
출처 : 데브원영 - 아파치 카프카 강좌
카프카 설치
EC2 인스턴스에 들어가서 카프카 설치
wget https://downloads.apache.org/kafka/3.3.2/kafka-3.3.2-src.tgz
tar xvf kafka_2.12-3.3.2.tgz
cd kafka_2.12-3.3.2
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m" // 카프카 힙 메모리 조정
echo ${KAFKA_HEAP_OPTS} // 설정값 확인설정 조작
cd ~/kafka-3.3.2-src/config
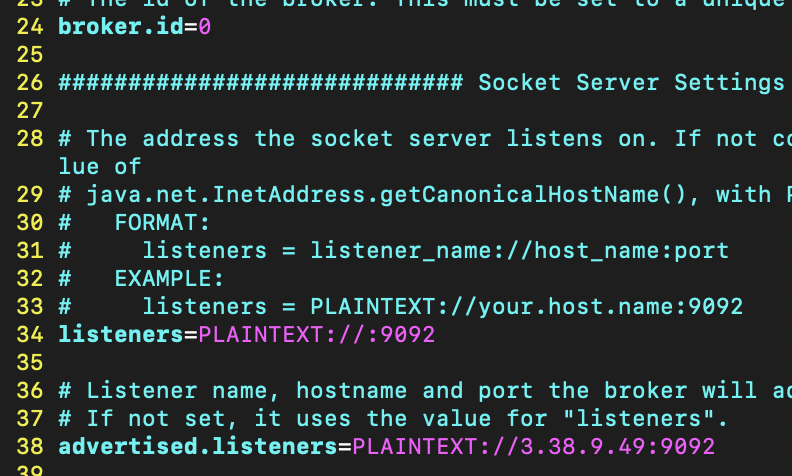
vi server.propertiesserver.properties
- broker.id=0 (24열) : 브로커 고유값. 클러스터로 형성할 시 각각의 아이디가 달라야 한다.
- 34열 주석해제하기 : listeners=PLAINTEXT://:9092
- 38열 주석해제하기 : advertised.listeners=PLAINTEXT://{IP주소}:9092
zookeeper 실행하기
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
jps // 자바 프로세스 조회
주키퍼인 QuorumPeerMain가 떠있다.
카프카 실행하기
bin/kafka-server-start.sh -daemon config/server.properties
jps
tail -f logs/* // 카프카 로그 조회
정상적으로 실행되었다.
로컬에서 카프카 접속하기
카프카 cli 설치
curl https://archive.apache.org/dist/kafka/3.3.2/kafka_2.13-3.3.2.tgz --output kafka.tgz터미널에서 카프카 다루기
cd kafka_2.13-3.3.2/bin
// 1. 테스트 토픽 생성
./kafka-topics.sh --create --bootstrap-server {aws ec2 public ip}:9092 --replication-factor 1 --partitions 3 --topic test
// 2. 토픽에 데이터 넣기
./kafka-console-producer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test
// 3. 들어간 데이터 "모두" 확인하기
./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test --from-beginning
// 4. 그룹별로 데이터 확인하기
./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test -group testgroup --from-beginning
// 5. 생성된 그룹 확인하기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --list
// 6. 그룹 세부정보 확인하기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --describe
// 7-1. 그룹 오프셋 되돌리기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic test --reset-offsets --to-earliest --execute
// 7-2. 그룹 오프셋의 특정 파티션만 되돌리기 --topic {토픽:파티션} --to-offset {되돌릴 위치}
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic test:1 --reset-offsets --to-offset 10 --execute1~3. 토픽 생성 / 프로듀서에서 데이터 입력 / 컨슈머에서 데이터 조회
// 1. 테스트 토픽 생성
./kafka-topics.sh --create --bootstrap-server {aws ec2 public ip}:9092 --replication-factor 1 --partitions 3 --topic test
// 2. 토픽에 데이터 넣기
./kafka-console-producer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test
// 3. 들어간 데이터 확인하기
./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test --from-beginning프로듀서에서 만든 데이터가 컨슈머에서 확인되는 것을 볼 수 있다.
