FastAPI로 pytorch Model serving 하기 with Micro Batching
최근 팀에서 서빙 API를 변경할 일이 생겨 포스트를 남긴다.
기존 API의 경우 Flask를 사용해 단일 배치로 Embedding 값을 추출하는 API와 torchserve를 통해 여러 모델이 한번에 올라가 있는 API 2가지 형태로 나누어져 배포되고 있다.
- 전자(Flask)의 경우 Micro batch가 적용되지 않아 API의 GPU 효율이 좋지 못한 상태이고
- 후자(torchserve)의 경우 4~7개의 모델이 하나의 컨테이너에 모여 있어 거대한 문제가 있었다.
발생한 문제는 Flask로 구현한 서버로 요청이 늘어나며 단일 배치로는 들어오는 요청을 감당할 수 없어 서비스가 지연되는 문제가 발생했다. 이번기회에 Micro batch가 적용된 API로 변경하며 글을 작성한다.
Model Serving
Model serving은 웹 서버를 통해 학습된 모델을 REST,gRPC, websocket등을 통해 사용할 수 있는 API를 배포하는 것이다.
모델을 서비스환경으로 서빙하는 몇몇 프레임 워크가 있다.
- torchserve
- tensorflow serving
- kubeflow serving
- Seldon-core
- Bentoml
- MLflow serving
- Redis AI
각각 특색이 있으며 장단점이 있다고 생각한다.
개인적인 프로젝트를 진행할때는 Bentoml을 주로사용하고 있었고 1.0.0에 컨트리뷰트하기 위해 소스코드도 뜯고있던 상황이었지만 아직 프로덕션에서 사용하기에는 실험적이고 torch의 trace module이 바로 구동되지 않는등 여러 문제가 있었다.
따라서 Flask를 FastAPI로 변경하고 Pydantic을 적용, Micro batch 기능이 있는 API를 다시 작성하기로 결정했다.
FastAPI model serving
모델 직렬화
모델의 의존성을 줄이기 위해 가능하다면 직렬화를 진행한다. 학습한 사람과 서빙하는 사람이 다를 경우 직렬화하지 않은 모델을 서빙하는데 이해도, 커뮤니케이션 등 여러 문제가 발생할 수 있기 때문에 가능하면 직렬화해서 모델을 서빙한다.
torch의 경우 torchscript를 통해 직렬화를 진행할 수 있다.
예시를 위해 resnet50 모델을 사용
import torch
import torch.nn as nn
model = torch.hub.load("pytorch/vision:v0.10.0", "resnet50", pretrained=True)
model = list(model.children())
# embedding값을 추출, 클레스 테그를 추출 하는 endpoint를 각각 만들기 위해 모델을 분리
embedding = nn.Sequential(*model[:-1], nn.Flatten()).to("cpu")
classifier = nn.Sequential(*model[-1:]).to("cpu")
# script module로 추출
jit_embedding = torch.jit.script(embedding)
jit_classifier = torch.jit.script(classifier)
print(type(jit_embedding))
# <class 'torch.jit._script.RecursiveScriptModule'>
torch.jit.save(jit_embedding, "embedding.zip")
torch.jit.save(jit_classifier, "classifier.zip")
# trace module로 추출
jit_embedding = torch.jit.trace(
embedding,
example_inputs=torch.rand(1, 3, 224, 224),
)
jit_classifier = torch.jit.trace(
classifier,
example_inputs=torch.rand(1, 2048),
)
print(type(jit_embedding))
# <class 'torch.jit._trace.TopLevelTracedModule'>Basic model serving
- 모델을 로딩
- 전/후 처리 정의
- endpoint 정의
- 모델 추론
대략 이런 방식을 통해 간략한 서빙을 진행할 수 있을것이다.
