해당 문서에 사용된 모든 코드는 KorBertSum에 있습니다.
1.Intro
딥러닝 기반의 여러 요약 모델을 공부하고 있던 중, 한국어 데이터로 학습한 추출요약 모델이 있으면 좋겠다 싶어서 만들어 보았습니다. BERT 모델에 관한 기본적인 이해에 관련해서는 좋은 논문 요약본들이 많으니, 몇 개 읽어보시면 모델을 이해하는 데 도움이 될 것 같습니다.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
(1) Abstractive summary, extractive summary
문서 요약에는 두 가지 종류가 존재합니다. 바로 생성요약(abstractive summary)와 추출요약(extractive summary)입니다.
생성요약은 토큰 간의 관계를 계산하여 원래 문서에 포함되지 않은 문장으로 요약을 합니다.
예를 들자면,
나는 오늘 친구와 만났다. 나는 친구와 피자를 먹고 맥주를 마셨다. 나와 친구는 밥을 먹고 보드게임 카페를 갔다. 거기서 할리갈리를 했는데 매우 재미 있었다.
이런 문서를,
나는 오늘 친구와 만나 재미있게 놀았다.
이렇게 요약하는 방식이라 할 수 있겠습니다.
반면 추출요약은 토큰 간의 관계를 계산하여 문서에 포함된 문장으로 요약을 합니다. 구분된 문장 중 중요도가 높은 순으로 n개의 문장을 뽑는다고 생각하면 편합니다. (문장 말고도 다른 토큰을 기준으로 요약할 수 있습니다. 다만 문장이 가장 보편적입니다)
아까 예시로 든 문서을 추출요약으로 요약한다면 이렇습니다.
나는 오늘 친구와 만났다.
중요도가 가장 높은 한 개의 문장을 선택하였기에 많은 정보가 누락되는 결과를 가져옵니다.
다만 추출요약은 생성요약보다 학습 시간과 컴퓨팅 리소스가 적게 드는 장점이 있습니다.
이렇게 문서 요약의 두 방법을 알아보았습니다.
그렇다면 두 방법을 사용하여 문서를 요약했을 때, 문서가 얼마나 잘 요약됐는지는 어떻게 판단할 수 있을까요?
(2) ROUGE Metric
ROUGE Metric은 모델의 요약 능력을 나타내는 자동화된 평가지표입니다.
기본적으로 "사람이 요약한 문장의 단어들이 얼마나 기계 요약에 많이 등장하는지" 측정하는 지표인데요,
ROUGE-N, ROUGE-L 등 다양한 score가 존재합니다. (추후 업데이트 예정)
2. Preparing Datasets
(1) Pre-trained BERT Model
BERT fine-tuning을 위해서는 먼저 사전학습된 BERT 모델이 필요합니다.
이 프로젝트에서는 ETRI(한국전자통신연구원)에서 배포한 형태소 기반 한국어 언어모델을 사용하였습니다.
또한 ETRI와의 사용협약을 준수하기 위해서, ETRI에서 배포한 모델과 그것을 기반으로 fine-tuned 된 모델은 공개하지 않습니다.
따라서 본 파이프라인을 돌리시려면 ETRI 홈페이지에서 모델 사용신청을 하여 BERT Model을 다운로드받으셔야 합니다.
여기에서는 사용신청 후 받으실 수 있는 네 가지 모델 중 파이토치 프레임워크를 사용한 형태소 기반 모델을 사용하였습니다.
(2) Training Pipeline
트레이닝 파이프라인은 BertSum논문과 이를 기반으로 배포한 nlpyang의 Bertsum 코드를 사용했습니다.
다만 사전학습 모델로 한국어 기반 언어모델을 사용하게 되어 코드에 수정사항이 있습니다.
간단하게 BertSum의 트리 구조를 살펴봅시다.
/BertSum
├── bert_config_uncased_base.json ### bert train parameters
├── bert_data ### fine-tuning input data directory
├── json_data
│ └── cnndm_sample.train.0.json
├── LICENSE
├── logs
├── models ### saved model inventory
├── raw_data
├── README.md
├── results ### rouge score result가 저장됩니다.
├── src
│ ├── distributed.py
│ ├── models
│ │ ├── data_loader.py ### input data를 Batch로 가공하고 iterative하게 바꿉니다.
