1. 프로젝트 개요:
시카고 매거진에서 발표한 50개 샌드위치 맛집의 정보
웹데이터 수집 & 정리
https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
2. 데이터 가공 및 분석
1. html코드 데이터 확보 (BeautifulSoup활용)
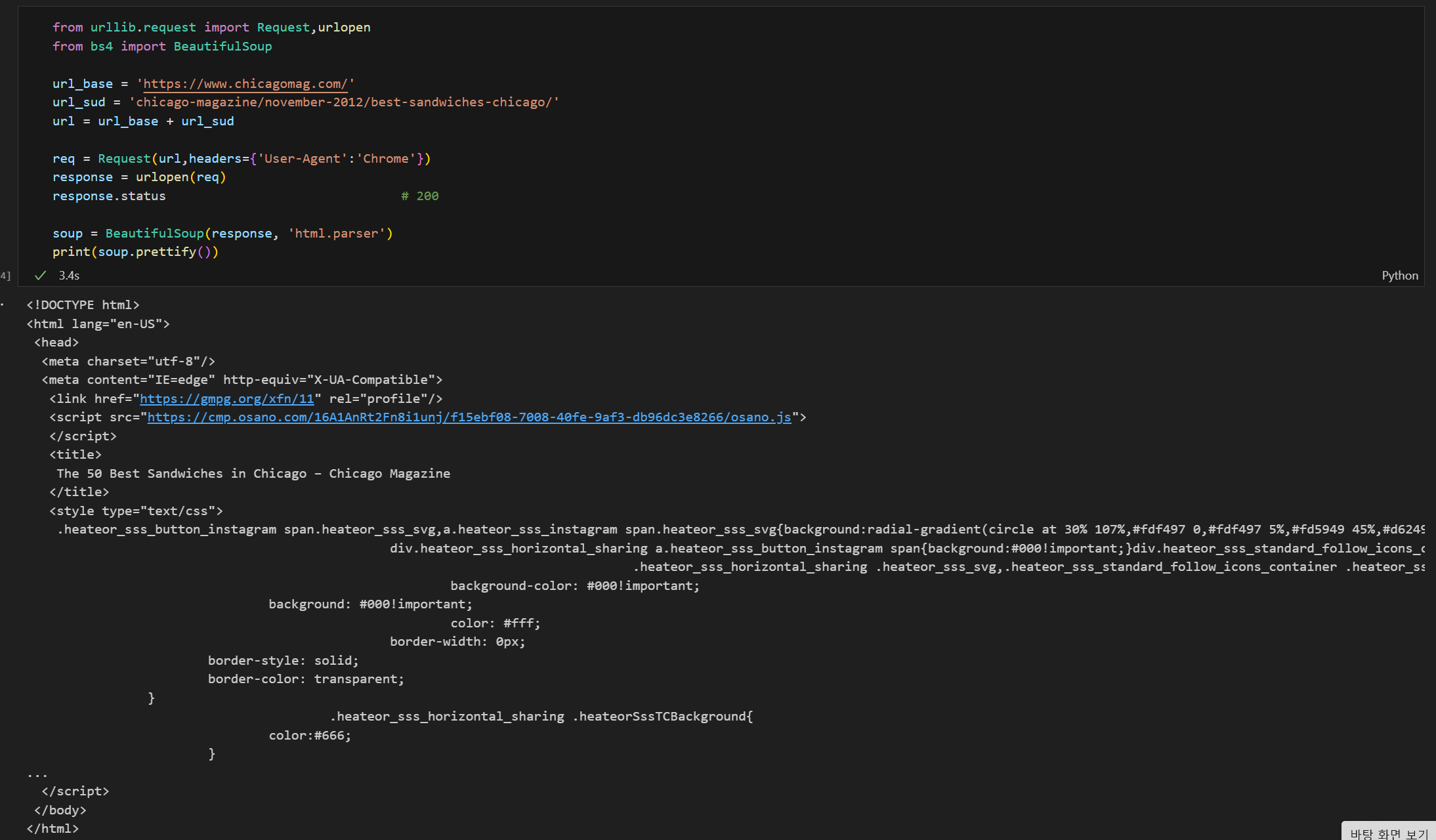
-
샌드위치 가게 정보가 담긴 코드 check! (원하는 코드)
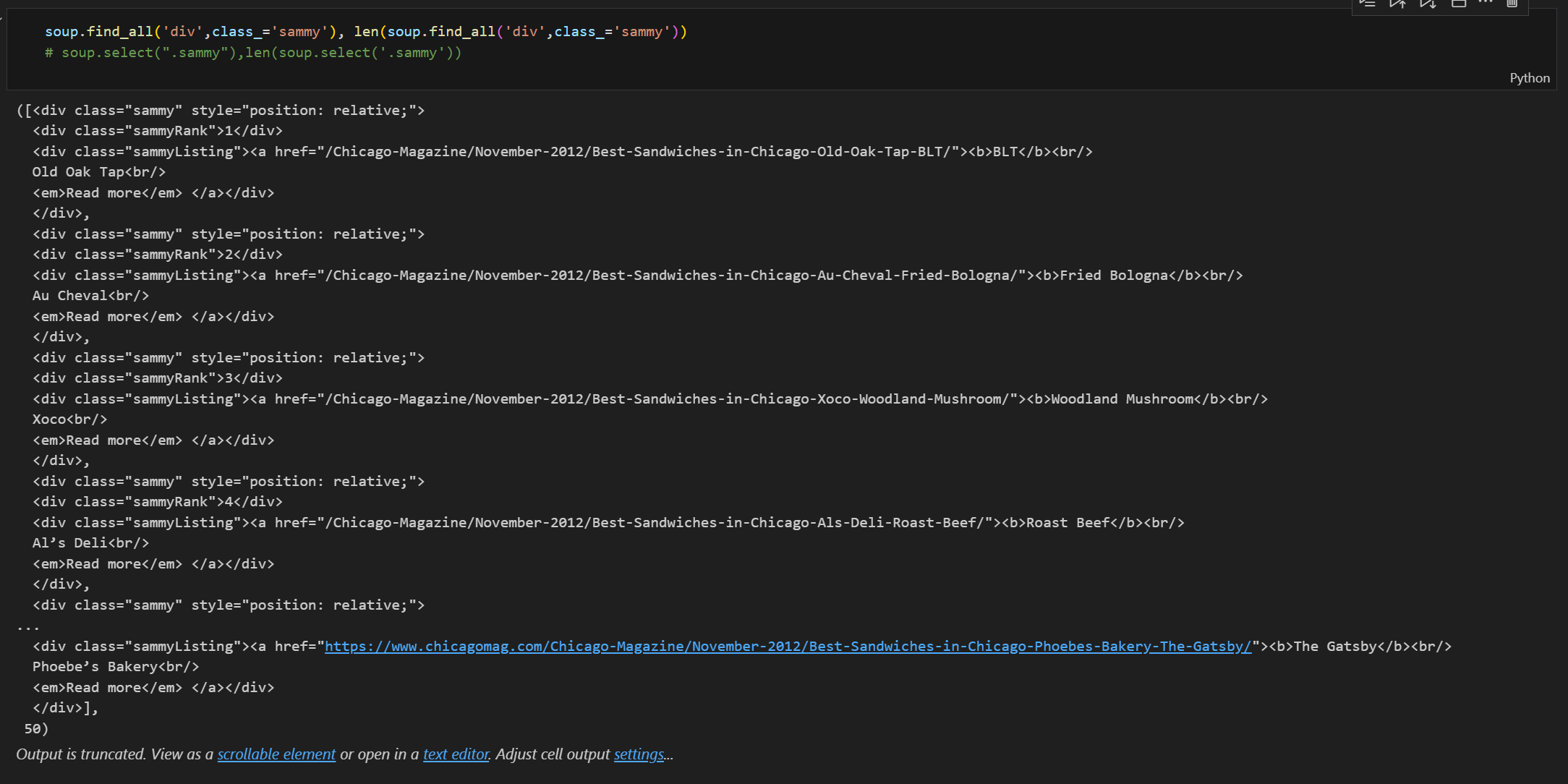
