CNN활용
세가지의 주요 컴퓨터 비전 작업
- 이미지 분류 image classification: 이미지에 하나 이상의 레이블을 할당하는 것 [단일/다중]
- 이미지 분할 image segmentation: 이미지를 다른 영역으로 나누거나 분할하는 것(ex. 화상회의에서 얼굴과 배경분리)
- 객체 탐지 object detection: 이미지에 있는 관심 객체 주변에 사각형(바운딩박스 bounding box)그리기

이미지 분할
- 시맨틱 분할: 각 픽셀이 독립적으로 하나의 의미를 가진 범주로 분류
- ex: 이미지에 고양이 2마리가 있다면 모든 픽셀은 'Cat'의 범주로 매핑
- 인스턴스 분할: 이미지 픽셀을 개별 객체 인스턴스까지 구분
- ex: 이미지에 고양이 2마리가 있으면 'Cat_1','Cat_2' 별개로 매핑

Oxford-IIIT Pets 데이터 셋 사용하기
- 다양한 품종의 고양이, 강아지 사진
- 각 사진의 전경-배경 분할 마스크 segmentation mask(레이블에 해당)
- 입력 이미지와 동일크기
- 컬러채널 한개(정수)
- 1: 전경
- 2: 배경
- 3: 윤곽
🔸 데이터셋 내려받고 압축 풀기
import wget
url = "http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz"
wget.download(url)
url = "http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz"
wget.download(url)- images: 입력될 이미지
- annotations: 레이블(분할 마스크)
🔸 파일경로 분할
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
input_img_paths = sorted([os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted([os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])- 확인
input_img_paths[:3]
🔸 이미지 로드: keras.utils.load_img
import matplotlib.pyplot as plt
from keras.utils import load_img, img_to_array
plt.axis("off")
plt.imshow(load_img(input_img_paths[9]))
🔸 분할마스크 확인: keras.utils.img_to_array
img = img_to_array(load_img(target_paths[9], color_mode="grayscale"))
plt.axis("off")
plt.imshow(img)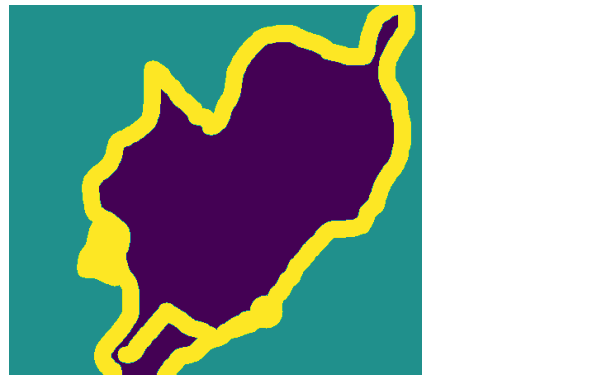
🔸🔸 데이터 준비: 파일을 넘파이 배열로 로드하고(동일사이즈로), 훈련과 검증 세트 나누기
import numpy as np
import random
img_size = (200, 200)
num_imgs = len(input_img_paths)
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
#----------------------------------------------------------------------#
# 이미지 사이즈 동일하게 조정
# 원래레이블값:1,2,3/ 0,1,2가 되도록 수정
def path_to_input_image(path):
return img_to_array(load_img(path, target_size=img_size))
def path_to_target(path):
img = img_to_array(load_img(path, target_size=img_size, color_mode="grayscale"))
img = img.astype("uint8") - 1
return img
#----------------------------------------------------------------------#
# 데이터 넘파이 배열로 로드
# 전체이미지개수, (이미지 사이즈), 3혹은 1차원
input_imgs = np.zeros((num_imgs,) + img_size + (3,), dtype="float32")
targets = np.zeros((num_imgs,) + img_size + (1,), dtype="uint8")
for i in range(num_imgs):
input_imgs[i] = path_to_input_image(input_img_paths[i])
targets[i] = path_to_target(target_paths[i])
#----------------------------------------------------------------------#
# 훈련, 검증 데이터로 분리
num_val_samples = 1000
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]🔸🔸 모델 정의
import keras
from keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape = img_size + (3,))
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(256, 3, strides=2, padding="same", activation="relu")(x)
x = layers.Conv2D(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same", strides=2)(x)
# 각 출력을 3개의 범주 중 하나로 분류하기 위해 3개의 유닛과 소프트맥스사용
outputs = layers.Conv2D(num_classes, 3, activation="softmax",padding="same")(x)
model = keras.Model(inputs, outputs)
return model
model = get_model(img_size=img_size, num_classes=3)
model.summary()
- strides=2: 스트라이드를 통한 3번의 다운샘플링:
- 이미지 분할의 경우 정보의 공간상 위치에 관심을 둠 → MaxPooling(X)
- MaxPooling의 경우 위치정보 완전 삭제 → 분할 작업에는 상당한 해를 끼칠수 있다.
- Conv2DTranspose :
- 최종출력은 타깃 마스크의 크기와 동일해야함
- 적용한 변환을 거꾸로 적용
- 업샘플링
🔸🔸 모델 적용
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
batch_size=64,
validation_data=(val_input_imgs, val_targets))🔸 그래프
epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()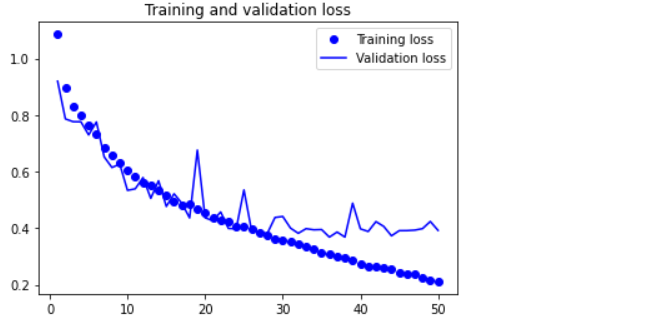
🔸 분할마스크 예측
- keras.utils.array_to_img
from tensorflow.keras.utils import array_to_img
i = 4
test_image = val_input_imgs[i]
plt.axis("off")
plt.imshow(array_to_img(test_image))
model = keras.models.load_model("oxford_segmentation.keras")
mask = model.predict(np.expand_dims(test_image, 0))[0]
# test_image = val_input_imgs[4]
# np.expand_dims(val_input_imgs[4], 0).shape >>>(1, 200, 200, 3)
# 0번 밖에 없음(예측을 1장만 함)
def display_mask(pred):
mask = np.argmax(pred, axis=1)
# mask *= 127
plt.axis("off")
plt.imshow(mask)
display_mask(mask)
** 이미지출처
https://drek4537l1klr.cloudfront.net/chollet2/Figures