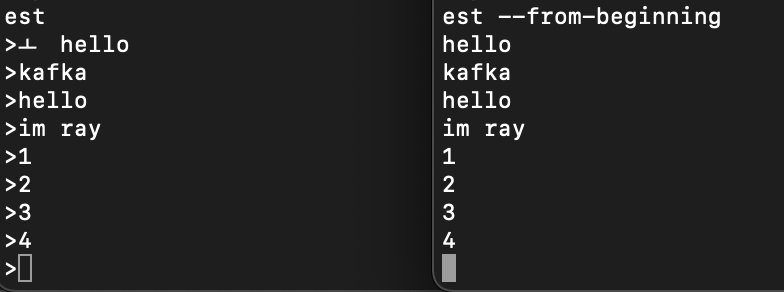
4. 그룹별로 데이터 확인하기
// 4. 그룹별로 데이터 확인하기
./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test -group testgroup --from-beginning테스트 그룹을 지정한 경우 해당 그룹이 어디까지 읽었는지 카프카에 기록된다. 따라서 다시 동일한 명령어를 수행하면 이전에 읽은 내용 다음부터 출력된다.
5. 생성된 그룹 리스트를 확인한다.
// 5. 생성된 그룹 확인하기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --list
6. 그룹 세부정보 확인하기
// 6. 그룹 세부정보 확인하기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --describe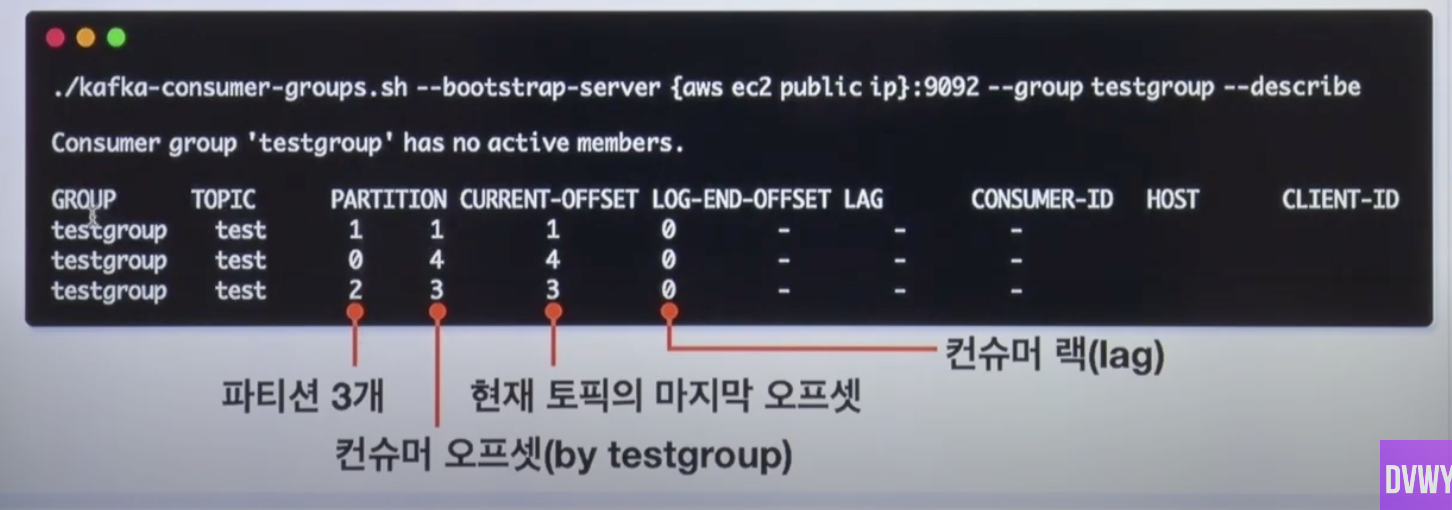

7. 그룹의 오프셋 데이터 리셋하기
// 7-1. 그룹 오프셋 되돌리기
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic test --reset-offsets --to-earliest --execute
// 7-2. 그룹 오프셋의 특정 파티션만 되돌리기 --topic {토픽:파티션} --to-offset {되돌릴 위치}
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic test:1 --reset-offsets --to-offset 10 --execute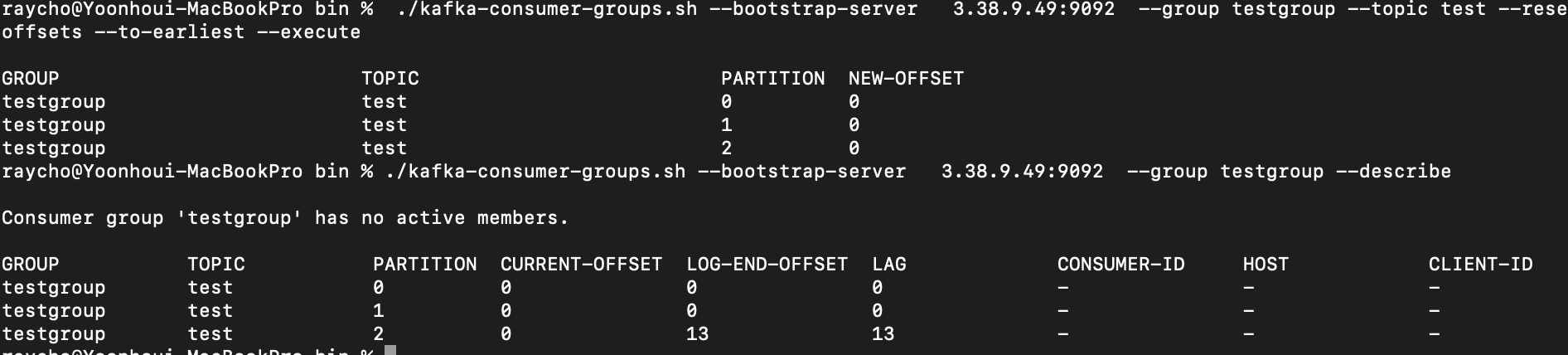
카프카 프로듀서
❗️카프카 브로커 버전과 dependency 버전이 일치해야 한다!!!❗️
build.gradle
