
Cache(캐시)
캐시는 광범위하게 사용되는 개념인데, 임시로 데이터를 저장하는 역할을 하는 공간들을 뜻한다.
CPU내에도 캐시 공간이 있고 서비스에서도 캐시 서버를 따로 두기도 하며, DB에서도 필요에 따라 캐시를 사용하기도 한다.
(용어는 캐시로 같이 쓰이지만 각각 가리키는 공간은 다르다.)
그렇다면 캐시는 왜 사용하는 걸까?
캐시는 원본 데이터가 이미 저장되어 있는 상황에 별도의 공간을 두고 동일한 데이터를 저장하고 그 데이터에 접근하게 되는데, 이렇게 되면 중복으로 데이터가 공간을 차지하게 된다.
그럼에도 불구하고 캐시를 사용하는 이유는 빠른 처리 속도를 위해서 이다.
한번 읽어온 데이터를 임의의 공간에 저장해서 다음에 같은 데이터에 접근해야할 때 빠르게 결과값을 받아올 수 있게 한다.
예를들어, DB에서 한번 읽어온 데이터를 어딘가에 임의로 저장해 놓으면 같은 요청이 왔을 때 DB까지 데이터 요청을 보내지 않고 캐시 공간에서 데이터를 가져오면 DB서버의 부하를 줄여줄 수 있고, 더 빠르게 데이터를 가져올 수 있다.
Redis
캐시 서버를 구축할 때 가장 많이 사용되는 것이 바로 Redis이다.
Redis는 시스템 메모리를 사용하여 데이터를 저장하는, Key-Value 데이터 스토어 솔루션이다.
MySQL과 같은 데이터베이스와 비교하면 데이터 저장이라는 공통점은 있으나, 데이터가 저장되는 방식과 저장 위치에 큰 차이가 있고 저장되는 데이터의 성격도 달라진다.
디스크가 아닌 메모리에 접근하여 데이터를 관리하기 때문에 관계형DB에 비해 속도가 빠르다는 장점이 있다.
또한 다양한 데이터 타입을 지원하고 있어, 단순 문자열 뿐만 아니라 Hash나 List와 같은 자료형을 저장할 수 있어 개발의 편의성도 높다.
데이터를 메모리에 저장한다는 것은 바꿔말하면 서버가 종료되면 데이터가 사라지는 휘발성이라는 특징을 갖는다는 것을 뜻한다.
그런데 Redis는 인메모리 기반임에도 영속성을 지원한다.
다만, 영속성이 지원되더라도 관계형DB 만큼 안정적으로 데이터를 저장한다고 볼 수 없기 때문에, 영구적으로 저장해야하는 중요한 데이터를 저장하기 보다는 주로 캐시 서버의 용도로 많이 사용된다.
Redis 서버를 구축할 때에는 여러 방법이 있다.
- 하나의 인스턴스 필요
- Single
- 여러 서버의 인스턴스 필요
- Sentinel : Master-Slave가 정상 동작하는지 모니터링하며, 문제가 생겼을 경우 조치해주는 모듈
- Cluster : 여러 개 서버를 묶어서 하나의 시스템처럼 동작하게 하는 방식
Redis 설치
Redis 설치는 이곳에서 할 수 있다.
사용자의 OS에 맞는 것을 선택하면 설치 가이드가 상세하게 나와있으니 그대로만 따라하면 된다.
나의 경우 MacOS 사용자이기 때문에 가이드에 따라 터미널에서 설치를 진행했다.
사실 MacOS의 경우 brew가 설치되어 있다면 Redis 설치가 정말 간단하다.
👉 brew install redis
이게 끝이다. 이렇게 입력하고 엔터키를 누르면 알아서 설치가 진행되고 완료된다.
설치가 완료되고 redis-server라고 입력후 엔터를 누르면, 아래와 같이 6379포트에 standalone mode로 서버가 뜬 것을 확인할 수 있다.
redis-server로 서버를 띄우게 되면 터미널 창을 껐을 때 다른 터미널 창에서 서버를 사용할 수 없게 되는데, 이런 경우에는 brew services start redis라고 입력하고 엔터를 쳐주면 터미널 창을 켜도 다른 터미널에서 사용이 가능하다.
