
- 집에가면 맥북에 스프링 설치해보자
- Arrays.copyOfRange(복사할 배열, 시작 위치, 배열 크기), .copyOf(복사할 배열, 복사할 배열의 크기)
- 코딩테스트 (자바 공부를 열심히 하자...)
오늘 공부 메모
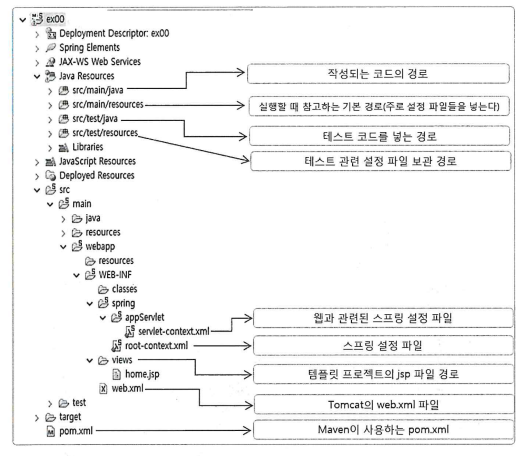
이런 기본 구조로 프로젝트가 생성이 될텐데 버전에 따라 pom.xml 파일을 통해서 관리가 필요하다. 만약 조장과 조원의 버전이 다르면 문제가 생기는데 pom.xml만 수정해주면 버전이 바뀌기 때문에 매우 편리하다!!
프로젝트 진행 중 메이븐이 불안정한 것 같으면 .m2 밑에 repository 폴더의 내용물을 삭제하고 이클립스를 재시작하면 자동으로 생성된 프로젝트를 점검하면서 관련 라이브러리를 다시 다운로드한다.
원래는 jsp를 실행하면 통째로 실행이 되기 때문에 어디에서 오류가 났는 지를 찾아야 하는데 spring에서는 junit을 사용해서 메서드별로 테스트를 해 오류를 찾아낼 수 있다! 엄청 좋은듯
spring은 jsp파일에서 실행할 필요 없이 tomcat 실행해서 인터넷창으로 보면 된다
model = 스프링이 관리하는 매우 유연한 메모리 영역
(페이지, 리퀘스트, 세션, 어플리케이션 같은 영역이라고 생각하면 된다.)
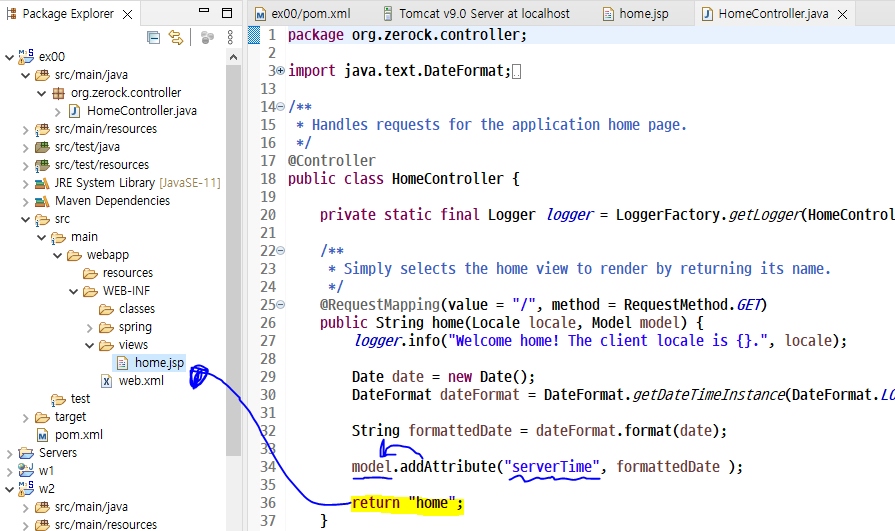
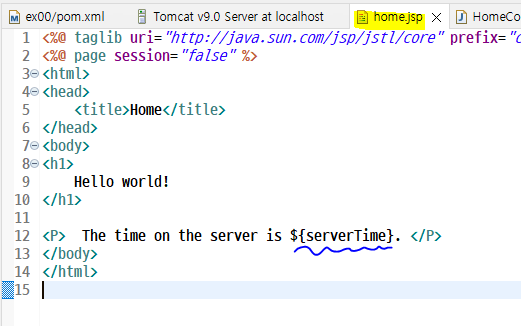
프레임워크 : '뼈대나 근간을 이루는 코드들의 묶음'
프레임워크를 이용한다는 의미는 프로그램의 기본 흐름이나 구조를 정하고, 모든 팀원이 이 구조에 자신의 코드를 추가하는 방식으로 개발하게 된다.