-
Sample code!(전체데이터를 뽑기위한 하나의 자료로 test실험)
 - 타입(bs4.element.Tag)으로 보아 find( ), select( )사용 가능
- 타입(bs4.element.Tag)으로 보아 find( ), select( )사용 가능
- 랭크와 url, 가게이름, 메뉴이름 확인됨
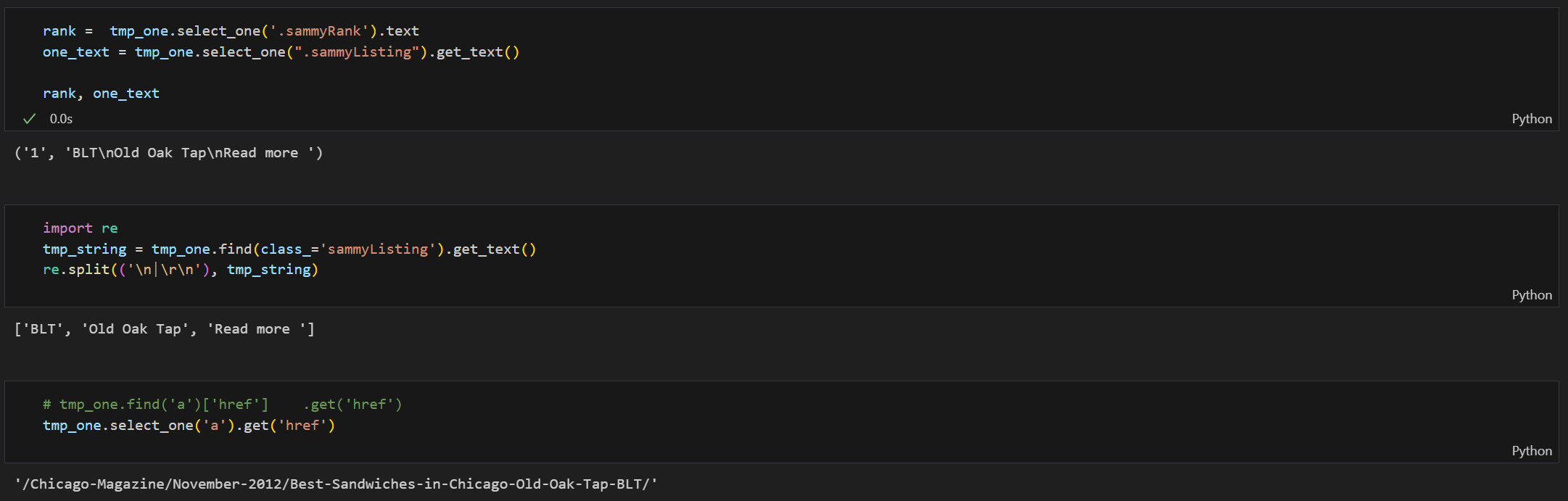 - 랭킹1위 정보를 확인하여 내가 가져오려는 정보 다시 Check!
