PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
1. Abstract, Introduction
point cloud 단점irregular, unordered하다.
- 3d voxel or image collection으로 바꾸게 되면 voluminous해짐
*point cloud를 3d voxel or image collection으로 변환하지 않고 1. raw point cloud로 2. permutation invariance한 model
*permutation invariace : 입력벡터의 순서와 상관 없이 같은 출력을 생성하는 모델(순서가 바뀌지 않는 모델)
Key use a single symmetric function, max pooling.
PointNetinput : point cloud // Rigid, Affine Transformation 적용하기 쉬움
- Rigid transformation : 형태와 크기를 유지한 채, 위치와 방향만 바뀌는 변환(회전, 평행이동만 허용)
- Affine Transformation : 직선, 점들의 상대적 위치, 길이(거리)의 비, 평행성을 보존하는 변환
* 평행성 보존 : 교차하는 선, 평행하지도 교차하지도 않는 선을 보존한다.
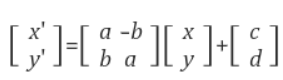
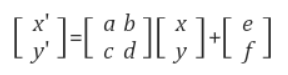
output :
key point : point cloud중 informative한 sparse point를 select할 수 있는 최적화 함수를 학습하는 것이 목표이다.
- data의 작은 변화나 corruption(insert/delete)에도 왜 강건한 모델인지 설명한다.
2. Related Work
A. Point Cloud Features
- intrinsic or extrinsic으로 분류된다.
- local or global feature로 분류된다.
B. Deep Learning on 3D Data
- Volumetric CNNs : voxelized shapes
- data sparsity와 계산 비용으로 인해 resolution(해상도) 제약을 받는다.
- FPNN & Vote3D : sparsity problem 다루는 용도
- Multiview CNNs : 3D point cloud -> 2D image -> 2D CNN
- space reconstruction, point classification 불가능
- Spectral CNNs : 3D point clous -> mesh
- manifold mashes에서 non-isometric shape으로 확장하기 어려움.
- Feature-based DNNs:3D data를 vector로 변환함.
C. Deep Learning on Unordered Sets
현재 딥러닝 process는 정규화된 data(speech, language, video etc.)에 초점을 맞추고 있어, point sets에 대한 연구가 더 필요하다.
-> Unordered input sets을 sorting 하기 위해 attention의 'read-process-write' network를 사용한다.
3. Problem Statement
point cloud = Set of 3D points({Pi|i=1,2,...,n})
Pi는 3차원 좌표(x,y,z)에 color등의 특성을 나타내는 channel을 추가한 것이지만, 본 논문에서는 3차원 좌표(x,y,z)만을 사용함
task
Classification : k개의 class에 대한 k score를 output으로 가짐
Semantic segmentation : n개의 points와 m semantic-subcategories에 대해 n*m score 출력함
4. Deep Learning on Point Sets
Architecture

4.1 Properties of Point Sets in R^n
point cloud의 속성
a. Unordered : voxel, 2D image와 달리 순서가 없음. N개의 data는 가능한 N!개의 순열에 대해 순서를 유지해야 함
b. Interaction among points : 각 포인트는 거리라는 관계를 가지고 있음 따라서 각 포인트 간의 상호작용을 local point에서 확인할 수 있어야 함
c. Invariance ubder transformations : 특정 기하학적 변형에 대해 변하지 않아야 함
4.2 🍀PointNet Archirecture
**중요 포인트 (Key modules) **a. Symmetric function to aggregate information
b. Local & global information combination structure
c. Two joint alignment networks
a. Symmetry function for unordered input
기존 permutation invariant한 모델을 만든 세가지 방법1) input 정렬(Canonical)
- 단점 : 간단해보이지만, feature가 고차원에 있기 때문에 point pertubation에 대해 안정적인 순서는 존재하지 않음. 따라서 sorting이 ordering 문제를 완전히 해결할 수는 없음.
2) RNN 이용
- 단점 : 짧은 길이의 sequence에서 ordering할 때 robust가 좋은 것이므로 data 수가 많은 point sets에는 적합하지 않음.
3) Simple symmetric fuction
- input order에 변하지 않는 새로운 vector를 찾는 과정. ex) +, *, max 함수**
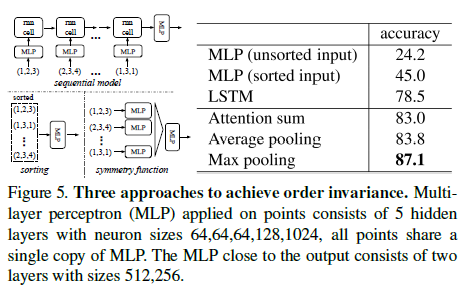
> 실험을 통한 3가지 방법 비교 결과 Max pooling의 성능이 가장 좋음Max pooling 적용
1. n x 64의 행렬에서 모든 n에 대하여 MLP(multi layer perceptron) 적용
2. 결과로 nx1024의 행렬이 나오게 됨.
3. Max-pooling을 column에 대해 적용
4. 순서에 구애받지 않는 global feature를 추출해 낼 수 있음.
Simple symmetric function을 통해 permutation invariant한 모델을 만들자
= transformed element에 symmetric function을 적용하자

