분류와 회귀에 사용하는 용어
- 이진 분류: 각 입력 샘플이 2개의 배타적인 범주로 구분
- 다중 분류: 각 입력 샘플이 2개 이상의 범주로 분류
- 다중 레이블 분류: 각 입력 샘플이 여러 레이블에 해당할 경우
(ex: 고양이와 강아지가 같이 있는 사진 분류) - 스칼라 회귀: 타깃이 연속적인 스칼라값인 작업
- 벡터 회귀: 타깃이 연속적인 집합인 작업
예제살피기
- 영화리뷰 분류( 긍정, 부정 ): 이진분류
- 신문기사 토픽분류: 다중분류
- 부동산데이터로 주택가격 예측: 회귀
1. 영화리뷰 긍정,부정 분류: 이진분류
1) 데이터 셋 로드
- 훈련데이터 25000개, 테스트데이터 25000개, 각각 50% 긍정, 50% 부정
- train_data, test_data = 단어 인덱스(단어를 숫자화 한 것) 리스트
- train_labels, test_labels = 부정 0, 긍정 1
- num_words=10000(특성선택)
:훈련데이터에서 가장 자주 나타나는 단어 1만 개만 사용
from keras.datasets import imdb
(train_data, train_labels),(test_data,test_labels)=imdb.load_data(num_words=10000)train_data.shape
(25000,)
🔸 참고: 단어 인덱스를 다시 텍스트로 디코딩해보기
word_index()
word_index = imdb.get_word_index()
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
decoded_review=' '.join([reverse_word_index.get(i-3,'!') for i in train_data[0]])
# 리뷰의 0,1,2는 '패딩','문서시작','사전에없음'이 예약되어있음
decoded_review
2) 데이터 준비
- 신경망에 숫자리스트를 바로 주입 불가(숫자리스트의 길이가 다 다름/ 텍스트의 길이가 다 다르므로)
- 방법 2가지
- 같은 길이로 리스트에 패딩추가 ,(samples,max_length)크기의 정수 텐서로 변환
- 멀티-핫 인코딩
🔸 sample 멀티-핫 인코딩
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results= np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i,j]=1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)- 리스트 길이 10000으로 통일
- 값이 있는 위치에 1, 그 외 모든 값 0
🔸 레이블 인코딩
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')3) 모델 구성
from keras import Sequential
from keras.layers import Dense
model = Sequential([
Dense(16,activation='relu'),
