논문리뷰(2)-Physics-Informed Neural Network Evolution and Beyond: A systematic Literature Review and Bibliometric Analysis
Abstract
이 논문은 PINN에 관한 다양한 사람들의 관점을 조사하고 평가함.
이 리뷰에서는 PRISMA framework가 사용되었음.
PINN의 성능을 향상시키고 높은 학습 비용과 느린 속도 등 여러 한계를 극복하기 위해 개발된 새로운 개선 기법들 역시 소개함.
기존 PINN의 제약을 극복하기 위한 다양한 접근법이 제안되었으며 이를 크게 세가지로 구분한다.
- Extended PINNs
- Hybrid PINNs
- Minimized Loss Techniques
또한 제안된 솔루션들의 한계를 기반으로 향후 연구를 위한 가능성 있는 대안을 제시한다.
주요 키워드:PINNs, PDE, loss function, activation function, deeplearning
Introduction
PINNs는 뛰어난 근사 능력과 일반화 능력 덕분에 고차원 PDE를 푸는 데 있어 각광받고 있다.
PINN의 장점으로는,
희소한 입력 데이터로도 학습이 가능하다는 점이다. PINN 구조에서는 초기 조건과 경계 조건이 체계적으로 주어지지 않기 때문에, 이러한 조건들을 손실 함수에 직접 포함시켜야 하며 이는 미분 방정식의 불확실한 함수와 함께 동시에 학습해야 한다.
하지만 gradient-based methods을 사용할 때 여러 목표를 동시에 학습하려 하면 biased gradients가 발생하여 PDE의 해를 잘 학습하지 못하게 된다.
PINN을 정확히 학습시키려면 residual loss를 최소화하는 방식이 중요한데, 특히 복잡한 비선형 문제에 대해 고차원 축소 모델보다 저차원 공간에서의 고해상도 예측 성능이 더 우수하다.
이러한 PINNs의 단점으로는,
학습 비용이 높아 실시간 응용에는 적합하지 않다는 것이다.
PINN의 학습 효율을 높이기 위한 다양한 접근이 제안되어 왔지만 initialization의 영향을 고려한 연구는 상대적으로 적다. 또 다른 중요한 문제는 PINN의 낮은 확장성(scalability)으로 인해 발생한다.
또한 핵심적인 한계는 미분 방정식의 제약 조건조차도 수학적으로 명확히 해결되지 않으며, 도메인 내에서 해와 함께 학습해야 한다는 점이다. 이로 인해 PINN 학습 과정에서는 도메인 내에서의 숨겨진 해와 경계에서의 해를 동시에 잘 학습해야 하는 목표가 발생하게 된다. 이로 인해 그래디언트가 불균형해지고 편미분방정식의 해를 정확히 학습하는 데에 어려움을 겪게 된다.
이를 정리하면 주요 단점으로는
- 느린 속도: 경사하강법 기반의 PINN의 기존 수치 해법보다 매우 느림.
- 그래디언트 소실 문제: 심층 네트워크일수록 PINN은 그래디언트가 사라지는 문제에 취약함.
- 수작업 기반 미세조정: 데이터의 양이나 어떤 네트워크 구조가 적절한지에 대한 기준이 명확하지 않아 학습 조정이 경험적으로만 이루어짐.
💡 weighted least-squares collocation
PINN에서 사용하는 방법으로, 물리 기반 손실과 데이터 기반 손실을 혼합한 방식으로 해석될 수 있음.
이로 인해 PDE의 잔차를 초기 및 경계 조건에 대해 정확히 평가해야 하는 어려움이 있으며 해가 연속성을 요구하는 높은 정칙성(regularity)과 같은 단점이 생긴다.
Background
전통적 미분방정식 해법과 ANN의 도입
기존에는 격자 기반 수치 해석법(유한차분법, 유한요소법)이 주로 사용되었고, 이들은 해를 배열 형태로 제공하거나 해석적으로 나타내는 방법을 사용하였음.
💡유한요소법(FEM)이란?
: 복잡한 문제를 단순한 작은 문제들로 나눠서 푸는 방식. '문제 설정 - 도메인 분할 - 형상함수(shape function) 정의 - 약식 또는 가상일의 원리 적용 - 요소 방정식 구성 - 전체 방정식 조립 - 경계조건 적용 후 풀기' 의 단계로 진행됨.
❔FEM 대신 PINN을 쓰게되는 이유?
