스크래핑
HTML문서를 가져온 후, 문서를 파싱(Parsing)해서 필요한 데이터를 추출하는 것이다.
그러나 아무 사이트에서나 데이터를 가져와도 되는 것은 아니다.
데이터는 회사의 중요 자산이고 스크래퍼를 위해 Request 할 때, 해당 사이트의 서버부하가 있을 수도 있다.
또한, 사이트에서 스크래퍼가 접근을 못하게 막는 경우도 있고, 너무 잦은 데이터를 수집할 경우에는 개별적으로 IP를 차단시킬 수도 있다.
위와같은 문제점들이 있어 스크래핑을 할 때에는 충분한 주의가 필요하다.
robots.txt
그러면 어떤 데이터를 스크래핑 할 수 있는지 어떻게 알 수 있을까?
각 사이트에서는 규칙을 정해두고 있다.
웹 사이트의 루트 경로에서 robots.txt를 치고 엔터를 누르면 확인할 수 있다.
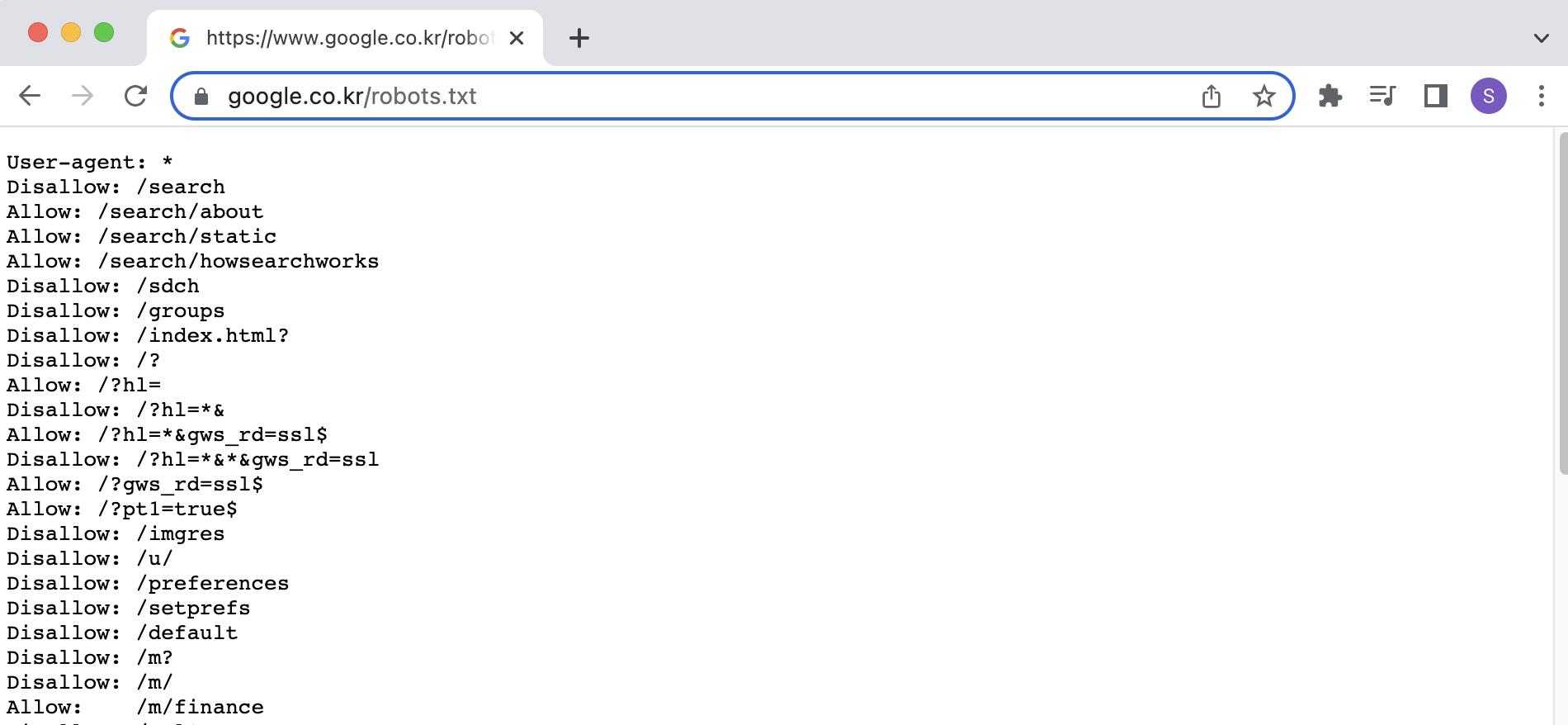
구글 robots.txt
네이버 robots.txt
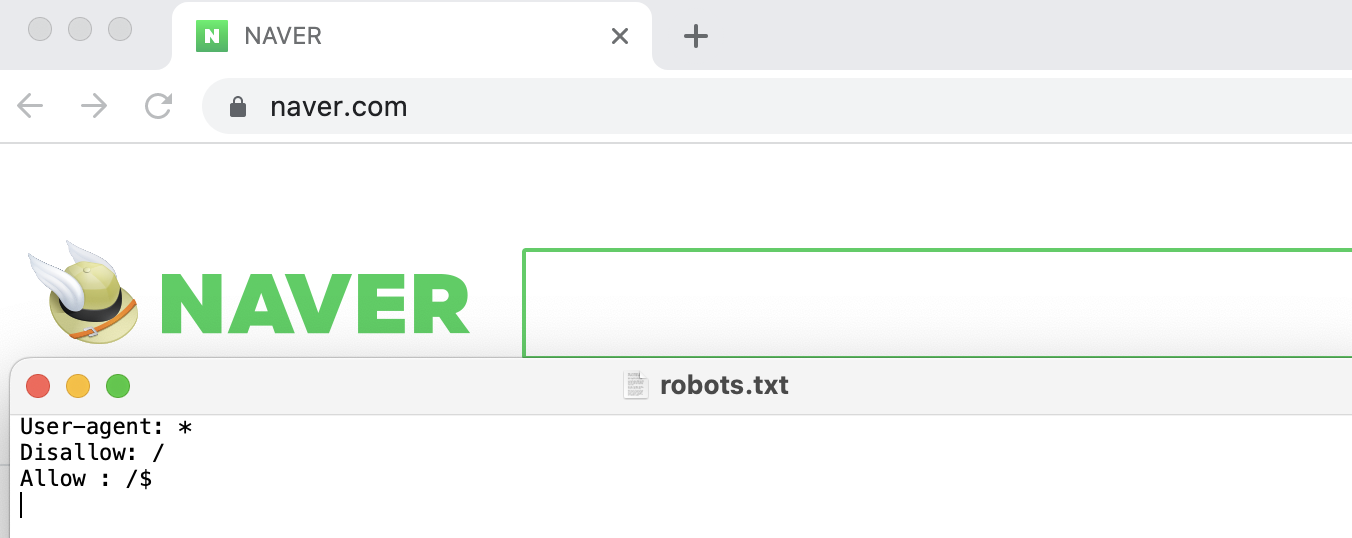
위의 사진을 보면 알 수 있듯 스크래핑 해도 되는 부분은 Allow, 스크래핑이 불가한 부분은 Disallow로 정의되어 있으니 확인하고 스크래핑을 진행하면 된다.
💡스크래핑을 할 때의 주의사항
robots.txt에 정의된 규칙을 준수할 것
데이터 사용이 가능하더라도 웹 서버에 무리가 가지 않는 선에서 요청할 것
스크래핑 하기
가져오고자 하는 데이터가 어디에 위치하고 있는지를 먼저 확인한 후, 해당 사이트의 루트 경로에서 robots.txt를 확인한다.