│ │ ├── encoder.py ### 인풋 값을 bert encoding으로 바꿉니다.
│ │ ├── __init__.py
│ │ ├── model_builder.py ### fine-tuning 포워딩 모델입니다.
│ │ ├── neural.py ### classifier, transformer 등 파인튜닝 NN가 있습니다.
│ │ ├── optimizers.py
│ │ ├── reporter.py
│ │ ├── rnn.py
│ │ ├── stats.py
│ │ └── trainer.py ### train, test, valid process
│ ├── others
│ │ ├── __init__.py
│ │ ├── logging.py
│ │ ├── pyrouge.py
│ │ └── utils.py
│ ├── prepro
│ │ ├── data_builder.py ### preprocess 실행파일의 함수들입니다.
│ │ ├── __init__.py
│ │ ├── smart_common_words.txt
│ │ └── utils.py
│ ├── preprocess.py
│ └── train.py
└── urls
├── cnn_mapping_test.txt
├── cnn_mapping_train.txt
├── cnn_mapping_valid.txt
├── mapping_test.txt
├── mapping_train.txt
└── mapping_valid.txt수정사항
pytorch update에 따른 boolean matrix problem 수정
BertSum/src/models/data_loader.py, line 31,33mask = 1 - (src == 0) -> mask = ~(src == 0) mask_cls = 1 - (clss == -1) -> mask_cls = ~(clss == -1)
BertSum/src/models/encoder.py, line 97x = self.transformer_inter[i](i, x, x, 1 - mask) -> x =self.transformer_inter[i](i, x, x, ~mask)
Batch 함수의 인덱싱 수정
BertSum/src/models/data_loader.py, line 45,47src_str = [x[-2] for x in data] -> src_str = [x[4] for x in data] tgt_str = [x[-1] for x in data] -> tgt_str = [x[5] for x in data]
한국어 pre-trained 모델 사용을 위해 BertSum/src/prepro/data_builder.py에 tokenizer class 추가, 한글 데이터 처리를 위해 convert_to_unicode 함수 추가
forward propagation을 통한 빠른 summary를 위해 BertSum/src/models/trainer.py에 summary 함수 추가, summary argument BertSum/src/train.py 에 추가
해당 수정사항들을 반영한 코드는 KorBertSum에 있습니다.
(3) Train Dataset
fine-tuning을 위한 훈련 데이터 셋은 Dacon 한국어 문서 추출요약 경진대회의 데이터셋을 활용하였습니다.
해당 데이터는 4만여개의 기사 텍스트와 그 기사의 abstractive, extractive summary(3 sentences) 피쳐를 가지고 있습니다.
데이터는 dacon 사이트에서 받으실 수 있습니다.
3. Preprocess
(1) POS Tagging
우리의 학습 데이터를 BERT 모델의 인풋으로 넣어주기 위해서는 몇 가지 거쳐야 할 과정들이 있습니다. 기본적으로 우리는 형태소 기반 BERT 모델을 사용할 예정이기 때문에 먼저 형태소 분석이 필요합니다.
한국어 문장에 대한 형태소 분석의 방법은 크게 두 가지가 있습니다.
첫 번째는 형태소 분석 패키지를 사용하는 것입니다. 파이썬에서는 KoNLPy에 포함되어 있는 Komoran, Okt, MeCab 등으로 형태소 분석을 해볼 수 있습니다.
둘째로 형태소 분석 API를 사용하는 방법이 있습니다. 여기에선 ETRI의 형태소 분석 API를 사용할 예정입니다. 형태소 분석의 결과가 비교적 정확하고, 태그셋이 동일 기관의 BERT과 일치하는 점을 고려하여 선택하였습니다.
ETRI 형태소 분석 API를 사용하려면 사용승인 신청을 하고 API key를 발급받아야 합니다.
etri-api-scraper.py를 실행시켜 형태소 분석 결과를 얻으실 수 있습니다.
실행 예시)
python etri_api_scraper.py --input '.../train.jsonl' --api_key 'your openapi key' --first_index 0 --last_index 10000해당 문장이
나는 오늘 친구와 만났다.
형태소별로 나누어지는 것을 볼 수 있습니다.