implementation 'org.apache.kafka:kafka-clients:3.3.2'
카프카 브로커 에 record 보내기
// 생성자
ProducerRecord(String topic, V value)
ProducerRecord(String topic, K key, V value)
ProducerRecord(String topic, Integer partition, K key, V value)
// 예시
ProducerRecord<K, V> record = new ProducerRecord<>(TOPIC_NAME, Integer.toString(index), data)서비스 요구사항에 맞는 생성자를 사용하면 된다.
- key - 필요 시에 사용, 안쓰면 null로 처리된다.
- 파티션 번호 직접 지정 가능
Record key
- 메시지를 구분하는 구분자 역할
- 동일 키는 동일 파티션에 적재되도록 보장된다.
- 활용
- 하나의 키 → 순서 보장 → State machine으로 사용 가능!
- key에 따른 컨슈머 분리 가능 — 주문 처리 컨슈머는 주문이 들어오는 파티션만 / 결제 처리 컨슈머는 결제 파티션만 읽으면 된다.
- 키에 레코드의 해쉬값을 넣어 중복처리 방지
Producer acks
acks = 0 : 속도 빠름/ 유실 가능성 높음
- 브로커에 전송 후 확인메시지 x
acks = 1 (default) : 속도 보통 / 유실 가능성 있음
- 리더 파티션에 저장되었는지 확인
- 리더 파티션의 브로커가 죽을 경우 유실 가능!
acks = all or -1 : 속도 느림 / 유실 가능성 없음
- 리더 파티션의 데이터가 팔로워 파티션에 복제될때까지 기다린다.
- reflication = 1 이면 acks=1과 동일하다!
Options

카프카 컨슈머
- 데이터를 polling한다
- commit을 통해 읽은 consumer offset을 카프카에 기록한다.