import typing as T
from PIL import Image
from fastapi import FastAPI, File, UploadFile, status, HTTPException, Query
import torch
from torchvision.transforms.functional import (
normalize,
resize,
to_tensor,
)
MODEL_EMBEDDING_PATH = "./model_store/embedding.zip"
MODEL_CLASSIFIER_PATH = "./model_store/classifier.zip"
DEVICE = "cuda"
with open("imagenet_classes.txt", "r") as f:
CLASSES = [s.strip() for s in f.readlines()]
embedding_mdoel = (
torch.jit.load(MODEL_EMBEDDING_PATH, map_location="cpu").eval().to(DEVICE)
)
classifier = (
torch.jit.load(MODEL_CLASSIFIER_PATH, map_location="cpu").eval().to(DEVICE)
)
# 전처리 함수
def preprocessing(image: Image.Image) -> torch.Tensor:
image = resize(image, (224, 224))
image = to_tensor(image)
image = normalize(
image,
mean=[0.7137, 0.6628, 0.6519],
std=[0.2970, 0.3017, 0.2979],
)
return image.unsqueeze(0)
app = FastAPI()
def imread(image: UploadFile) -> Image.Image:
try:
image = Image.open(image.file).convert("RGB")
except Exception as e:
raise HTTPException(
status_code=status.HTTP_406_NOT_ACCEPTABLE,
detail=f"""{image.filename} is not image file, {e} """,
)
return image
class PredictTag(BaseModel):
name: str
prob: float
@app.post("/predict/embedding", response_model=T.List[float])
def predict_embedding(image: UploadFile = File(...)):
image = imread(image)
tensor = preprocessing(image)
with torch.inference_mode():
tensor = tensor.to(DEVICE)
embedding = embedding_mdoel(tensor)
embedding = embedding.cpu().numpy().tolist()[0]
return embedding
@app.post("/predict/tag", response_model=T.List[PredictTag])
def predict_tag(
image: UploadFile = File(...),
k: int = Query(5, ge=1, le=1000),
):
image = imread(image)
tensor = preprocessing(image)
results = []
with torch.inference_mode():
tensor = tensor.to(DEVICE)
embedding = embedding_mdoel(tensor)
pred = classifier(embedding)
prob = torch.softmax(pred[0], dim=0)
prob = prob.cpu()
print(len(prob))
top_prob, top_catid = torch.topk(prob, k)
top_prob = [prob.item() for prob in top_prob]
results = [
PredictTag(name=CLASSES[index], prob=prob)
for prob, index in zip(top_prob, top_catid)
]
return resultsProject structure refactoring
지금 구조는 단일 파일 그리고 라우터에서 모든 로직을 처리하고 있다.
여기서 프로젝트를 아래와 같이 파일을 나누고 서비스 레이어를 정의해본다.
PROJECT_ROOT_PATH
├── app
│ ├── dependencies.py
│ ├── main.py
│ ├── routers
│ │ ├── __init__.py
│ │ └── resnet.py
│ ├── schema.py
│ ├── services
│ │ ├── __init__.py
│ │ └── resnet.py
│ └── settings.py
├── model_store
│ ├── classifier.zip
│ └── embedding.zip
├── README.md
├── imagenet_classes.txt
└── requirements.txtrouters/resnet.py
router = InferringRouter()
setting = get_settings()
@cbv(router)
class Resnet:
svc: Resnet50Service = Depends()
@router.post("/predict/embedding", response_model=T.List[float])
def predict_embedding(
self,
image: UploadFile = File(...),
):
logger.info("------------- Embedding Start -----------")
image = self.imread(image)
output = self.svc.predict_embedding(image)
logger.info("------------- Embedding Done -----------")
return output
@router.post("/predict/tag", response_model=T.List[PredictTag])
def predict_tag(
self,
image: UploadFile = File(...),
k: int = Body(5, embed=True),
):
...
@router.get("/tags", response_model=T.List[str])
def get_tags(self) -> T.List[str]:
return load_classes()
@staticmethod
def imread(image):
...
return image
servies/resnet.py
env = get_settings()
class Resnet50Service:
def __init__(
self,
embedding_model=Depends(load_embedding_model),
classifier=Depends(load_classifier_model),
classes=Depends(load_classes),
):
logger.info(f"DI: {self.__class__.__name__}")
self.embedding_model = embedding_model
self.classifier = classifier
self.classes = classes
@torch.inference_mode()
def predict_embedding(
self,
image: Image.Image,
) -> T.List[float]:
image = self.preprocessing(image)
image = image.to(env.CUDA_DEVICE)
output = self.embedding_model(image)
output = output.cpu().numpy()[0]
output = output.tolist()
return output
@torch.inference_mode()
def predict_tags(
self,
image: Image.Image,
k: int,
) -> T.List[PredictTag]:
...
return results
@staticmethod
def preprocessing(image: Image.Image) -> torch.Tensor:
image = resize(image, (244, 244))
image = to_tensor(image)
image = normalize(
image,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)
return image.unsqueeze(0)Micro Batch
지금까지 작성한 API의 경우 단일 배치로 추론을 진행한다.
모델을 프로덕션 환경으로 서빙하면서 효율적인 처리를 위해 배치처리는 중요한 문제이다.