- 랭킹1위 정보를 확인하여 내가 가져오려는 정보 다시 Check!
- 순위, 메뉴, 가게, 하위사이트 url 확인 코드 check!
- 특히, import reimport re
re.split()으로 원하는 정보를 잘라 리스트로 반환시켜줌
-
문제발생!
:href속성의 정보에 '상대주소'만 or '절대주소(base) + 상대주소(sub)'가 있는 경우가 있음.from urllib.parse import urljoin
중복을 되면 자동으로 없애주는 urljoin이용(상대 주소를 절대 주소로 변환)
url_base = 'https://www.chicagomag.com/'
url_sud = 'chicago-magazine/november-2012/best-sandwiches-chicago/'
urljoin(url_base, item.find('a')['href'])
2. 원하는 데이터 확보
- 전체 데이터를 뽑기 위한 for문 이용
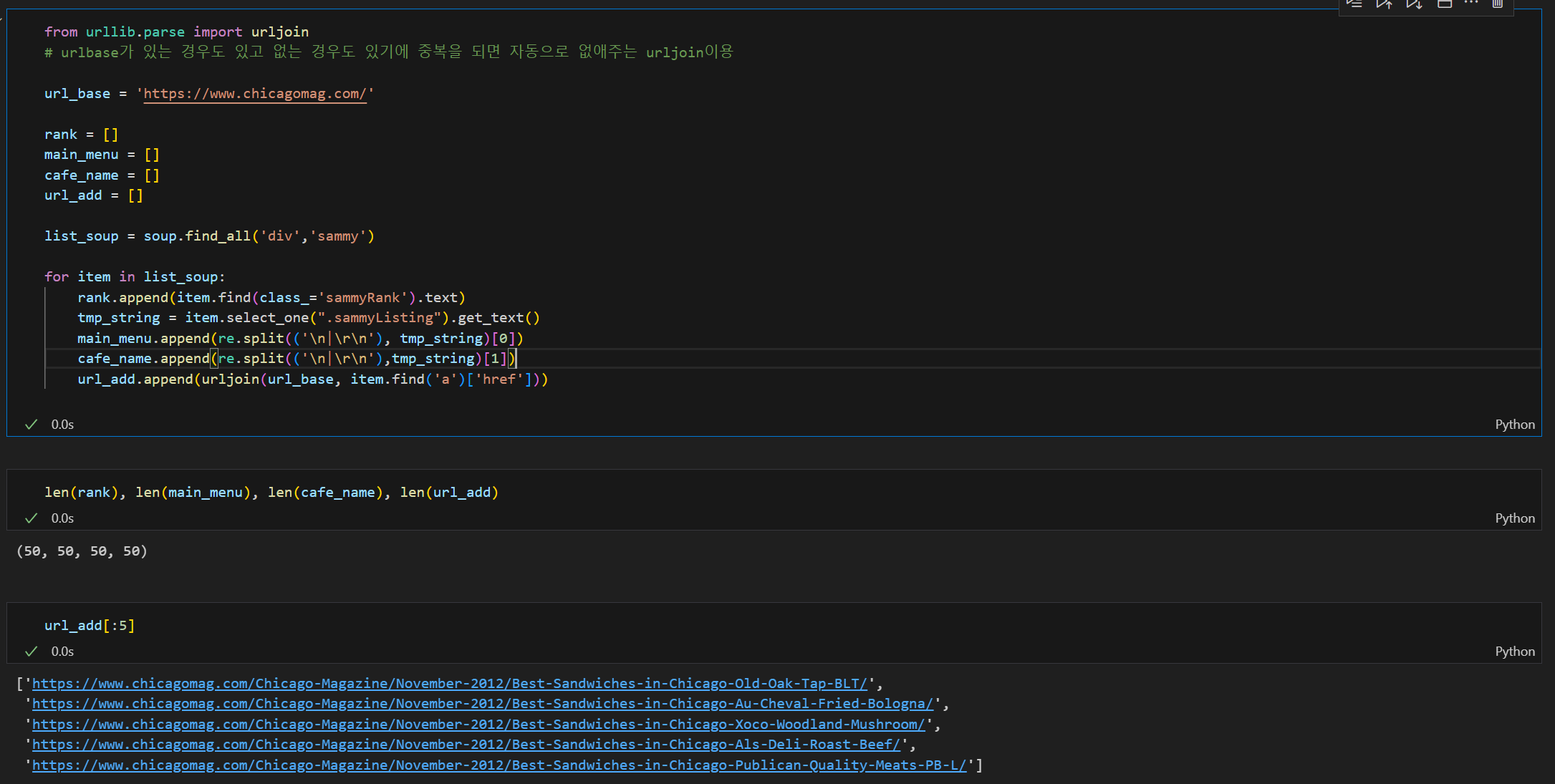 - len()함수로 뽑아온 정보만 맞는지 한번 더 check!
