Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, AdaIN 논문리뷰
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
Huang, X., & Belongie, S. (2017). Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE international conference on computer vision
(pp. 1501-1510).
핵심 아이디어
- Instance Normalization(IN)을 확장
- Batch Normalization(BN), IN, Conditional Instance Normalization(CIN)과 달리 변수를 사용하지 않고 입력받은 스타일을 사용해 Affine 변수를 계산
- 입력받은 콘텐츠의 평균과 분산을 입력받은 스타일의 평균과 분산과 일치하도록 변형
Background
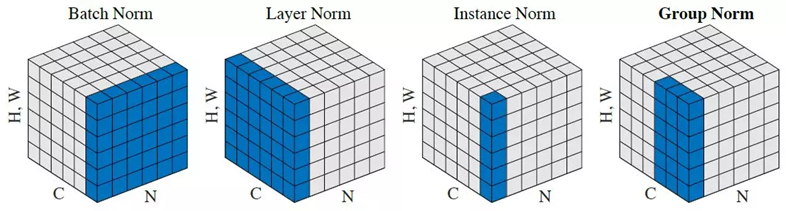
Batch Normalization
BN의 경우 평균 표준편차 계산에서 ,batch (N) 까지의 영역을 기준으로 계산을 진행하여 적용
Instance Normalization
IN의 경우 BN과 유사하게 계산되지만 평균과 분산을 측정하는 부분에서 batch 축을 포함하지 않고 진행한다.
Conditional Instance Normalization
CIN은 학습 과정에서 값을 스타일에 따라 다르게 적용하는 방법을 제안했다. 학습 시에는 스타일 이미지를 각각의 index()로 묶어 처리하고 모델 내부에서 스타일에 따른 를 사용한다. 스타일의 조건을 입력하는 것으로 하나의 네트워크에서 다른 스타일을 생성해낼 수 있다. 제안된 연구에서는 32개의 스타일을 한 번에 학습하는 게 가능했다.
Methods
저자는 affine parameters(의 transformations를 독립적으로 주어지는 스타일에 적용해 content 이미지에 스타일을 적용할 수 있도록 IN을 확장한 Adaptive InstnaceNormalization (AdaIN)을 제안한다.
여기서 x,y는 각각 content,style 이미지의 특징맵 는 체널 축을 기준으로 계산되는 평균과 표준편차를 나타낸다.
AdaIN은 BN,IN,CN과 달리 정규화 과정에서 사용되는 파라미터가 없이 주어지는 스타일 특징에서 평균과 표준편차를 계산하고 정규화된 content 이미지 특징에 스타일의 역으로 입혀 스타일을 변환한다.
여기까지 봤을 때는 통계값을 단순히 입혀 주는것이 어떻게 스타일을 변환하게 되는 것인지 이해가 되지 않았다. 이런 의문은 손실함수 정의에서 해답을 찾을 수 있다. 논문의 손실 함수는 아래와 같이 정의된다.
는 각각 content, style에 대한 손실을 나타낸다.
여기서 는 각각 content, style 이미지, (인코더)는 VGG19 의 레이어(up to *relu4_1 로 표기되어 있다.*)를 나타낸다. g는 디코더를 나타내며 는 생성된 이미지를 의미한다.
은 생성된 이미지의 특징맵과 디코더의 입력전 사용되는 특징맵의 을 사용한다. 저자는 content 이미지의 특징맵을 사용하는 것과 비교해 생성된 이미지를 사용하는 것이 더 빨리 수렴된다고 한다.
여기서 는 VGG19의 레이어를 나타낸다. 연구에서는 “relu1 1, relu2 1, relu3 1, relu4 1”를 사용했다고 한다.
를 보고 위 의문이 해결되었다. 스타일 손실은 생성된 이미지와 입력한 스타일 이미지의 특징을 추출하고 각 특징 공간에서 평균 분산을 최소화하도록 정의되었다. 이를 통해 Gram Matrix를 사용하는 것과 유사하게 스타일을 통일시킬 수 있다.
Architecture
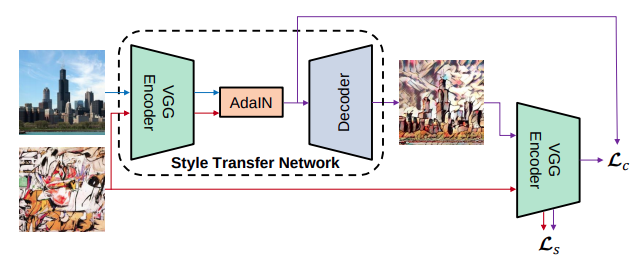
모델은 인코더, Adain , Decoder로 구성되어있다. 인코더는 사전 학습되어진 VGG 네트워크를 사용한다. 입력 받은 두 content, style 이미지를 인코더를 통해 특징을 추출하고 AdaIN을 적용한 특징을 디코더를 통해 복구한다. 학습 과정에서는 Decoder만 학습되며 Decoder는 정규화를 사용하지 않는 것이 가장 좋은 결과를 만들어 낸다고 한다.

Result
저자들은 추출된 특징맵을 사용해 스타일을 적용 정도를 조정하고 나아가 여러 스타일에 대한 interpolation을 수행했다.


Code
논문을 리뷰하고 구현을 진행했다. 구현 시 인코더를 torchvision에서 제공되는 VGG19를 사용할 경우 학습이 원활하게 진행되지 않으니 주의!
구현을 진행하면서 colab으로 간편하게 사용할 수 있도록 제공하는 레포는 많이 있었다. 하지만 어플로 사용할 수 있게끔 만들어놓은 별로 없었다.
다양한 이미지에서 실험을 진행할 필요가 있었고 이번기회로 논문에 접근성을 높이기위해 streamit을 사용해 웹에서 사용할 수 있도록 만들어 보았다. (하단 링크 참고)
참조