나/NP 는/JX 오늘/NNG 친구/NNG 와/JKB 만나/VV 았/EP 다/EF ./SF
하루에 10,000개의 호출 제한이 있습니다. 4만 2천여개의 기사를 모두 처리하려면 최소 5일이 걸릴 것입니다. 다만 단순히 파이프라인을 실행시키고 결과를 얻을 목적이라면 10,000개의 기사로도 학습이 가능합니다.
형태소 분석된 기사들은 article_morp 라는 column name으로 원래 데이터를 csv로 만든 파일에 추가해줍니다.
csv 파일 예시)
| media | id | article_original | article_morp | abstractive | extractive |
|---|---|---|---|---|---|
| 신문사 | 기사번호 | 기사원문 | 형태소분석된 기사 | 생성요약 | 추출요약 |
여기서는 train, valid, test를 각각 80%, 10%, 10%로 나누어줬습니다.
실행하실 때는 CSV file을 train, valid, test를 적당한 비율로 나누어서 따로 저장해 주시고,
article_to_json.py의 input으로 주시면 됩니다.
article_to_json.py를 실행하시면 korean.train.17.json 이런 식으로 저장이 됩니다. 원 논문과 같은 방식대로 6개의 기사를 묶어서 하나의 json file로 저장해 주었습니다.
실행 예시)
python article_to_json.py -mode train -news_dir '' -output ''실행 결과물을 json_data folder에 추가해줍니다.
(2) Embedding
BertSum 논문에 나온 대로 임베딩을 해 줍시다. BERT input에는 세 가지 임베딩이 있다는 것을 배웠습니다. token, segment, position embedding이 그것입니다.
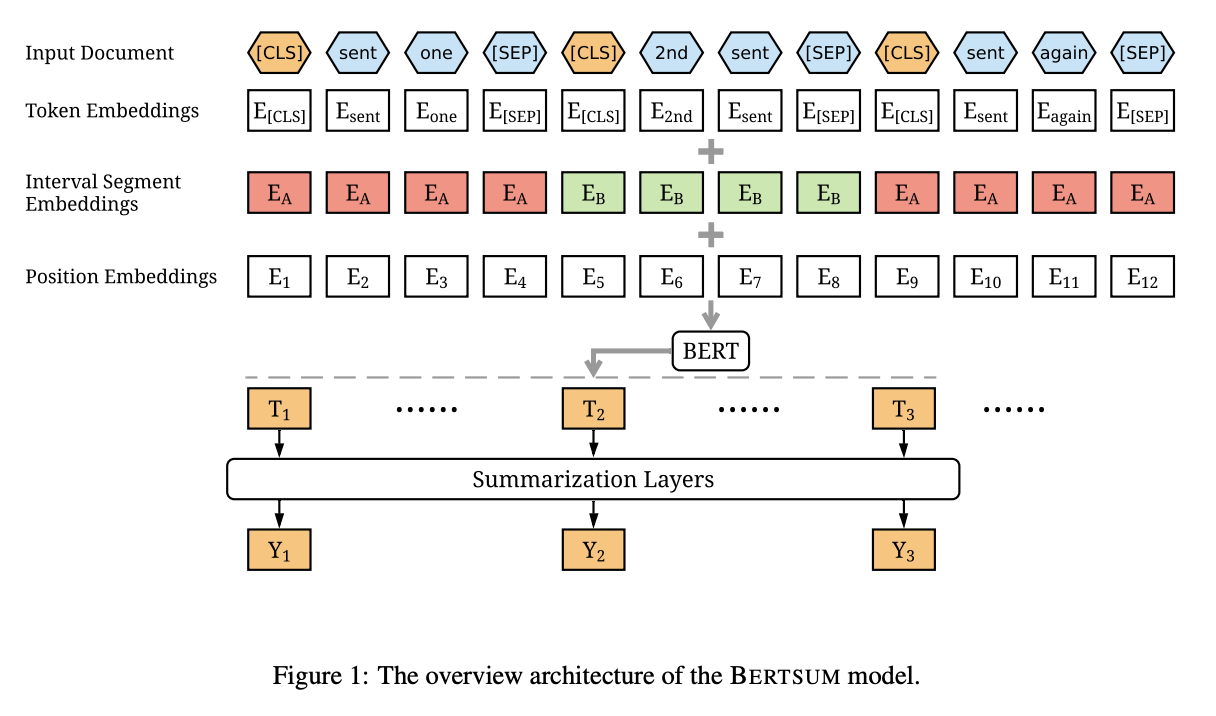
먼저 논문에 나온 대로 문장의 시작에 CLS, 문장의 끝에 SEP 토큰을 넣어 줍니다. 마침표 토큰(./SF)은 텍스트를 문장별로 split 할 때 split 토큰으로 사용되며 사라집니다.
