1. 프로젝트 개요
- 인식상 강남 3구(강남,서초,송파) 체감안전도가 높은데
실제 데이터와 비교하여 인식(가정)을 검증하려는 목적.
2. 데이터 개요
1. 데이터셋 확보
2. 데이터 확인
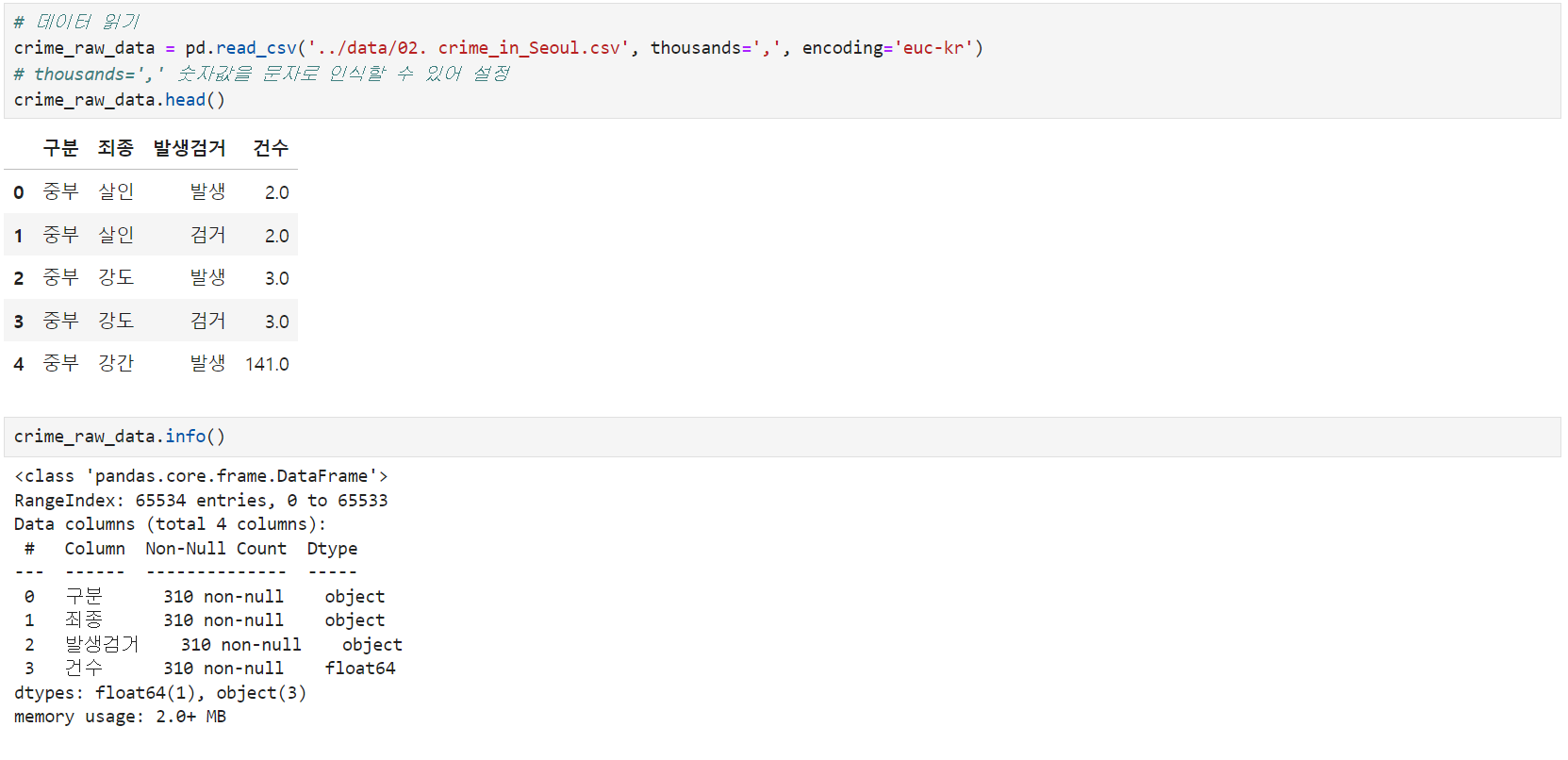
- csv파일: 대부분 csv파일 구분은 sep=','이지만 숫자 천단위와 혼동이 올 수 있다. 이를 방지하여 <thousands=','>
- 'index_col=' 으로 미리 인덱스를 정해서 데이터 불러오기
- 문제점 발견: RangeIndex: 65534, 310 non-null!