- 고차원 문제에 강함.(curse of dimensionality)
- mesh가 필요 없는 방식. 정교한 격자 생성은 복잡한 형상에서는 매우 까다롭고 시간 소모적임. PINN은 단순히 좌표값을 입력으로 사용하므로 격자 없이 해를 근사시킬 수 있음.
- PINN은 데이터가 일부만 있어도 나머지는 물리 법칙을 통해 보완하기 때문에 적은 수의 실험 또는 관측 데이터로도 정밀한 예측이 가능함.
- 역문제와 계수 추정 문제에 적합함. FEM은 계수나 초기 조건이 알려져 있어야 정확한 결과가 나오나 PINN은 미지의 계수를 학습할 수 있고 inverse problem(원인을 찾아내는 문제)에 강력함.
- Automatic differentiation을 사용함. PINN은 딥러닝 프레임워크의 자동미분 기능을 활용하여 PDE의 도함수 항들을 계산함.
- 학습된 PINN은 한번 학습하면 다른 해상도나 다른 입력에서도 재사용이 가능하나 FEM은 격자를 다시 만들고 시스템 방정식을 새로 풀어야 함.
⚠️ 단, FEM이 수렴성 이론이 잘 정립되어있고 선형 문제에서 속도가 빠르며, 상용 소프트웨어가 ANSYS, Abaqus 등 있으며 정밀한 수치해가 나온다는 강점이 있음. PINN은 정밀하다기 보다 근사적 성격이 강하다.
PINN의 원리와 수학적 구성
loss function: L_data + w*L_physics
이는 다시 쓰면
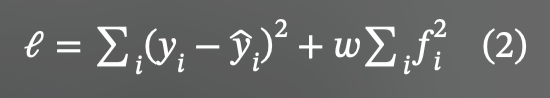
여기서 w는 두 손실 항의 상대적 중요도를 조절하는 가중치. 물리 손실은 PDE의 residual 항을 기반으로 함.
미분 연산은 Automatic Differentiation으로 진행됨.
💡입/출력 구조
input: 공간(x,y), 시간(t)
output: 해 변수(u,v 등). 출력은 데이터 오차 계산, 자동미분을 통해 PDE 미분항 계산(물리 손실 값)에 이용됨.
PINNs는 다음과 같은 일반적인 형태의 비선형 PDE를 다룰 수 있음.
이 수식은 물리학에서 등장하는 대부분의 PDE(보존 법칙, 확산, 운동 방정식 등)를 포괄함.
💡Non-linear PDE란?
: 편미분방정식 자체는 여러 개의 독립 변수에 대해 편미분이 포함된 방정식임. 예를 들면 시간, 공간에 따라 변하는 어떤 물리량을 설명하는 방정식이 해당될 수 있음.
- 선형 PDE: 미지함수와 그 도함수가 곱해지거나 제곱되지 않음 ex) heat equation, linear diffusion, Laplace's equation
- 비선형 PDE: 다음 중 하나라도 포함되면 비선형
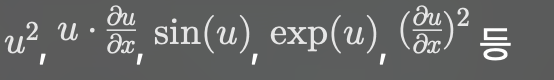
ex) Burger's equation, Navier-Stokes, Korteweg-de Vries equation
그렇다면, 비선형 PDE가 어려운 이유는 무엇일까?
그 이유는 다음과 같다.
- 해의 존재/유일성 보장이 어려움
- 해석적인 해 구하기가 굉장히 어려움(거의 불가능에 가까움)
- 충격파, 경계층, 패턴 형성 등 비정상적이고 복잡한 현상이 발생함
- 작은 오차가 증폭되기 쉬움, 해가 폭주하거나 발산 가능함
💡PINN의 두 가지 적용 방식
1. Data-Driven solutions
: 관측값(관측된 데이터) z와 알려진 파라미터 람다가 주어졌을 때, PINN은 다음 PDE를 풀어 u(t,x)를 근사
즉, 물리법칙을 지키면서 관측값에 가장 잘 맞는 해(u(t,x))를 찾는다고 볼 수 있음.