[CLS] 나/NP 는/JX 오늘/NNG 친구/NNG 와/JKB 만나/VV 았/EP 다/EF [SEP]
ETRI-BERT 모델을 다운받으면 단어/형태소 쌍의 인덱스가 저장된 BERT 사전이 있습니다. 해당 사전은 BERT의 토큰과 단어/형태소 쌍을 연결해 주는 역할을 합니다.
이 사전을 사용해서 토큰을 BERT index로 바꾸어 준다면 Token Embedding이 됩니다.
아래는 실제 값이 아닌 토큰 임베딩 예시입니다
1, 23, 576, 1769, 235, 657, 65, 42, 4, 2
Segment Embedding은 논문대로 홀수 번째 문장을 0, 짝수 번째 문장을 1로 해서 입력하면 됩니다.
Position Embedding은 논문대로 [CLS] 토큰의 포지션값을 저장해 주면 됩니다.
결과값은 list of Dictionary로 만들고 파이토치 텐서로 만들어 bert_data 폴더에 저장해 줍니다.
결과값 예시입니다.
mydict['src'] -> token embedding
mydict['label'] -> 라벨값입니다. 요약문에 포함된 문장이면 1, 아니면 0으로 구성되어 있습니다.
mydict['segs'] -> segment embedding
mydict['clss'] -> position embedding
mydict['src_txt'] -> propagation 후 형태소 분석된 문장을 원 문장으로 복구하는 데 쓰입니다.
mydict['tgt_txt']
해당 작업은 preprocess.py 로 구현되었습니다. BertSum 원 데이터를 한국어 모델에 맞게 수정하였습니다.
python preprocess.py -mode format_to_bert -raw_path ../json_data -save_path ../bert_data -vocab_file_path 'etri vocab file list'결과물은 bert_data 폴더에 저장해 줍니다.
4. Train, validation, test
bert_data 폴더의 preprocess된 파일과 ETRI BERT Model이 준비되었다면 본격적으로 모델 학습을 시작할 수 있습니다.
먼저 실행 코드를 봅시다.
- ML Framework
- Python 3.7.10
- Pytorch 1.8.1
python train.py -mode train -encoder classifier -dropout 0.1 -bert_data_path /content/bert_data/korean -model_path ../models/bert_classifier -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 1000 -decay_method noam -train_steps 1000 -accum_count 1 -log_file ../logs/bert_classifier -use_interval true -warmup_steps 8000 -bert_model 'ETRI BERT model Path' -bert_config_path 'ETRI BERT Config Path' -temp_dir .어? encoder가 뭐지? 생각하실 수도 있습니다. BERT Model은 기본적으로 비지도 학습 모델이기 때문에, 라벨 output node와 연결시켜 주기 위해 fine-tuning layer를 필요로 합니다.
아까 보여드렸던 그림입니다.