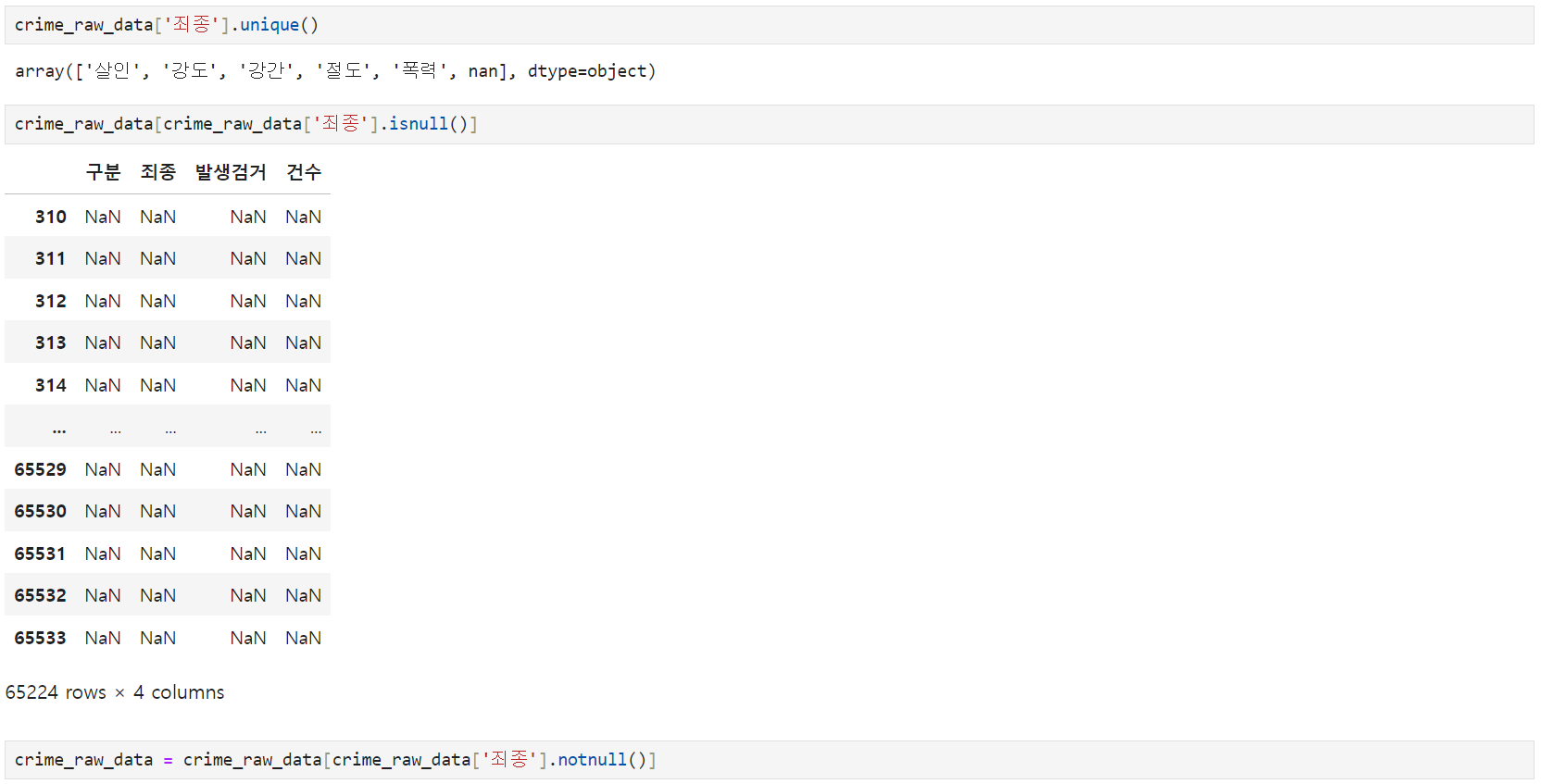 ** Nan값 발견
** Nan값 발견
** isnull(): nan값 확인(확인할 방법이 없어 Nan데이터를 없애는 게 최선)
** notnull(): nan값 없애기
3. 데이터 가공
1. 피벗테이블 활용
Pandas pivot table