프레임워크 최대의 장점은 개발에 필요한 구조를 이미 코드로 만들어 놓았기 때문에, 실력이 부족한 개발자라 하더라도 반쯤 완성한 상태에서 필요한 부분을 조립하는 형태의 개발이 가능하다는 점이다! => 프레임워크를 사용하면 일정한 품질이 보장되는 결과물을 얻을 수 있고, 개발자 입장에서는 완성된 구조에 자신이 맡은 코드를 개발해서 넣어주는 형태이기 때문에 개발 시간을 단축할 수 있다!
스프링의 주요 특성
- POJO(Plain Old Java Object) 기반의 구성
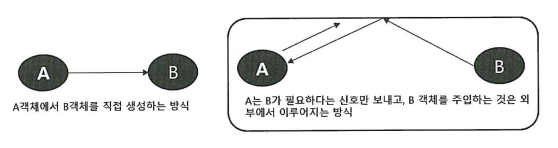
- 의존성 주입(Dependency Injection) 을 통한 객체 간의 관계 구성
자회사(JSP, servlet) -> 음식부터 하나하나 내가 다 사와서 해야한다
프랜차이즈(Spring) -> 발주하면 된다
이라고 생각하면 된다.
- ApplicationContext 라는 존재가 필요한 객체들을 생성하고, 필요한 객체들을 주입하는 역할을 해주는 구조, 관리하는 객체들을 'Bean'이라는 용어로 부르고, 빈과 빈 사이의 의존관계를 처리하는 방식으로 XML 설정, 어노테이션 설정, Java 설정 방식을 이용할 수 있다
- AOP의 지원(Aspect Oriented Programming)
- 트랜잭션의 지원
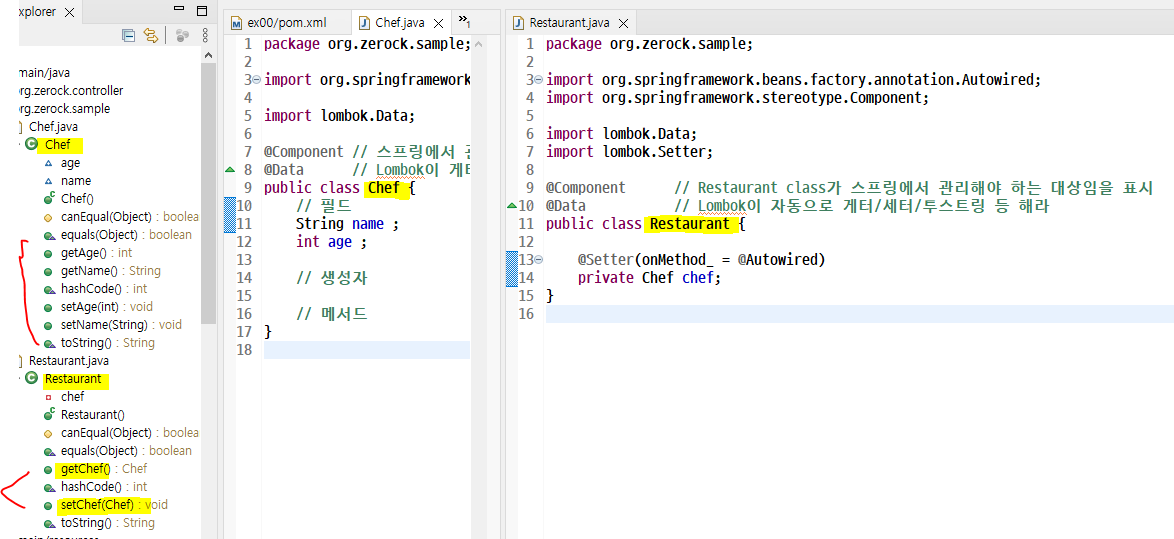
Chef에서 getter/setter를 따로 하지 않았는데도 보면 만들어져있다. 이건 @Data 어노테이션을 이용해서 getter, setter, toString, 생성자등이 자동으로 생성됐기 때문이다.