- len()함수로 뽑아온 정보만 맞는지 한번 더 check!
3. DataFrame으로 만들기
import pandas as pd
data={'Rank': rank,
'Menu': main_menu,
'Cafe': cafe_name,
'URL': url_add
}
# 컬럼 순서변경
df = pd.DataFrame(data, columns=['Rank','Cafe','Menu',"URL"])
# csv파일 저장
df.to_csv('./03. best_sandwiches_list_chicago.csv', sep=',', encoding='utf-8')
# 다시 불러오기
pd.read_csv('./03. best_sandwiches_list_chicago.csv', index_col=0)
4. 하위페이지 데이터 분석
# requirments
import pandas as pd
from urllib.request import urlopen,Request
from bs4 import BeautifulSoup- Sample code
url = df['URL'][0] # df파일 맨 처음 데이터로 하위페이지 샘플링
req = Request(url, headers={'User-Agent':'Chrome'})
res = urlopen(req).read() #read()함으로써 바로 읽어옴
soup_tmp = BeautifulSoup(res,'html.parser') #lxml엔진 사용가능
# .prettify()안하고 바로 필요정보만 뽑기
soup_tmp.find('p','addy')
# soup_tmp.select_one('p.addy')- 문제 발생 : 원하는 정보(가격과 주소가 한 문장에 붙어있음)
<p class="addy">
<em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>- $10. 2109 W. Chicago Ave., 773-772-0406Regular Expression 정규식
하나의 문장안에 잘라서 읽어야(일정 패턴有) 할 정보가 있다면 쓸 것
예) 000-0000-0000 : \d+\s-\s\d+\s-\s\d+
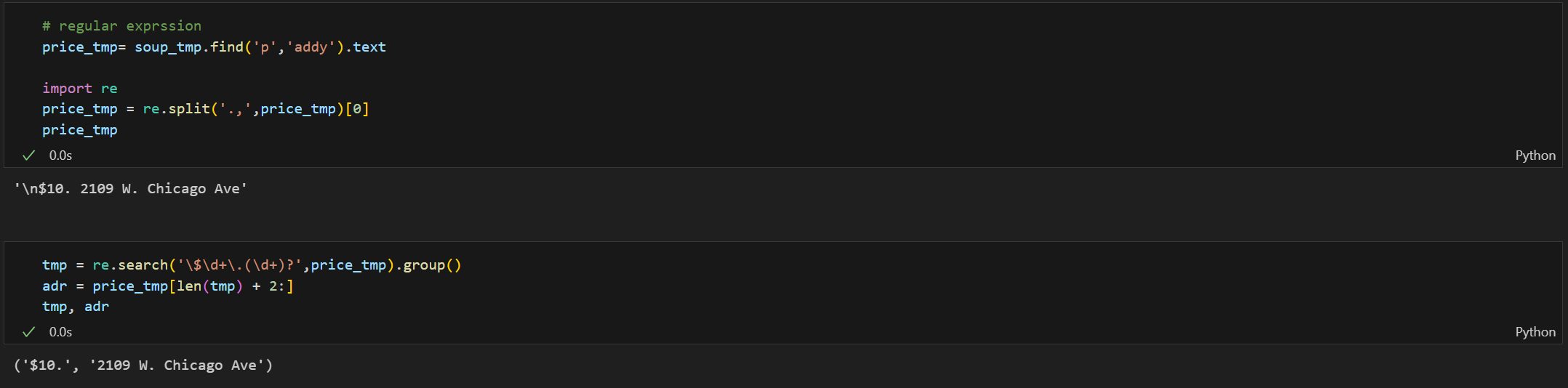 - re.search()로 Regular Expression표현법 이용
- re.search()로 Regular Expression표현법 이용
- 가격과 주소를 찾는 코드 확인
5. 전체 데이터 뽑기
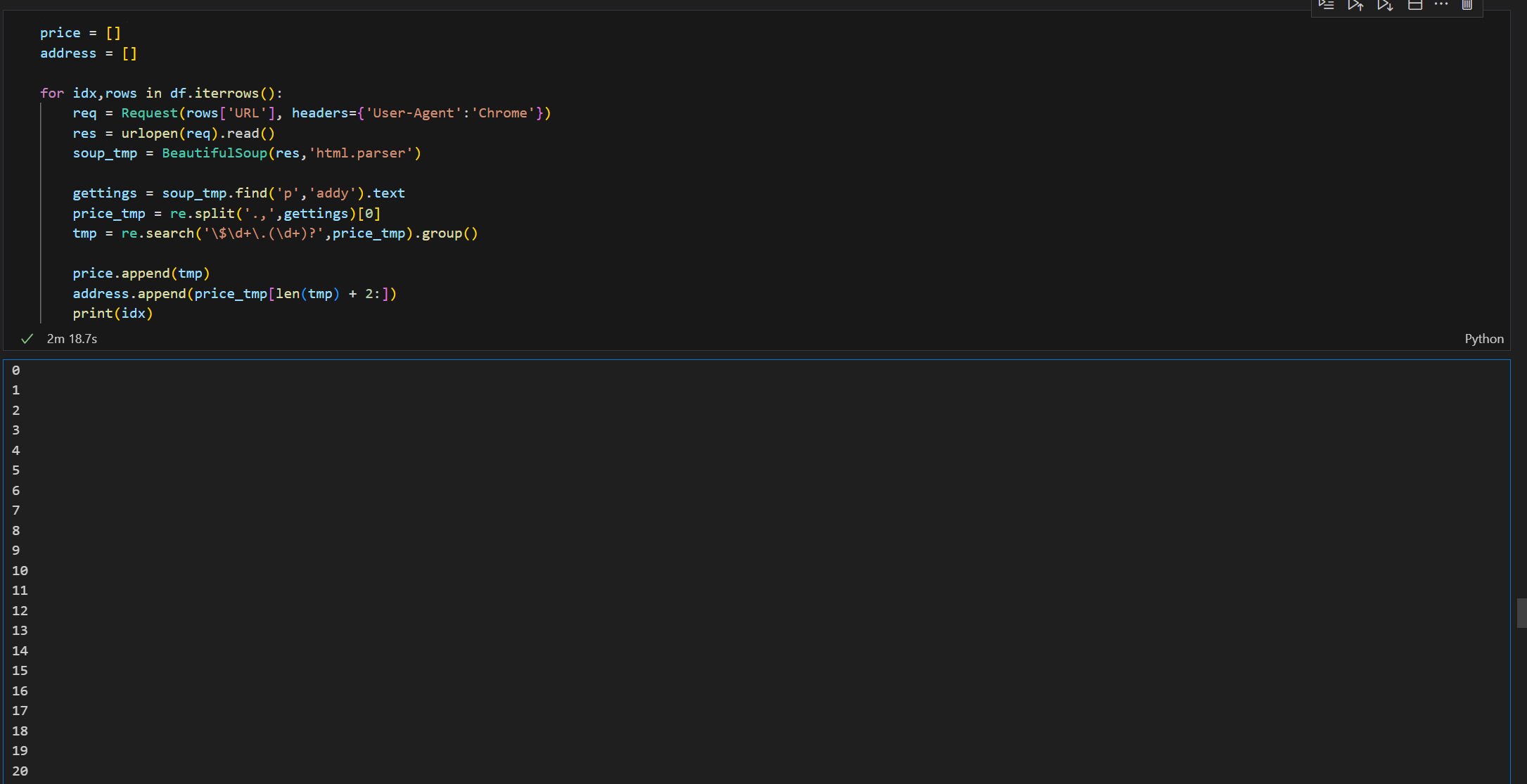 - iterrows()을 활용해 각각 URL로 들어가 필요정보만 뽑아옴
- iterrows()을 활용해 각각 URL로 들어가 필요정보만 뽑아옴
- print(idx)는 데이터가 잘 뽑아서 오는지의 확인 하지만 화면이 지저분해지는 관계로 tqdm활용
tqdm
위처럼 index번호를 하나하나 프린터하지 않고 '간단하게' 프로그램이 잘 돌아가는지 확인할 수 있게 함.