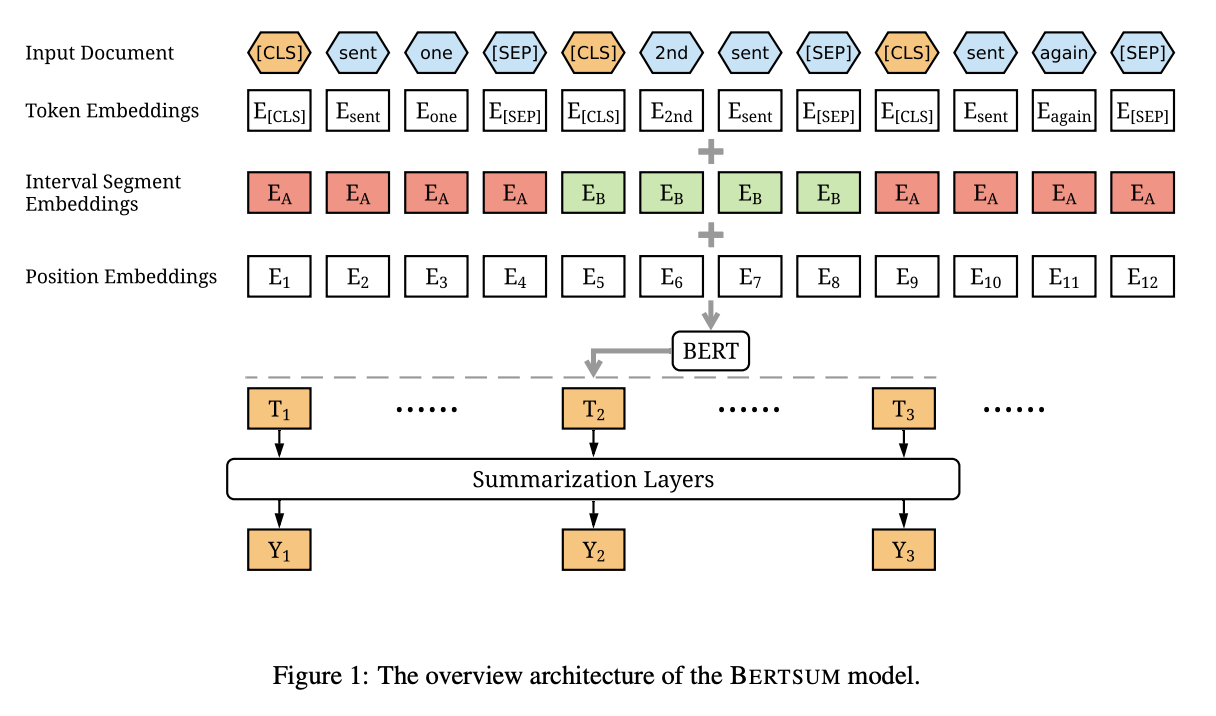
여기서 Summarization layers를 argument의 encoder로 볼 수 있습니다. BertSum 논문에서는 Simple Classifier, Transformer, RNN 세 가지 encoder를 시도했는데, Transformer가 가장 성능이 좋다고 나왔습니다. 저는 일단 가장 간단한 classifier encoder로 학습을 시도하겠습니다. (단순 sigmoid output을 내는 encoder입니다)
학습은 Colab Pro 환경에서 20-30분 정도 걸립니다. 학습이 완료되면 모델 output이 model_path에 저장됩니다. 이 모델을 사용하여 validation과 test도 진행 가능합니다.
해당 학습 과정은 Newsdata_extractive_summ.ipynb 에 자세히 나와 있습니다.
5. Summary Bot
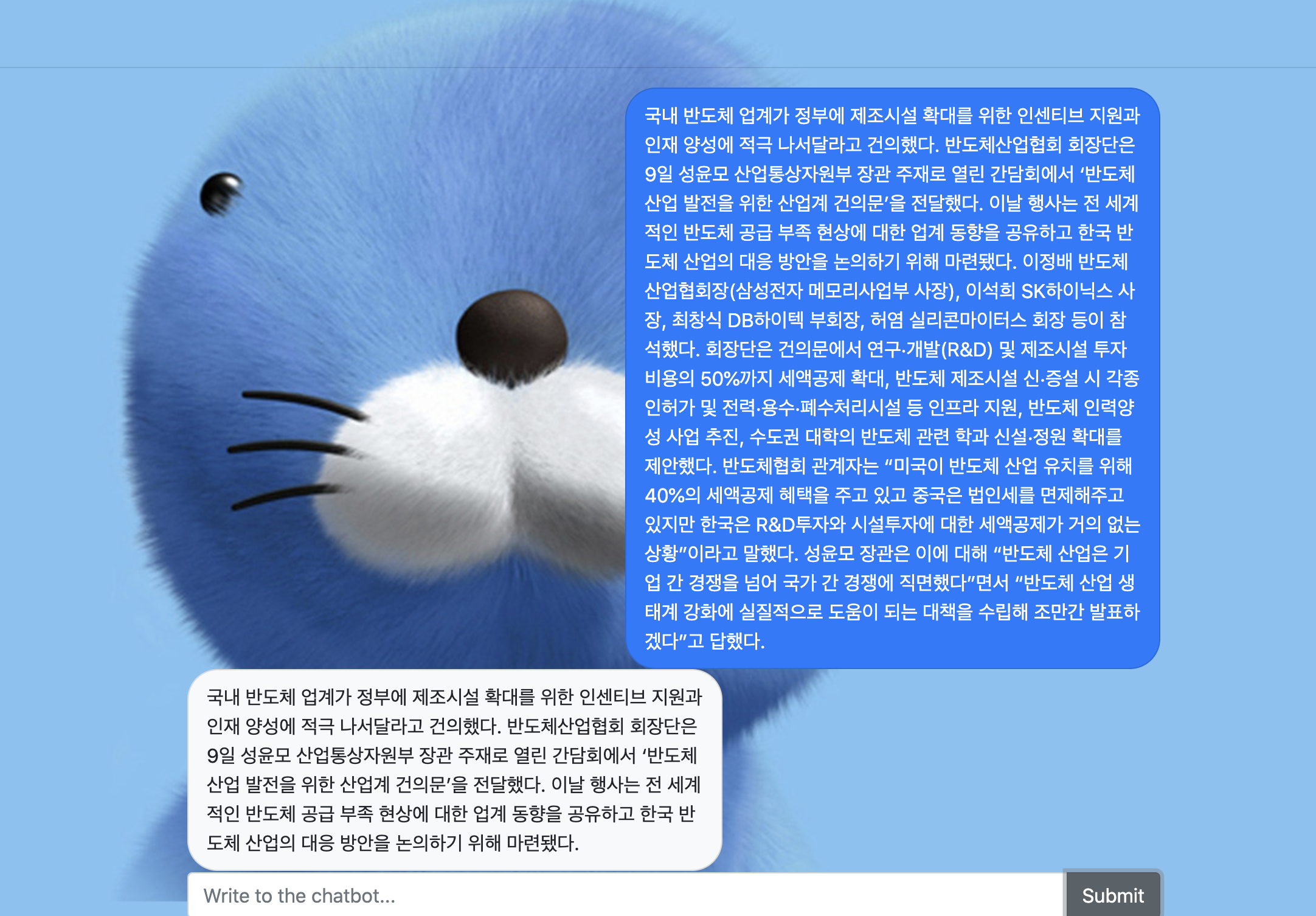
지금까지의 파이프라인을 쭉 이어서 Summary Bot을 만들었습니다.
문장입력부터 추출요약까지 모두 자동화되어 5초 안에 결과를 받아보실 수 있습니다.
summary 결과는 sent_score가 높은 순대로 나오는 리스트입니다.