또한 Restaurant 클래스도 Chef를 주입받도록 설계해서 자동으로 생긴 것! 원래라면 Chef chef= new Chef() 이런식으로 객체를 생성해야 했는데 그럴 필요가 없는 것이다.
스프링이 동작하면서 생기는 일
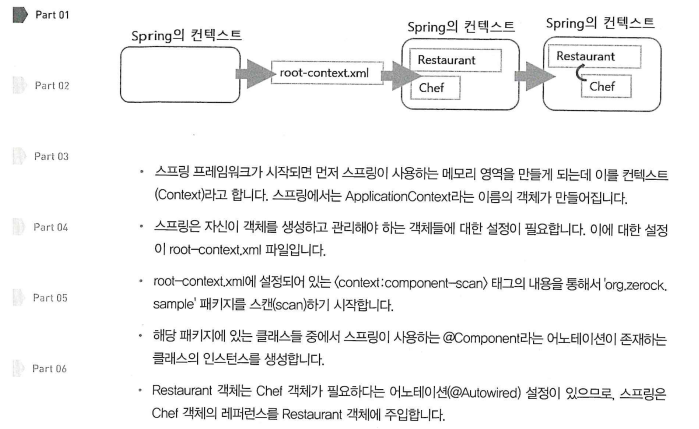
Beans Graph를 보면 이렇게 생겨있다!
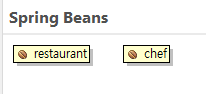

테스트 코드를 통한 확인!
package org.zerock.sample;
import static org.junit.Assert.assertNotNull;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import lombok.Setter;
import lombok.extern.log4j.Log4j2;
@RunWith(SpringJUnit4ClassRunner.class)
// 현재 테스트 코드가 스프링을 실행하는 역할을 할 것임을 표시
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/root-context.xml")
// 지정된 클래스나 문자열을 이용해서 필요한 객체들을 스프링 내에 객체로 등록(스프링의 빈으로 등록)
@Log4j2
// 신형 log 사용
public class SampleTests {
@Setter(onMethod_ = { @Autowired })
// @Autowired는 해당 인스턴스 변수가 스프링으로부터 자동으로 주입해 달라는 표시
private Restaurant restaurant;
@Test
// jUnit에서 테스트 대상을 표시하는 어노테이션 - (메서드명 - 우클릭 junit 테스트 진행)
public void testExist() {
assertNotNull(restaurant);
// restaurant 변수가 null이 아니어야만 테스트가 성공한다는 것을 의미
log.info(restaurant);
log.info("---------------------------------");
log.info(restaurant.getChef());
log.info(restaurant.getChef().getName());
log.info(restaurant.getChef().getAge());
}
}

- Lombok 관련
- @Setter : 말 그대로 setter 메서드를 생성해 주는 역할. (3가지 속성을 부여할 수 있다.)
1. value : 접근 제한 속성을 의미
2. onMethod : setter 메서드의 생성 시 메서드에 추가할 어노테이션을 지정. 예제에는 @Autowired라는 어노테이션이 지정되도록 작성되었다. 코드에 '' 표기가 있는데 JDK 버전에 따라 차이가 있다. (JDK8 이후부턴 사용)
3. onParam : setter 메서드의 파라미터에 어노테이션을 사용하는 경우에 적용
- @Data : 가장 자주 사용되는 어노테이션. @ToString, @EqualsAndHashCode, @Getter/@Setter, @RequiredArgsConstructor를 모두 결합한 형태로 한 번에 자주 사용되는 모든 메서드를 생성할 수 있다. 세부적인 설정이 필요 없다면 주로 @Data를 이용.