Dense(16,activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics='acc')- 분류문제
- metrics: 'acc'
- 이진분류이므로
- activation: sigmoid
- loss: binary_crossentropy
4) 훈련검증(검증데이터)
🔸 검증 세트 만들기
x_val = x_train[:15000]
y_val = y_train[:15000]
partial_x_train = x_train[15000:]
partial_y_train = y_train[15000:]🔸 fit()
- history로 저장하여 교정값 찾기
history = model.fit(partial_x_train,partial_y_train,
epochs=20, batch_size=512,
validation_data =(x_val,y_val))print(history.history.keys())
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
- 손실값 그래프
import matplotlib.pyplot as plt
loss_values = history.history['loss']
val_loss_values = history.history['val_loss']
epochs = range(1,len(loss_values)+1)
plt.figure(figsize=(6,4))
plt.plot(epochs, loss_values,'bo', label="Training loss")
plt.plot(epochs, val_loss_values,'b', label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()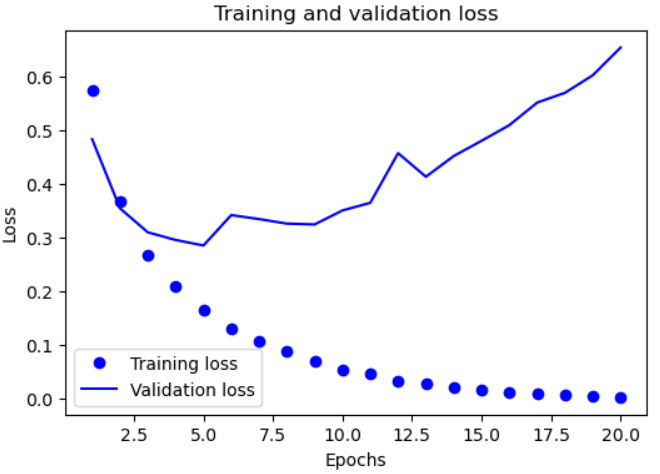
- 정확도 그래프
plt.clf() # 그래프 초기화
acc = history.history["acc"]
val_acc = history.history["val_acc"]
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()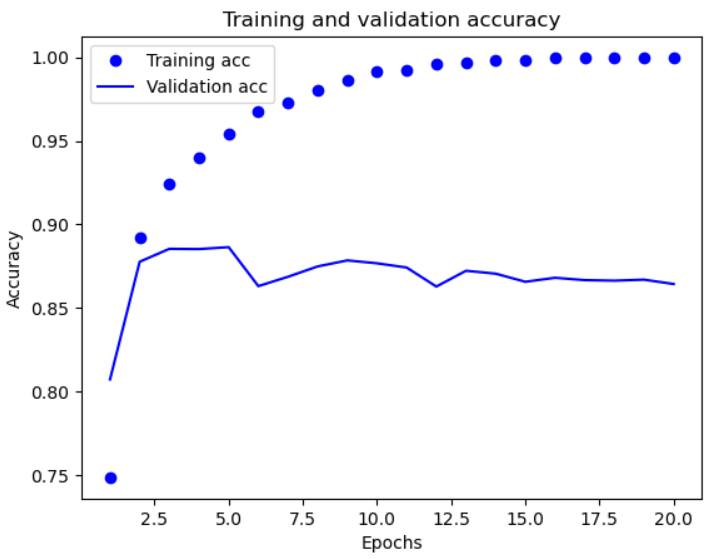
5) 테스트 데이터에서 평가
model = Sequential([
Dense(16,activation='relu'),
Dense(16,activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics='acc')
model.fit(x_train, y_train,
epochs=4, batch_size=512)
result = model.evaluate(x_test, y_test)
print(f'loss:{result[0]}, acc:{result[1]}')
loss:0.2982291281223297, acc:0.8823999762535095
6) 새로운데이터 예측(테스트 데이터): predict
model.predict(x_test)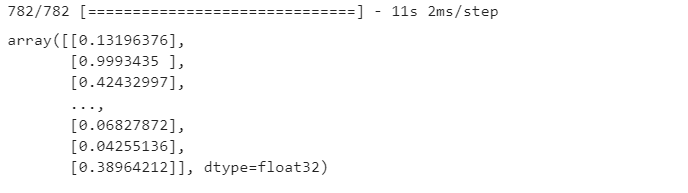
- 25000개 각각의 값이 출력