pred_lst = [0,3,6,2,5,1,4]여기서 세 문장으로 추출요약을 한다면 0,3,6번째 문장이 요약의 결과물이 되겠습니다.
코드의 편의성과 가독성을 위해 일부러 bert data input의 threshold를 여유롭게 두었습니다.
해당 코드는 Newsdata_summarybot.ipynb 에 있습니다.
ETRI api-key와 BERT Model이 필요합니다! ETRI 홈페이지에서 사용승인신청을 해주세요. 사용협약 때문에 모델을 공개하지 않는 점 양해 바랍니다.
모델의 실행 결과는 dash로 구현하였습니다. 예시로 뉴스 하나를 긁어와서 요약해 보겠습니다.
3문장으로 추출 요약된 것을 볼 수 있습니다. 혹시 추출요약 문장의 개수를 조절하고 싶으시다면 run_chatbot 함수의 pred_lst 변수를 수정해주시면 됩니다.
첫 글이라 두서 없고 잘못 설명한 부분도 있을 수 있습니다. 혹시 내용이나 코드 실행 관련해서 질문이 있으시다면 적극적으로 해주시기 바랍니다!
잘 부탁드립니다.

21개의 댓글

위 질문과 비슷한데....input csv파일 만드는데 어려움이 있어서 여쭤봅니다.
이제는 1일 5000건으로 제한이 생겨서...약 10일에 걸쳐서 output0 ~ output49999까지 생성했습니다.