- @Log4j : log.info 이용, 로그 객체를 생성 (log4j는 시스템 결함이 있어 요즘은 log4j2를 사용한다.) - Spring 관련
- @Component : 해당 클래스가 스프링에서 객체로 만들어서 관리하는 대상임을 명시하는 어노테이션. 현재 예제에서 @ComponentScan을 통해서 지정되어 있으므로 해당 패키지에 있는 클래스들을 조사하면서 @Component가 존재하는 클래스들을 객체로 생성해서 빈으로 관리하게 된다.
- @Autowired : 스프링 내부에서 자신이 특정한 객체에 의존적이므로 자신에게 해당 타입의 빈을 주입해주라는 표시. 예제에서 Restaurant 객체는 Chef 타입의 객체가 필요하다는 것을 명시함.
- 테스트 관련 어노테이션
- @ContextConfiguration : 스프링이 실행되면서 어떤 설정 정보를 읽어 들여야 하는지를 명시. 속성으로는 locations를 이용해서 문자열의 배열로 XML 설정 파일을 명시할 수도 있고, classes 속성으로 @Configuration이 적용된 클래스를 지정해 줄 수도 있다.
- @Runwith : 테스트 시 필요한 클래스를 지정
- @Test : junit에서 해당 메서드가 jUnit 상에서 단위 테스트의 대상인지 알려줌
단일 생성자의 묵시적 자동 주입 테스트
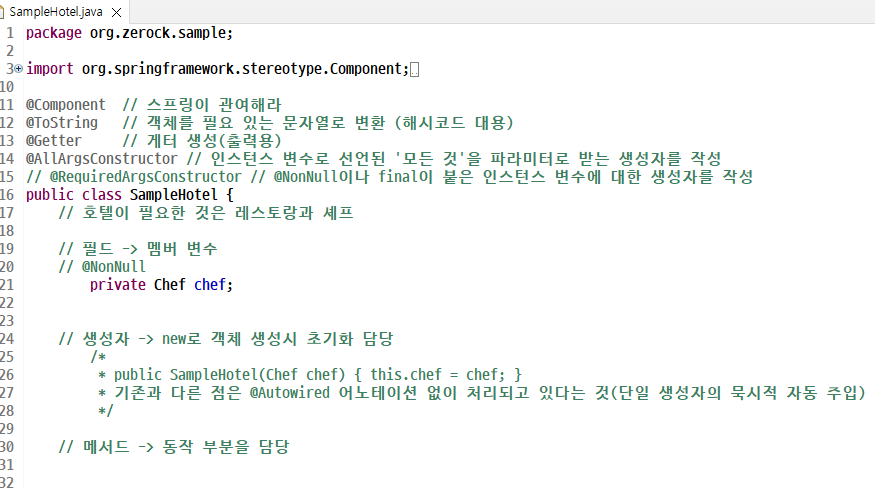
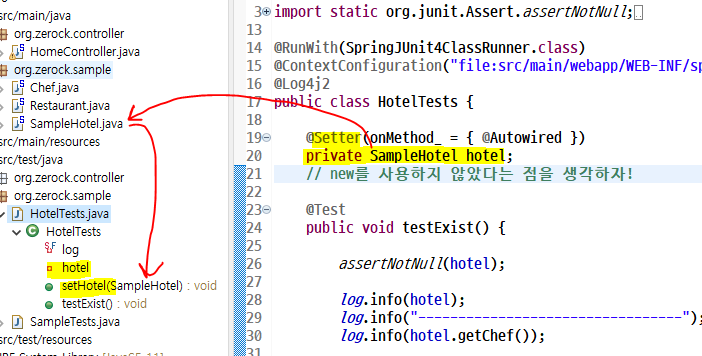
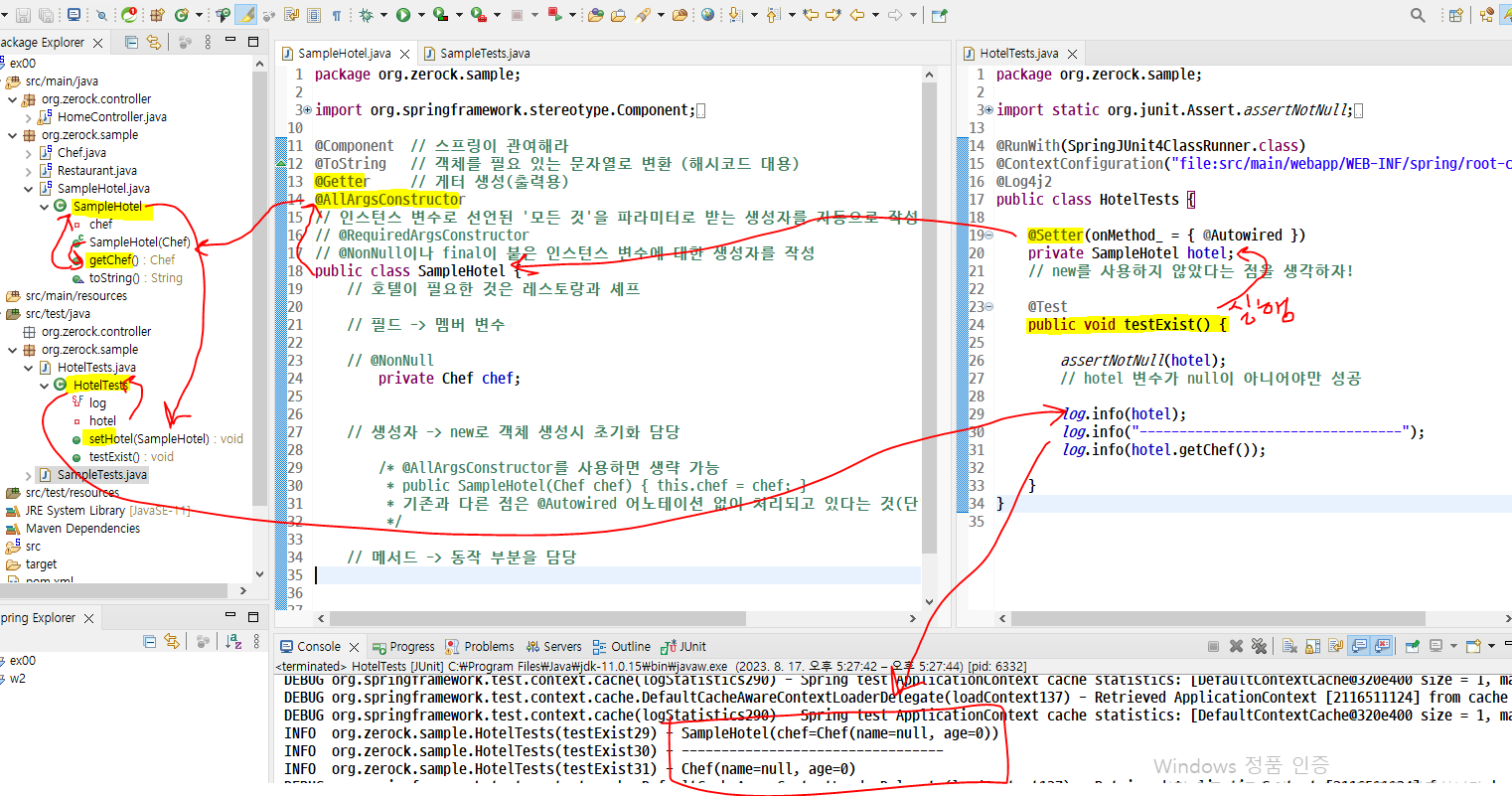
Spring과 DB 연결하기
JDBC 사용하는 것과 커넥션 풀(hikari를 이용)을 사용하는 방법이 있는데 JDBC를 사용하면 DB 연결하는데 100번의 반복을 하니 오류가 나서 실행이 안되는 반면 커넥션 풀은 실행도 빠르게 되고 안정성까지 있어서 좋다. 구멍가게 영상을 보니 DB 연결은 커넥션 풀을 꼭 이용하라고 하는데 무슨 차이가 있는지를 보여주니 이해가 잘 됐다. 링크!
