딥러닝 이미지 영상 비정형데이터
머신러닝 정형데이터=table데이터=엑셀데이터
여러 모델을 돌려 고성능인 것을 찾는 것이 아니다!(특별한 경우를 제외하고)
모델이 바뀌는 것은 작업프로세스상 중요한 것이 아니다!
=> 결국 집중해야 할 것은 데이터!!! 데이터 그 자체에 집중하고 데이터에서 답을 얻자
<Ensemble 앙상블 기법>
: 여러 개의 학습기를 생성하고 그 예측을 "결합"함으로써 보다 정확한 예측을 도출하는 기법
: 전통적으로 Voting(보팅), Bagging(배깅), Boosting(부스팅), 스태깅 등으로 나눔
- 보팅, 배깅: 여러 개의 분류기가
투표를 통해 최종 예측 결과를 결정
(한 번에 병렬적인 결과) - 부스팅:
순차적인 학습
결정방법
-하드보팅: 다수결
-소프트보팅
: 확률의 평균을 취해 높은것 채택
: but 확률의 평균이 동률일 경우 다수결
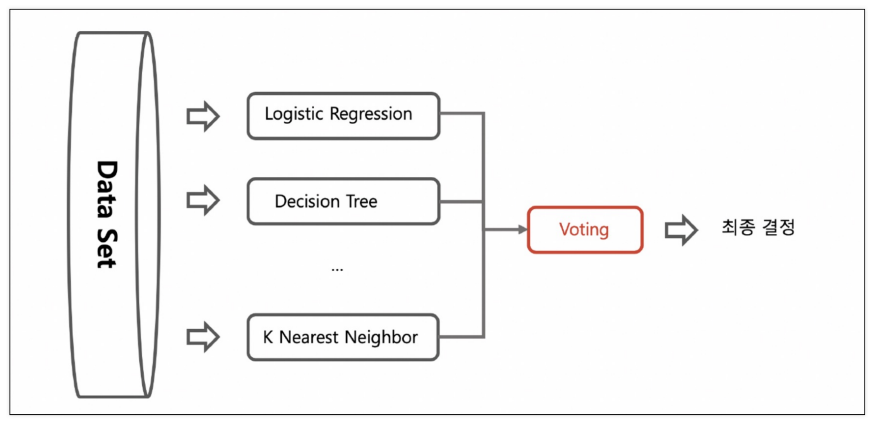
voting 기법
: 전체 데이터셋에 여러 모델(알고리즘)을 돌려 결정. 다수결의 원칙으로 선택
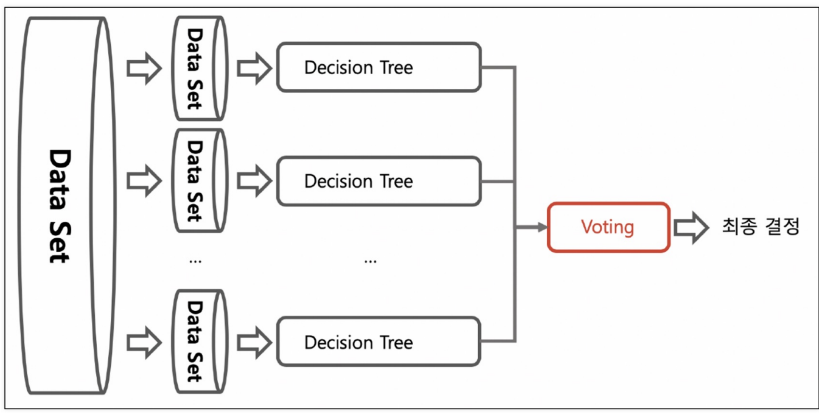
bagging 기법(Bootstrap AGGregatING)
: 데이터셋을 랜덤하게 샘플링하여 똑같은 모델(알고리즘)을 돌려 결정.