2. 뉴스기사의 토픽 분류: 다중분류 문제
1) 데이터 셋 로딩
- 짧은 뉴스 기사와 토픽의 집합
- 46개의 토픽, 훈련 세트에 최소 10개의 샘플
from keras.datasets import reuters
(train_data, train_labels),(test_data, test_labels) = reuters.load_data(num_words=10000)train_data.shape
(8982,)
2) 데이터 준비(원핫인코딩)
🔸 sample 멀티-핫 인코딩
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results= np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i,j]=1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)🔸 레이블 인코딩
- 원핫인코딩으로 변환하는 방법 사용
from keras.utils.np_utils import to_categorical
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)3) 모델 구성
from keras import Sequential
from keras.layers import Dense
model = Sequential([
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(46, activation='softmax')
])
model.compile(optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = 'acc')- 다중분류(원핫인코딩):
- activation: softmax
- loss: categorical_crossentropy
4) 훈련검증(검증데이터)
🔸 데이터 분리
x_val = x_train[:1000]
y_val = y_train[:1000]
partial_x_train = x_train[1000:]
partial_y_train = y_train[1000:]🔸 fit()
history = model.fit(partial_x_train,partial_y_train,
epochs=20, batch_size=512,
validation_data =(x_val,y_val))🔸 손실 그래프
import matplotlib.pyplot as plt
loss_values = history.history['loss']
val_loss_values = history.history['val_loss']
epochs = range(1,len(loss_values)+1)
plt.figure(figsize=(6,4))
plt.plot(epochs, loss_values,'bo', label="Training loss")
plt.plot(epochs, val_loss_values,'b', label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()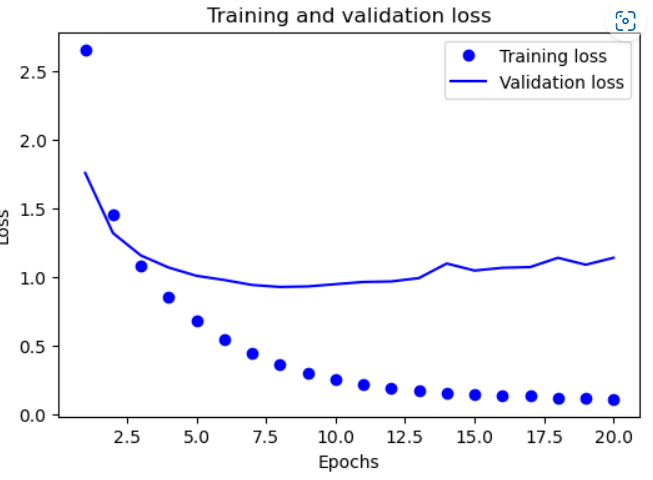