Commit
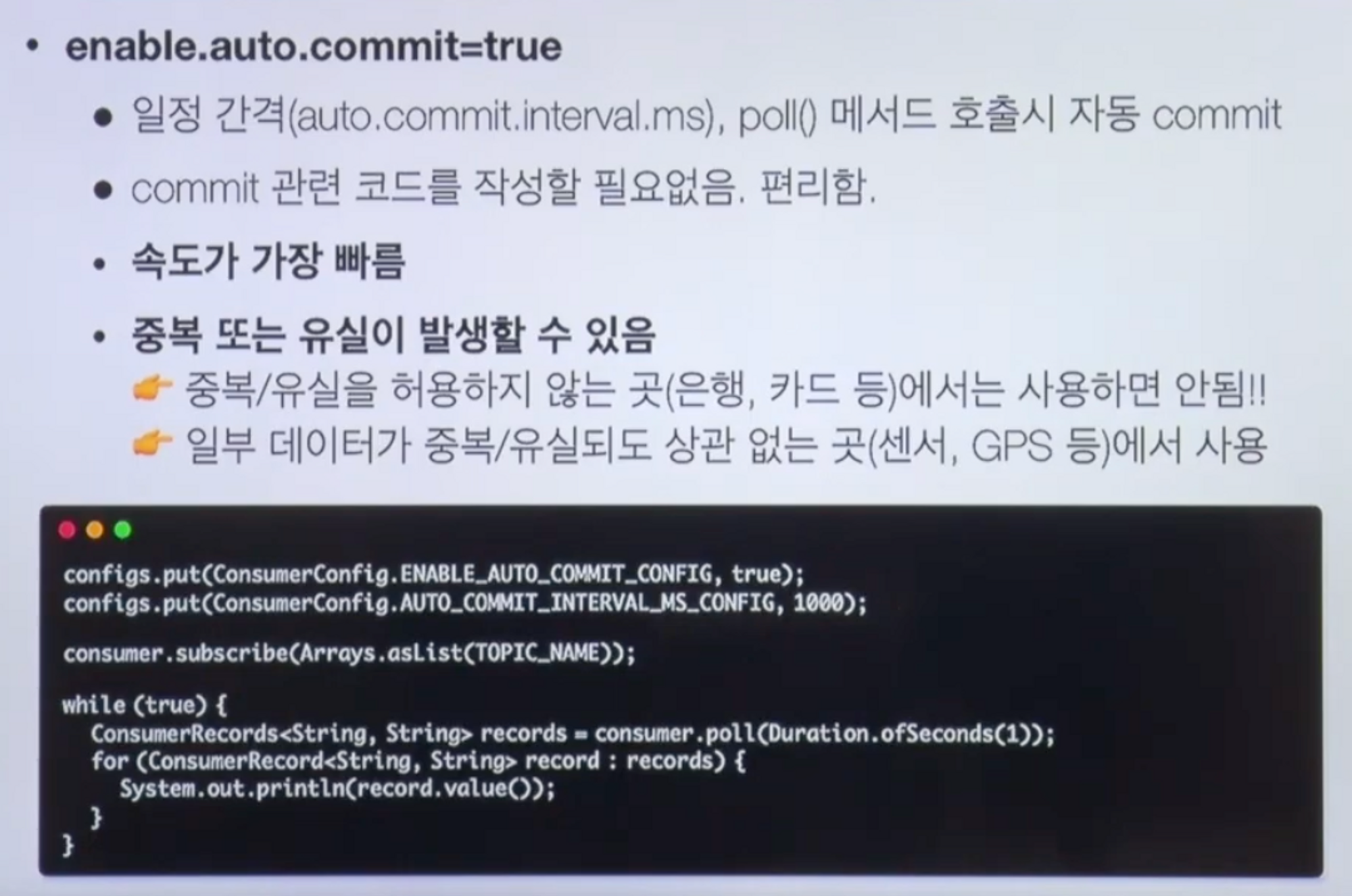
ENABLE_AUTO_COMMIT
- commit 직접 처리하지 않아도 됨
- 속도가 가장 빠름
- but 중복/유실 발생가능!!
commitSync
- 순서 보장하여 커밋
commitAsync
- 동기커밋보다 빠름
- 중복 발생 가능!
...
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
...
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value()); // 작업 수행
}
consumer.commitSync();
}wake up 전략
클라이언트 셧다운시 중복/유실 방지
{
...
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
consumer.commitSync();
}
} catch (WakeupException e) {
System.out.println("WakeupException");
} finally {
consumer.commitSync();
consumer.close();
}
}
public void shutdown() {
consumer.wakeup();
}📚참고문헌

한걸음씩 성실히