Node.js 로 크롤링 하기
이 글은 Node.js 에서 크롤링 및 파싱 후 DB 에 저장하기까지의 과정을 포함하고 있습니다.
여러 커뮤니티의 인기글을 크롤링해서 보여주는 1인 토이프로젝트를 기획 중,
크롤링을 파이썬에서 하는 방식이 아닌 Node.js 에서 할 수는 없을까? 하는 생각을 가지게 되었습니다.
서칭을 해보니 짠~~! 있었습니다! Node.js 에서 크롤링 하는 법
그래서 이번엔 저처럼 Node.js 로 크롤링을 하고싶어하시는 분을 위해 글을 작성하게 되었습니다.
자 이제부터 한번 알아볼까요?

axios 와 puppeteer
Node.js 로 크롤링 하는 방법을 검색하면 나오는 대표적인 방법들입니다.
둘 중 어떤 것을 사용하는게 좋을까요?
한번 둘의 특징을 분석해봅시다!
🟢 axios
이 방식은 말그대로 get 을 사용해서 웹페이지의 데이터를 가져오는 것입니다.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items');
console.log(response.data);이렇게 말이죠.
한번 직접 구현해볼까요?
저는 Next.js 로 개발을 하고 있기 때문에,
scripts 폴더에 아래의 파일을 만들어주었습니다.
// scripts/scraper/axios-scraper.ts
import axios from "axios";
async function scrap() {
const url = "https://www.dcinside.com/";
try {
const response = await axios.get(url);
const html = response.data;
// 일부만 출력
console.log(html.substring(0, 500) + "...");
} catch (error) {
console.error("크롤링 실패:", error);
}
}
scrap();정말 단순히 axios.get() 으로 response 를 받아서 html 텍스트를 출력하는 코드입니다.
이제 터미널 창에 npx tsx scripts/scraper/axios-scraper.ts 를 입력해서 실행해주게 되면,
<!DOCTYPE html>
<html lang="ko" class="darkmode">
<head>
<meta charset="UTF-8">
<title>## CONNECTING HEARTS! 디시인사이드입니다. ## </title>
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="content-language" content="kr">
<meta name="google-site-verification" content="8aEYAJVec9-3ebnXb0JXhG6k_tD5Jkn3lXnZHqosLJ0">
<link rel="canonical" href="https://www.dcinside.com/">
<link rel="alternate" media="only screen and (max-width: 640px)" href="https://m.dcinside.com/...이런 결과가 나오게 됩니다!
🔴 axios 방식의 단점
axios 를 활용하면 정말 간단하게 크롤링을 수행할 수 있습니다.
하지만 이 방식에는 두가지 문제가 있습니다.
첫째, 단순히 HTML 텍스트를 받습니다.
크롤링은 웹 페이지 내에서 원하는 데이터를 추출하기 위해 수행됩니다. 하지만 단순 문자열 형태로 HTML을 받아오면 특정 요소를 구분하거나 선택하기가 매우 어렵습니다.
예를 들어 <title> 태그 안의 텍스트를 찾고 싶을 때, DOM 구조로 파싱되어 있어야 document.querySelector("title") 혹은 $(".title") 같은 셀렉터를 사용하여 쉽게 접근할 수 있습니다.
반대로 단순 텍스트 상태라면 수많은 문자열 중 일일이 패턴을 찾아야 하므로 효율이 떨어집니다.
둘째, JavaScript 로 동적로딩 하는 페이지는 크롤링 하기 힘듭니다.
일부 웹사이트는 최초 요청 시 HTML 문서만 전달하고, 핵심 데이터는 JavaScript 코드가 실행되면서
AJAX 요청이나 API 호출을 통해 동적으로 채워 넣는 방식(CSR, Client Side Rendering)을 사용합니다. 이런 경우 단순히 axios 같은 HTTP 요청으로는 화면에 보이는 데이터가 포함되지 않습니다.
