예전에 네트워크에서 데이터를 받는 코드를 작성할 때 호출 자체도 백그라운드에서 하면 더 좋지 않을까 라는 생각으로 코드를 짠적이 있다. 그 부분을 한 번 실험을 해보았슴니다. 제 생각에 엄청난 확신이 있지는 않았기 때문에,,,
URLSession 호출
호출을 Task 로 감싸서 호출하는것과 감싸지 않고 호출하는것의 속도 차이를 보도록 하겠슴니다.
일반적인경우
Task 없이 메인 스레드에서 호출하는 부분
print(progressTime {
print("first")
for _ in 0..<10000 {
session.dataTask(with: URLRequest(url: URL(string: "https://httpbin.org/get")!)) { data, response, error in
print(data)
}.resume()
}
})
// 한 번 호출: 0.0009419918060302734
// 10번: 0.0028859376907348633
// 10000번: 2.6666예상한대로, 호출 자체를 메인스레드에서 하다보니 시간이 점점 늘어남을 볼 수 있다.
Task를 사용한 경우
이번에는 Task를 활용한 백그라운드 스레드에서 호출하는 부분임니다
print(progressTime {
print("task")
Task {
for _ in 0..<10000 {
session.dataTask(with: URLRequest(url: URL(string: "https://httpbin.org/get")!)) { data, response, error in
print(data)
}.resume()
}
}
})
// 한 번 호출: 0.00039005279541015625
// 10번: 0.0006300210952758789
// 10000번: 0.0006290674209594727어느정도는 차이가 날 줄 알았는데 확실히 Task를 사용한 코드가 매우 효율적임을 볼 수 있었슴니다. Task가 계속 스레드에 작업들을 할당해주기 때문에 호출 자체가 상당히 빨리 끝나지 싶다.
시간측정함수, api사이트, cpu 사용량
get api 테스트를 위한 사이트는 https://resttesttest.com/ 임니다. 여기서 https://httpbin.org/get 를 사용하였씀니다.
시간 차이를 print하는 코드는 아래와 같슴미다
// 참조: https://chanhhh.tistory.com/94
func progressTime(_ closure: () -> ()) -> TimeInterval {
let start = CFAbsoluteTimeGetCurrent()
closure()
let diff = CFAbsoluteTimeGetCurrent() - start
return (diff)
}그리고 호출한 후의 CPU 사용량 사진임니다 cpu 사용량의 차이는 거의 존재하지 않슴니다. dataTask는 호출하고 나서는 백그라운드에서 응답을 받기 떄문에 큰 차이는 나지 않는거 같슴니다 ~ 위에 사진이 일반적인 경우의 호출이고, 아래 사진이 Task를 사용한 버전임니다.
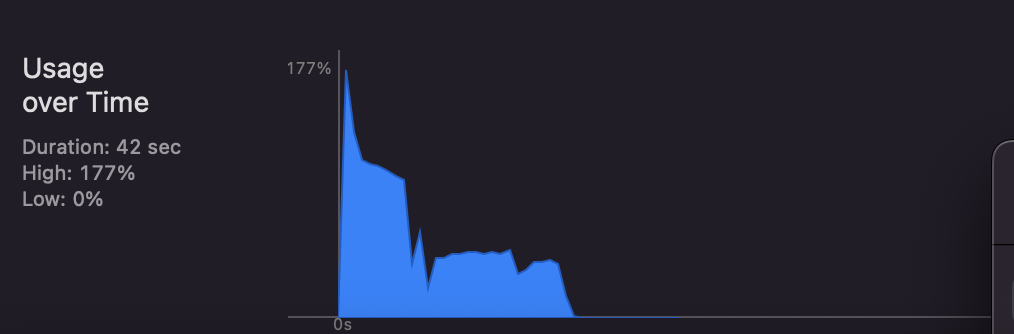
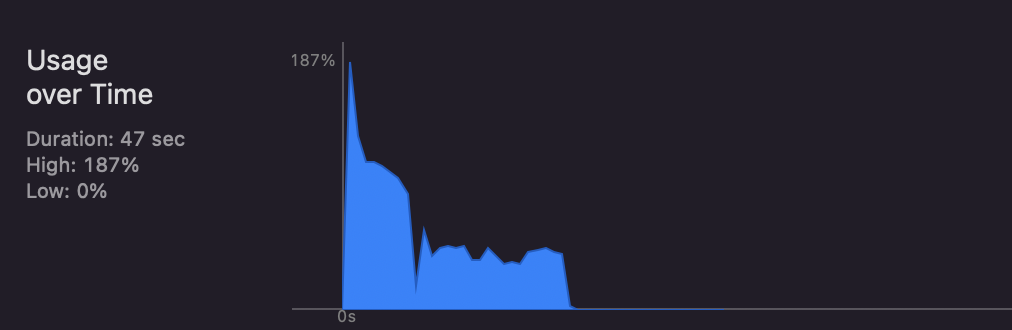
내용의 결과는 대충 예상은 하고 있었지만 확신을 얻기 위해 이번에 테스트 해보았는데 나름 재밌었던거 같슴미당ㅎ,ㅎ

hi there 👋