Disallow 항목 중에 원하는 데이터의 위치가 포함되어 있지 않다면 그 데이터는 사용가능하다.
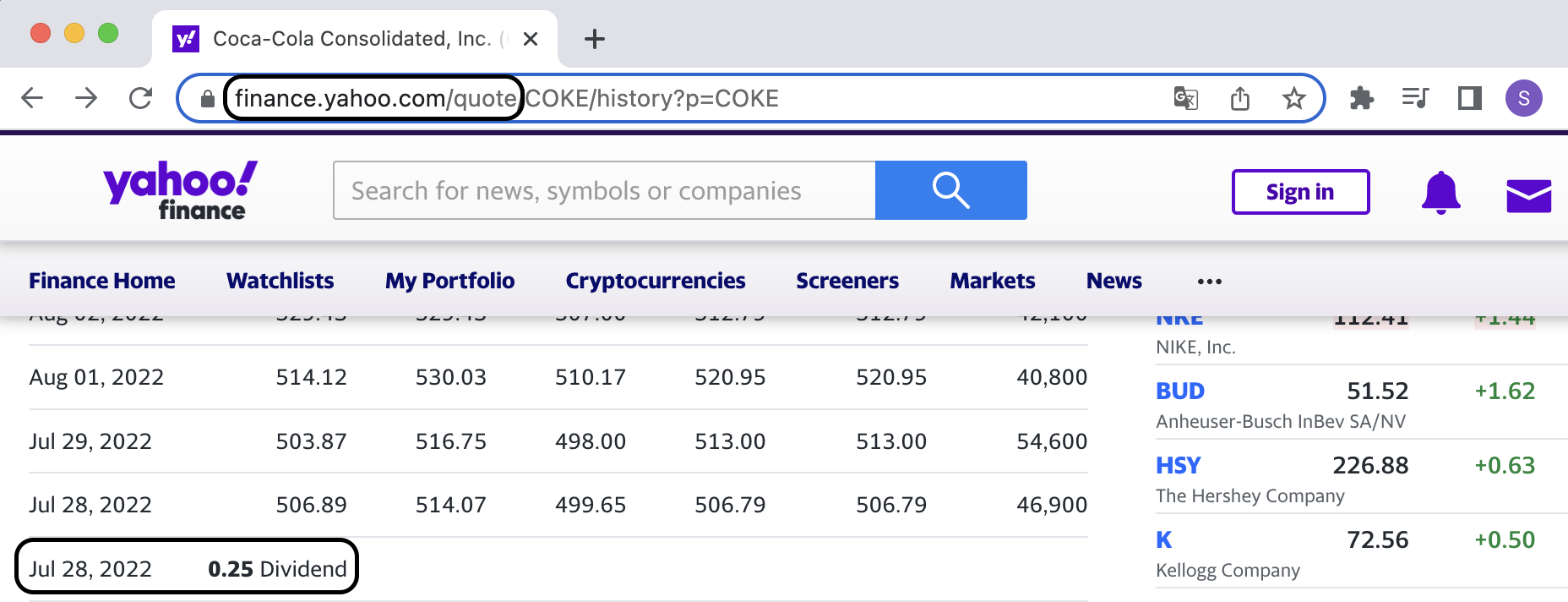
예를들어, 주식 배당금 정보를 가져오려고 한다.
원하는 데이터는 finance.yahoo.com/quote/에 위치하고 있는 것을 확인할 수 있다.
robots.txt를 확인했더니 /quote는 Disallow 항목에 포함되어 있지 않으므로 위의 데이터는 사용이 가능하다는 것을 알 수 있다.