🔴 단점 해결법
그럼 이 두가지 문제는 해결이 불가능한 것일까요?
아닙니다!
첫번째 문제 해결법(cheerio)
cheerio 라는 라이브러리를 사용하면 단순 텍스트를 DOM 구조로 변환할 수 있습니다!
import axios from "axios";
import * as cheerio from "cheerio";
async function scrap() {
const url = "https://www.dcinside.com/";
try {
const response = await axios.get(url);
const html = response.data;
// 1. 정규식으로 title 추출
const titleMatch = html.match(/<title[^>]*>([^<]+)<\/title>/i);
const titleWithoutCheerio = titleMatch ? titleMatch[1].trim() : "제목 없음";
// 2. Cheerio로 title 추출
const $ = cheerio.load(html);
const titleWithCheerio = $("title").text().trim();
console.log("정규식 사용:", titleWithoutCheerio);
console.log("Cheerio 사용:", titleWithCheerio);
} catch (error) {
console.error("크롤링 실패:", error);
}
}
scrap();cheerio 를 사용하지 않고 정규식으로 html 의 title 을 추출하는 방식과
cheerio 를 사용하는 방식 두가지를 사용해봤습니다.
정규식 사용: ## CONNECTING HEARTS! 디시인사이드입니다. ##
Cheerio 사용: ## CONNECTING HEARTS! 디시인사이드입니다. ##결과는 똑같지만 cheerio 를 사용하는 것이 훨씬 깔끔하고 직관적인 것을 볼 수 있습니다.
그럼 원하는 데이터를 어떻게 가져올 수 있을까요?
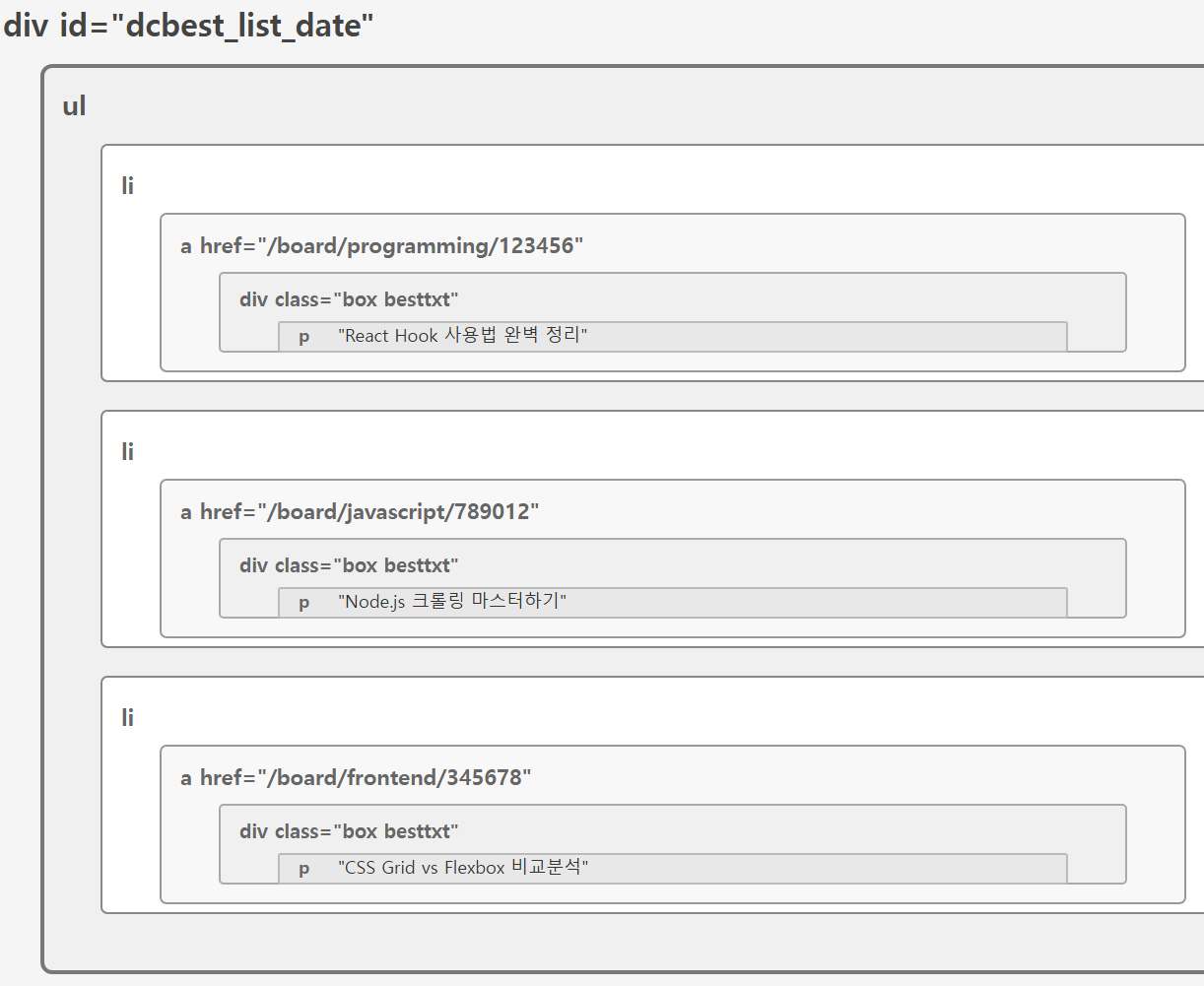
위는 DC 인사이드 의 인기 게시글 목록 구조입니다.
id 가 dcbest_list_date 인 div 아래
ul 아래
li 들 아래
a 안의 href 경로 와
a 아래의 p 태그 안의 게시글 제목
을 추출 하고 싶다고 할 때,
cheerio 코드는 다음과 같습니다.
const $ = cheerio.load(html);
// dcbest_list_date 아래의 li 요소들을 순회
$("#dcbest_list_date ul > li > a").each((index, element) => {