(서버 종료는 brew services stop redis)
Redis 명령어
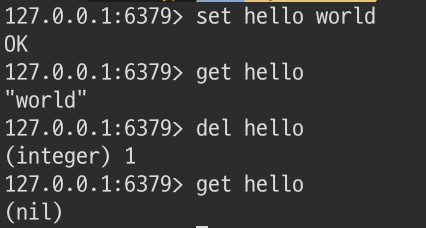
- $>set myKey myValue
- 원하는 key와 value를 입력해주면 쌍으로 저장된다.
- $>get myKey
- key를 입력하면 그에 해당하는 value를 찾을 수 있다.
- $>del myKey
- 삭제하고 싶은 데이터의 key를 입력하면 value를 삭제한다.
- $>keys *
- 모든 키를 조회하는 명령어.
성능에 지장을 줄 수 있기 때문에 서비스 운영환경에서는 사용하지 않는 것이 좋다.
- 모든 키를 조회하는 명령어.
위의 명령어들을 사용해보면...
스프링에서 Redis에 접근하기
1. 의존성 추가(Gradle)
build.gradle에 아래와 같이 의존성을 추가해준다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'2. Redis관련 설정(application.yml)
spring:
redis:
host: localhost -> ip주소 입력
port: 63793. @EnableCaching
Main 클래스에 @EnableCaching 어노테이션을 붙여 캐시 기능을 사용할 수 있게 해준다.
@SpringBootApplication
@EnableCaching
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}4. config
생성된 config 정보를 LettuceConnectionFactory에 설정 정보로 넣어서 인스턴스를 생성해주면, RedisConnectionFactory Bean을 사용할 수 있게 된다.
@RequiredArgsConstructor
@Configuration
public class CacheConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Bean
public RedisConnectionFactory redisConnectionFactory() { // RedisConnection 관리
// cluster
RedisClusterConfiguration conf = new RedisClusterConfiguration();
//single
RedisStandaloneConfiguration conf = new RedisStandaloneConfiguration();
conf.setHostName(host);
conf.setPort(port);
return new LettuceConnectionFactory(conf);
}
}이렇게 생성된 Bean은 Redis와 Connection을 맺을 수 있는 ConnectionFactory만 생성된 상태이고, 이것을 캐시에 적용시켜 사용하기 위해서는 CacheManager Bean을 생성해 주어야 한다.
@Bean
public CacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory) {
RedisCacheConfiguration conf = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
return RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(conf)
.build();
}Redis 자바 시스템 외부의 캐시 서버이기 때문에 데이터를 저장하기 위해서는 Sericalization(직렬화)가 필요하다.
데이터를 가져올 때에도 물론 역직렬화가 필요하다.
5. @Cacheable
캐시 기능을 사용하고 싶은 기능을 하는 메소드에 @Cacheable어노테이션을 붙여준다.
요청한 데이터가 캐시에 저장되어있지 않은 경우에는 해당 메소드가 실행되어 데이터를 가져오지만 Redis에 저장이 되어 있는 경우에는 DB가 아닌 Redis에서 저장되어 있는 데이터를 가져온다.
// 회사 이름을 받아 배당금 정보를 가져오는 기능
@Cacheable(key = "#companyName", value = "finance")
public ScrapedResult getDividendByCompanyName(String companyName) {
log.info("search company -> " + companyName); //처음 데이터가 저장될 때만 출력된다.
CompanyEntity company = companyRepository.findByName(companyName)
.orElseThrow(() -> new RuntimeException("존재하지 않는 회사명입니다."));
List<DividendEntity> dividendEntities = dividendRepository.findAllByCompanyId(company.getId());
List<Dividend> dividends = dividendEntities.stream()
.map(e -> new Dividend(e.getDate(), e.getDividend()))
.collect(Collectors.toList());
return new ScrapedResult(new Company(company.getTicker(), company.getName()), dividends);
}