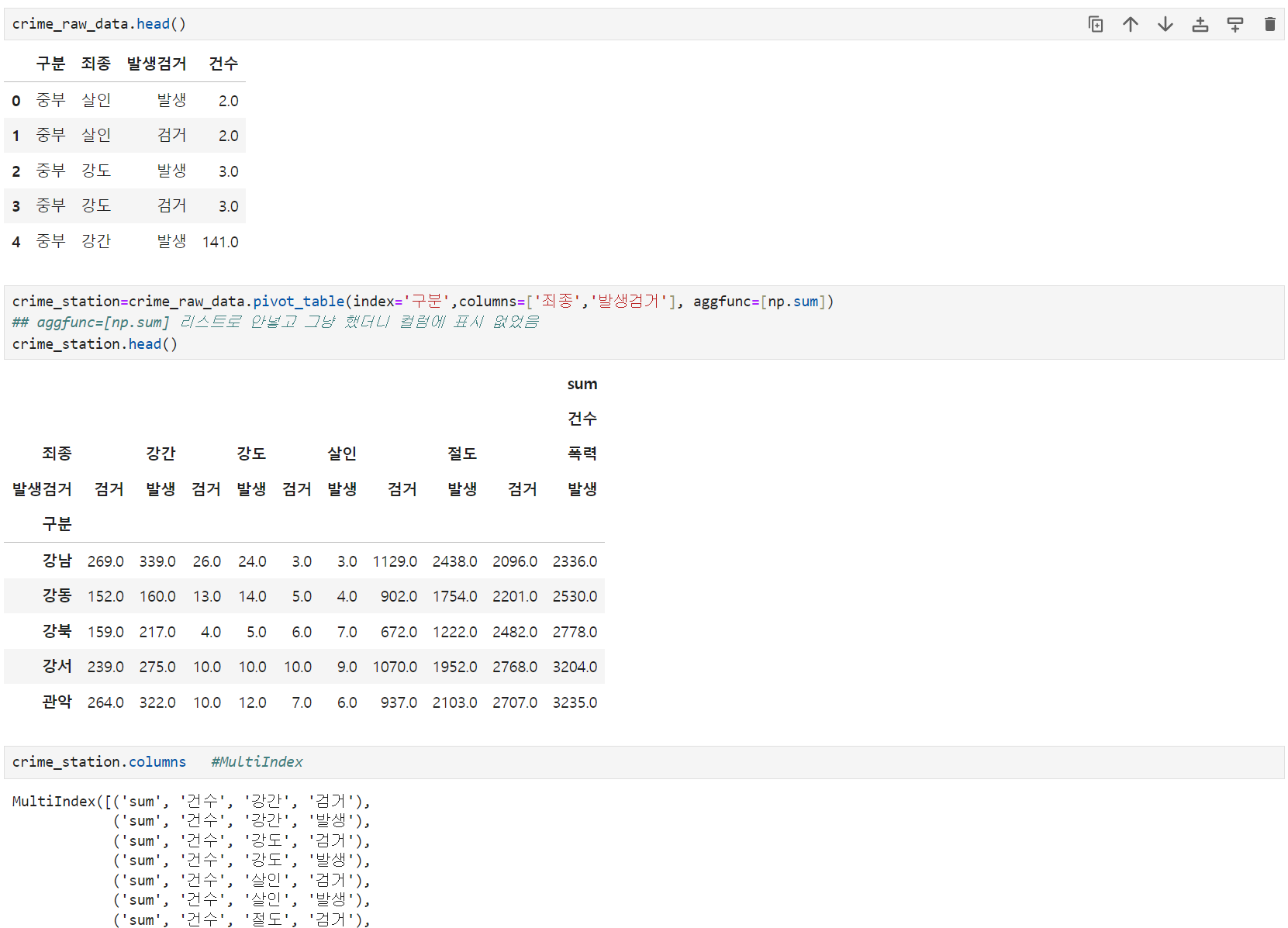
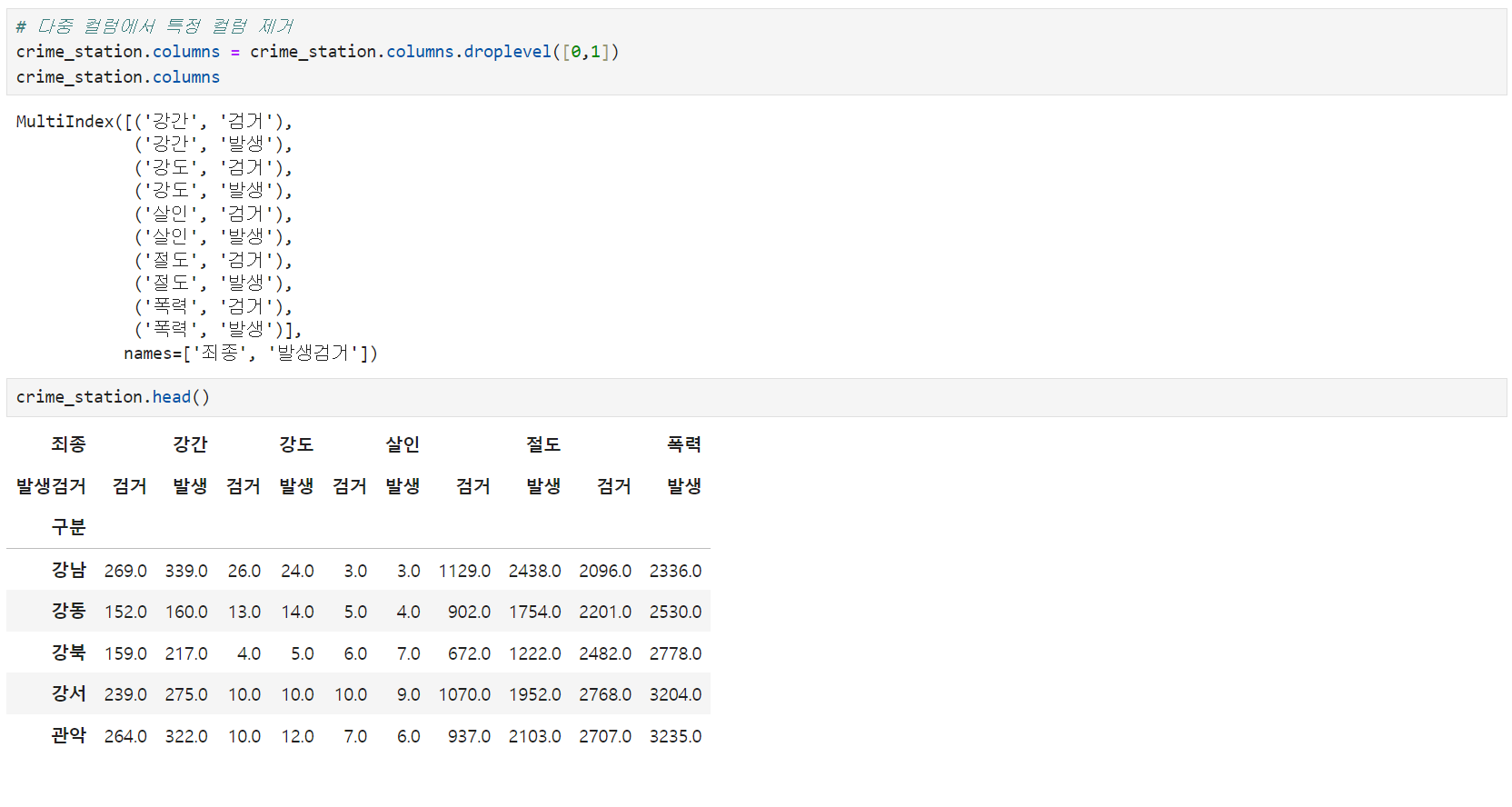 ** 피벗테이블 정리(컬럼 삭제:droplevel())
** 피벗테이블 정리(컬럼 삭제:droplevel())
2. Google Maps API 활용
- 현재 index는 경찰서 이름으로 되어있음.
- 경찰서 이름으로 구 이름을 알아내야함.