const $link = $(element);
const href = $link.attr("href");
const $bestTextDiv = $link.find(".box.besttxt");
const text = $bestTextDiv.find("p").text().trim();
if (href && text) {
results.push({
href: href,
text: text,
});
}
});아주 쉽죵?
.each 를 통해 반복 요소들을 순회,
.find 를 통해 원하는 태그 찾아내기,
.attr 를 통해 원하는 속성 찾아내기
등을 할 수 있습니다.
=== 크롤링 결과 ===
1. 텍스트: 싱글벙글 방청제(녹방지) 실험
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358824
---
2. 텍스트: [ㅇㅎ] 2003 / Mizuki Kirihara / 桐原美月 / きりはらみづき
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358823
---
3. 텍스트: F6로 갈긴 벨비아50 떴냐.webp
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358821
---
4. 텍스트: 묶어놓고 물려놓고 덮어놨지만 죽을 줄은 몰랐다
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358819
---
5. 텍스트: 미츠토게 성지순례 후기_03
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358818
---
6. 텍스트: 싱글벙글 요즘따라 그리운 분...
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358816
---
7. 텍스트: 울산보도연맹 생존자 인터뷰
링크: https://gall.dcinside.com/board/view/?id=dcbest&no=358814
---이렇게 단순 텍스트를 받는 axios 방식의 단점을 어느정도 해결할 수 있게 됩니다!
두번째 단점 해결법(API 엔드포인트 찾기)
axios 로 JavaScript 로 나중에 렌더링 되는 요소를 크롤링하기 힘드니
API 엔드포인트를 찾아서 직접 요청을 보내고 데이터를 받아오는 방법이 있습니다!
const response = await axios.get('https://api.example.com/data', {
headers: {
'User-Agent': 'Mozilla/5.0...',
'Authorization': 'Bearer token...'
