLECTION AND ALL ITS DATA
client.collections.delete("Article") # Replace with your collection name
from weaviate.classes.config import Property, DataType
articles = client.collections.get("Article")
articles.config.add_property(
Property(
name="onHomepage",
data_type=DataType.BOOL
)
)컬렉션 조회를 위해서 위처럼 단일 컬렉션을 조회할 수 있고 모든 컬렉션에 대해서 조회할 수 있다.
그리고 delete 메소드를 통해 삭제할 수 있으며 add_property를 통해서 속성을 추가할 수 있다.
마무리
이외에도 sharding, replication, multi-tenancy등 여러가지 설정을 할 수 있다. 샤드의 상태도 변경할 수 있으니 참고해보는게 좋을 것 같다.
필자의 프로젝트는 한달용으로 단기이기에 따로 다루진 않았다. 현업에서 weaviate를 사용하게 된다면 추가 포스팅을 고려해보겠다.
정말 공식 문서를 읽는 능력도 중요하다고 생각이 들었다.