conda install -c conda-forge tqdm
from tqdm import tqdm
for idx,rows in tqdm(df.iterrows()):
req = Request(rows['URL'], headers={'User-Agent':'Chrome'})
res = urlopen(req).read()
soup_tmp = BeautifulSoup(res,'html.parser')
gettings = soup_tmp.find('p','addy').text
price_tmp = re.split('.,',gettings)[0]
tmp = re.search('\$\d+\.(\d+)?',price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
# 뽑은 자료 df - Price컬럼, 'Address'컬럼에 넣기
df['Price'] = price
df['Address'] = address
df = df.loc[:,['Rank','Cafe','Menu','Price','Address']]
df.set_index('Rank',inplace=True)6. 최종 가공된 데이터
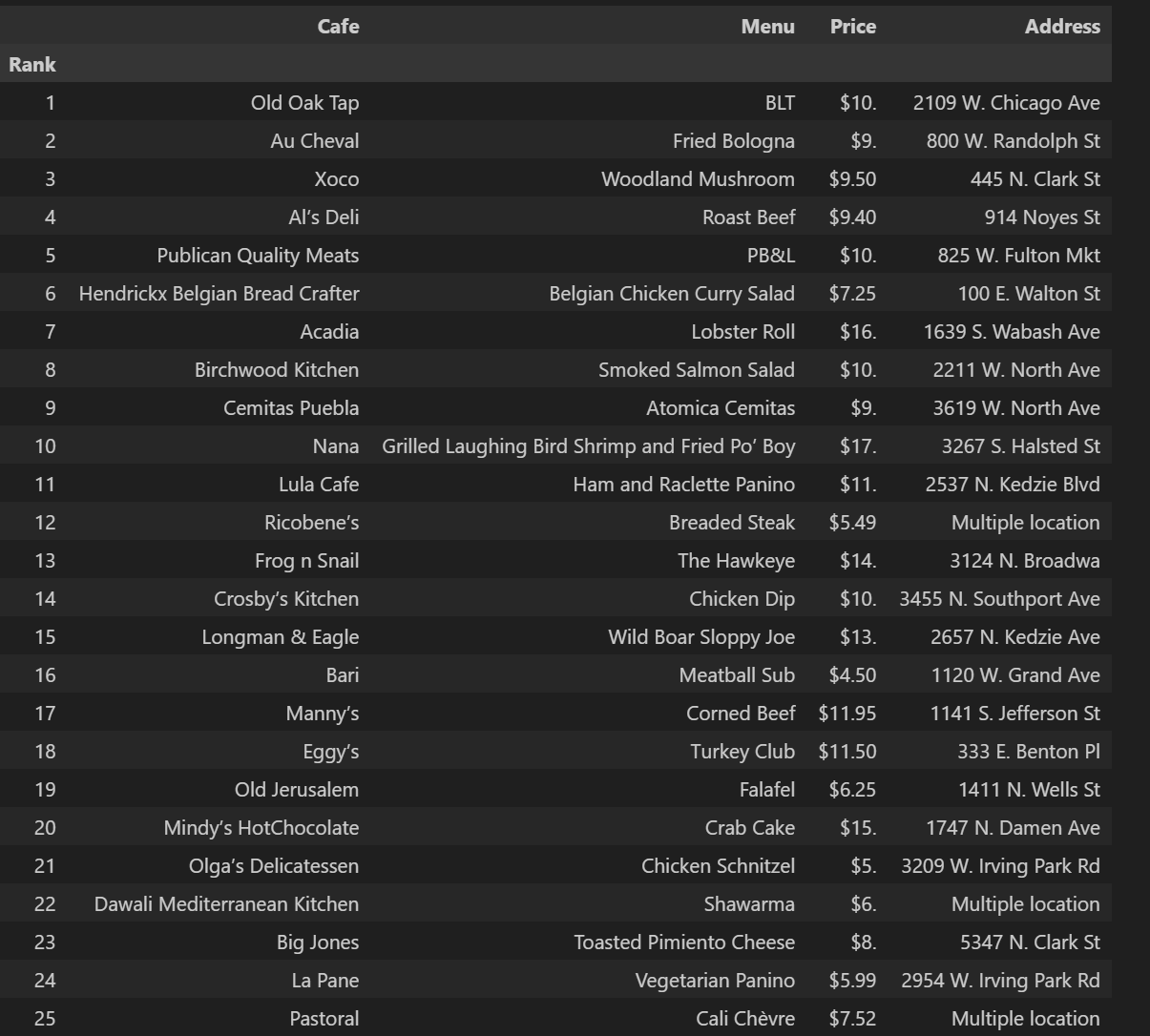
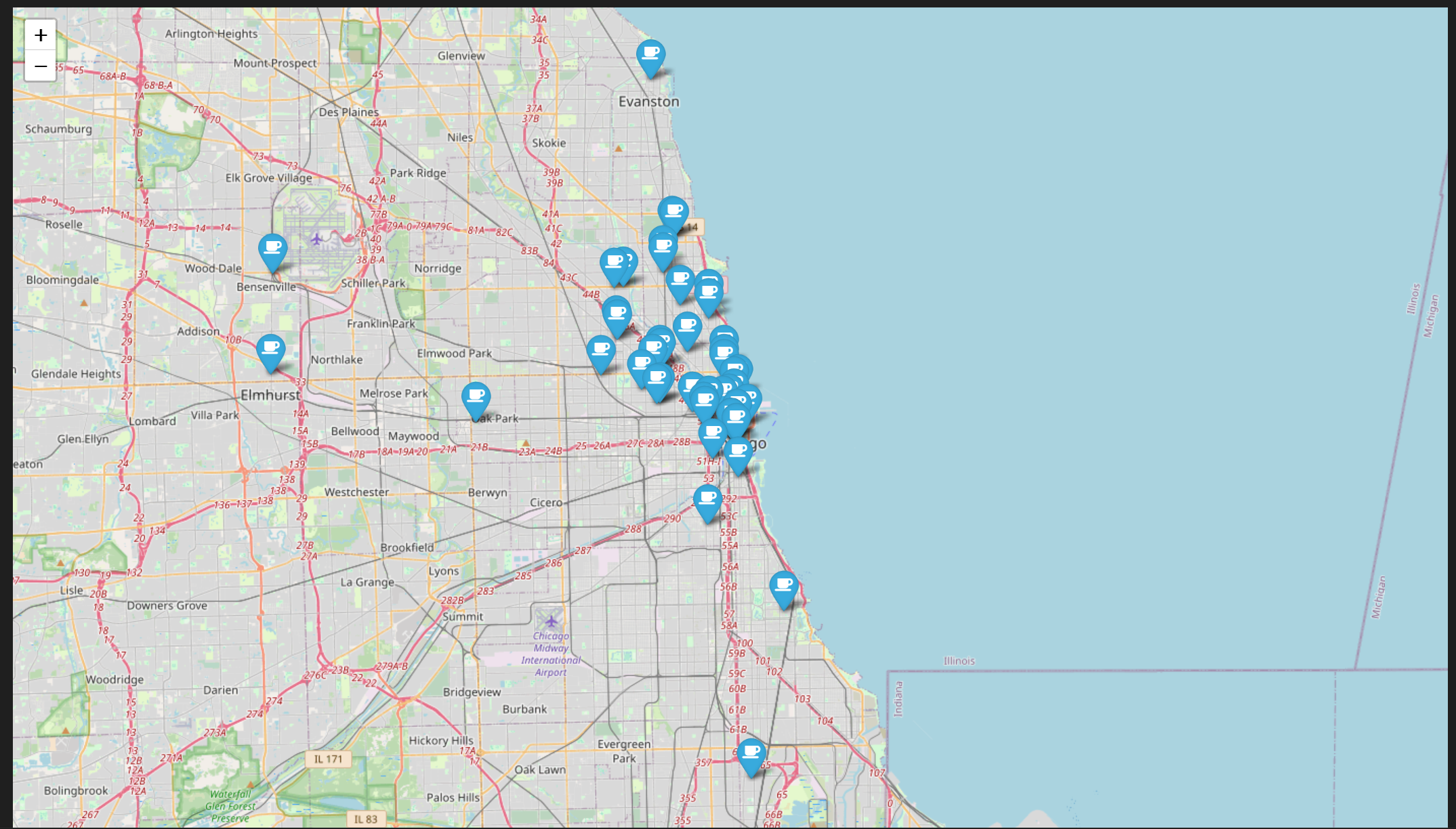
3. 시카고 맛집 데이터 지도 시각화
import folium
import pandas as pd
import numpy as np
import googlemaps- Google Maps API(위도, 경도 확인) 활용
lat = []
lng = []
for idx,rows in tqdm(df.iterrows()):
if not rows['Address'] == 'Multiple location':
target_name = rows['Address'] + ', Chicago'
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get('geometry') #gmaps_output[0]['geometry']도 가능!!