}
});하지만 API 엔드포인트를 찾기 힘들고, 인증이 필요한 경우엔 이 역시도 불가능할 수 있습니다.
🟢 puppeteer
puppeteer 는 위 axios 방식의 문제점을 해결한 라이브러리입니다!
puppeteer 공식 문서에서는 puppeteer 를 아래와 같이 설명하고 있습니다.
Puppeteer는 Chrome이나 Firefox를 제어할 수 있는 고수준 API를 제공하는 JavaScript 라이브러리입니다.
기본적으로 헤드리스(화면에 보이는 UI가 없는) 모드로 실행됩니다.
그럼 실제로 사용해볼까요?
browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto(url);
await page.waitForSelector("#dcbest_list_date");
const links = await page.evaluate(() => {
const container = document.getElementById("dcbest_list_date");
const listItems = container.querySelectorAll("ul > li > a");
const results: Array<{ href: string; text: string }> = [];
listItems.forEach(link => {
const href = link.getAttribute("href");
const bestTextDiv = link.querySelector(".box.besttxt");
const text = bestTextDiv
? bestTextDiv.querySelector("p")?.textContent?.trim()
: "";
if (href && text) {
results.push({
href: href,
text: text,
});
}
});
return results;
});위는 디시인사이드의 베스트 게시글을 크롤링하는 코드입니다. 몇가지 다른 것들이 보이네요.
1. 새로운 브라우저 인스턴스를 시작합니다
browser = await puppeteer.launch();Chrome/Chromium 브라우저를 백그라운드에서 실행합니다.
기본적으로 headless: true로 화면에 보이지 않습니다.
await puppeteer.launch({ headless: false })로 브라우저 실행 모습을 볼 수도 있습니다.
2. 새로운 탭(페이지)을 생성
const page = await browser.newPage();브라우저에서 새 탭을 여는 것과 동일합니다.
3. 지정된 URL로 페이지를 이동시킵니다
await page.goto(url);실제 브라우저에서 URL을 입력하는 것과 동일합니다.
페이지 로딩이 완료될 때까지 대기합니다.
덕분에 CSR 방식이어도 JavaScript를 실행하고, 모든 리소스가 로드될 때까지 기다리기 때문에 정상적으로 크롤링을 진행할 수 있게 됩니다!
4. page.waitForSelector() - 특정 요소 대기
await page.waitForSelector("#dcbest_list_date");왜 필요한가요?
- 페이지가 로드되었다고 해서 모든 콘텐츠가 바로 준비되는 건 아닙니다
- JavaScript로 동적으로 생성되는 요소들은 시간이 더 걸릴 수 있어요
#dcbest_list_date요소가 DOM에 나타날 때까지 기다립니다
다른 대기 옵션들:
page.waitForTimeout(3000)- 단순히 3초 대기page.waitForFunction()- 특정 조건이 참이 될 때까지 대기page.waitForNetworkIdle()- 네트워크 요청이 끝날 때까지 대기
5. page.evaluate() - 브라우저 내부에서 코드 실행
const bestPosts = await page.evaluate(() => {
// 이 코드는 브라우저 내부에서 실행됩니다!
const container = document.getElementById("dcbest_list_date");
const listItems = container.querySelectorAll("ul > li > a");
const results = [];
listItems.forEach(link => {
const href = link.getAttribute("href");
const bestTextDiv = link.querySelector(".box.besttxt");
const text = bestTextDiv ? bestTextDiv.querySelector("p")?.textContent?.trim() : "";
if (href && text) {
results.push({
href: href,
text: text,
});
}
});
return results;
});핵심 포인트:
page.evaluate()안의 코드는 브라우저 내부에서 실행됩니다- 마치 개발자 도구 콘솔에서 코드를 실행하는 것과 같아요
document,window등 브라우저 객체에 직접 접근 가능합니다- 함수의 리턴값이 Node.js 환경으로 전달됩니다
주의사항:
- 브라우저 내부 코드이므로 Node.js 모듈은 사용할 수 없습니다
- 외부 변수에 직접 접근할 수 없어요 (매개변수로 전달해야 함)
🟢 Puppeteer 심화
여러모로 기본 axios를 활용하는 것보다는 puppeteer를 사용하는 것이 좋아보입니다.