🔸 정확도 그래프
plt.clf() # 그래프 초기화
acc = history.history["acc"]
val_acc = history.history["val_acc"]
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()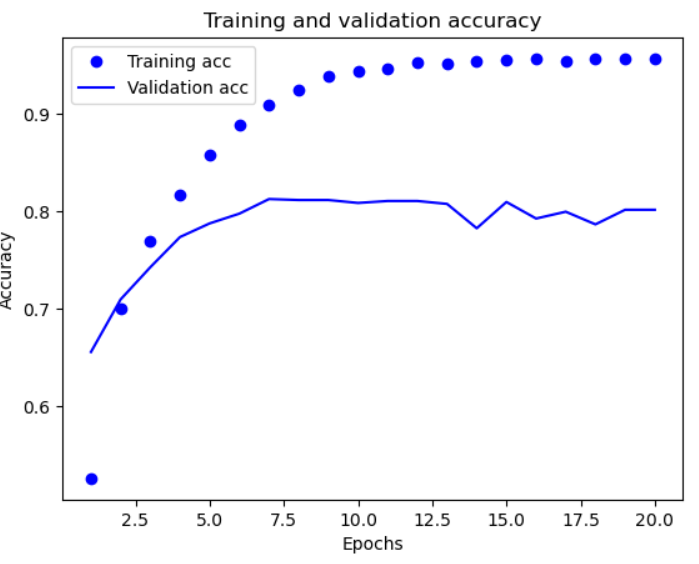
5) 테스트 데이터에서 평가
model = Sequential([
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(46, activation='softmax')
])
model.compile(optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = 'acc')
model.fit(x_train,y_train,
epochs=9, batch_size=512)
result = model.evaluate(x_test, y_test)
print(f'loss:{result[0]}, acc:{result[1]}')
loss:0.9278658032417297, acc:0.7974176406860352
6) 새로운 데이터 예측
pred = model.predict(x_test)
pred[0].argmax()
3
7) 레이블 인코딩 방법 바꾸기: 정수텐서 변환
y_train = np.array(train_labels)
y_test = np.array(test_labels)model = Sequential([
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(46, activation='softmax')
])
model.compile(optimizer = 'rmsprop',
loss = 'sparse_categorical_crossentropy',
metrics = 'acc')
model.fit(x_train,y_train,
epochs=9, batch_size=512)
result = model.evaluate(x_test, y_test)
print(f'loss:{result[0]}, acc:{result[1]}')
loss:0.9744129776954651, acc:0.7836152911186218
- 다중분류(정수텐서)
- loss: sparse_categorical_crossentropy
3. 주택가격예측: 회귀문제
1) 데이터셋 로드
from keras.datasets import boston_housing
(train_data, train_target),(test_data, test_target) = boston_housing.load_data()train_data.shape(404, 13)
2) 데이터 준비: 정규화
-
-
axis참고
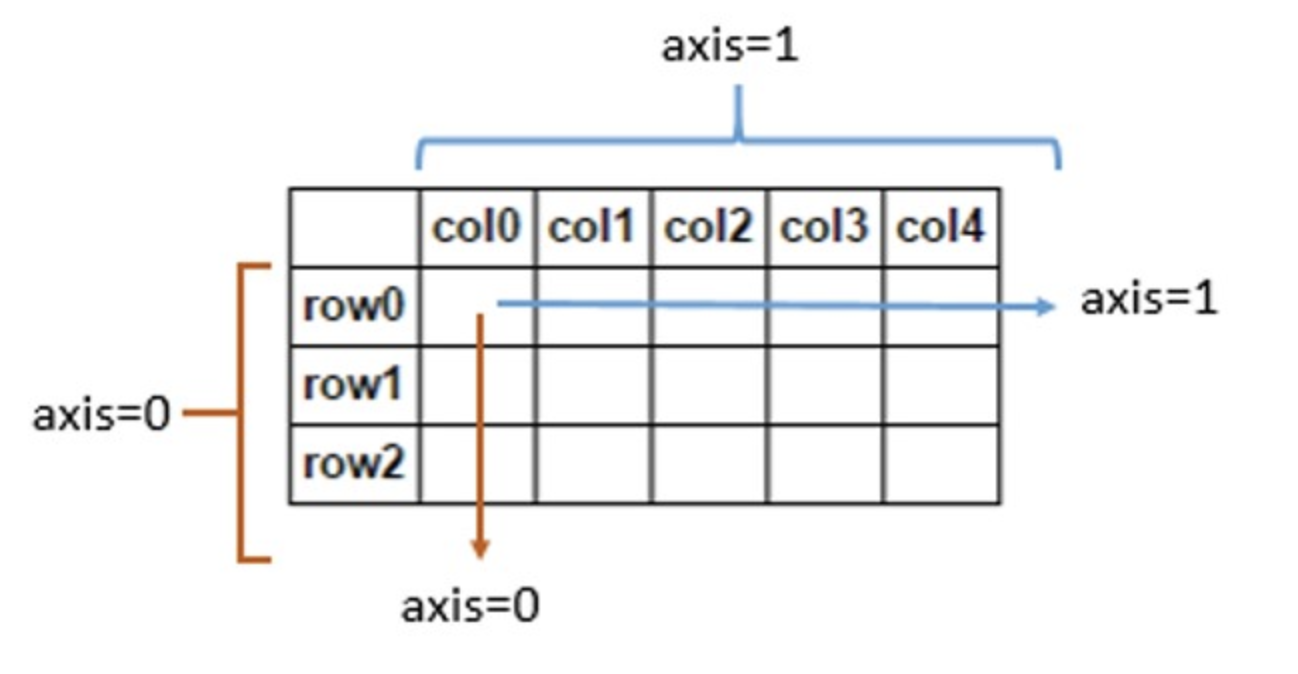
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std# 정규화에 사용한 값은 훈련데이터에서 계산한 값이어야함!!