lat.append(location_output['location']['lat'])
lng.append(location_output['location']['lng'])
else:
lat.append(np.nan)
lng.append(np.nan)
df['lat'] = lat
df['lng'] = lng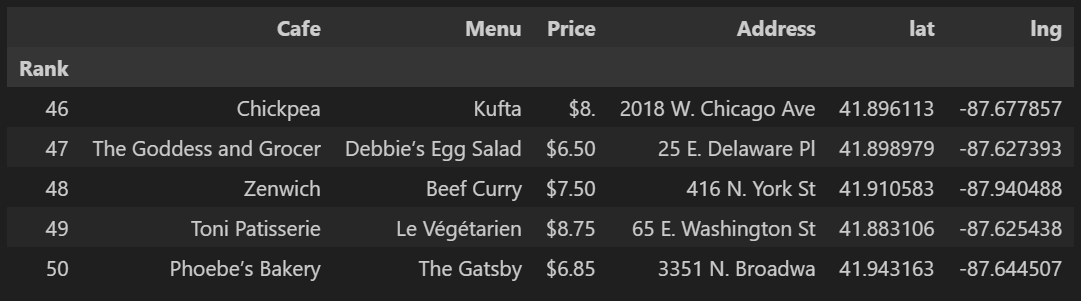
- Folium 활용
mapping = folium.Map([41.8781136,-87.6297982],zoom_start=11)
for idx,rows in df.iterrows():
if not rows['Address'] == 'Multiple location':
folium.Marker(
location=[rows['lat'],rows['lng']],
popup=rows['Cafe'],
tooltip=rows['Menu'],
icon=folium.Icon(icon='coffee',prefix='fa')
).add_to(mapping)
mapping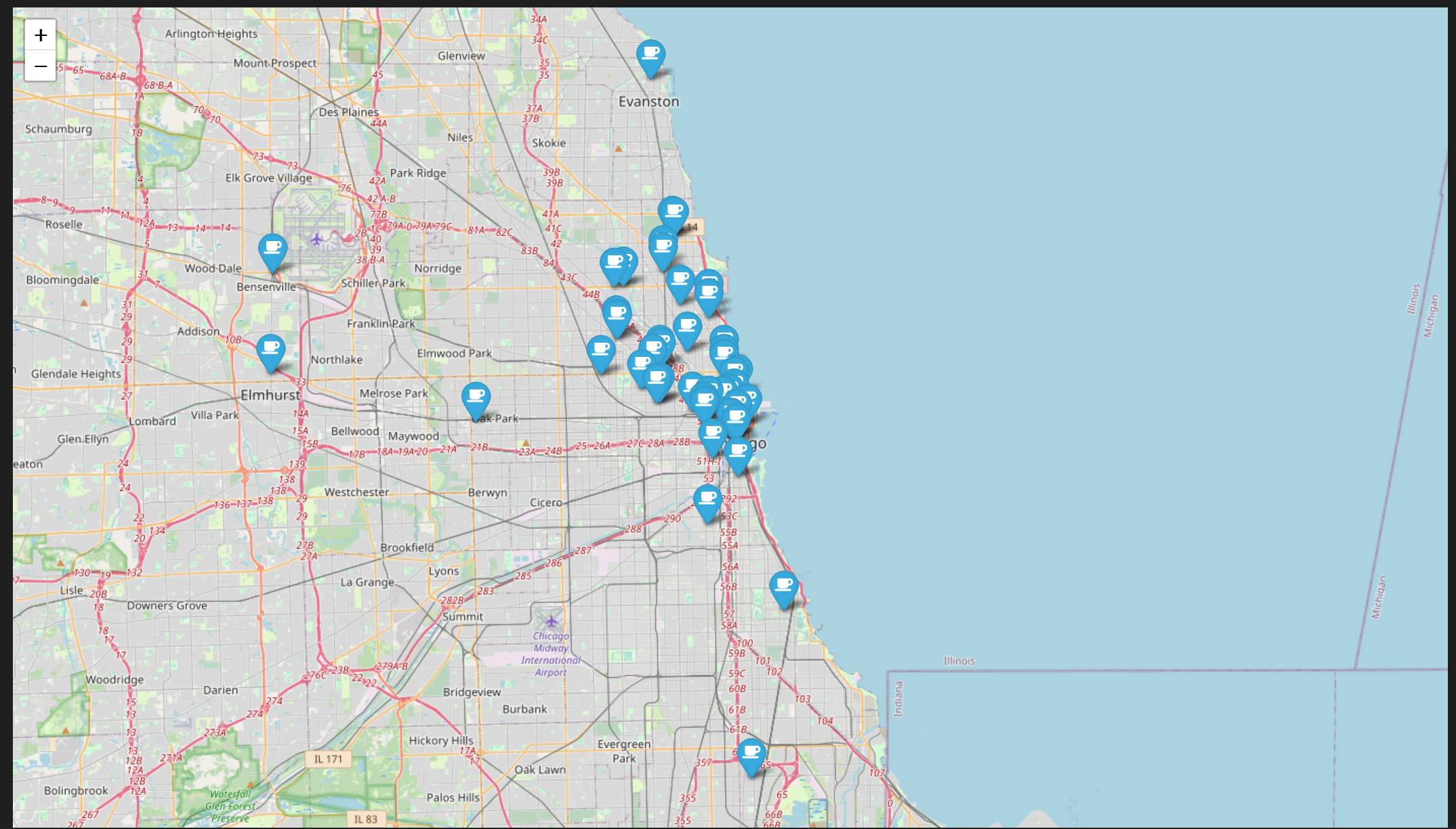
<새로 배운 코드 / 함수 >
.find() / .find_all()
.select() / /select_one()
.strip()
.replace("","")
.isinstance()
.get() / .get_text()
.string / .text
.strip()# import re re.split(('\n|\r\n'), tmp_string) re.search('\$\d+\.(\d+)?',price_tmp).group()# isinstance() 리스트 자료형 favorite_movie = ['위대한쇼맨', 9.6, '인셉션', 9.5, ['레오나르도 디카프리오','톰 크루즈']] for each in favorite_movie: if isinstance(each,list): for e in each: print('nested: ', e) else: print('each: ',each)
: each: 위대한쇼맨 ... nested: 레오나르도 디카프리오
“이글은제로베이스데이터취업스쿨의강의자료일부를발췌하여
작성되었습니다.”