- 많은 S/W 관련 회사들이 자사 제품을 사용하는 것에 대해 API를 제공
- 특히 웹크롤링에 대한 방어가 높아지는 이때 해당 회사의 API를 사용하는것이 더 바람직 (API사용에 익숙해질 필요_
- 네이버 Application API(Client ID, Client Secret 확보) 네이버 개발자 센터
네이버 검색 API 사용(검색 API)
- 블로그 검색 구현 예제
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8')) #글자로 읽을경우 decode utf-8(한글)설정
else:
print("Error Code:" + rescode)- json {키:값}으로 데이터를 보여줌
- blog이외에도 책 검색, 네이버 카페 검색, 쇼핑 검색, 사전 검색 가능하다!
: url = '~/search/blog~' -> book, cafearticle, shop, encyc
Project. '몰스킨'상품 데이터분석
네이버 API를 활용한 간단한 프로젝트
- SW개발 순서도 절차 명시

< 프로젝트 절차별 함수만들기 >
1. gen_search_url( )
- 먼저 검색해야 할 url만들기
- url + 옵션 사용(display,start... 포함)
def gen_search_url(api_node, search_text, start_num, display_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num) #'&start='과 합치기 위해 str()
param_disp = '&display=' + str(display_num)
return base + node + param_query + param_start + param_disp- gen_result_onepage( )
import json # 키와 값의 형태
import datetime
def gen_result_onepage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success' % datetime.datetime.now()) #현재 시간
return json.loads(response.read().decode('utf-8'))
# {키:값}형태로 한글로 데이터를 읽어옴- get_fields( ) :DataFrame 만들기
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each['title'])for each in json_data['items']]
link = [each['link']for each in json_data['items']]
lprice = [each['lprice']for each in json_data['items']]
mall = [each['mallName']for each in json_data['items']]
result_pd = pd.DataFrame({
'title' : title,
'link' : link,
'lprice' : lprice,
'mall' : mall
}, columns=['title','lprice','link','mall'])
return result_pd- 수집한 데이터 수정
def delete_tag(input_str):
input_str = input_str.replace('<b>','')
input_str = input_str.replace('</b>','')
return input_str- actMain 데이터 모으기
result_mol = []
for n in range(1,1000,100):
url = gen_search_url('shop','몰스킨',n,100)
json_result = gen_result_onepage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
# 인덱스 수정
result_mol.reset_index(drop=True, inplace=True)-
to_Excel
!pip install xlsxwriter -
시각화
# 'Multiple values'가 있는 행을 제외하고 그래프를 그립니다.
filtered_result = result_mol[result_mol['mall'] != 'Multiple values']
sns.countplot(
x='mall',
data=filtered_result,
palette='deep',
order=filtered_result['mall'].value_counts().index
) #order 매개변수는 범주형 데이터의 순서를 정의,index
plt.xticks(rotation=90)
plt.show()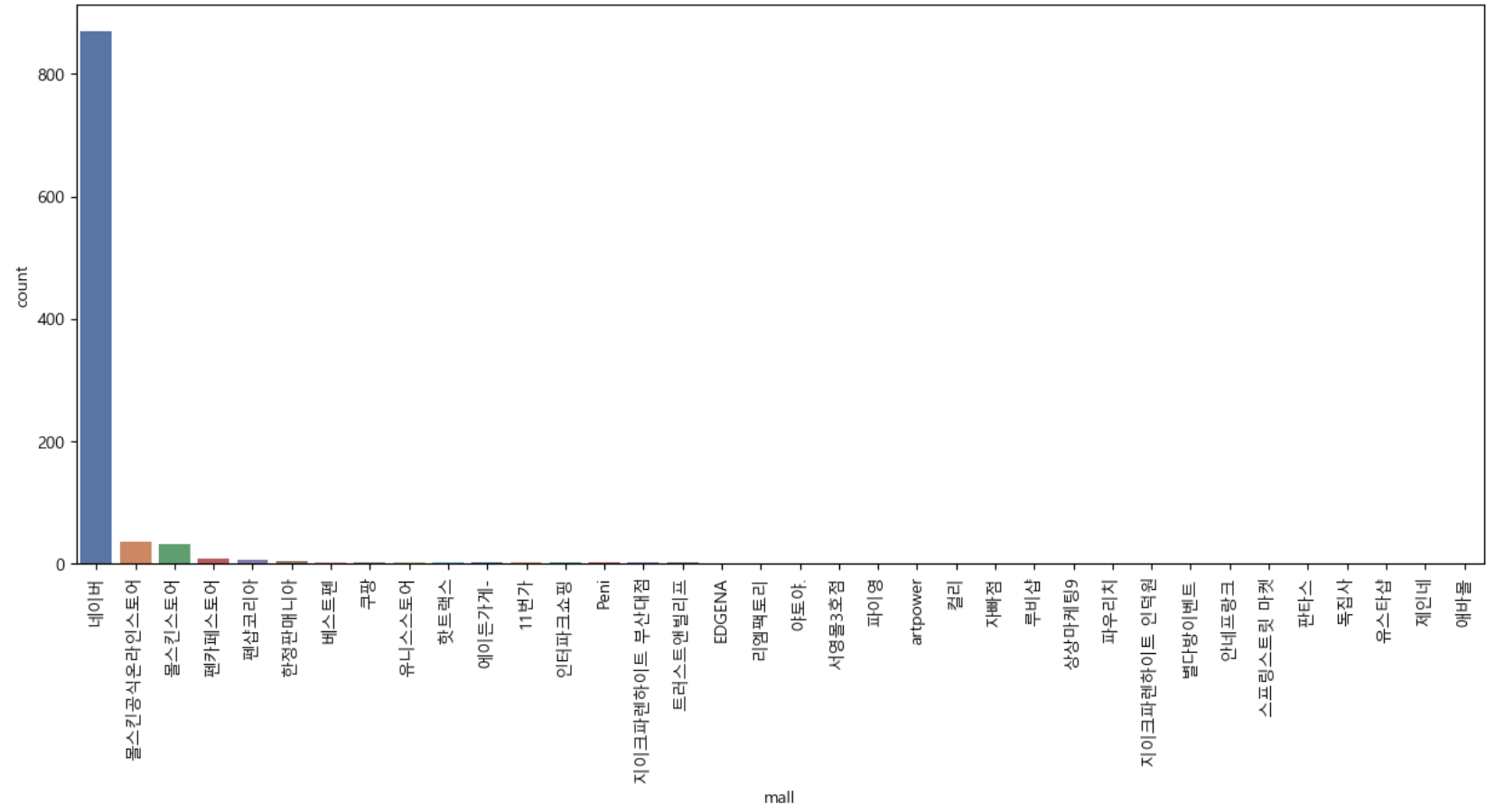

Hello