bagging계열에 앙상법 기법은 Decision Tree알고리즘을 사용
샘플링해서 추출하는 방식을 부트스트래핑(bootstrapping)분할 방식(중복 허용)
- Random Forest
: bagging 기법(Decision Tree 여러 개를 돌려 부트샘플링) + 투표(소프트보팅)
: 앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여줌
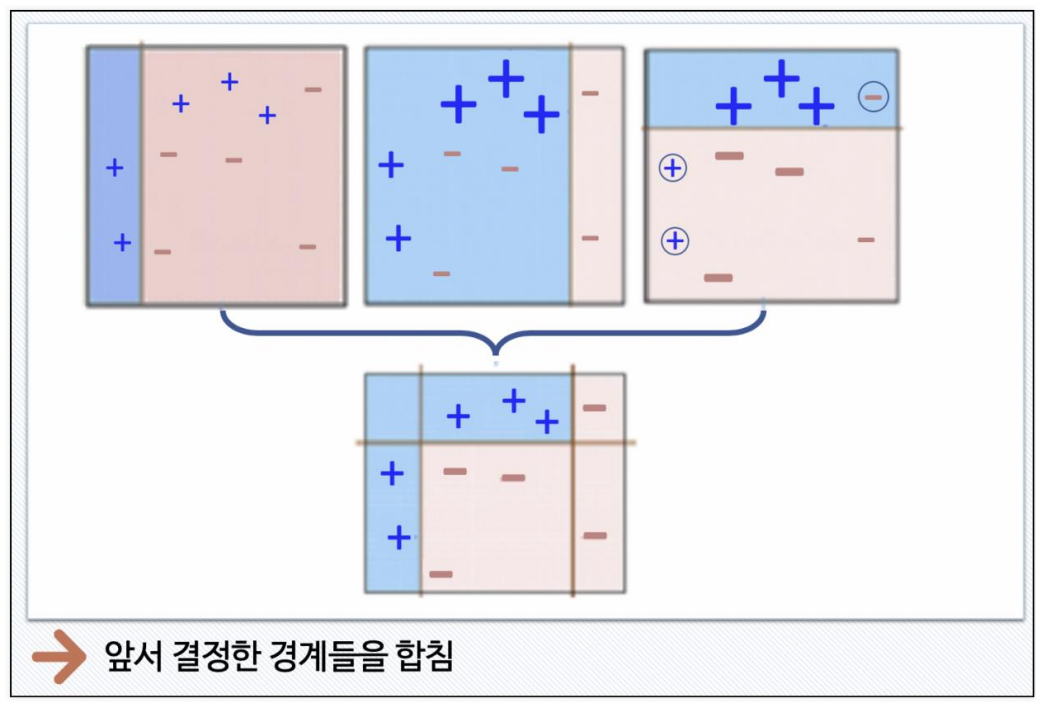
Boosting 기법
: 여러 개의 (약한)학습기가 순차적으로 학습. 앞에서 학습한 예측이 틀린 데이터에 대해 다음 학습기에 가중치를 부여해 오류를 개선해 학습 진행
(약한)분류기? 속도가 빠르지만 성능이 떨어지는. 예로 math_depth가 2
인 decision tree
-
Adaboost
: Decision Tree 기반 순차적 가중치 부여해 최종 결과
-
GBM(Gradient Boost 그래디언 부스트)