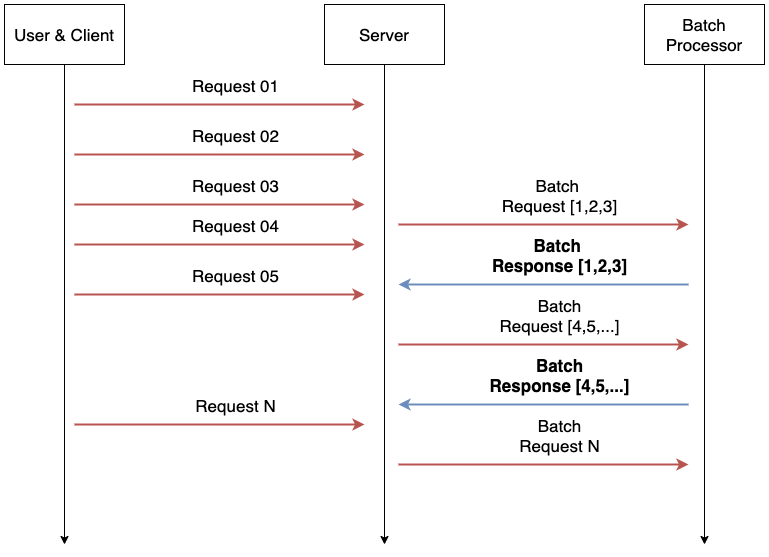
요청이 적을경우는 괜찮지만 여러 요청이 들어올경우 일정 기간 동안 요청을 한 번에 묶어 처리하는 기술이 필요하다. 이런 기능을 Micro Batching 이라고 한다.
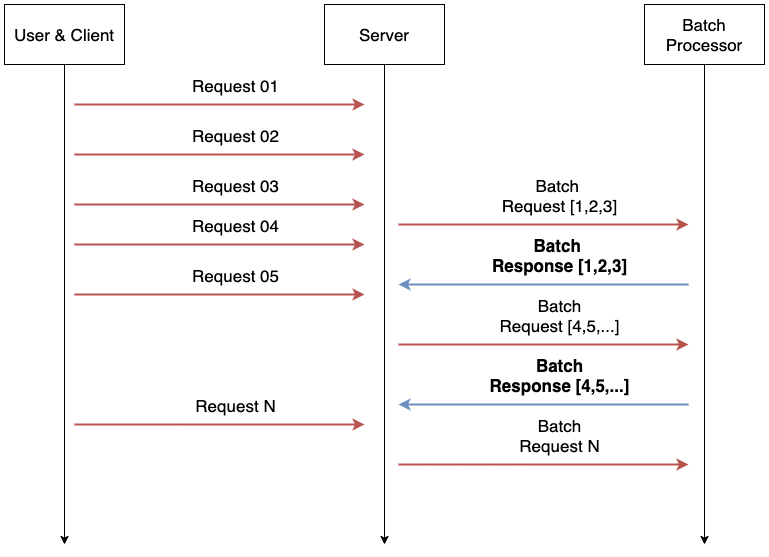
Model serving을 위한 다양한 프레임워크의 경우 대부분 이런 Micro batching 기능을 제공한다. 조금씩 차이는 있지만 최대 배치 사이즈, 최대 응답 시간을 하이퍼파라미터로 입력받아 최대 배치 사이즈의 데이터를 한번에 묶어 처리하는 방식을 사용한다.
FastAPI에는 이런 기능은 제공되지 않지만 service-streamer 프로젝트를 사용해 fastapi에서 Micro batch를 사용할 수 있다.
service-streamer는 아래와 같이 몇 줄의 코드로 Micro batch 기능을 제공한다.