test_data -= mean
test_data /= std3) 모델 구성
from keras import Sequential
from keras.layers import Dense
def build_model():
model = Sequential([
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(1)
])
model.compile(optimizer='rmsprop',loss='mse',metrics='mae')
return model- 회귀
- loss: mse
- metrics: mae
4) K-fold 훈련 검증
🔸 기본 검증
k = 4
val_samples = len(train_data)//k
epochs=100
all_scores=[]
for i in range(k):
print(f'{i}번째 fold')
val_data = train_data[i* val_samples : (i+1)*val_samples] # 분할
val_target = train_target[i* val_samples : (i+1)*val_samples] # 분할
partial_train_data = np.concatenate([
train_data[:i*val_samples],
train_data[(i+1)*val_samples:]
],
axis= 0) # 분할 나머지
partial_train_target = np.concatenate([
train_target[:i*val_samples],
train_target[(i+1)*val_samples:]
],
axis= 0) # 분할 나머지
# 모델훈련
model = build_model()
model.fit(partial_train_data, partial_train_target,
epochs = epochs, batch_size=16,verbose=0)
# 검증세트로 모델 평가
val_mse, val_mae = model.evaluate(val_data, val_target,verbose=0)
all_scores.append(val_mae)
print('mae평균:', np.mean(all_scores))
- 참고

🔸 각 폴드의 검증 점수 저장
k = 4
val_samples = len(train_data)//k
epochs = 500
all_histories_mae = []
for i in range(k):
print(f'{i}번째 fold')
val_data = train_data[i* val_samples : (i+1)*val_samples] # 분할
val_target = train_target[i* val_samples : (i+1)*val_samples] # 분할
partial_train_data = np.concatenate([
train_data[:i*val_samples],
train_data[(i+1)*val_samples:]
],
axis= 0) # 분할 나머지
partial_train_target = np.concatenate([
train_target[:i*val_samples],
train_target[(i+1)*val_samples:]
],
axis= 0) # 분할 나머지
model = build_model()
history = model.fit(partial_train_data, partial_train_target,
validation_data=(val_data, val_target),
epochs = epochs, batch_size=16,verbose=0)
mae_history = history.history['val_mae']
all_histories_mae.append(mae_history)
# epochs개의 평균 mae
avg_mae_history = [np.mean([x[i] for x in all_histories_mae]) for i in range(epochs)]
print(f'{epochs}개 평균 mae:',np.mean(avg_mae_history))
- 참고: avg_mae_history를 만드는 다른 방법(풀이)

🔸 검증 점수 그래프(20개 이후)
plt.plot(range(1,len(avg_mae_history[20:])+1), avg_mae_history[20:])
plt.xlabel('epochs')
plt.ylabel('validation MAE')
plt.show()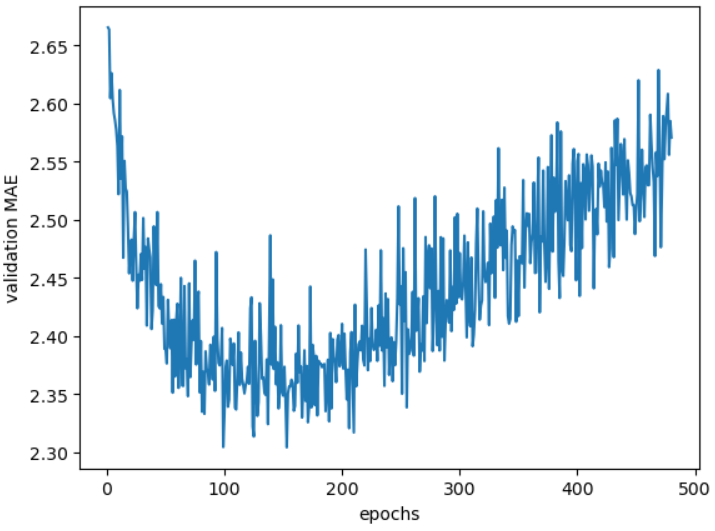
5) 테스트 데이터에서 평가
model=build_model()
model.fit(train_data, train_target,
epochs=128, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_target)
test_mae_score
2.271951675415039
6) 새로운 데이터 예측
pred = model.predict(test_data)
pred[0]
array([7.4122086], dtype=float32)
test_target[0]
7.2