: 가중치를 업데이트할 때 경사하강법(Gradient Descent)이용
(일반적으로 성능이 랜덤 포레스트보다 좋음. But 속도가 아주 느림) -
XGBoost(eXtra Gradient Boost)
: 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나로 GBM 기반의 알고리즘. 느린 속도를 다양한 규제로 해결. 특히 병렬 학습 가능. 반복 수행 시마다 교차검증(최적화시 조기 중단)
- 주요 파라미터 -
LightGBM
: 가장 각광받는 알고리즘 중 하나. 큰 장점은 속도!
(단, 적은 수의 데이터에는 어울리지 않음)
스태깅
wine 데이터 다시 활용
- StandardScaler 사용
- 간단한 EDA
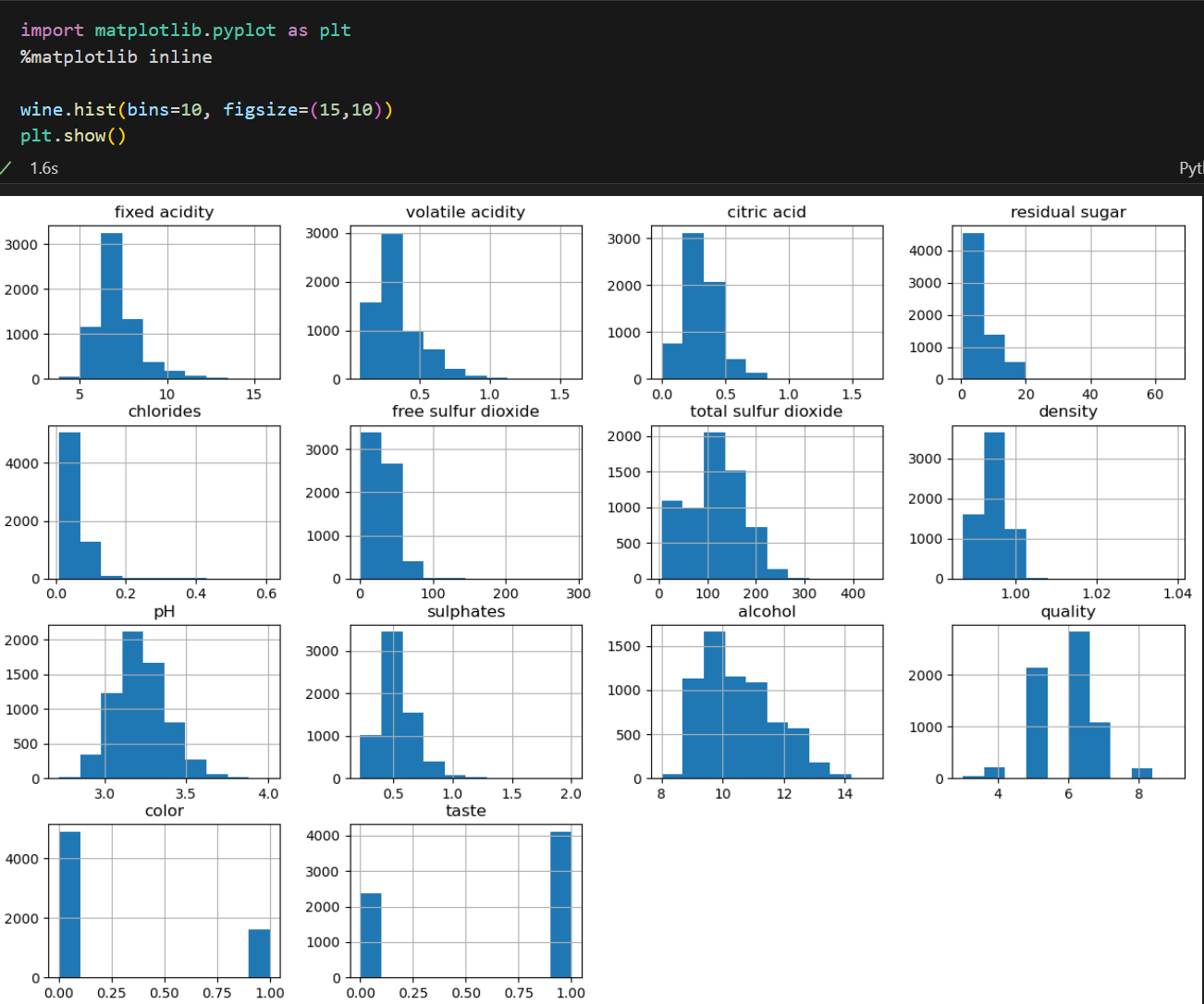
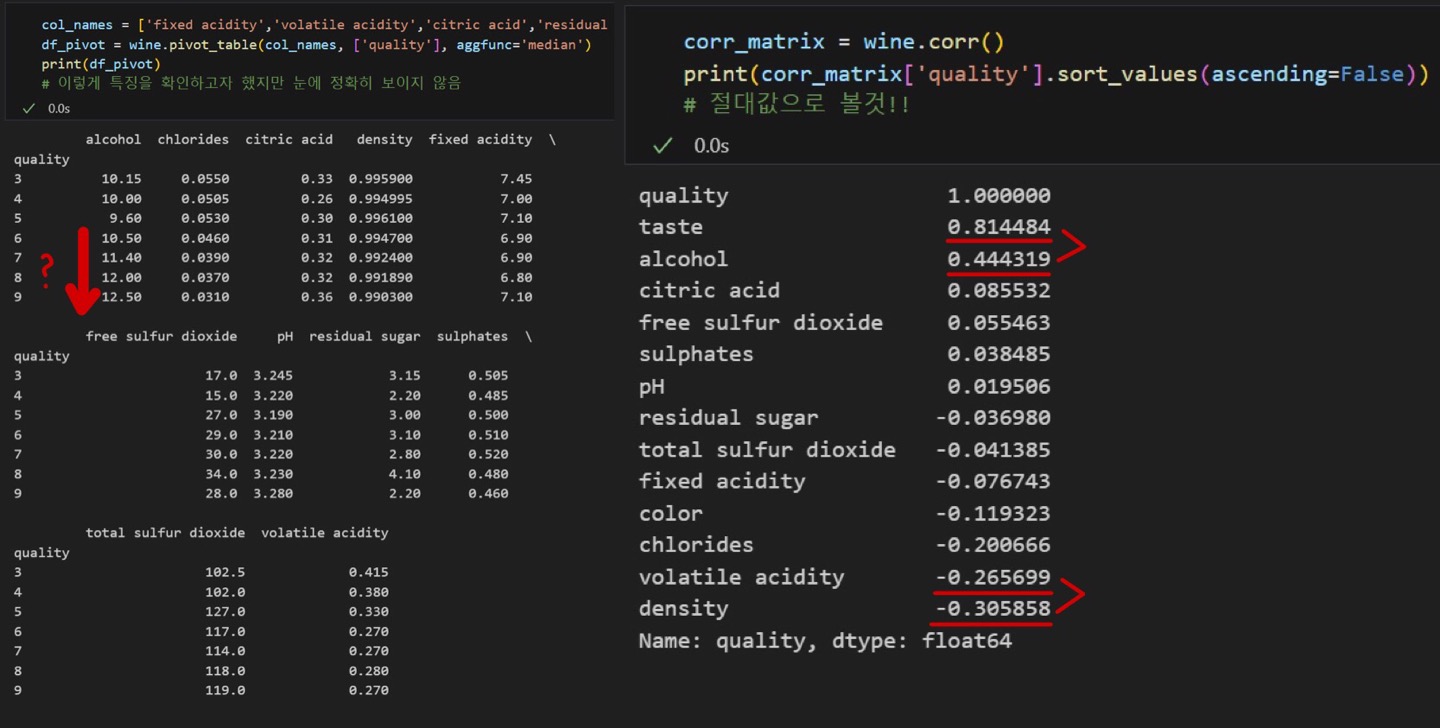
- 품질 5등급이상은 알콜과의 상관관계가 있어보임
- corr()로 상관관계 확인
다양한 모델을 한번에 테스트!