from service_streamer import ManagedModel
class ManagedBertModel(ManagedModel):
def init_model(self):
self.model = Model()
def predict(self, batch):
return self.model.predict(batch)
# Spawn produces 4 gpu worker processes, which are evenly distributed on 0/1/2/3 GPU
streamer = Streamer(ManagedBertModel, 64, 0.1, worker_num=4, cuda_devices=(0, 1, 2, 3))
outputs = streamer.predict(batch)FastAPI Micro batch 적용
managers/resnet.py
class ResnetEmbeddingModelManager(ManagedModel):
def init_model(self):
embedding_model = torch.jit.load(
env.DL_EMBEDDING_MODEL_PATH, map_location="cpu"
)
self.embedding_model = embedding_model.eval().to(env.CUDA_DEVICE)
logger.info("danbooru embedding model init Done")
@torch.inference_mode()
def predict(self, inputs: T.List[torch.Tensor]) -> T.List[torch.Tensor]:
logger.info(f"batch size: {len(inputs)}")
results = []
try:
# 들어온 tensor를 batch로 묶음
batch = torch.cat(inputs, 0).to(env.CUDA_DEVICE)
# test용으로 찍어보자
print("batch_size:", batch.shape)
outputs = self.embedding_model(batch)
outputs = outputs.cpu()
# 결과를 리스트로 바꿔 리턴
results = [output for output in outputs]
except Exception as e:
logger.error(f"Error {self.__class__.__name__}: {e}")
return results
@lru_cache(maxsize=1)
def get_resnet_embedding_streamer():
streamer = Streamer(
ResnetEmbeddingModelManager,
# 최대 배치 사이즈
batch_size=env.MB_BATCH_SIZE,
# 최대 대기 시간
max_latency=env.MB_MAX_LATENCY,
# 최대 대기 시간
worker_num=env.MB_WORKER_NUM,
# cuda visible devices
cuda_devices=env.CUDA_DEVICES,
)
return streamer
services/resnet.py (Micro Batch 적용)
class Resnet50Service:
def __init__(
self,
# service streamer 주입
embedding_streamer=Depends(get_resnet_embedding_streamer),
classifier_streamer=Depends(get_resnet_classifier_streamer),
classes=Depends(load_classes),
):
logger.info(f"DI: {self.__class__.__name__}")
self.embedding_streamer = embedding_streamer
self.classifier_streamer = classifier_streamer
self.classes = classes
@torch.inference_mode()
def predict_embedding(
self,
image: Image.Image,
) -> T.List[float]:
image = self.preprocessing(image)
# 데이터를 리스트로 스트리머로 넘김
output = self.embedding_streamer.predict([image])[0]
output = output.numpy()
output = output.tolist()
return output
@torch.inference_mode()
def predict_tags(
self,
image: Image.Image,
k: int,
) -> T.List[PredictTag]:
image = self.preprocessing(image)
# 여기서는 RAM -> vRAM -> RAM의 반복적인 IO가 발생하기 때문에 더 느려질 수 있음
embedding = self.embedding_streamer.predict([image])[0]
embedding = torch.unsqueeze(embedding, dim=0)
prob = self.classifier_streamer.predict([embedding])[0]
top_prob, top_catid = torch.topk(prob, k)
top_prob = [prob.item() for prob in top_prob]
results = [
PredictTag(name=self.classes[index], prob=prob)
for prob, index in zip(top_prob, top_catid)
]
return resultsMicro batch Test
배치처리가 잘되는지 확인하기 위해 세팅을 다음과 같이 하고
- MB_BATCH_SIZE: 128
- MB_MAX_LATENCY: 2 #sec
- MB_WORKER_NUM: 1
loucust를 사용해 실험해보면 40개의 데이터가 꾸준히 배치로 처리되고 있는 모습을 확인할 수 있다. 사용한 PC의 CPU 사양이 낮아 CPU에서 병목이 발생해 128 배치를 꽉 채울 순 없었지만, 의도한 대로 배치로 데이터를 처리해 반환하고 있다.
api_1 | batch_size: torch.Size([40, 3, 244, 244])
api_1 | batch_size: torch.Size([40, 3, 244, 244])
api_1 | batch_size: torch.Size([40, 3, 244, 244])
api_1 | batch_size: torch.Size([40, 3, 244, 244])LINE Engineering - MLOps를 위한 BentoML 기능 및 성능 테스트 결과 공유 – 2에서 BentoML을 사용한 실험 결과를 보면 배치처리를 진행해도 드라마틱한 성능변화는 볼 수 없지만, 확실히 즉시 처리보다는 데이터를 효율적으로 처리하고 있는 모습은 확인할 수 있다. 모델의 사이즈나 파라미터를 조정해 더 최적의 효율을 확인할 수 있는 여지가 생기게 된다.
총총
모델을 배포하기 위한 다른 여러 방식이 있지만 프레임워크로 변환이 어려운 방식의 모델이나 전처리가 포함되어 있거나, 자유롭게 API를 구성하고 싶을 경우 이런 방식으로 배포를 할수도 있다고 생각한다.
service streamer는 Redis를 사용해 큐를 만들어 사용할 수도 있고 여러 활용 방안이 있어 프레임 워크로 변환이 어려운 경우 사용해볼 만한 프레임 워크인 듯 하다. 대신 Bentoml의 adaptive micro batching과 비교해 미흡한 부분이 많고 비동기로 작업을 사용할 수도 없다. 또한 프로젝트의 마지막 커밋이 2년이 넘어 지금 도입하기에는 위험한 부분이 많은 프로젝트라고 생각된다.
포스팅에 사용된 소스코드는 github에 있습니다.
References