문제는 이걸 csv로 바꾸는건데.........혹시 10000건에 대해서 전부 수작업으로 csv로 만드셨나요?

실례지만 혹시 etri-api-scraper.py를 구체적으로 어떻게 실행하는지 파이썬 코드를 알려주실 수 있으신지요? ETRI에서 API는 발급받았지만 위에 글에 쓰신 것처럼 딱 필요한 형태소분석 결과만 얻고 싶은데요. ETRI에 문의해도 복잡한 샘플만 받고 친절한 답변을 못 얻었습니다. 텍스트를 읽어들이면 단순하게 다음 같은 결과만 보고 싶은데요...
나/NP 는/JX 오늘/NNG 친구/NNG 와/JKB 만나/VV 았/EP 다/EF ./SF

안녕하세요 preprocess.py 과정에 대해서 질문드려요
임베딩 전까지 잘 따라가서 json_data 폴더에 korean.train.0.json ... 여러개의 train json파일을 만들었습니다.
preprocess를 실행하니
FileNotFoundError: [Errno 2] No such file or directory: './bert_data\bert.pt_data\korean.train.0.bert.pt' 라는 에러가 발생하는데 save_path에 왜 문제가 발생하는지 모르겠습니다
-vocab_file_path 부분에는 001_bert_morp_pytorch/vocab.korean_morp.list 를 지정해줬습니다.

안녕하세요 저번에 댓글 남기고 모델 학습 및 봇 만드는 과정에서 문제가 생겨 다시 한번 댓글 남깁니다.
우선 Newsdata_summarybot.ipynb 파일의 5. html for SummaryBot 부분은 코드 동작을 알기 위해 run_chatbot 함수 부분만 따로 동작시켜 보았는데요.
summary() 함수 호출 시
RuntimeError: Error(s) in loading state_dict for BertModel:
size mismatch for bert.embeddings.word_embeddings.weight: copying a param with shape torch.Size([30349, 768]) from checkpoint, the shape in current model is torch.Size([30522, 768]).
이런 오류가 납니다.
이 오류가 Newsdata_extractive_summ.ipynb 파일에서 train 후 validate, test 하는 과정에서도 났었는데 bert_config.json 파일을 임시로 수정해 실행했었습니다.
혹시 어떻게 해결할 수 있는지 아실까 해서 다시 댓글 남깁니다.
BERT dictionary 길이 오류는 해결되었는데 Trainer 클래스 summary 함수에서 오류가 나네요. 어떤 부분을 고쳐야 해결될지 혹시 아실까 하여 댓글 다시 남깁니다. https://drive.google.com/uc?id=1JmMZSfHDe9iOmUtU6Hyl6EG2rxiiI7HL
Newsdata_summarybot.ipynb의 News_to_input 함수에서 b_data_list를 작성할 때 b_data_dict = {"src":tmp[0],
"labels":[0,1,2],
"segs":tmp[2],
"clss":tmp[3],
"src_txt":tmp[4],
"tgt_txt":'hehe'}
가 혹시 "labels": tmp[1], "tgt_txt":tmp[5]인가요?
그리고 BertData 클래스의 preprocess 함수에서
labels = None
tgt_txt = None
와 같이 labels와 tgt_txt에 None이 들어가는 것이 맞는지도 궁금합니다.

안녕하세요~ train validate test 과정 중 질문이 생겨 댓글 남깁니다 train과 test는 이상 없이 잘 작동되는 듯 하나, validate 과정에서 colab 환경이 6시간 이상 멈추지 않는데 raqoon님께서 validate를 하실 땐 이런 오류가 없었는지 궁금합니다......
안녕하세요 이 글을 참고하며 bert 학습을 하는 중 막히는 부분이 생겨 댓글 남깁니다. article_to_json.py 실행 부분에서 미리 만들어 둔 csv 파일이 존재해야 하는 건가요? etri-api-scraper.py를 실행시켜 얻은 형태소 분석 결과를 article_to_json.py 파일을 통해 json file로 만드는 걸로 이해했는데 아니면 형태소 분석 결과 파일이 csv 파일로 존재해야 하는 걸까요? 그렇다면 이 부분은 작성한 글 내용에는 없고 제가 손수 알아서 csv 파일을 만든 후에 진행해야 하는 걸까요? 어렵네요…