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models= []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))
# 튜플형태로 models리스트에 넣음
%%time #모델 돌리는데 시간 확인이 가능함
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())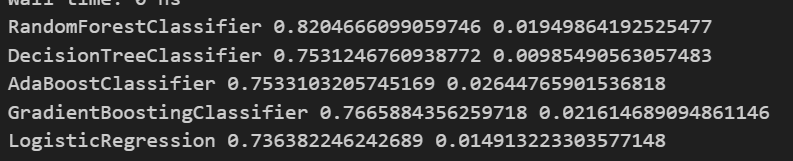
fig = plt.figure(figsize=(14,8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()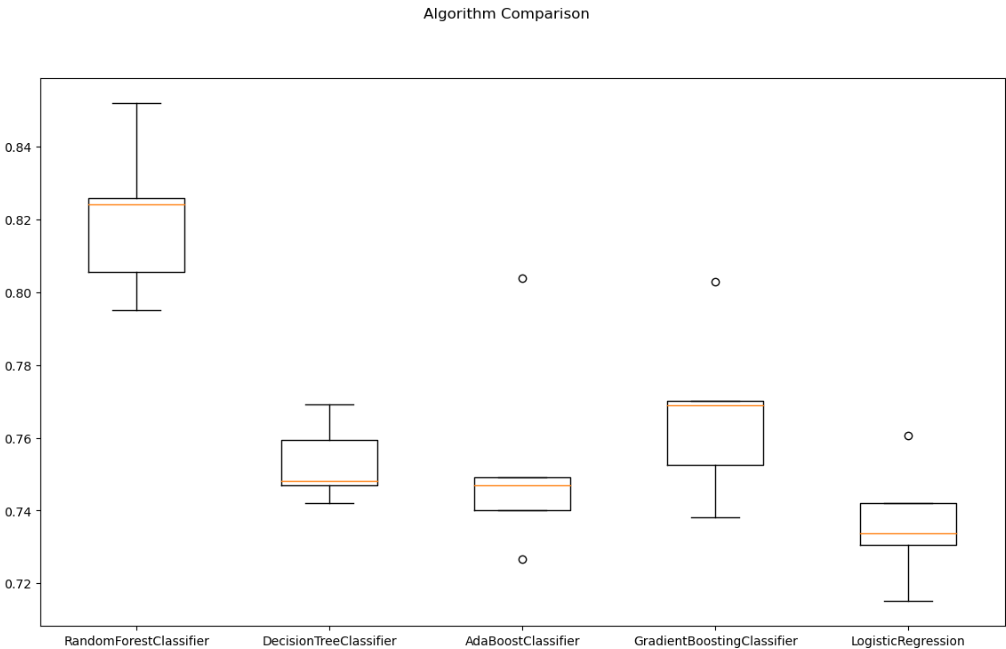
- 이 데이터는 RandonForest모델이 가장 적합해 보임
# 테스트 데이터
from sklearn.metrics import accuracy_score
for name,model in models:
model.fit(X_train,y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))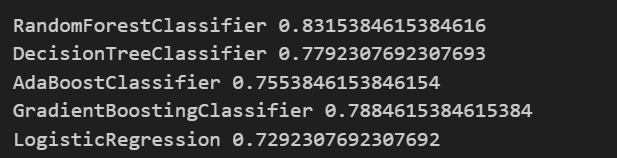
- 테스트 데이터로 알고리즘을 돌려봐도 RandonForest모델이 가장 성능이 좋음