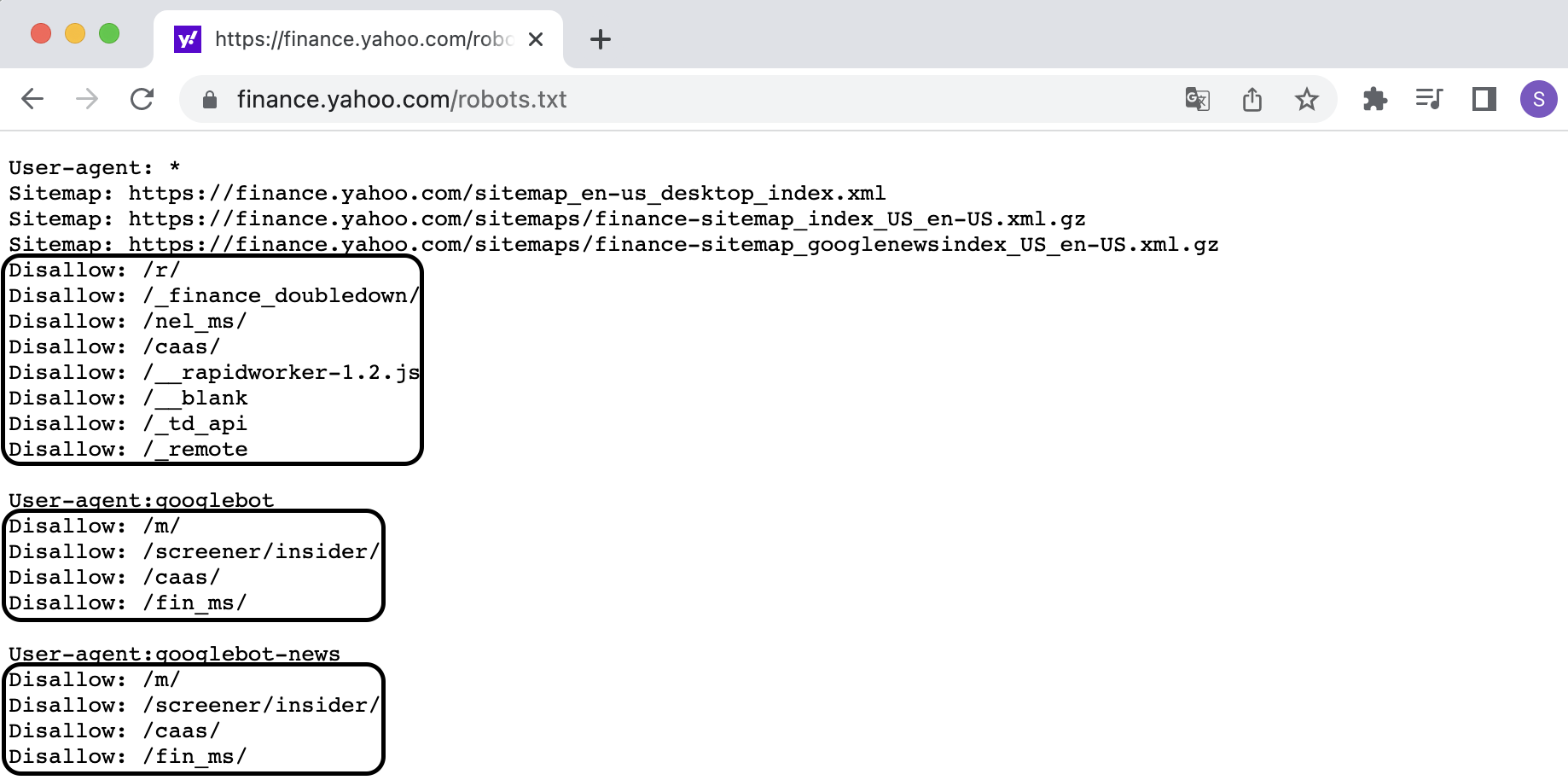
💡위에서도 말했듯이 Disallow에 포함되어 있지 않더라도 무한정 데이터 요청을 보내서는 안된다.