그리고! puppeteer 라이브러리의 기능은 위에서 언급한 것뿐만이 아닙니다.
🔴 Page 인터랙션 (Locator)
puppeteer를 활용하면 페이지와 상호작용을 할 수 있습니다.
// 버튼 클릭
await page.locator('button').click();이런 식으로 말이죠!
// input 필드에 텍스트 입력
await page.locator('input').fill('value');이렇게 input 필드에 텍스트를 채워넣을 수도 있습니다.
외에도 다양한 인터랙션 기능들이 있습니다:
// 특정 요소에 마우스 호버
await page.locator('.menu-item').hover();
// 페이지 스크롤
await page.locator('#bottom-section').scroll();
// 요소가 나타날 때까지 대기
await page.locator('.loading-spinner').wait();
// 드롭다운 메뉴 선택
await page.locator('select#category').selectOption('electronics');
// 체크박스 체크
await page.locator('input[type="checkbox"]').check();🔴 실용적인 활용 예시
로그인 페이지 자동화
await page.goto('https://example.com/login');
await page.locator('input[name="email"]').fill('user@example.com');
await page.locator('input[name="password"]').fill('password123');
await page.locator('button[type="submit"]').click();
// 로그인 완료 후 페이지 이동 대기
await page.waitForSelector('.dashboard');검색 기능 사용
await page.locator('#search-input').fill('검색어');
await page.locator('#search-button').click();
await page.waitForSelector('.search-results');
// 검색 결과 데이터 추출
const results = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.search-item')).map(item => ({
title: item.querySelector('h3')?.textContent,
url: item.querySelector('a')?.href
}));
});🔴 추가 유용한 기능들
스크린샷과 PDF 생성
// 전체 페이지 스크린샷
await page.screenshot({ path: 'screenshot.png', fullPage: true });
// 특정 요소만 스크린샷
await page.locator('.chart').screenshot({ path: 'chart.png' });
// PDF 생성
await page.pdf({ path: 'page.pdf', format: 'A4' });쿠키와 세션 관리
// 쿠키 설정
await page.setCookie({
name: 'session',
value: 'abc123',
domain: 'example.com'
});
// 쿠키 가져오기
const cookies = await page.cookies();
console.log(cookies);네트워크 요청 제어
// 네트워크 요청 가로채기
await page.setRequestInterception(true);
page.on('request', (request) => {
if (request.resourceType() === 'image') {
request.abort(); // 이미지 로딩 차단으로 속도 향상
} else {
request.continue();
}
});이런 기능들 덕분에 단순한 크롤링을 넘어서 실제 사용자가 브라우저를 조작하는 것처럼 완전한 자동화가 가능합니다!
자세한 내용은 puppeteer 공식문서에서 확인할 수 있습니다.
마치며...

여기까지 axios 와 puppeteer 를 활용해서 node.js 로 크롤링을 하는 방법에 대해 알아보았습니다!
개인적으로는 두 가지 방법 중 조금 더 활용성이 좋은 puppeteer를 사용할 것 같습니다. 물론 간단한 정적 사이트라면 axios가 더 효율적일 수 있으니, 상황에 맞게 선택하시면 됩니다.
여러분들도 Node.js로 크롤링하는 방법, 잘 알아가셨으면 좋겠습니다!
참고자료
https://www.browserless.io/blog/ultimate-guide-to-puppeteer-web-scraping-in-2025
https://thunderbit.com/ko/blog/web-scraping-with-java-nodejs
https://pptr.dev/