Google Maps (Google Maps API 설치)
conda install -c channel_name module_name(지정된 배포 채널에서 모듈 설치) anaconda.org
- 컬럼 추가 '구별', 'lat', 'lng' (각 values는 GoogleMaps활용)
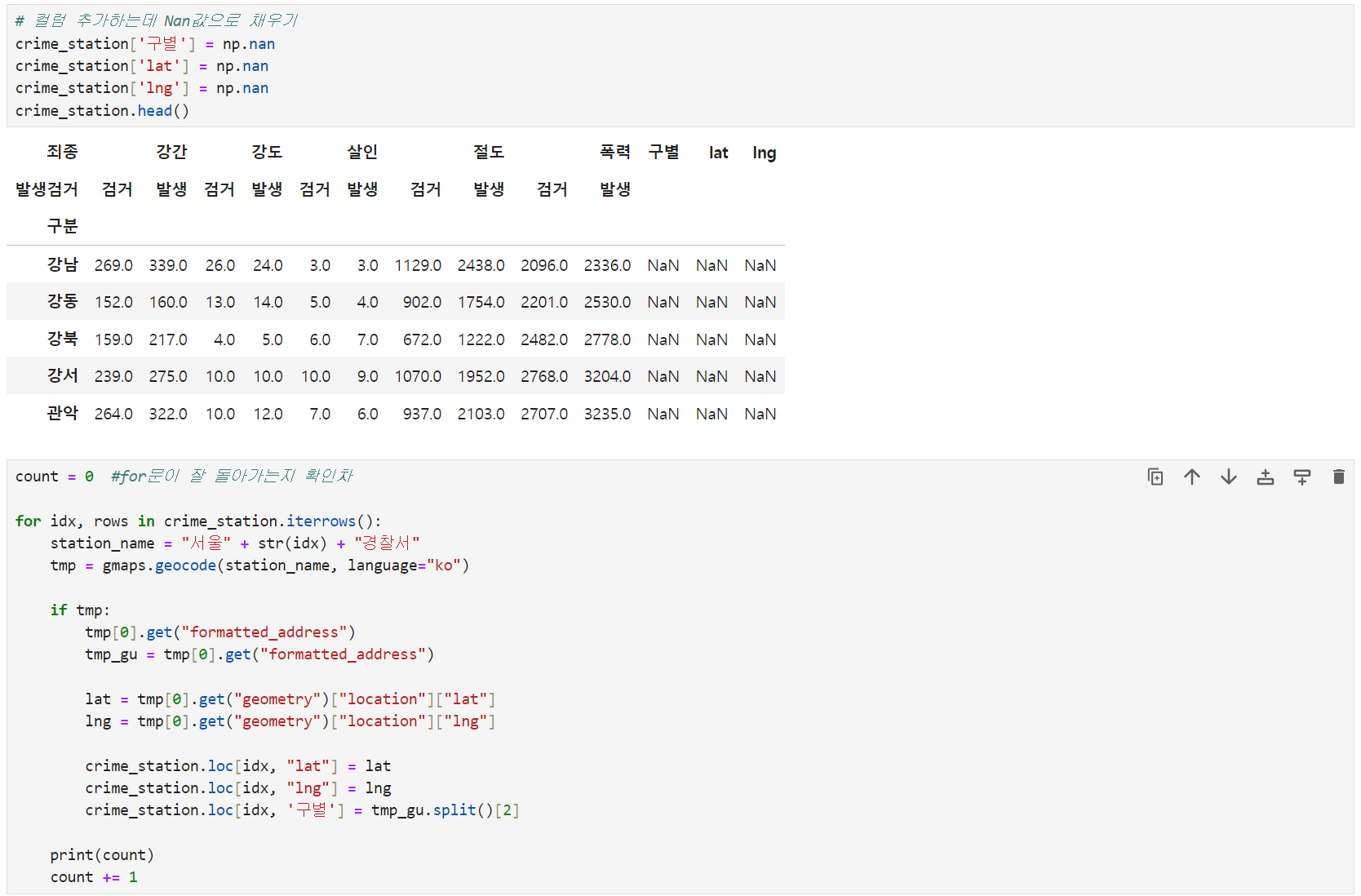 ** if문으로 형식에 안맞는 경찰서 찾음(노원,용산)
** if문으로 형식에 안맞는 경찰서 찾음(노원,용산)
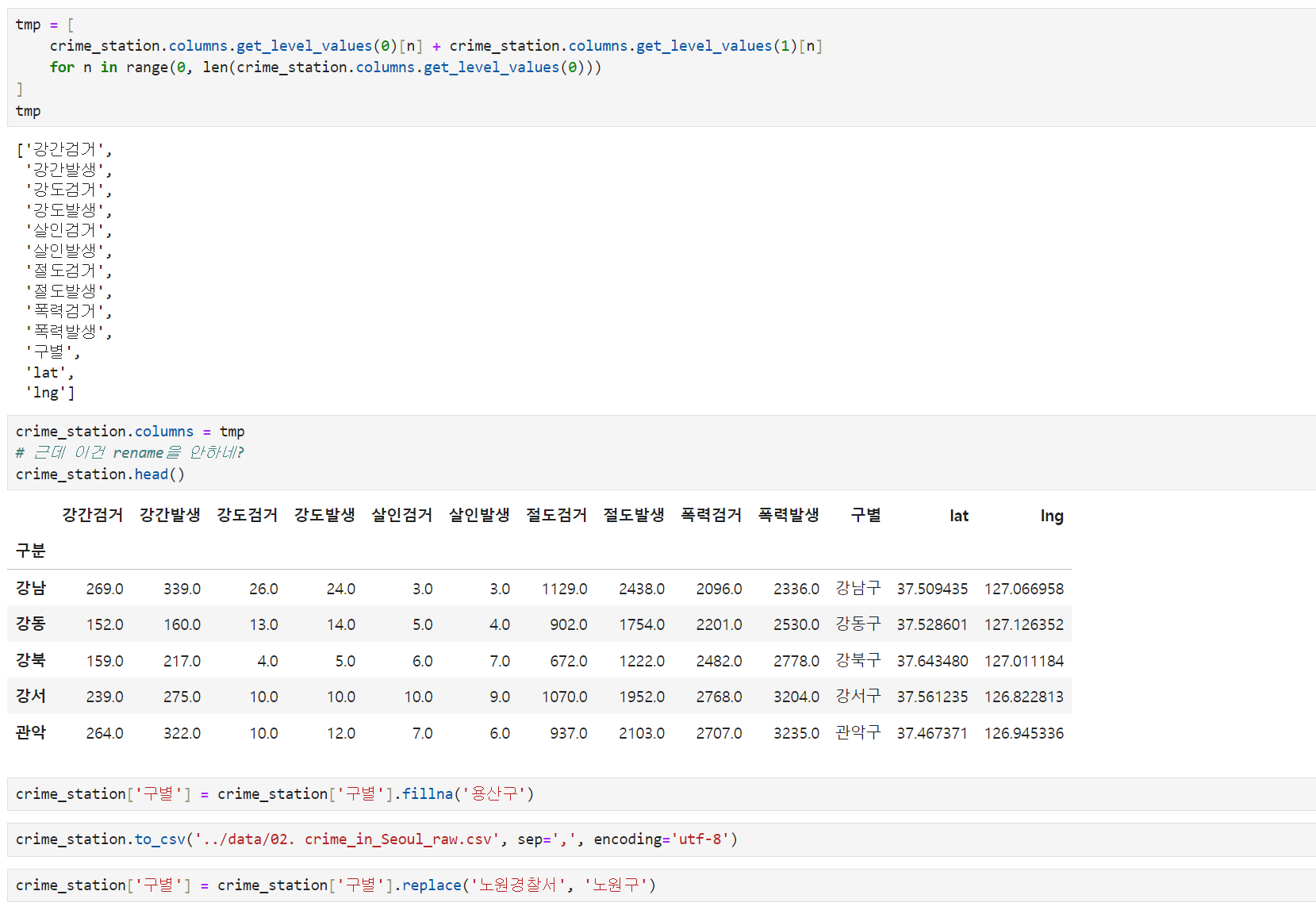
** iterrows(): pandas에 맞는 반복문 명령, 데이터프레임(2차원)으로 반복문을 만들때 용이. 