2. Data-Driven Discovery
: 관측값만 있고, PDE 구조 또는 계수 람다가 불명확한 경우. 신경망으로 u(t,x)를 근사할 뿐 아니라 람다도 함께 학습. PDE가 주어져있지 않고 해당 데이터를 설명할 PDE가 무엇인지 찾아야 함.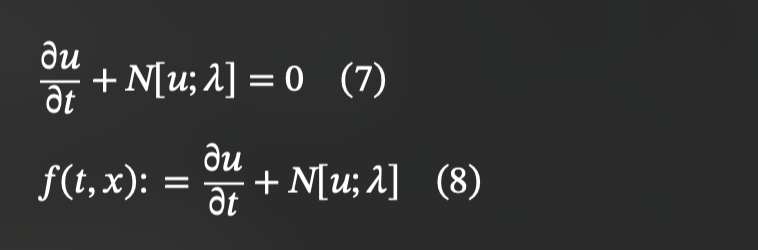
즉, 관측 데이터만 가지고 지배 PDE 구조와 계수를 동시에 추론하는 것이라고 볼 수 있다.
Methodology
이 논문은 PRISMA 기반으로 리뷰 프레임워크를 설정함.
PRISMA란 Preferred, Reporting, Items for, Systematic reviews, Meta-Analyses의 앞글자를 딴 것으로, 체계적 문헌고찰 및 메타분석을 위한 선호 보고 항목들이라고 직역할 수 있음.
전공 분야별로 보았을 때,
PINN은 수학 분야에서 논문 35편으로 가장 활발하게 연구 중이며 그 다음으로 Engineering에서 31편, Computer Science에서 29편, Physics에서 25편이 쓰임.
논문 유형별로 보았을 때,
Journal Article에서 99편, Conference Article에서 21편이 작성된 것으로 보아 대부분의 연구는 저널에 정식 게재된 학술 논문으로 연구가 점점 발전되고 있다는 점을 알 수 있음.
방법론별로 보았을 때,
Conventional PINNs(기본형)은 97편, Extended PINNs(확장형)은 12편, Hybrid PINNs(혼합형)은 7편, Minimized Loss PINNs(손실 최소화형)은 4편인 것으로 보아 현재까지는 대부분의 연구가 기본 구조의 PINN에 집중되어 있고 다양한 변형 기법은 아직 비교적 초기 단계임을 알 수 있음.
Advancements in PINNs
1. Extended PINNs
기존 PINN 구조는 단일 연산 네트워크로 구성되어 있는데 복잡한 문제나 넓은 영역에서는 수렴이 느리거나 불안정할 수 있음. 이를 보완하기 위해 구조적으로 기능을 확장한 모델.
대표 기법으로는,
- 도메인 분할 PINN: 전체 영역을 여러 서브도메인으로 나눠 각각 학습 후 결합
- Ensemble PINNs: 여러 PINN 모델을 동시에 학습하고 평균화하여 결과 안정화
- Bayesian PINNs: 확률적 접근으로 불확실성 추정 및 예측 신뢰도 향상
2. Hybrid PINNs
PINN은 기본적으로 Feedforward Neural Network 구조를 사용함. 그러나 문제 유형에 따라 다른 신경망 구조(CNN,RNN ...)와 결합하면 더 좋은 성능을 낼 수 있음.
대표 기법으로는,
- PPINN: 시계열 문제를 시간 축으로 나눠 병렬 처리하여 계산 속도 향상
- CNN-PINN: 공간 기반 문제에서 CNN 구조로 특징 추출 강화
- RNN-PINN: 시계열이나 시간 종속 문제에 순환 구조 RNN을 접목
이로 인해 시공간 문제의 복잡한 구조 반영, 고차원 특징 학습, 계산 시간 단축이라는 장점이 있다.
3. Minimized Loss Techniques
PINN은 물리 법칙 잔차 + 데이터 오차를 동시에 줄이는 방식이지만, 손실 함수의 스케일 불균형, 수렴 문제, 초기화 민감성 때문에 학습이 어려울 수 있음.
이를 해결하기 위해 손실 함수 자체를 개선하거나 최적화하는 방법임.
대표 기법으로는,
- NRPINN(New Reptile Initialization PINN): 여러 유사 문제를 통해 좋은 초기 가중치를 학습하는 메타러닝 방식
- PI-PP-NN: 물리 법칙을 더 강하게 반영하기 위해 패널티 항 추가 및 강화
- Adaptive Weighting: 손실 항목 간 가중치를 자동으로 조정하여 학습 안정화
이로 인해 학습 안정성 향상, 수렴 속도 개선, 더 정확한 PDE 근사를 기대할 수 있다.
