다양한 종류의 시계열 작업
- 시계열 데이터: 일정한 간격으로 측정하여 얻은 모든 데이터
- 가장 일반적인 시계열 관련 작업: 예측
- 시계열 데이터로 할 수 있는 작업
- 분류: 범주형 레이블을 시계열에 부여, 예로 웹사이트 방문자 활동에 시계열을 부여하여 방문자가 BOT인지 사람인지 분류
- 이벤트 감지: 특정 이벤트 발생을 식별
- 이상치 탐지: 연속된 데이터 스트림에서 발생하는 비정상적 현상 감지
시계열 데이터 대표예시
- 기본 텐서 구조: (Sample, timesteps, features)
- 시계열 데이터 대표 예시: 온도 예측, 주가 예측
온도 예측 예시: Jena시의 기상관측소 데이터
1) 데이터 다운로드
!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip
!unzip jena_climate_2009_2016.csv.zip2) 데이터 불러오기
🔸 일반적 방법
# 파일 경로 지정 후 읽어오기
import os
fname = os.path.join('jena_climate_2009_2016.csv')
with open(fname) as f:
data = f.read()# culumns(header)부분과 내용(lines)구분하기
lines = data.split('\n')
header = lines[0].split(",")
lines = lines[1:]
print(header)
print(len(lines))import numpy as np
# 데이터 구분해서 저장
temperature = np.zeros((len(lines),))
raw_data = np.zeros((len(lines),len(header)-1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(",")[1:]]
temperature[i] = values[1]
raw_data[i,:] = values[:]- 그래프로 확인
from matplotlib import pyplot as plt
plt.plot(range(len(temperature)), temperature)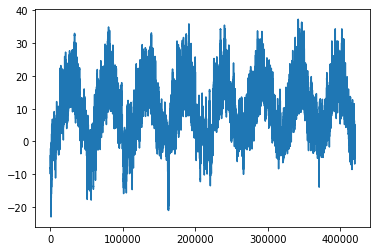
🔸 pandas로 불러오기
import pandas as pd
jena = pd.read_csv('jena_climate_2009_2016.csv')
temp = jena['T (degC)'].values
raw = jena.iloc[:,1:].values<참고>
temp = temperature
raw = raw_data3) 데이터 분리: 훈련/검증/테스트
num_train_samples = int(0.5 * len(raw_data))
num_val_samples = int(0.25 * len(raw_data))
num_test_samples = len(raw_data) - num_train_samples - num_val_samples
print("num_train_samples:", num_train_samples)
print("num_val_samples:", num_val_samples)
print("num_test_samples:", num_test_samples)num_train_samples: 210225 num_val_samples: 105112 num_test_samples: 105114
4) 데이터 정규화
mean = raw_data[:num_train_samples].mean(axis=0)
raw_data -= mean
std = raw_data[:num_train_samples].std(axis=0)
raw_data /= std5) 데이터 세트 만들기
import keras
sampling_rate = 6 # 시간당 1개만 사용(데이터가 10분단위)
sequence_length = 120 # 5일
delay = sampling_rate * (sequence_length + 24 - 1)
batch_size = 256
train_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=0,
end_index=num_train_samples)
val_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples,
end_index=num_train_samples + num_val_samples)
test_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples + num_val_samples)<참고>
raw_data.shape
>>> (420451, 14)
raw_data[:-delay].shape
>>> (419593, 14)
delay
>>> 858
# 420451-419593=858🔸 데이터셋 확인
for samples,targets in train_dataset:
print('samples:', samples.shape)
print('targets:', targets.shape)
break# (배치사이즈, 타임스텝, 피처) samples: (256, 120, 14) targets: (256,)
6) 상식수준의 기준점 제시
- 시계열 데이터는 연속성이 있고 일자별로 주기성을 가진다고 가정
- 상식수준: 지금온도 = 24시간후 온도
- 평가방법: 평균절대값오차(MAE)
def evaluate_naive_method(dataset):
total_mae = 0.
samples_seen = 0.
for samples, targets in dataset:
preds = samples[:,-1,1] * std[1] + mean[1]
# 온도특성: sample 인덱스 1번 / samples[:,-1,1]: 입력 시퀀스의 마지막 온도측정값
# 특성을 정규화 했으므로 다시 표준편차를 곱하고 평균을 나눔
# std = raw_data[:num_train_samples].std(axis=0)
# mean = raw_data[:num_train_samples].mean(axis=0)
total_mae += np.sum(np.abs(preds - targets))
samples_seen += samples.shape[0]
return total_mae / samples_seen
print(f'검증 mae: {evaluate_naive_method(val_dataset):.2f}')
print(f'테스트 mae: {evaluate_naive_method(test_dataset):.2f}')검증 mae: 2.44 테스트 mae: 2.62
7) 온도 예측 여러방법
🔸 기본 딥러닝
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Flatten()(inputs)
x = layers.Dense(16, activation="relu")(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_dense.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_dense.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")

🔸 1D합성곱 모델 활용: Conv1D
- Conv1D 층을 사용하여 구현, Conv2D와 인터페이스가 비슷
- (samples,time,features)크기의 3D텐서를 입력받고 비슷한 형태의 3D텐서를 반환
- 합성곱 윈도우(커널)는 시간 축의 1D 윈도우이며 입력덴서의 두번째 축임
GlobalMaxPooling1D():Flatten대신 사용- 1D 시간 데이터에 대한 전역 최대 풀링 작업
- 매개변수: data_format/ keepdims(default False)
keepdims=False: 2D 텐서 (batch_size, features).keepdims=True: 2D 텐서data_format='channels_last': (batch_size, steps, features)data_format='channels_first': (batch_size, features, steps)

inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
# 초기 윈도우 24, 한번에 24시간의 데이터를 살핌
x = layers.Conv1D(8, 24, activation="relu")(inputs)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 12, activation="relu")(x)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 6, activation="relu")(x)
x = layers.GlobalAveragePooling1D()(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_conv.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_conv.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")

🔸 순환신경망 활용: LSTM
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(16)(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")

🔸 스태킹순환층활용: SimpleRNN / GRU
- SimpleRNN
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.SimpleRNN(16, return_sequences=True)(inputs)
x = layers.SimpleRNN(16)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_stacking_rnn.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_stacking_rnn.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")

- GRU
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.GRU(32, recurrent_dropout=0.5, return_sequences=True)(inputs)
x = layers.GRU(32, recurrent_dropout=0.5)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_gru.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_gru.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")

🔸 순환신경망+드롭아웃: LSTM + Dropout
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(32, recurrent_dropout = 0.25)(inputs)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")

🔸 양방향 순환층: Bidirectional
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Bidirectional(layers.LSTM(16))(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("jena_bidirectional.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_bidirectional.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")