인덱스와 내용으로 나누어 받는 것만 주의 - 다중 컬럼명 바꾸기(get_level_values)
- values값(Nan값이거나 값이 있는 경우)을 변경
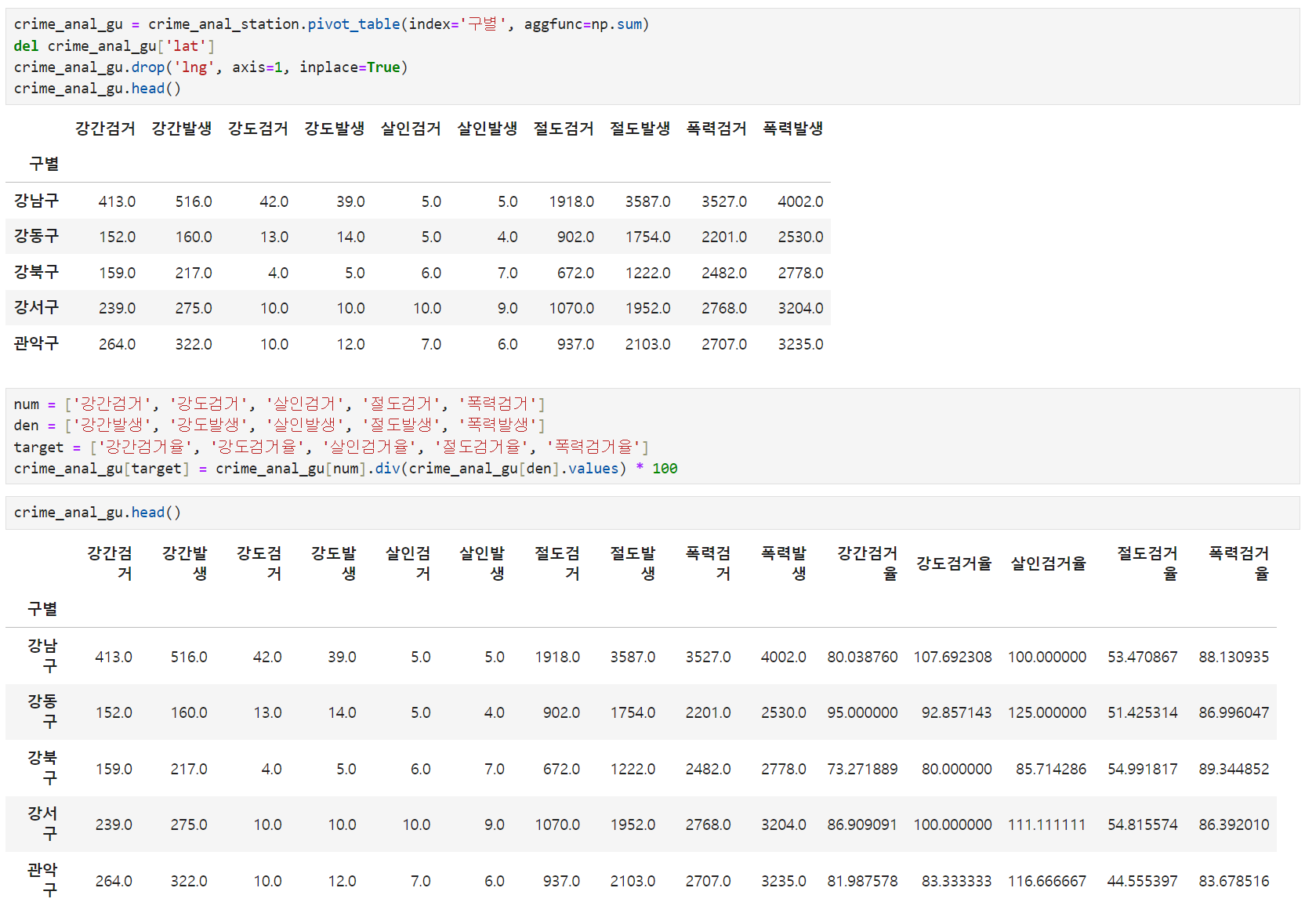
3. 구별 데이터 정렬
- pivot_table로 자치구별 정렬
- 검거율 생성(다수의 컬럼을 다수 컬럼으로 나누기): div()
- 100보다 큰 숫자 바꾸기: crime_anal_gu[crime_anal_gu[target]>100] = 100
4. 범죄 데이터 정렬
- 정규화: 각 사건의 스케일 조절(0<N<1)
- 각 사건을 그 사건의 최댓값으로 나눔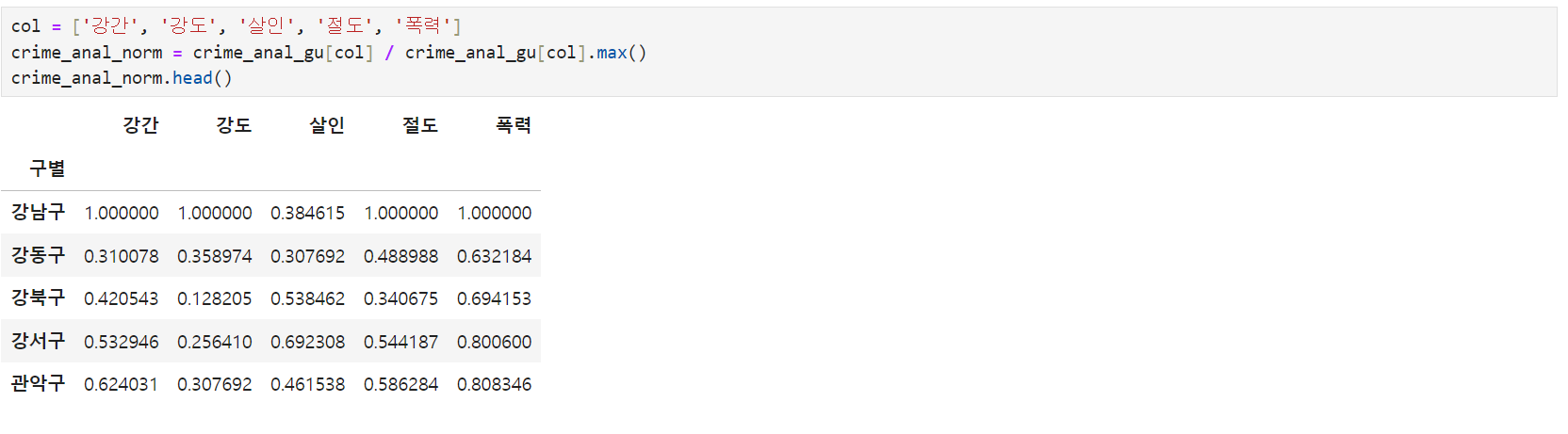