transformed element에 symmetric function을 적용하자
g : symmetric function, maxpooling
h : Multu Layer Perception(MLP)
- MLP는 가중치가 다양할 것이기 때문에 다양한 transformation을 할 수 있을 것이다.
f : 최종 함수, point cloud의 서로 다른 characteristic을 찾을 수 있는 function
- h, g를 근사하여 얻을 수 있음b. Local and Global Information Aggregation
- Segmentation을 위한 부가적인 과정
Classification과 Segmentation의 차이는, Classification은 전체에 대해서 하나의 라벨이 필요하지만, Segmentation은 각 픽셀에 대하여 라벨링이 필요하기 때문에 neighborhood point와의 관계를 파악해야 한다.
* Segmentation에서는 neighborhood point와의 관계, local feature를 합쳐야 한다.
global feature
= classification을 하기 위한 feature.
= classification network에서 max-pooling을 통과하고 나온 output
local feature
= feature transform을 거치고 나온 feature
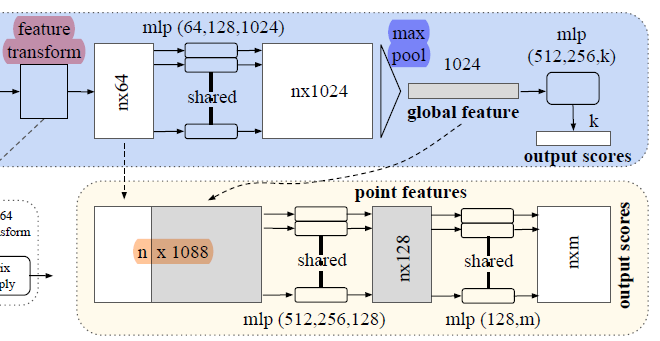
red : local feature
blue : global feature
orange : local and global informatin combination structure
c. Join alignment Network
목적 : 어떤 기하학적 변형에 대해서도 라벨링 결과가 변화하면 안된다. (ex. rigid transformation)
-> T-net을 이용하여 rigid transformation에 invariant를 유지한다
T-net?
1) T-net의 역할
affine transformation matrix 예측
= orthogonal matrix로 변환
2) T-net이 orthogonal matrix를 만드는 과정
a. point wise로 feature extract
b. Max pooling
c. Fully Connected Layer
d. Regularize항 추가
3) orthogonal matrix : 각도와 길이 정보 보존할 수 있는 matrix
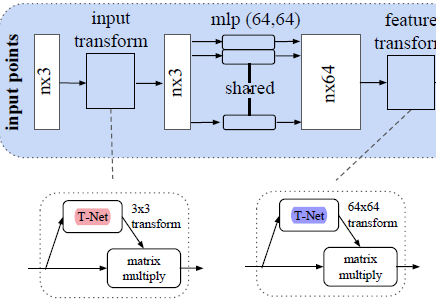
a. input transform(red)
Input의 feature 를 추출해 rotatio되어 있는 정도나 translation 되어있는 정도를 찾아 기존의 input point cloud와 3x3행렬로 계산
- 기존 point cloud에 affine transformation 적용하여 rigid transformation에 강해지도록 함(orthogonal matrix로 만듦)
- affine transformaton matrix A가 orthogonal matrix가 되면 input matrix에 곱해도 도형의 원래 고유 모양이 바뀌지 않는 rigid motion이 되기 때문
b. feature transform(blue) :
feature에서 transform하는 것이 spatial에서의 transform보다 고차원이기 때문에 loss function에 대한 optimization이 어려움. 따라서 더 차원이 높을수록 oryhogonal하게 만들기 위해 규제항을 추가
A matrix가 orthogonal하면 AA^T는 identity matrix됨.
-> 위의 Loss function을 minimize하는 A matrix는 orthogonal.
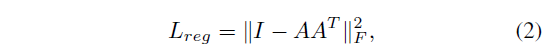
4.3 Theoretical Analysis
pointnet이 outlier나 missing data에 강한 이유
1. Universal Approximation
2. Bottleneck dimension and stability
5. Experiment
- Apply PointNet multiple 3D recognition tasks
- validate network design
- visualize network learn
- Analyza time and space complexity
5.1 Applications
3D Classification
dataset : ModelNet40
ModelNet40
- 40 Categories
- 12,311 data ; split into 9843/2468 for train , test
mesh faces에서 1024개 points를 sampling한 후, unit sphere로 normalize
- data augmentation : up-axis축을 따라 랜덤하게 회전시키거나, gaussian noise 추가
3D part Segmentation
- per-point classification problem로 고려
- Evaluation : mIoU
- mIoU 관련 설명은 reference 참고
3D part Segmentation
- 9-dimension vector ; X,Y,Z 좌표 및 R,G,B정보, 그리고 normalized location 정보를 포함.
- additional vector ; ㅣlocal point density, local curvature, normal
5.2 Architecture Design Analysis
A. Comparison with Alternative Order-invariant Methods4.2에서 언급했던 unordered input을 처리하는 방법에 대한 실험
1) MLP(unsorted input)
2) MLP(sorted input)
3) LSTM
LSTM의 성능이 가장 좋은 것을 확인할 수 있음
B. Effectiveness of Input and Feature Transformationinput과 feature에 대해 transformation했을 때 성능 향상 실험

-
transformation시 0.8% performance boost 보임
-
transformation과 regularization을 동시에 수행했을 때 가장 좋은 성능을 보임
C. Robustness Testmissing data와 outlier에 대한 성능 확인 실험

-
Furthest sampling & Random Sampling사용시 missing data ratio가 50%이상이 되어도 성능 저하가 각각 2.4%, 3.8%로 강건함
-
ouliert ratio가 20%가 되어도 80%이상의 Accuracy를 보임
5.3 Visualizing Pointnet

- Critical Point Sets(Cs) : max pooling을 통해 추출한 골격(최소한의 point)
- Upper-bounded Shapes(Ns) : largest possible cloud
*non-critical point를 잃는 경우는 global shape signature, f(S)에 영향을 주지 않는다.
🧠reference🧠
mIoU https://gaussian37.github.io/vision-segmentation-miou/

GaramJJang~