- 각 사건 검거율과 전 프로젝트(CCTV소계, 인구수)데이터 넣기
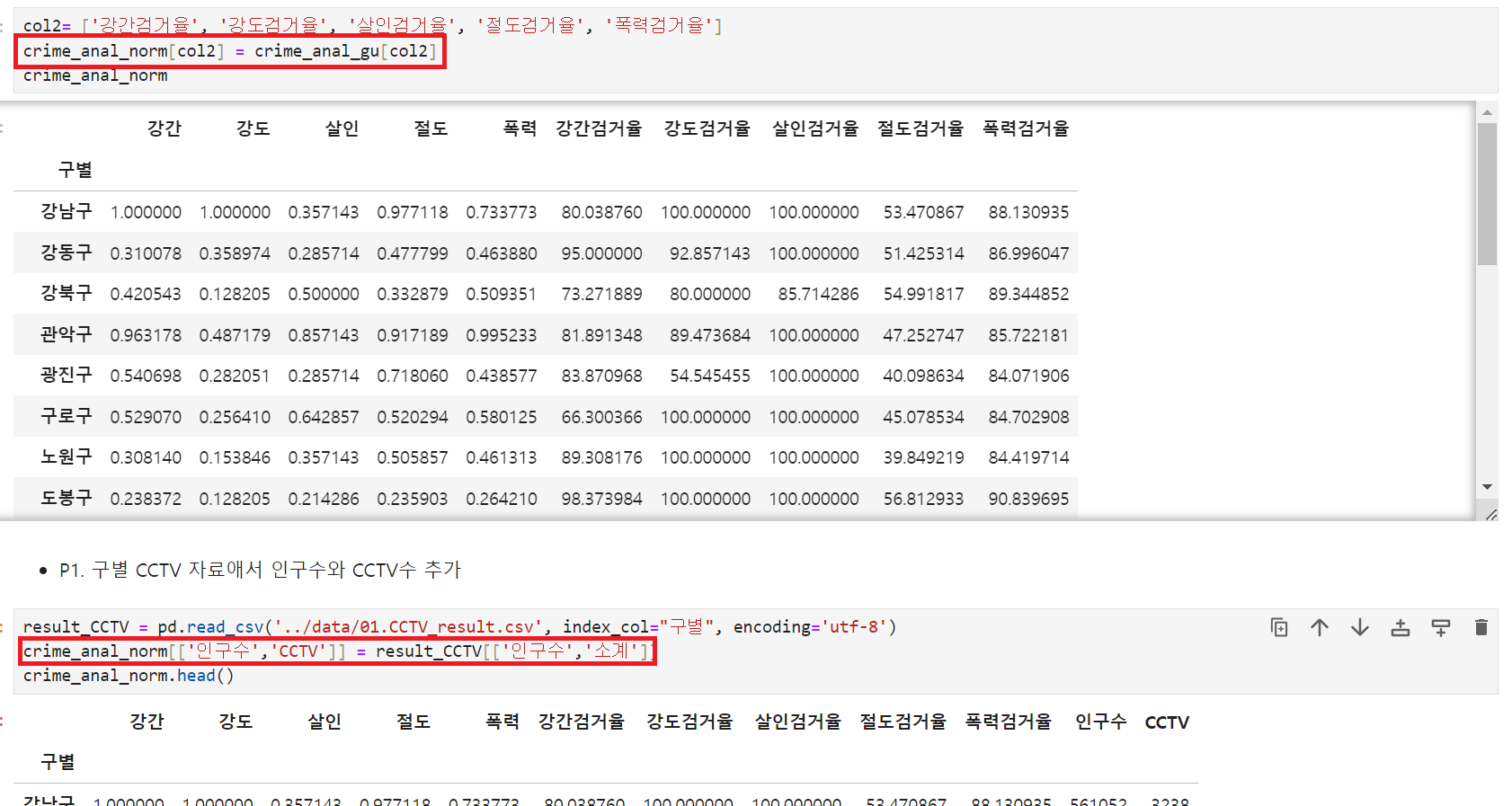
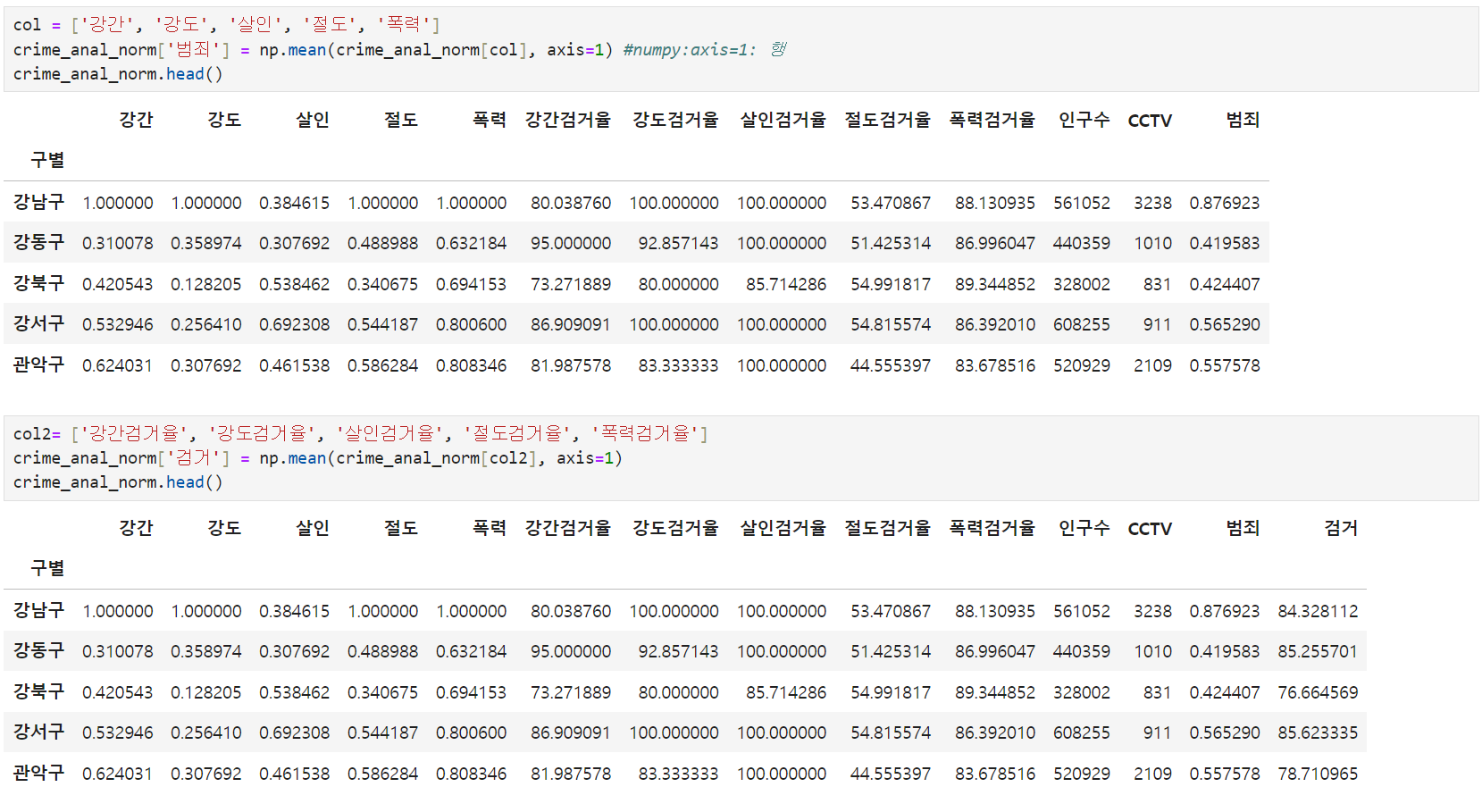
원하는 컬럼들만 뽑아오는 게Good! 너무 좋은 기능을 가지고 있는듯 - 범죄발생 건수 전체의 평균을 구해 '각 자치구 범죄 평균'
- 검거율 평균을 '각 자치구 검거율'
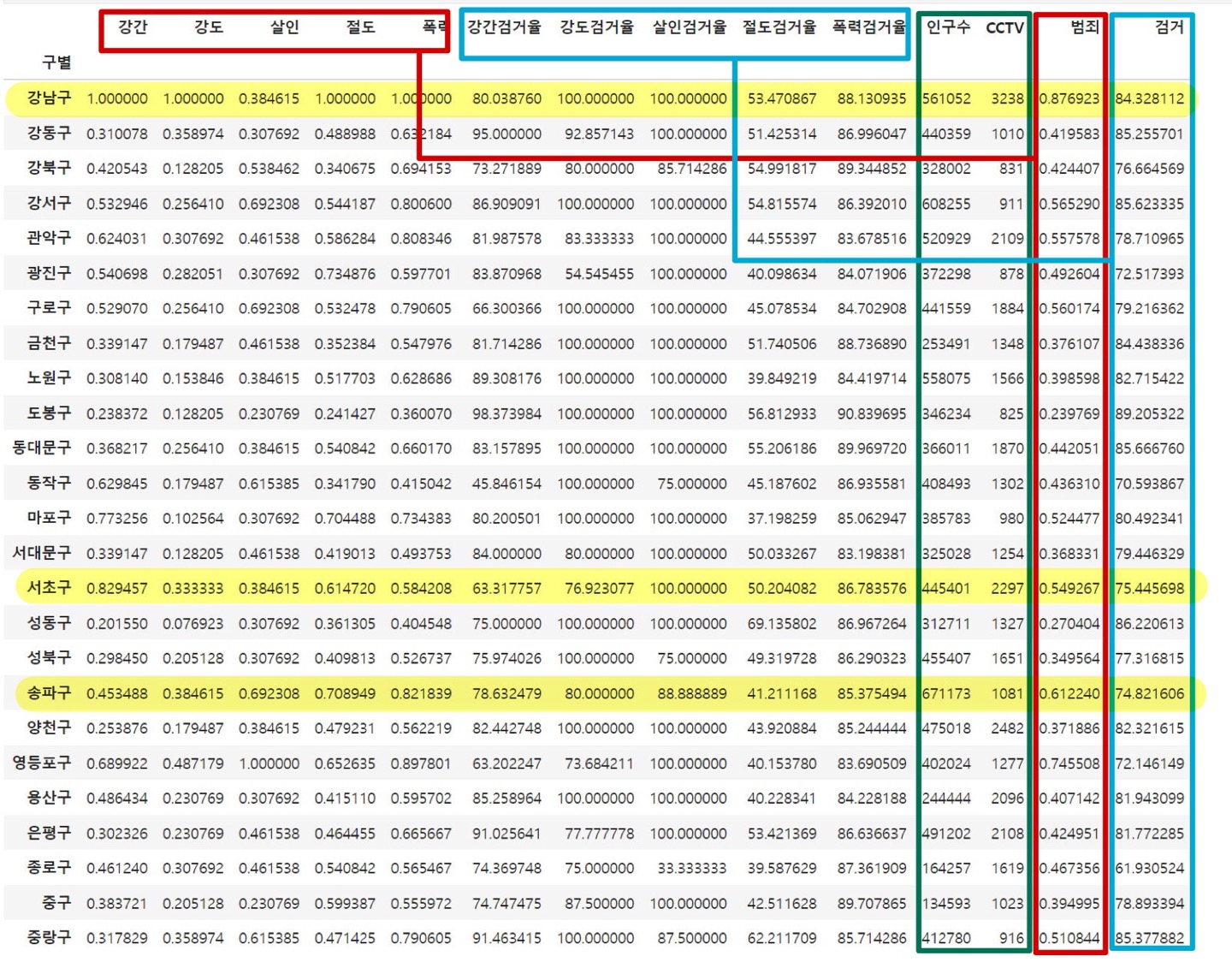
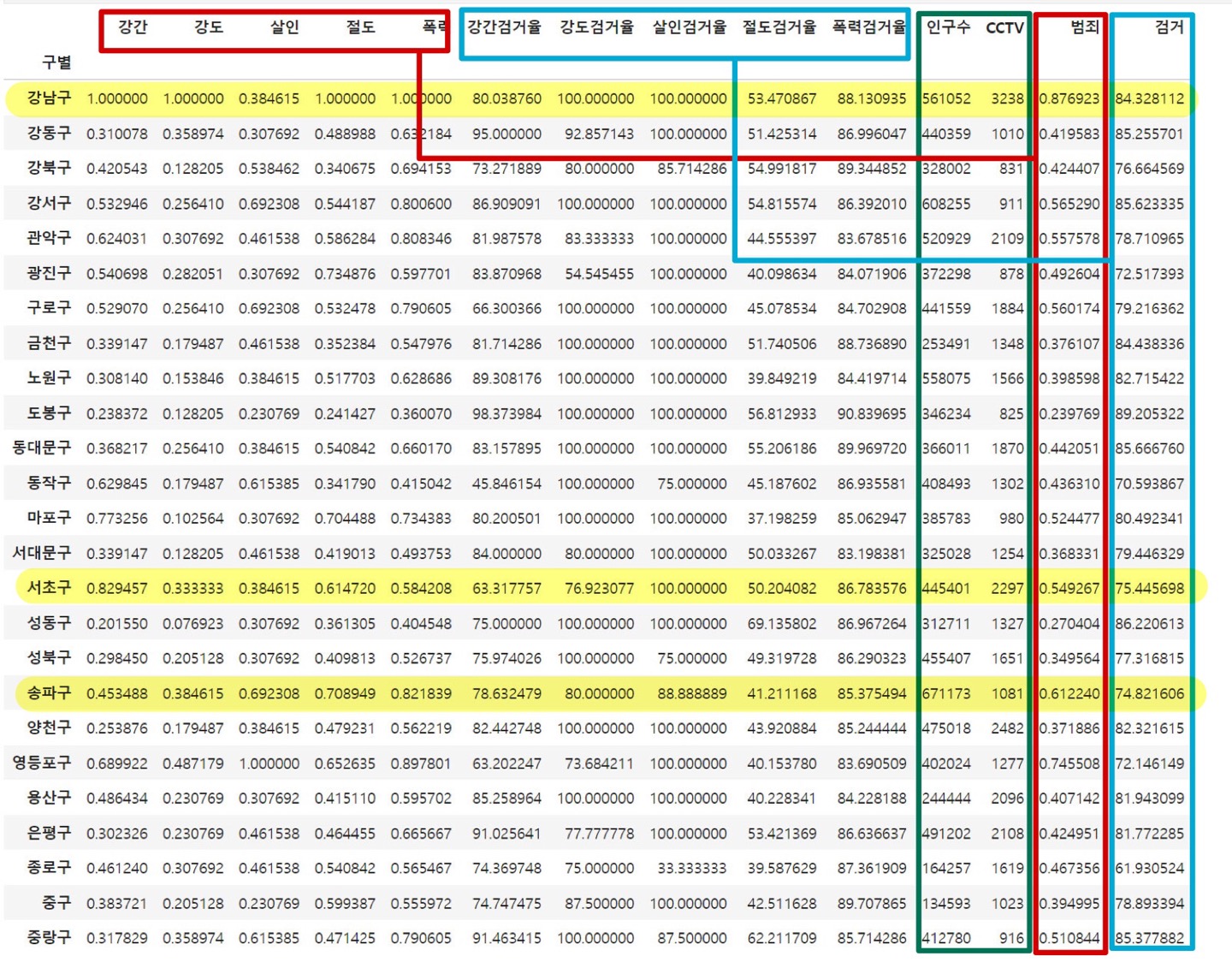
5. 최종 가공된 데이터
< 다시 보는 코드 >
# 하나의 컬럼을 다른 컬럼으로 나누기 crime_anal_gu['강도검거']/crime_anal_gu['강도발생'] # 다수의 컬럼을 다수 컬럼으로 나누기 div() crime_anal_gu[['강도검거','살인검거']].div(crime_anal_gu['강도발생'],axis=0) num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거'] den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생'] crime_anal_gu[num].div(crime_anal_gu[den].values) # 100보다 큰 숫자 바꾸기 crime_anal_gu[crime_anal_gu[target]>100] = 100 # 정규화(최고값1, 최소값:0) crime_anal_gu[col] / crime_anal_gu[col].max() col = ['강간', '강도', '살인', '절도', '폭력'] crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col], axis=1) #numpy:axis=1: 행 col=['강간검거','강도검거','살인검거','절도검거','폭력검거'] tmp=crime_anal_station[col] / crime_anal_station[col].max() #정규화 crime_anal_station['검거'] = np.mean(tmp, axis=1)
“이글은제로베이스데이터취업스쿨의강의자료일부를발췌하여
작성되었습니다.”

Hello